JSON-LD: Komplett guide till implementation och SEO-fördelar
Lär dig vad JSON-LD är och hur du implementerar det för SEO. Upptäck fördelarna med strukturerad datamarkering för Google, ChatGPT, Perplexity och AI-sökbarhet....
14 min läsning
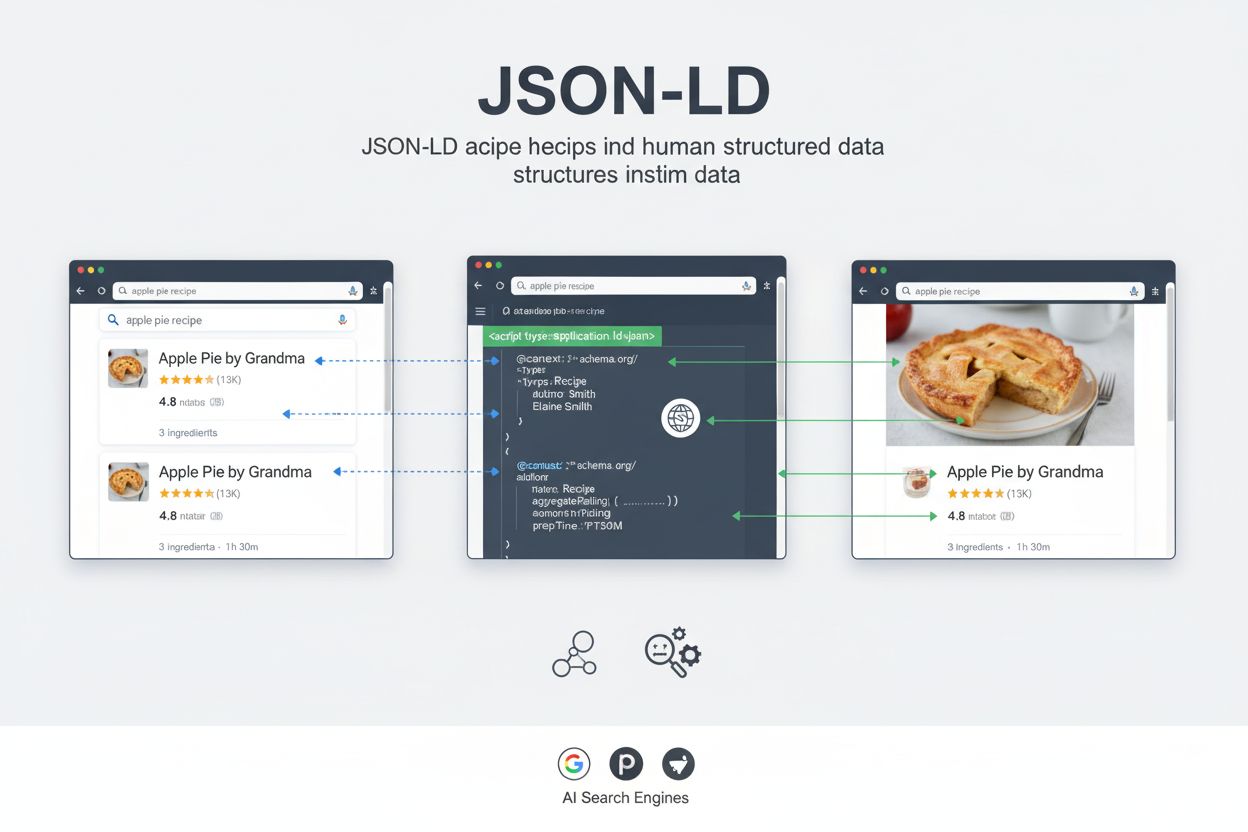
JSON-LD (JavaScript Object Notation for Linked Data) är ett lättviktigt, W3C-standardiserat format för att uttrycka strukturerad data med hjälp av JSON-syntax, vilket gör det möjligt för sökmotorer och AI-system att förstå webbplatsinnehåll via schema.org-vokabulär. Det bäddas in i webbsidor som maskinläsbar markering som hjälper sökmotorer att visa rika resultat och förbättrar upptäckbarheten av innehåll på AI-drivna plattformar.
JSON-LD (JavaScript Object Notation for Linked Data) är ett lättviktigt, W3C-standardiserat format för att uttrycka strukturerad data med hjälp av JSON-syntax, vilket gör det möjligt för sökmotorer och AI-system att förstå webbplatsinnehåll via schema.org-vokabulär. Det bäddas in i webbsidor som maskinläsbar markering som hjälper sökmotorer att visa rika resultat och förbättrar upptäckbarheten av innehåll på AI-drivna plattformar.
JSON-LD står för JavaScript Object Notation for Linked Data och representerar ett lättviktigt, standardiserat format för att uttrycka strukturerad data på webbsidor. Etablerat som en W3C-rekommendation sedan januari 2014 kombinerar JSON-LD enkelheten i JSON-syntax med den semantiska styrkan i länkade datavokabulärer, särskilt schema.org. Till skillnad från andra format för strukturerad data som blandar markering med HTML-innehåll, bäddas JSON-LD in som en separat <script>-tagg i sidhuvudet eller kropp, vilket håller data åtskilt från presentationsmarkeringen. Denna separation gör JSON-LD särskilt lätt att implementera, underhålla och skala över stora webbplatser och innehållshanteringssystem.
Det huvudsakliga syftet med JSON-LD är att tillhandahålla maskinläsbar kontext som hjälper sökmotorer, AI-system och andra webbapplikationer att förstå betydelsen och relationerna i webbsidans innehåll. När det implementeras korrekt möjliggör JSON-LD för sökmotorer att visa rika resultat – förbättrade sökfragment som inkluderar betyg, priser, bilder, evenemangsdetaljer och annan strukturerad information. För AI-drivna sökplattformar som ChatGPT, Perplexity, Google AI Overviews och Claude fungerar JSON-LD som en avgörande brygga mellan människoläsbart innehåll och maskintolkbar data, vilket förbättrar precisionen och relevansen i AI-genererade svar och citeringar.
JSON-LD har blivit det rekommenderade formatet för strukturerad data av Google och andra ledande sökmotorer eftersom det minimerar implementeringsfel och fungerar sömlöst med moderna webbtekniker, inklusive JavaScript-ramverk och dynamisk innehållsgenerering. Formatets flexibilitet gör det möjligt att uttrycka komplexa, nästlade datastrukturer, vilket gör det lämpligt för olika innehållstyper – från enkel produktinformation till avancerade organisationshierarkier och evenemangsdetaljer.
JSON-LD uppstod ur behovet att överbrygga traditionella JSON-dataformat med semantiska webbstandarder. Innan JSON-LD förlitade sig utvecklare som arbetade med länkad data på RDF/XML eller Turtle-format, vilka var kraftfulla men komplexa och inte naturligt anpassade till webbteknik. Utvecklingen av JSON-LD startade i början av 2010-talet inom W3C JSON-LD Community Group, med insikten att JSON hade blivit de facto-standard för webb-API:er och datautbyte. Formatet standardiserades officiellt av W3C 2014, med efterföljande förbättringar som ledde till att JSON-LD 1.1 blev en fullständig W3C-rekommendation 2020.
Användningen av JSON-LD accelererade kraftigt efter att Google och andra stora sökmotorer började rekommendera det som det föredragna formatet för schema.org-markering 2013. Denna rekommendation var avgörande, då det signalerade för webbutvecklare att JSON-LD inte bara var en akademisk lösning utan även ett praktiskt, produktionsklart verktyg för verkliga SEO- och upptäckbarhetsutmaningar. Under det senaste decenniet har användningen av JSON-LD ökat exponentiellt, och nu visar data att 41% av alla webbplatser använder JSON-LD för strukturerad data, upp från 34% år 2022. Bland webbplatser som implementerar någon form av strukturerad data använder cirka 70% JSON-LD, vilket gör det till det dominerande formatet på området.
JSON-LD:s utveckling har också påverkats av ökningen av AI-drivna sökmotorer och stora språkmodeller. När plattformar som ChatGPT, Perplexity och Google AI Overviews blivit vanliga har betydelsen av JSON-LD ökat, eftersom dessa system är starkt beroende av strukturerad data för att extrahera exakt och kontextuell information från webbsidor. Formatets förmåga att tydligt definiera entitetstyper, relationer och egenskaper gör det ovärderligt för AI-system som behöver förstå webbinnehåll i stor skala.
JSON-LD-dokument följer standard JSON-syntax men inkluderar särskilda reserverade nyckelord med prefixet @ som tillför semantisk betydelse. De mest grundläggande av dessa är @context, @type och @id. @context-egenskapen specificerar vokabulärens namnrymd – oftast https://schema.org – som definierar betydelsen av alla egenskaper och typer i markeringen. Denna kontext fungerar som en namnrymdsdeklaration, likt XML-namnrymder, vilket garanterar att egenskapsnamn tolkas konsekvent över olika system och plattformar.
@type-egenskapen anger schematypen för den entitet som beskrivs, t.ex. Product, Article, Event, Organization eller LocalBusiness. Varje typ i schema.org har en uppsättning associerade egenskaper som kan användas för att beskriva instanser av den typen. Exempelvis kan en Product-typ inkludera egenskaper som name, description, price, image, aggregateRating och offers. @id-egenskapen tillhandahåller en unik identifierare för entiteten, vanligen en URL som leder till mer information om den.
Utöver dessa kärnnyckelord innehåller JSON-LD-dokument anpassade egenskaper som direkt mappar mot schema.org-vokabulären. Dessa kan innehålla enkla värden (strängar, siffror, datum) eller komplexa nästlade objekt som representerar relaterade entiteter. Till exempel kan en Product-entitet ha en offers-egenskap som innehåller ett inbäddat Offer-objekt med eget @type och egenskaper som price och priceCurrency. Denna nästlingsmöjlighet gör att JSON-LD kan uttrycka avancerade datarelationships och hierarkier som skulle vara svårhanterliga i plattare format som Microdata.
| Aspekt | JSON-LD | Microdata | RDFa |
|---|---|---|---|
| Implementeringsplats | Separat <script>-tagg i <head> eller <body> | Inbäddad i HTML-attribut | Inbäddad i HTML-attribut |
| Implementeringsvänlighet | Mycket enkel; minimala HTML-ändringar | Måttlig; kräver HTML-attribut | Måttlig till komplex; kräver namnrymdsdeklarationer |
| Underhållskomplexitet | Låg; data separerad från presentation | Medel; markering blandad med innehåll | Medel till hög; flera vokabulärer möjliga |
| Stöd för dynamiskt innehåll | Utmärkt; fungerar med JavaScript-injektion | Begränsat; kräver serverrendering | Begränsat; kräver serverrendering |
| Google-rekommendation | Rekommenderad | Stöds | Stöds |
| Användningsgrad (2024) | 41% av alla webbplatser; 70% av sidor med strukturerad data | ~20% av sidor med strukturerad data | ~15% av sidor med strukturerad data |
| Vokabulärflexibilitet | En vokabulär per dokument (oftast schema.org) | En vokabulär per dokument | Flera vokabulärer stöds |
| Näslingskomplexitet | Utmärkt; naturlig JSON-hierarki | Bra; kräver flera itemscope-deklarationer | Bra; stöder komplexa relationer |
| AI-sökmotor-kompatibilitet | Utmärkt; föredras av ChatGPT, Perplexity, Claude | Bra; stöds men mindre föredraget | Bra; stöds men mindre föredraget |
När en sökmotorrobot eller ett AI-system stöter på en webbsida som innehåller JSON-LD-markering, tolkar den <script type="application/ld+json">-taggen och extraherar den strukturerade datan. Robotens användning av @context gör att den förstår vilken vokabulär som används och tolkar varje egenskap enligt schema.org-definitioner. Denna process gör att sökmotorn kan extrahera specifik, maskinläsbar information om sidans innehåll utan att förlita sig på naturlig språkbehandling eller heuristik.
För Google Sök möjliggör JSON-LD-markering visning av rika resultat – förbättrade sökfragment med visuella element som betyg, priser, bilder och evenemangsdetaljer. När Google genomsöker en produktsida med korrekt implementerad JSON-LD kan de extrahera produktnamn, pris, tillgänglighet, recensioner och bilder direkt från den strukturerade datan. Denna information används sedan för att generera ett rikt resultat i sökningen, oftast med högre klickfrekvens än vanliga blå länkar. Forskning från större webbplatser visar effekten: Rotten Tomatoes såg en 25% högre klickfrekvens på sidor med strukturerad data och Nestlé mätte 82% högre klickfrekvens på sidor som visades som rika resultat.
För AI-sökmotorer som Perplexity, ChatGPT och Google AI Overviews fyller JSON-LD en annan men lika viktig funktion. Dessa system använder strukturerad data för att förstå det semantiska innehållet, identifiera nyckelentiteter och relationer samt extrahera korrekt information till AI-genererade svar. När ett AI-system möter JSON-LD-markering kan det säkert identifiera vilken typ av entitet som beskrivs, dess egenskaper och hur den relaterar till andra entiteter. Denna strukturerade förståelse hjälper AI-system att leverera mer precisa, relevanta svar och ge korrekt källa till webbplatser.
Effektiv implementering av JSON-LD kräver förståelse för flera centrala principer och bästa praxis. För det första bör JSON-LD placeras i sidans <head>-sektion, även om det även kan ligga i <body>. Placering i <head> är att föredra, då den strukturerade datan då tolkas innan sidinnehållet, även om moderna sökmotorer och AI-system kan tolka JSON-LD var som helst på sidan.
För det andra bör @context alltid definieras explicit, oftast som "@context": "https://schema.org". Detta garanterar att alla egenskapsnamn och typer tolkas enligt schema.org-definitioner. Även om det tekniskt är möjligt att använda flera kontexter eller egna vokabulärer, använder nästan alla webbimplementationer endast schema.org.
För det tredje bör JSON-LD-markeringen korrekt återge det synliga innehållet på sidan. Sökmotorer och AI förväntar sig att den strukturerade datan stämmer överens med vad användaren ser. Att lägga till JSON-LD om information som inte är synlig för användaren – eller som motsäger synligt innehåll – kan leda till att markeringen ignoreras eller till och med bestraffas. Denna princip är avgörande för att bibehålla förtroende hos sökmotorer och säkerställa att AI-system citerar ditt innehåll korrekt.
För det fjärde bör alla obligatoriska egenskaper för vald schematyp inkluderas. Även om schema.org definierar många valfria egenskaper, säkerställer inkludering av de obligatoriska att sökmotorer kan validera och visa markeringen korrekt. Till exempel kräver ett Product-schema minst egenskaperna name, description och offers för att kunna visas som rikt resultat.
För det femte bör JSON-LD-markering valideras med verktyg som Googles Rich Results Test eller Schema.orgs Validator innan lansering. Dessa verktyg kontrollerar syntaxfel, saknade obligatoriska egenskaper och andra problem som kan göra att markeringen inte känns igen. Testning under utvecklingen förhindrar problem i produktion och säkerställer att markeringen fungerar som avsett.
Implementering av JSON-LD för strukturerad data ger mätbara fördelar på flera områden. Ur ett SEO-perspektiv möjliggör JSON-LD rika resultat som kraftigt förbättrar klickfrekvensen. Food Network konverterade 80% av sina sidor till strukturerad data och mätte en 35% ökning av besök. Rakuten upptäckte att användare spenderade 1,5 gånger mer tid på sidor med strukturerad data jämfört med sidor utan, och såg en 3,6 gånger högre interaktionsgrad på AMP-sidor med sökfunktioner.
Ur ett AI-synlighetsperspektiv blir JSON-LD allt viktigare i takt med att AI-drivna sökmotorer blir norm. Webbplatser som implementerar JSON-LD-markering har större chans att deras innehåll förstås, citeras och lyfts fram i AI-genererade svar. Detta är särskilt viktigt för AmICited-användare som vill spåra och övervaka hur deras varumärke, domän och URL:er syns i AI-sökresultat över plattformar som ChatGPT, Perplexity, Google AI Overviews och Claude. Korrekt JSON-LD-implementering säkerställer att AI-system har den strukturerade kontext som krävs för att korrekt tillskriva och citera ditt innehåll.
Ur ett tekniskt perspektiv minskar JSON-LD implementeringskomplexiteten och underhållsbördan. Eftersom markeringen är separerad från HTML-innehållet kan utvecklare hantera strukturerad data oberoende av layoutändringar. Detta är särskilt värdefullt för större organisationer med komplexa innehållshanteringssystem där flera team ansvarar för innehåll och teknik.
Ur ett användarupplevelseperspektiv förbättrar JSON-LD indirekt användarengagemang genom att möjliggöra rikare och mer informativa sökresultat. Användare klickar oftare på sökresultat som visar betyg, priser, bilder och annan strukturerad information, vilket leder till ökad trafik och bättre konverteringsgrad för webbplatser som implementerar JSON-LD effektivt.
JSON-LD integreras sömlöst med moderna webbutvecklingsmetoder och tekniker. Till skillnad från Microdata och RDFa, som kräver serverrendering för att tolkas korrekt av sökmotorer, kan JSON-LD dynamiskt injiceras med JavaScript. Denna förmåga är avgörande för single-page applications (SPAs), progressive web apps (PWAs) och andra JavaScript-tunga webbplatser som genererar innehåll dynamiskt.
Innehållshanteringssystem (CMS) som WordPress, Shopify, Wix och Drupal erbjuder allt oftare inbyggt stöd för JSON-LD-generering, antingen inbyggt eller via plugins. Detta gör att även icke-tekniska användare kan lägga till strukturerad data utan att skriva kod. Många CMS genererar automatiskt JSON-LD-markering baserat på sidans metadata och innehåll, vilket minskar arbetsbördan för utvecklare och innehållsskapare.
JSON-LD fungerar även väl med headless CMS-arkitekturer där innehåll hanteras separat från presentationen. I dessa system kan JSON-LD genereras server-side och levereras som en del av sidans svar, eller genereras client-side med hjälp av JavaScript-ramverk som React, Vue eller Angular. Denna flexibilitet gör JSON-LD lämpligt för praktiskt taget alla moderna webbarkitekturer.
https://schema.org för konsekvent vokabulärtolkningDen framtida betydelsen av JSON-LD förväntas snarare öka än minska. Allt eftersom AI-drivna sökmotorer och stora språkmodeller blir mer sofistikerade kommer behovet av högkvalitativ, maskinläsbar strukturerad data att öka. Sökmotorer och AI-system använder i ökande grad strukturerad data inte bara för visning utan som en kärnkomponent i sin förståelse och rankningsalgoritmer.
Framväxande utveckling inom JSON-LD inkluderar JSON-LD-star, som utökar formatet för att stödja mer komplexa kunskapsgrafer, samt CBOR-LD, som ger en kompakt binär representation av JSON-LD-data. Dessa utökningar antyder att JSON-LD-ekosystemet kommer fortsätta utvecklas för att möta behoven hos alltmer avancerade webbapplikationer och AI-system.
Framväxten av AI-sökmotorer representerar ett paradigmskifte i hur strukturerad data används. Traditionella sökmotorer använder i huvudsak strukturerad data för visningsändamål – för att skapa rika resultat. AI-sökmotorer, däremot, använder strukturerad data som ett fundamentalt underlag för förståelse och resonemang. Detta innebär att webbplatser som implementerar JSON-LD effektivt får ett betydande försprång i AI-synlighet och citeringsfrekvens.
Dessutom, i takt med att integritetsfrågor och datastyrning blir viktigare, kan JSON-LD spela en större roll i att uttrycka datakälla, licenser och användningsrättigheter. Formatets flexibilitet och utbyggbarhet gör det väl lämpat för att uttrycka komplex metadata om datakällor och användningsrestriktioner, vilket blir allt viktigare när organisationer vill behålla kontrollen över hur deras data används av AI-system.
För organisationer som använder plattformar som AmICited för att övervaka sin synlighet i AI-sökresultat är en heltäckande JSON-LD-implementation en strategisk investering. Genom att ge AI-system tydlig och strukturerad kontext om ditt innehåll ökar du sannolikheten att ditt varumärke, din domän och dina URL:er blir korrekt förstådda, citerade och lyfta i AI-genererade svar. I takt med att AI-sök fortsätter att växa i betydelse blir JSON-LD en oumbärlig del av varje heltäckande SEO- och synlighetsstrategi.
JSON-LD och Microdata är båda format för strukturerad data, men de skiljer sig åt i implementation. JSON-LD bäddas in i en separat <script>-tagg och blandas inte med HTML-innehållet, vilket gör det lättare att underhålla och implementera i stor skala. Microdata använder HTML-attribut direkt i sidans innehåll. Google rekommenderar JSON-LD för de flesta implementationer eftersom det är mindre benäget för användarfel och fungerar smidigt med dynamiskt injicerat innehåll från JavaScript-ramverk och innehållshanteringssystem.
JSON-LD gör det möjligt för sökmotorer att bättre förstå sidans innehåll, vilket kan resultera i rika resultat – förbättrade sökvisningar med betyg, priser, bilder och annan strukturerad information. Studier visar att sidor med strukturerad datamarkering får avsevärt högre klickfrekvens. Till exempel mätte Nestlé en 82% högre klickfrekvens på sidor som visades som rika resultat jämfört med sidor utan, vilket visar JSON-LD:s direkta effekt på sökprestanda och användarengagemang.
@context i JSON-LD specificerar vokabulärens namnrymd (vanligtvis schema.org) som definierar betydelsen av egenskaper och typer som används i markeringen. Det fungerar som ett XML-namnrymd och talar om för sökmotorer och AI-system hur datan ska tolkas. Till exempel @context: 'https://schema.org' talar om för tolken att @type-värden som 'Product' eller 'Article' avser schema.org-definitioner, vilket säkerställer enhetlig tolkning över olika plattformar och system.
Ja, JSON-LD-strukturerad data blir allt viktigare för AI-sökmotorer. Plattformar som ChatGPT, Perplexity och Google AI Overviews använder strukturerad data för att bättre förstå och extrahera information från webbsidor. JSON-LD ger maskinläsbar kontext som hjälper dessa AI-system att identifiera nyckelentiteter, relationer och innehållstyper, vilket ökar sannolikheten att ditt innehåll citeras och lyfts fram i AI-genererade svar.
Viktiga JSON-LD-egenskaper inkluderar @context (definierar vokabulären), @type (specificerar schematypen som Product eller Article), @id (unik identifierare för entiteten) samt anpassade egenskaper baserat på schematyp. För ett Product-schema kan man inkludera name, description, price, image och aggregateRating. Varje egenskap kopplas till schema.org-definitioner, vilket gör att sökmotorer kan extrahera och förstå specifik information om ditt innehåll.
Användningen av JSON-LD har ökat markant och nådde 41% av alla webbplatser 2024, upp från 34% år 2022. Bland webbplatser som använder strukturerad datamarkering är JSON-LD det mest använda formatet, med cirka 70% av sidor med strukturerad data. Denna tillväxt speglar Googles rekommendation av JSON-LD som föredraget format och dess enkelhet jämfört med alternativa format som Microdata och RDFa.
JSON-LD har flera fördelar jämfört med RDFa: det är enklare att implementera och underhålla, kräver inte inbäddning i HTML-innehållet, fungerar smidigt med JavaScript-genererat innehåll och är mindre benäget för fel. Även om RDFa tillåter kombination av flera vokabulärer för komplexa behov, gör JSON-LD:s enkelhet och Googles tydliga rekommendation det till det föredragna valet för de flesta webbplatser som vill implementera strukturerad data för sökbarhet och AI-upptäckbarhet.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig vad JSON-LD är och hur du implementerar det för SEO. Upptäck fördelarna med strukturerad datamarkering för Google, ChatGPT, Perplexity och AI-sökbarhet....
Diskussion i communityn om implementering av JSON-LD för synlighet i AI-sök. Utvecklare och SEO-experter delar hur strukturerad data påverkar AI-citat och bästa...
Lär dig hur du implementerar Organization-schema markup för AI-synlighet. Steg-för-steg-guide för att lägga till JSON-LD-strukturerad data, förbättra AI-citerin...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.