
Vad är en kunskapsgraf och varför är den viktig? | AI Monitoring FAQ
Upptäck vad kunskapsgrafer är, hur de fungerar och varför de är avgörande för modern datalagring, AI-tillämpningar och affärsanalys.
8 min läsning
En kunskapsgraf är en databas med sammankopplad information som representerar verkliga enheter—såsom personer, platser, organisationer och koncept—och illustrerar de semantiska relationerna mellan dem. Sökmotorer som Google använder kunskapsgrafer för att förstå användarens avsikt, leverera mer relevanta resultat och driva AI-baserade funktioner som kunskapspaneler och AI-översikter.
En kunskapsgraf är en databas med sammankopplad information som representerar verkliga enheter—såsom personer, platser, organisationer och koncept—och illustrerar de semantiska relationerna mellan dem. Sökmotorer som Google använder kunskapsgrafer för att förstå användarens avsikt, leverera mer relevanta resultat och driva AI-baserade funktioner som kunskapspaneler och AI-översikter.
En kunskapsgraf är en databas med sammankopplad information som representerar verkliga enheter—såsom personer, platser, organisationer och koncept—och illustrerar de semantiska relationerna mellan dem. Till skillnad från traditionella databaser som organiserar information i fasta, tabellbaserade format, strukturerar kunskapsgrafer data som nätverk av noder (enheter) och kanter (relationer), vilket gör det möjligt för system att förstå betydelse och kontext snarare än att bara matcha nyckelord. Googles kunskapsgraf, lanserad 2012, revolutionerade sök genom att införa entitetsbaserad förståelse, vilket gjorde att sökmotorn kunde besvara faktabaserade frågor som “Hur hög är Eiffeltornet?” eller “Var hölls sommar-OS 2016?” genom att förstå vad användaren faktiskt letar efter, inte bara orden de använder. I maj 2024 innehöll Googles kunskapsgraf över 1,6 biljoner fakta om 54 miljarder enheter, vilket är en enorm ökning jämfört med 500 miljarder fakta om 5 miljarder enheter år 2020. Denna tillväxt återspeglar den ökande betydelsen av strukturerad, semantisk kunskap för att driva modern sök, AI-system och intelligenta applikationer över branscher.
Konceptet kunskapsgrafer växte fram ur decennier av forskning inom artificiell intelligens, semantiska webbteknologier och kunskapsrepresentation. Begreppet fick dock brett genomslag när Google introducerade sin kunskapsgraf 2012, vilket fundamentalt förändrade hur sökmotorer levererar resultat. Innan kunskapsgrafen använde sökmotorer främst nyckelordsmatchning—om du sökte på “säl” visade Google resultat för alla möjliga betydelser av ordet utan att förstå vilken entitet du faktiskt ville veta mer om. Kunskapsgrafen förändrade detta genom att tillämpa principer från ontologi—ett formellt ramverk för att definiera enheter, deras attribut och relationer—i stor skala. Denna övergång från “strängar till saker” var ett grundläggande framsteg inom sökteknologi, vilket gjorde att algoritmer kunde förstå att “säl” kunde syfta på ett havsdjur, en musikartist, en militär enhet eller en säkerhetsanordning, och avgöra vilken betydelse som var mest relevant utifrån kontexten. Den globala marknaden för kunskapsgrafer speglar denna betydelse, med prognoser som visar på en tillväxt från 1,49 miljarder dollar 2024 till 6,94 miljarder dollar år 2030, vilket motsvarar en årlig tillväxttakt på cirka 35 %. Denna explosiva tillväxt drivs av företagsadoption inom finans, sjukvård, detaljhandel och försörjningskedjehantering, där organisationer alltmer inser att förståelse för entitetsrelationer är avgörande för beslutsfattande, bedrägeribekämpning och operativ effektivitet.
Kunskapsgrafer fungerar genom en sofistikerad kombination av datastrukturer, semantiska teknologier och maskininlärningsalgoritmer. I grunden använder kunskapsgrafer en grafstrukturerad datamodell bestående av tre grundläggande komponenter: noder (som representerar enheter som personer, organisationer eller koncept), kanter (som representerar relationer mellan enheter) och etiketter (som beskriver relationernas natur). Till exempel kan “Seal” vara en nod, “är-en” vara en kantetikett och “Musikartist” en annan nod, vilket skapar den semantiska relationen “Seal är-en Musikartist.” Denna struktur skiljer sig fundamentalt från relationsdatabaser som tvingar in data i rader och kolumner med fördefinierade scheman. Kunskapsgrafer byggs antingen med labeled property graphs (där egenskaper lagras direkt på noder och kanter) eller RDF (Resource Description Framework) triple stores (där all information representeras som subjekt-predikat-objekt-trippel). Styrkan hos kunskapsgrafer ligger i deras förmåga att integrera data från flera källor med olika strukturer och format. När data matas in i en kunskapsgraf använder semantiska berikningsprocesser naturlig språkbehandling (NLP) och maskininlärning för att identifiera enheter, extrahera relationer och förstå kontext. Detta gör att kunskapsgrafer automatiskt kan känna igen att “IBM”, “International Business Machines” och “Big Blue” alla syftar på samma entitet, samt förstå hur denna entitet relaterar till andra, som “Watson”, “Molntjänster” och “Artificiell Intelligens”. Den resulterande sammankopplade strukturen möjliggör sofistikerade frågor och resonemang, vilket skulle vara omöjligt i traditionella databaser, och gör det möjligt för system att besvara komplexa frågor genom att vandra mellan relationer och dra ny kunskap från befintliga kopplingar.
| Aspekt | Kunskapsgraf | Traditionell relationsdatabas | Grafdatabas |
|---|---|---|---|
| Datastruktur | Noder, kanter och etiketter som representerar enheter och relationer | Tabeller, rader och kolumner med fördefinierade scheman | Noder och kanter optimerade för relationsvandring |
| Schemaflexibilitet | Mycket flexibel; utvecklas när ny information upptäcks | Stel; kräver schemadefinition före datainmatning | Flexibel; stödjer dynamisk schemautveckling |
| Relationshantering | Inbyggt stöd för komplexa, flerledade relationer | Kräver joins över flera tabeller; beräkningsintensivt | Optimerad för effektiva relationsfrågor |
| Frågespråk | SPARQL (för RDF), Cypher (för property graphs), eller egna API:er | SQL | Cypher, Gremlin eller SPARQL |
| Semantisk förståelse | Betonar betydelse och kontext genom ontologier | Fokuserar på datalagring och hämtning | Fokuserar på effektiv vandring och mönsterigenkänning |
| Användningsområden | Semantisk sök, kunskapsupptäckt, AI-system, entitetsupplösning | Affärstransaktioner, rapportering, OLTP-system | Rekommendationsmotorer, bedrägeridetektion, nätverksanalys |
| Dataintegration | Utmärkt på att integrera heterogen data från flera källor | Kräver omfattande ETL och datatransformation | Bra för sammankopplad data men mindre semantisk inriktning |
| Skalbarhet | Skalar till miljarder enheter och biljoner fakta | Skalar bra för strukturerad, transaktionell data | Skalar bra för relationsintensiva frågor |
| Inferensmöjligheter | Avancerat resonemang och kunskapsderivering genom ontologier | Begränsat; kräver explicit programmering | Begränsat; fokuserar på mönsterigenkänning |
Kunskapsgrafer har blivit centrala i moderna SEO- och AI-synlighetsstrategier eftersom de i grunden avgör hur information visas i sökresultat och AI-genererade svar. När Google bearbetar en sökfråga är en av dess huvuduppgifter att identifiera entiteten som användaren söker efter och sedan hämta relevant information från kunskapsgrafen för att fylla SERP-funktioner. Detta entitetsbaserade tillvägagångssätt har lett till framväxten av semantisk sök—Googles förmåga att förstå betydelsen och kontexten i frågor istället för att bara matcha nyckelord. Kunskapsgrafen driver flera synliga SERP-funktioner som direkt påverkar klickfrekvenser och varumärkessynlighet. Kunskapspaneler visas framträdande på desktop och mobila resultat och visar kuraterade fakta om den sökta entiteten hämtade från kunskapsgrafen. AI-översikter (tidigare Search Generative Experience) syntetiserar information från flera källor identifierade genom kunskapsgrafrelationer och ger omfattande svar som ofta skjuter traditionella organiska listningar längre ner på sidan. People Also Ask-rutor använder entitetsrelationer för att föreslå relaterade sökningar och ämnen. Att förstå dessa funktioner är avgörande för varumärken eftersom de utgör förstklassiga placeringar i sökresultaten och ofta syns ovanför traditionella organiska listningar. För organisationer som övervakar sin närvaro i AI-system som Perplexity, ChatGPT, Claude och Google AI Overviews blir kunskapsgrafoptimering nödvändig. Dessa AI-system förlitar sig alltmer på strukturerad entitetsinformation och semantiska relationer för att generera exakta, kontextuella svar. Ett varumärke som har optimerat sin entitetsnärvaro i kunskapsgrafer—genom strukturerad datamärkning, anspråkade kunskapspaneler och konsekvent information över källor—har större chans att synas i AI-genererade svar om relevanta ämnen. Omvänt kan varumärken med ofullständig eller inkonsekvent entitetsinformation förbises eller felrepresenteras i AI-system, vilket direkt påverkar deras synlighet och rykte.
Googles kunskapsgraf hämtar data från ett brett ekosystem av datakällor, där varje källa bidrar med olika typer av information och fyller olika syften. Öppna data och community-projekt som Wikipedia och Wikidata utgör grunden för mycket av innehållet i kunskapsgrafen. Wikipedia tillhandahåller narrativa beskrivningar och sammanfattningsinformation som ofta syns i kunskapspaneler, medan Wikidata—en strukturerad kunskapsbas som stödjer Wikipedia—tillhandahåller maskinläsbar entitetsdata och relationer. Google använde tidigare Freebase, sin egen community-redigerade databas, men övergick till Wikidata efter att Freebase stängdes ner 2016. Myndighetsdatakällor bidrar med auktoritativ information, särskilt vid faktabaserade frågor. CIA World Factbook ger information om länder, geografiska områden och organisationer. Data Commons, Googles strukturerade offentliga dataprojekt, samlar data från myndigheter och organisationer som FN och EU, och tillhandahåller statistik och demografisk information. Väder- och luftkvalitetsdata hämtas från nationella och internationella meteorologiska myndigheter, vilket möjliggör Googles “nowcast”-väderfunktioner. Licensierad privat data kompletterar kunskapsgrafen med information som ofta ändras eller kräver särskild expertis. Google licensierar finansiell marknadsdata från leverantörer som Morningstar, S&P Global och Intercontinental Exchange för att driva funktioner för aktiekurser och marknadsinformation. Sportdata kommer från samarbeten med ligor, lag och aggregatorer som Stats Perform och ger realtidsresultat och historisk statistik. Strukturerad data från webbplatser bidrar avsevärt till berikningen av kunskapsgrafen. När webbplatser implementerar Schema.org-märkning ger de explicit semantisk information som Google kan extrahera och använda. Därför är korrekt implementering av strukturerad data—Organization schema, LocalBusiness schema, FAQPage schema och andra relevanta märken—avgörande för varumärken som vill påverka sin representation i kunskapsgrafen. Google Books-data från över 40 miljoner skannade och digitaliserade böcker tillför historisk kontext, biografisk information och detaljerade beskrivningar som förstärker entitetskunskapen. Användarfeedback och anspråkade kunskapspaneler gör det möjligt för individer och organisationer att direkt påverka informationen i kunskapsgrafen. När användare skickar in feedback om kunskapspaneler eller när auktoriserade representanter anspråkar och uppdaterar paneler behandlas denna information och kan leda till uppdateringar i kunskapsgrafen. Detta “human-in-the-loop”-tillvägagångssätt säkerställer att kunskapsgrafen förblir korrekt och representativ, även om Googles automatiserade system har sista ordet om vad som visas.
Google har uttryckligen sagt att de prioriterar information från källor som uppvisar hög E-E-A-T (Experience, Expertise, Authoritativeness och Trustworthiness) vid skapande och uppdatering av kunskapsgrafen. Sambandet mellan E-E-A-T och inkludering i kunskapsgrafen är ingen slump—det speglar Googles bredare åtagande att lyfta fram pålitlig, auktoritativ information. Om ditt webbplatsinnehåll visas i SERP-funktioner som drivs av kunskapsgrafen är det ofta ett starkt tecken på att Google ser din sajt som auktoritativ inom ämnet. Omvänt, om ditt innehåll inte syns i kunskapsgrafbaserade funktioner, kan det tyda på E-E-A-T-problem som behöver åtgärdas. Att bygga E-E-A-T för synlighet i kunskapsgrafen kräver ett mångfacetterat tillvägagångssätt. Erfarenhet innebär att visa att du eller dina skribenter har verklig erfarenhet inom ämnet. För en hälsohemsida kan det betyda att lyfta fram innehåll från legitimerade läkare med många års klinisk erfarenhet. För ett teknikföretag betyder det att visa upp ingenjörers och forskares expertis kring de produkter ni diskuterar. Expertis handlar om att skapa djupt kunnigt innehåll som täcker ämnen omfattande och korrekt. Det går bortom ytliga förklaringar för att visa på genuin förståelse för nyanser, undantag och avancerade begrepp. Auktoritet innebär att bygga erkännande inom ditt område. Det kan ske genom utmärkelser, certifieringar, omnämnanden i media, föredrag och att bli citerad av andra auktoritativa källor. För organisationer handlar det om att etablera sitt varumärke som ledande inom branschen. Förtroende bygger på de övriga tre elementen och visas genom transparens, noggrannhet, korrekta källhänvisningar, tydlig författarskap och god kundservice. Organisationer som utmärker sig i E-E-A-T-signaler har större sannolikhet att få sin information inkluderad i kunskapsgrafen och synas i AI-genererade svar, vilket skapar en positiv spiral där auktoritet leder till synlighet som i sin tur stärker auktoriteten.
Framväxten av stora språkmodeller (LLM) och generativ AI har gett kunskapsgrafer ny betydelse i AI-ekosystemet. Även om LLM:er som ChatGPT, Claude och Perplexity inte tränas direkt på Googles proprietära kunskapsgraf, förlitar de sig allt mer på liknande strukturerad kunskap och semantisk förståelse. Många AI-system använder retrieval-augmented generation (RAG), där modellen frågar kunskapsgrafer eller strukturerade databaser vid inferenstid för att grunda svaren i faktabaserad information och minska hallucinationer. Offentligt tillgängliga kunskapsgrafer som Wikidata används för att finjustera modeller eller injicera strukturerad kunskap, vilket förbättrar deras förmåga att förstå entitetsrelationer och ge korrekta svar. För varumärken och organisationer innebär detta att optimering för kunskapsgrafer får betydelse även utanför det traditionella Googlesök. När användare frågar AI-system om din bransch, produkter eller organisation beror AI-systemets förmåga att ge korrekta svar delvis på hur väl din entitet är representerad i strukturerade kunskapskällor. En organisation med en väl underhållen Wikidata-post, anspråkad Google-kunskapspanel och konsekvent strukturerad data på sin webbplats har större chans att bli korrekt representerad i AI-genererade svar. Omvänt kan organisationer med ofullständig eller motstridig information mellan källor bli felrepresenterade eller förbisedda i AI-svar. Detta skapar en ny dimension av AI-synlighetsövervakning—att spåra inte bara hur ditt varumärke syns i traditionella sökresultat, utan hur det representeras i AI-genererade svar på flera plattformar. Verktyg och plattformar som bevakar varumärkens AI-närvaro fokuserar i ökande grad på att förstå entitetsrelationer och kunskapsgrafsrepresentation, eftersom dessa faktorer direkt påverkar AI-synligheten.
Organisationer som vill optimera sin närvaro i kunskapsgrafer bör följa ett systematiskt tillvägagångssätt som bygger på SEO-grunder och lägger till entitetspecifika strategier. Första steget är att implementera strukturerad datamärkning med Schema.org-vokabulär. Det innebär att lägga till JSON-LD, Microdata eller RDFa-markup på webbplatsen som tydligt beskriver organisationen, produkter, personer och andra relevanta entiteter. Viktiga schematyper inkluderar Organization (företagsinformation), LocalBusiness (platsbaserad information), Person (personprofiler), Product (produktinformation) och FAQPage (vanliga frågor). Efter implementering är det viktigt att testa och validera märkningen med Googles Structured Data Testing Tool för att säkerställa korrekt formatering och igenkänning. Andra steget är att granska och optimera Wikidata- och Wikipedia-information. Om din organisation eller nyckelentiteter har Wikipedia-sidor, se till att de är korrekta, omfattande och ordentligt källhänvisade. För Wikidata, kontrollera att din entitet finns och att dess egenskaper och relationer är korrekt representerade. Observera dock att redigering av Wikipedia eller Wikidata kräver noggrannhet och förståelse för deras policyer och normer—direkt egenreklam eller icke-deklarerade intressekonflikter kan leda till att ändringar tas bort och skada ditt rykte. Tredje steget är att anspråka och optimera din Google Business Profile (för lokala företag) och kunskapspaneler (för personer och organisationer). En anspråkad kunskapspanel ger större kontroll över hur din entitet visas i sökresultat och gör att du kan föreslå ändringar snabbare. Fjärde steget är att säkerställa konsekvens över alla egendomar—webbplats, Google Business Profile, sociala medieprofiler och tredjepartsregister. Motstridig information mellan källor förvirrar Googles system och kan hindra korrekt representation i kunskapsgrafen. Femte steget är att skapa entitetsfokuserat innehåll snarare än traditionellt nyckelordsfokuserat innehåll. Istället för att skriva artiklar kring nyckelord, organisera din innehållsstrategi kring entiteter och deras relationer. Till exempel, istället för att skriva separata artiklar om “bästa CRM-programvaran”, “Salesforce-funktioner” och “HubSpot-priser”, skapa ett omfattande innehållskluster som tydligt visar entitetsrelationer: Salesforce är en CRM-plattform, den konkurrerar med HubSpot, den integreras med Slack, osv. Detta entitetsbaserade tillvägagångssätt hjälper kunskapsgrafer att förstå ditt innehålls semantiska betydelse och relationer.
Kunskapsgrafer utvecklas snabbt som svar på framsteg inom artificiell intelligens, ändrat sökbeteende och framväxten av nya plattformar och teknologier. En viktig trend är utbredningen av multimodala kunskapsgrafer som integrerar text, bilder, ljud och videodata. I takt med att röst- och bildsök blir vanligare anpassar sig kunskapsgrafer för att förstå och representera information över flera modaliteter. Googles arbete med multimodal sök via produkter som Google Lens visar på denna utveckling—systemet måste förstå inte bara textfrågor utan även visuella indata, vilket kräver kunskapsgrafer som kan representera och koppla information över olika medietyper. En annan viktig utveckling är den ökande sofistikeringen inom semantisk berikning och naturlig språkbehandling vid konstruktion av kunskapsgrafer. I takt med att NLP-förmågor förbättras kan kunskapsgrafer extrahera mer nyanserade semantiska relationer från ostrukturerad text, vilket minskar beroendet av manuellt kuraterad eller explicit markerad data. Detta innebär att organisationer med högkvalitativt, välskrivet innehåll kan få sin information inkluderad i kunskapsgrafer även utan explicit strukturerad datamärkning, även om märkning fortfarande är viktig för korrekt representation. Integrationen av kunskapsgrafer med stora språkmodeller och generativ AI representerar kanske den största utvecklingen. I takt med att AI-system får en alltmer central roll för informationssökning, sträcker sig betydelsen av kunskapsgrafoptimering bortom traditionell sök till att omfatta AI-synlighet över flera plattformar. Organisationer som förstår och optimerar för kunskapsgrafer kommer ha fördelar både i traditionell sök och AI-genererade svar. Dessutom speglar ökningen av företagsinterna kunskapsgrafer en växande insikt om att principerna för kunskapsgrafer gäller även för intern kunskapshantering i organisationer. Företag bygger interna kunskapsgrafer för att bryta ner datasilos, förbättra beslutsfattande och möjliggöra bättre AI-applikationer. Denna trend tyder på att kunskapsgraflitteracitet blir allt viktigare för företagsledare, datavetare och marknadsförare. Slutligen får de regulatoriska och etiska dimensionerna av kunskapsgrafer ökad betydelse. Eftersom kunskapsgrafer påverkar hur information presenteras för miljarder användare får frågor om noggrannhet, partiskhet, representation och vem som styr kunskapsgrafinformation större uppmärksamhet. Organisationer bör vara medvetna om att deras entitetsrepresentation i kunskapsgrafer har verkliga konsekvenser för synlighet, rykte och affärsresultat, och bör närma sig optimering av kunskapsgrafer med samma noggrannhet och etik som andra delar av sin digitala närvaro.
En traditionell databas lagrar data i fasta, tabellbaserade format med fördefinierade scheman, medan en kunskapsgraf organiserar information som sammankopplade noder och kanter som representerar enheter och deras semantiska relationer. Kunskapsgrafer är mer flexibla, självbeskrivande och bättre lämpade för att förstå komplexa relationer mellan olika datatyper. De gör det möjligt för system att förstå betydelse och kontext, inte bara matcha nyckelord, vilket gör dem idealiska för AI- och semantiska sökapplikationer.
Google använder sin kunskapsgraf för att driva flera SERP-funktioner, inklusive kunskapspaneler, AI-översikter, rutor med 'People Also Ask' och förslag på relaterade entiteter. I maj 2024 innehöll Googles kunskapsgraf över 1,6 biljoner fakta om 54 miljarder enheter. När en användare söker identifierar Google vilken entitet de letar efter och visar relevant, sammankopplad information från kunskapsgrafen, vilket hjälper användare att hitta 'saker, inte strängar' som Google beskriver det.
Kunskapsgrafer samlar data från flera källor, inklusive open source-projekt som Wikipedia och Wikidata, myndighetsdatabaser som CIA World Factbook, licensierad privat data för finansiell och sportinformation, strukturerad datamärkning från webbplatser med Schema.org, Google Books-data och användarfeedback via korrigeringar i kunskapspaneler. Detta tillvägagångssätt med flera källor säkerställer omfattande och korrekt entitetsinformation över miljarder fakta.
Kunskapsgrafer påverkar direkt hur varumärken syns i sökresultat och AI-system genom att etablera entitetsrelationer och kopplingar. Varumärken som optimerar sin entitetsnärvaro genom strukturerad data, anspråkade kunskapspaneler och konsekvent information över källor får bättre synlighet i AI-genererade svar. Att förstå relationerna i kunskapsgrafer hjälper varumärken att övervaka sin närvaro i AI-system som ChatGPT, Perplexity och Claude, vilka alltmer förlitar sig på strukturerad entitetsinformation.
Semantisk berikning är processen där maskininlärning och naturlig språkbehandling (NLP) analyserar data för att identifiera individuella objekt och förstå relationer mellan dem. Denna process gör att kunskapsgrafer kan gå bortom enkel nyckelordsmatchning och förstå betydelse och kontext. När data matas in känner semantisk berikning automatiskt igen entiteter, deras attribut och hur de relaterar till andra entiteter, vilket möjliggör mer intelligenta sök- och frågesvarsfunktioner.
Organisationer kan optimera för kunskapsgrafer genom att implementera strukturerad datamärkning med Schema.org, upprätthålla konsekvent information över alla egendomar (webbplats, Google Business Profile, sociala medier), anspråka och uppdatera kunskapspaneler, bygga starka E-E-A-T-signaler via auktoritativt innehåll och säkerställa datakvalitet över källor. Att skapa entitetsfokuserade innehållskluster istället för traditionella nyckelordskluster hjälper också till att etablera starkare entitetsrelationer som kunskapsgrafer kan känna igen och utnyttja.
Kunskapsgrafer ger den semantiska grunden för AI-översikter genom att hjälpa AI-system att förstå entitetsrelationer och kontext. När söksammanfattningar genereras använder AI-system kunskapsgrafdata för att identifiera relevanta entiteter, förstå deras kopplingar och syntetisera information från flera källor. Detta möjliggör mer exakta, kontextuella svar som går bortom enkel nyckelordsmatchning, vilket gör kunskapsgrafer till grundläggande infrastruktur för moderna generativa sökupplevelser.
En kunskapsgraf är ett designmönster och ett semantiskt lager som definierar hur entiteter och relationer modelleras och förstås, medan en grafdatabas är den tekniska infrastrukturen som används för att lagra och fråga denna data. Kunskapsgrafer fokuserar på betydelse och semantiska relationer, medan grafdatabaser fokuserar på effektiv lagring och hämtning. En kunskapsgraf kan implementeras med olika grafdatabaser som Neo4j, Amazon Neptune eller RDF triple stores, men själva kunskapsgrafen är den konceptuella modellen.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Upptäck vad kunskapsgrafer är, hur de fungerar och varför de är avgörande för modern datalagring, AI-tillämpningar och affärsanalys.
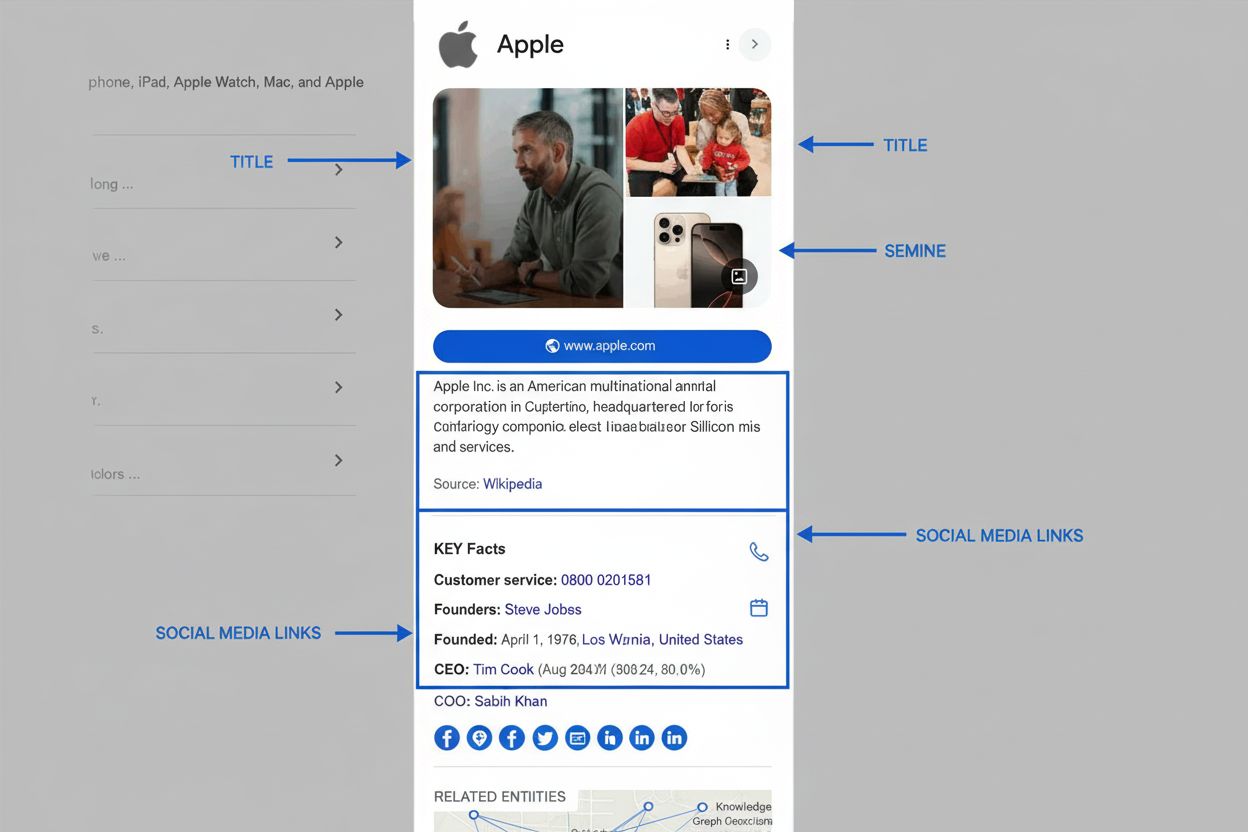
Lär dig vad en kunskapspanel är, hur den fungerar, varför den är viktig för SEO och AI-övervakning samt hur du kan göra anspråk på eller optimera en för ditt va...
Diskussion i communityn som förklarar Knowledge Graphs och deras betydelse för synlighet i AI-sök. Experter delar med sig av hur entiteter och relationer påverk...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.