
Meta AI-optimering: Facebooks och Instagrams AI-assistent
Upptäck hur Meta AI-optimering förändrar annonsering på Facebook och Instagram med AI-driven automatisering, realtidsbudgivning och intelligent målgruppsinriktn...
6 min läsning
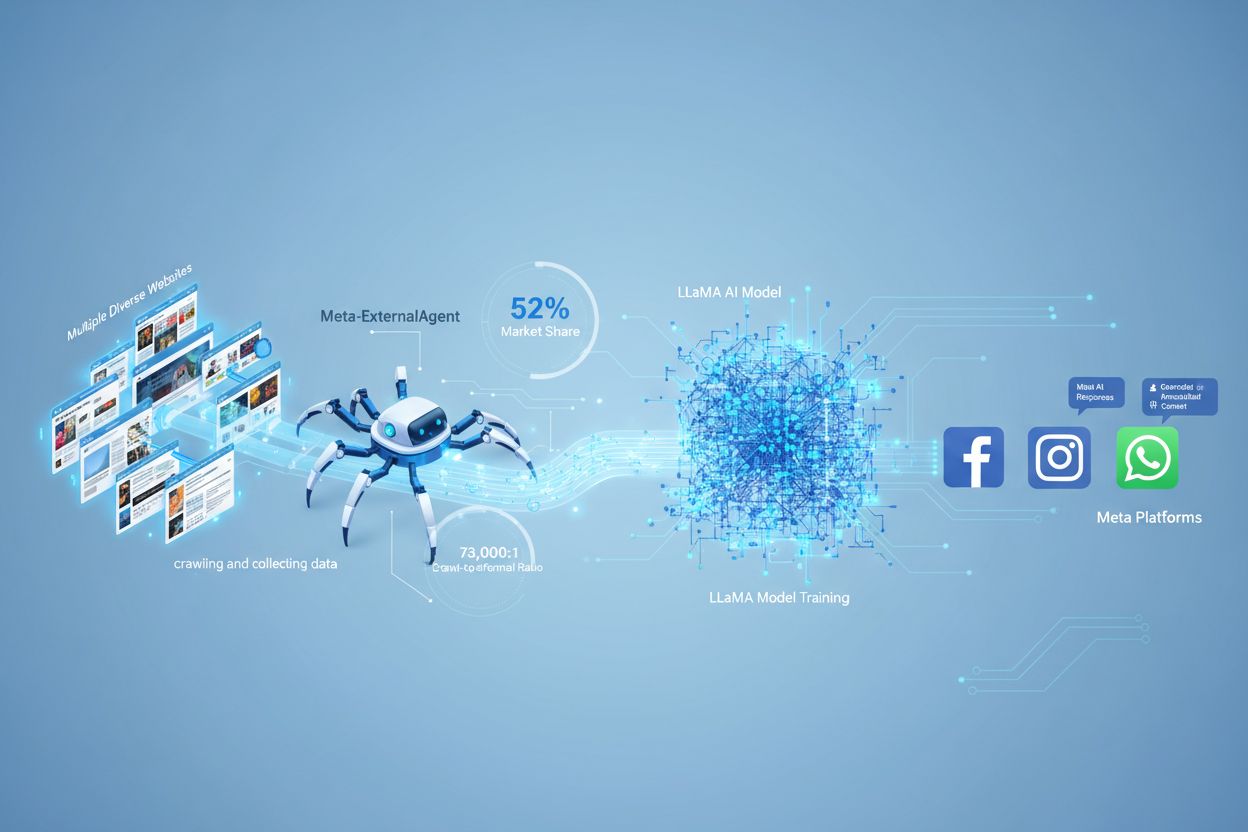
Meta-ExternalAgent är Metas webb-crawler-bot som lanserades i juli 2024 för att samla in offentligt tillgängligt innehåll för träning av AI-modeller som LLaMA. Den identifierar sig med User-Agent-strängen meta-externalagent/1.1 och styr om innehåll visas i Meta AI-svar på Facebook, Instagram och WhatsApp. Publicister kan blockera den via robots.txt eller serverkonfigurationer, även om efterlevnaden är frivillig och inte juridiskt bindande.
Meta-ExternalAgent är Metas webb-crawler-bot som lanserades i juli 2024 för att samla in offentligt tillgängligt innehåll för träning av AI-modeller som LLaMA. Den identifierar sig med User-Agent-strängen meta-externalagent/1.1 och styr om innehåll visas i Meta AI-svar på Facebook, Instagram och WhatsApp. Publicister kan blockera den via robots.txt eller serverkonfigurationer, även om efterlevnaden är frivillig och inte juridiskt bindande.
Meta-ExternalAgent är en webb-crawler som drivs av Meta Platforms och lanserades i juli 2024 för att samla in data för träning av artificiella intelligensmodeller. Crawlern identifierar sig med User-Agent-strängen meta-externalagent/1.1 och skiljer sig från Metas äldre facebookexternalhit-crawler, som främst användes för länkförhandsvisningar och funktioner för social delning. Meta-ExternalAgent markerar en betydande förändring i hur Meta samlar in träningsdata för sina AI-initiativ, inklusive LLaMA-språkmodellerna och Meta AI-chatboten som är integrerad på Facebook, Instagram och WhatsApp. Till skillnad från tidigare Meta-crawlers opererar denna agent med minimal transparens och introducerades utan något formellt offentligt tillkännagivande.

Meta-ExternalAgent fungerar som en automatiserad bot som systematiskt crawlar webbplatser över hela internet för att extrahera text och innehåll för AI-modellträning. Crawlern skickar HTTP-förfrågningar till webbservrar, identifierar sig via sin unika User-Agent-header och laddar ner sidinnehåll för bearbetning. När innehållet har samlats in analyserar och tokeniserar Metas system texten och omvandlar den till träningsdata som förbättrar deras stora språkmodeller. Crawlern respekterar filen robots.txt på frivillig basis, men detta bygger på ett hederssystem snarare än ett juridiskt krav. Enligt Cloudflare-data står Meta-ExternalAgent för cirka 52 % av all AI-crawlertrafik på internet, vilket gör den till en av de mest aggressiva datainsamlingsoperationerna i AI-branschen. Crawlern arbetar kontinuerligt och vissa publicister rapporterar crawl-frekvenser som tyder på att Meta prioriterar heltäckande täckning av webb-innehåll framför selektiv, riktad insamling.
| Crawler-namn | User-Agent-sträng | Huvudsakligt syfte | Lanseringsdatum | Användning av data |
|---|---|---|---|---|
| Meta-ExternalAgent | meta-externalagent/1.1 | AI-modellträning (LLaMA, Meta AI) | Juli 2024 | Träningsdata för generativ AI |
| facebookexternalhit | facebookexternalhit/1.1 | Länkförhandsvisningar och social delning | ~2010 | Open Graph-metadata, miniatyrbilder |
| Facebot | facebot/1.0 | Facebook-appinnehållsverifiering | ~2015 | Innehållsvalidering för mobilappar |
| Applebot | Applebot/0.1 | Apple Siri och sökindexering | ~2015 | Sökindexering och röstassistent |
| Googlebot | Googlebot/2.1 | Google-sökindexering | ~1998 | Bygga sökmotorindex |
Meta-ExternalAgent är en kritisk fråga för innehållsskapare och publicister eftersom den opererar i oöverträffad skala samtidigt som den ger minimal insyn i hur innehållet används. Enligt Cloudflare-forskning står Meta-ExternalAgent för 52 % av all AI-crawlertrafik, vilket vida överstiger konkurrenter som OpenAIs GPTBot och Googles AI-crawlers. Denna dominans innebär att Meta samlar in mer träningsdata än något annat AI-företag, samtidigt som publicister inte får någon ersättning eller attribution när deras innehåll används för att träna Metas AI-modeller. Det 73 000:1 crawl-to-referral-förhållandet visar att Meta extraherar enorma mängder innehåll men skickar nästan ingen trafik tillbaka till ursprungssidorna—en grundläggande obalans i värdeutbytet. Trots dessa farhågor blockerar endast 2 % av webbplatserna aktivt Meta-ExternalAgent, jämfört med 25 % som blockerar GPTBot, vilket antyder att många publicister är omedvetna om crawlerns närvaro eller dess konsekvenser. Med Meta som investerar 40 miljarder dollar i AI-infrastruktur är företagets satsning på aggressiv datainsamling sannolikt att intensifieras, vilket gör det avgörande för publicister att förstå och aktivt hantera sin relation till denna crawler.
Publicister kan kontrollera Meta-ExternalAgents åtkomst via filen robots.txt, men det är viktigt att förstå att detta är en frivillig mekanism och inte juridiskt bindande. För att blockera Meta-ExternalAgent, lägg till följande direktiv i din robots.txt-fil:
User-agent: meta-externalagent
Disallow: /
Alternativt, om du vill tillåta crawlern men begränsa den till specifika kataloger, kan du använda:
User-agent: meta-externalagent
Disallow: /private/
Disallow: /admin/
Allow: /public/
Dock har vissa publicister rapporterat att Meta-ExternalAgent fortsätter att crawla deras sajter även efter att de har infört robots.txt-blockeringar, vilket tyder på att Meta inte alltid följer dessa direktiv. För mer heltäckande skydd kan publicister implementera blockering baserad på HTTP-headers eller använda Content Delivery Network (CDN)-regler för att identifiera och avvisa förfrågningar från Meta-ExternalAgent baserat på User-Agent-strängen. Dessutom kan publicister övervaka sina serverloggar efter User-Agent-strängen meta-externalagent/1.1 för att verifiera om crawlern har åtkomst till deras innehåll. Verktyg som AmICited.com kan hjälpa publicister att spåra om deras innehåll citeras eller refereras i Meta AI-svar, vilket ger insyn i hur deras arbete används av Metas AI-system.

När användare interagerar med Meta AI-chatbots på Facebook, Instagram eller WhatsApp baseras de genererade svaren delvis på innehåll som samlats in av Meta-ExternalAgent. Men Meta AI-svar innehåller vanligtvis inte synliga citat eller attribution till ursprungssidor, vilket innebär att användare kanske inte vet vilka publicisters innehåll som bidrog till svaret de fick. Denna brist på transparens skapar en betydande utmaning för innehållsskapare som vill förstå vilket värde deras arbete tillför Metas AI-system. Till skillnad från vissa konkurrenter som inkluderar citat i AI-genererade svar prioriterar Meta användarupplevelsen framför attribution till publicister. Avsaknaden av synliga citat innebär också att publicister inte enkelt kan spåra hur ofta deras innehåll påverkar Meta AI-svar, vilket gör det svårt att bedöma affärseffekten av att innehåll används för AI-träning. Denna synlighetslucka är en av de främsta anledningarna till att övervakningslösningar har blivit allt viktigare för publicister som vill förstå sin roll i AI-ekosystemet.
Publicister kan verifiera Meta-ExternalAgents aktivitet genom analys av serverloggar, vilket visar crawlerns IP-adresser, förfrågningsmönster och åtkomstfrekvens till innehåll. Genom att granska accessloggar kan publicister identifiera förfrågningar med User-Agent-strängen meta-externalagent/1.1 och avgöra vilka sidor som crawlas mest frekvent. Avancerade övervakningsverktyg kan följa crawlmönster över tid och avslöja om Meta prioriterar vissa innehållstyper eller sektioner av en webbplats. Publicister bör också övervaka bandbreddsanvändning, eftersom aggressiv crawlning från Meta-ExternalAgent kan förbruka betydande serverresurser, särskilt för webbplatser med stora innehållsbibliotek. Dessutom kan publicister använda verktyg som AmICited.com för att övervaka om deras innehåll dyker upp i Meta AI-svar och följa citatmönster över Metas plattformar. Att sätta upp aviseringar för ovanlig crawl-aktivitet kan hjälpa publicister att upptäcka förändringar i Metas datainsamlingsbeteende och agera proaktivt. Regelbundna revisioner av serverloggar bör ingå i varje publicists strategi för AI-crawlerhantering, för att säkerställa att de har koll på hur deras innehåll nås och används.
Den juridiska statusen för Meta-ExternalAgent är omtvistad, med pågående rättsprocesser från innehållsskapare, konstnärer och publicister som ifrågasätter Metas rätt att använda deras arbete för AI-träning utan uttryckligt samtycke eller ersättning. Meta hävdar att webb-crawlning omfattas av fair use-doktrinen, medan kritiker menar att insamlingens omfattning och kommersiella natur, i kombination med brist på attribution, utgör upphovsrättsintrång. Filen robots.txt, även om den är allmänt respekterad som branschstandard, har ingen juridisk verkan, vilket innebär att Meta inte är juridiskt skyldiga att följa blockeringar. Flera jurisdiktioner utvecklar regler kring insamling av AI-träningsdata, där EU:s AI Act och föreslagen lagstiftning i andra regioner potentiellt kan ställa striktare krav på företag som Meta. Ur ett etiskt perspektiv handlar den grundläggande frågan om innehållsskapare ska ha rätt att kontrollera hur deras arbete används för kommersiell AI-träning, och om det nuvarande systemet tillräckligt kompenserar skapare för det värde deras innehåll ger. Publicister bör hålla sig informerade om föränderliga lagar och överväga att konsultera juridisk expertis om sina rättigheter och skyldigheter kring AI-crawleråtkomst. Balansen mellan att möjliggöra AI-innovation och att skydda skaparrättigheter är fortfarande olöst och detta område utvecklas snabbt juridiskt och regulatoriskt.
Landskapet för AI-crawlerhantering utvecklas snabbt i takt med att publicister, tillsynsmyndigheter och AI-företag förhandlar om villkoren för datainsamling och användning. Metas aggressiva utrullning av Meta-ExternalAgent signalerar att stora teknikbolag ser webb-innehåll som avgörande träningsmaterial för konkurrenskraftiga AI-system, och denna trend lär accelerera i takt med att AI-förmågor blir allt mer centrala för affärsstrategier. Framtida utveckling kan inkludera starkare juridiskt skydd för skapare, obligatoriska licensramverk för AI-träningsdata och tekniska standarder som gör det enklare för publicister att kontrollera och tjäna pengar på sitt innehålls användning i AI-system. Framväxten av verktyg som AmICited.com speglar det ökade behovet av transparens och ansvar i hur AI-system använder publicerat innehåll, vilket antyder att övervakning och verifiering blir standardpraxis för innehållsskapare. I takt med att AI-branschen mognar kan vi förvänta oss mer sofistikerade förhandlingar mellan innehållsskapare och AI-företag, vilket potentiellt leder till nya affärsmodeller som rättvist kompenserar publicister för deras bidrag till AI-träning.
Meta-ExternalAgent är Metas dedikerade AI-träningscrawler som lanserades i juli 2024 och identifieras av User-Agent-strängen meta-externalagent/1.1. Den skiljer sig från facebookexternalhit, som genererar länkförhandsvisningar för social delning. Meta-ExternalAgent samlar specifikt in innehåll för att träna LLaMA-modeller och Meta AI, medan facebookexternalhit har använts för sociala funktioner sedan cirka 2010.
Du kan blockera Meta-ExternalAgent genom att lägga till direktiv i din robots.txt-fil. Lägg till 'User-agent: meta-externalagent' följt av 'Disallow: /' för att blockera den helt. För mer omfattande skydd, implementera servernivå-blockering med .htaccess (Apache) eller Nginx-konfigurationsregler. Observera dock att robots.txt är frivillig och inte juridiskt bindande, så vissa publicister rapporterar fortsatt crawlning trots blockeringar.
Nej, blockering av Meta-ExternalAgent påverkar inte Facebooks länkförhandsvisningar. Crawlern facebookexternalhit hanterar länkförhandsvisningar och sociala delningsfunktioner. Du kan blockera meta-externalagent samtidigt som facebookexternalhit fortsätter att generera attraktiva förhandsvisningar när ditt innehåll delas på Metas plattformar.
Meta-ExternalAgent har ett crawl-to-referral-förhållande på cirka 73 000:1, vilket innebär att Meta extraherar innehåll i enorm skala samtidigt som nästan ingen trafik skickas tillbaka till källsidorna. Detta utgör en grundläggande obalans jämfört med traditionella sökmotorer, som crawlar innehåll i utbyte mot att driva hänvisningstrafik.
robots.txt bygger på förtroende och är inte juridiskt bindande. Även om många crawlers respekterar robots.txt-direktiv, har vissa publicister rapporterat att Meta-ExternalAgent fortsätter att crawla deras sajter trots uttryckliga robots.txt-blockeringar. För garanterat skydd, implementera servernivå-blockering med HTTP-headers, CDN-regler eller brandväggskonfigurationer.
Kontrollera dina serveraccessloggar efter förfrågningar med User-Agent-strängen 'meta-externalagent/1.1'. Du kan också använda övervakningsverktyg som AmICited.com för att spåra om ditt innehåll visas i Meta AI-svar. Verktyg som Dark Visitors och Cloudflare Analytics ger ytterligare insikt i AI-crawleraktivitet på din webbplats.
Enligt Cloudflare-data står Meta-ExternalAgent för cirka 52 % av all AI-crawlertrafik på internet, vilket gör den till den mest aggressiva AI-datainsamlingsoperationen. Detta överstiger klart konkurrenter som OpenAIs GPTBot och Googles AI-crawlers, vilket visar Metas dominerande position inom insamling av webb-innehåll för AI-träning.
Beslutet beror på dina affärsprioriteringar. Om Meta AI-trafik är värdefull för din publik kan du tillåta det. Tänk dock på att Meta inte ger någon ersättning eller attribution för innehåll som används i AI-träning. Många publicister tillämpar selektiva blockeringsstrategier som stoppar AI-träning men behåller förhandsvisningsfunktioner för social delning.
Följ hur ditt innehåll visas i Meta AI-svar på Facebook, Instagram och WhatsApp. Få insyn i AI-citat och förstå din varumärkesnärvaro i AI-genererade svar.
Upptäck hur Meta AI-optimering förändrar annonsering på Facebook och Instagram med AI-driven automatisering, realtidsbudgivning och intelligent målgruppsinriktn...

Förstå hur AI-crawlers som GPTBot och ClaudeBot fungerar, deras skillnader från traditionella sökmotor-crawlers och hur du optimerar din webbplats för synlighet...
Meta AI är Metas AI-assistent integrerad i Facebook, Instagram, WhatsApp och Messenger. Lär dig hur den fungerar, dess kapabiliteter och dess roll i AI-övervakn...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.