
Promptbibliotek för manuell AI-synlighetstestning
Lär dig hur du bygger och använder promptbibliotek för manuell AI-synlighetstestning. Gör-det-själv-guide till att testa hur AI-system refererar till ditt varum...
10 min läsning
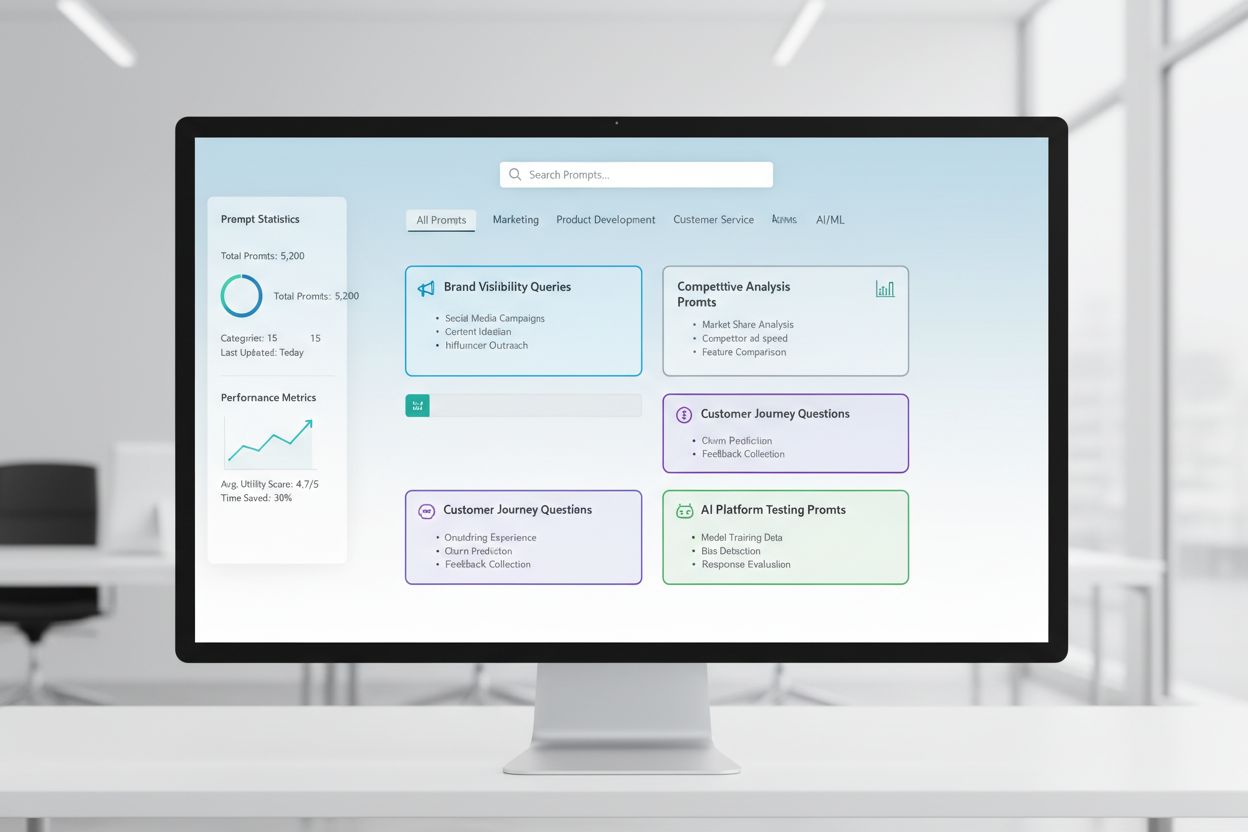
Utveckling av promptbibliotek är den systematiska processen att bygga och organisera omfattande samlingar av frågor avsedda att testa och övervaka hur varumärken syns på AI-drivna plattformar. Det etablerar en standardiserad ram för att utvärdera varumärkesexponering över flera AI-system, vilket möjliggör för organisationer att följa konkurrenspositionering och identifiera synlighetsluckor i AI-drivna sökningar.
Utveckling av promptbibliotek är den systematiska processen att bygga och organisera omfattande samlingar av frågor avsedda att testa och övervaka hur varumärken syns på AI-drivna plattformar. Det etablerar en standardiserad ram för att utvärdera varumärkesexponering över flera AI-system, vilket möjliggör för organisationer att följa konkurrenspositionering och identifiera synlighetsluckor i AI-drivna sökningar.
Utveckling av promptbibliotek är den systematiska processen att bygga och organisera omfattande samlingar av frågor avsedda att testa och övervaka hur varumärken syns på AI-drivna plattformar. Ett promptbibliotek fungerar som ett strukturerat arkiv av noggrant utformade frågor, söktermer och konversationella prompts som simulerar verkliga användarinteraktioner med AI-system som ChatGPT, Claude, Gemini och Perplexity. Begreppet “bibliotek” återspeglar den organiserade, katalogiserade karaktären hos dessa samlingar—på samma sätt som traditionella bibliotek organiserar information efter ämne, kategori och relevans. Till skillnad från ad hoc-testning etablerar utveckling av promptbibliotek en standardiserad ram för att utvärdera varumärkesexponering, vilket säkerställer konsekvent mätning över flera AI-plattformar och tidsperioder. Detta tillvägagångssätt erkänner att AI-system svarar olika på olika formuleringar, kontexter och intentioner, vilket gör det nödvändigt att testa ett brett utbud av prompts istället för att förlita sig på enstaka frågor. Biblioteket fungerar både som testinstrument och historiskt arkiv, vilket gör det möjligt för organisationer att följa hur deras varumärkesexponering utvecklas i takt med att AI-modeller uppdateras och användarbeteenden förändras. Genom att behandla prompttestning som en förvaltad disciplin istället för en tillfällig aktivitet får företag handlingsbara insikter om sin konkurrensposition på den AI-drivna sökmarknaden.
| Aspekt | Traditionell SEO-uppföljning | Promptbibliotekets tillvägagångssätt |
|---|---|---|
| Testomfattning | Begränsad till sökmotorns nyckelord | Omfattande testning över flera AI-plattformar med varierande formuleringar |
| Frågevariation | Fasta nyckelordslistor | Dynamiska, intentionsbaserade prompts som speglar naturliga samtal |
| Mätningsfrekvens | Månads- eller kvartalsvisa ögonblicksbilder | Kontinuerlig eller veckovis övervakning med detaljerad trendanalys |
| Konkurrensinsikt | Nyckelordspositioner | Frekvens av varumärkesnämningar, kontextkvalitet och positioneringsprecision |
Skiftet mot AI-drivet informationssökande har fundamentalt förändrat hur varumärken måste arbeta med synlighetsövervakning. Traditionell SEO-uppföljning fokuserar på nyckelordsplaceringar i sökmotorernas resultat, men denna metod fångar inte hur varumärken syns när användare interagerar konversationellt med AI-system. Promptbibliotek löser detta genom att organisationer får förståelse för deras närvaro på en helt ny kategori av upptäcktsplattformar. Affärsvärdet är stort: företag som systematiskt övervakar sin AI-synlighet får konkurrensfördelar genom att identifiera luckor i varumärkesrepresentation, upptäcka vilka ämnen eller sammanhang som triggar varumärkesnämningar samt förstå hur AI-system karaktäriserar deras produkter jämfört med konkurrenter. Denna insikt informerar direkt innehållsstrategi, produktpositionering och budskap. Organisationer som använder promptbibliotek kan upptäcka nya konkurrenshot snabbare än de som enbart litar på traditionella SEO-mått, eftersom AI-system ofta lyfter fram andra konkurrenter än sökmotorer. Dessutom avslöjar testning med promptbibliotek nyanserade insikter om varumärkesuppfattning—inte bara om ett varumärke syns, utan hur det beskrivs, vilka attribut som förknippas med det och om AI-systemets beskrivning stämmer överens med varumärkets avsedda positionering.
Att skapa ett effektivt promptbibliotek kräver en strukturerad metodik som kombinerar kundundersökningar, konkurrentanalys och strategisk planering:
Genomför kundundersökningar: Intervjua målgruppen, analysera supportärenden och granska sociala medier för att identifiera de faktiska frågor och språkbruk användare har när de söker information om din kategori. Det säkerställer att dina prompts speglar verklig användarintention och inte interna antaganden.
Kartlägg kundresan: Identifiera viktiga beslutspunkter och informationsbehov under medvetenhet, övervägande och beslutsstadier. Utveckla prompts som motsvarar varje steg och fångar hur kunder söker information vid olika tillfällen i köpprocessen.
Definiera intentionskategorier: Organisera prompts efter intention—informativ (lära sig om en kategori), jämförande (utvärdera alternativ), transaktionell (redo att köpa) samt varumärkesspecifik (direkt sökande efter ditt företag). Denna struktur säkerställer heltäckande täckning av hur användare kan upptäcka ditt varumärke.
Skapa promptvariationer: Utveckla flera formuleringar för varje kärnfråga för att ta hänsyn till hur olika användare kan uttrycka samma behov. Inkludera variationer i formalitet, specifikhet och kontext för att spegla verklig mångfald i interaktioner med AI-system.
Etablera grundläggande prompts: Ta fram en kärna av 20–50 viktiga prompts som representerar dina mest kritiska exponeringsmöjligheter. Dessa blir din grund för kontinuerlig övervakning och jämförelse över tid.
Dokumentera promptmetadata: För varje prompt, notera intentionskategori, kundresesteg, prioritet och förväntad varumärkesrelevans. Denna metadata möjliggör avancerad analys och hjälper till att identifiera mönster där ditt varumärke syns eller saknas.
Validera med intressenter: Gå igenom ditt promptbibliotek med försäljning, marknadsföring och produktteam för att säkerställa att det speglar de frågor och scenarier som är mest relevanta för affärsmålen.
Ett omfattande promptbibliotek är strukturerat kring flera dimensioner som säkerställer heltäckande mätning av varumärkesexponering. Biblioteket innehåller vanligtvis trattstegsprompts som följer kundresan: TOFU (Top of Funnel)-prompts täcker breda informationssökande frågor där användare lär sig om en kategori eller problem, exempelvis “Vilka är de bästa projektledningsverktygen?” eller “Hur förbättrar jag samarbete i team?” MOFU (Middle of Funnel)-prompts fokuserar på jämförande och utvärderande frågor där användare aktivt överväger alternativ, såsom “Jämför projektledningsprogram för distansteam” eller “Vilka funktioner ska jag leta efter i en samarbetsplattform?” BOFU (Bottom of Funnel)-prompts riktar sig mot beslutsfrågor där användare är redo att köpa eller implementera, till exempel “Varför ska jag välja [Varumärke] framför konkurrenter?” eller “Vad är [Varumärkes] prissättningsmodell?” Utöver trattsteg organiserar effektiva bibliotek prompts efter intentionskategorier—informativa, navigationsbaserade, jämförande och transaktionella—så att synligheten mäts över olika användarbehov. Bibliotek inkluderar även kontextuella variationer som testar hur varumärkesexponering förändras beroende på bransch, användningsområde, företagets storlek eller geografisk plats. Välutformade bibliotek innehåller dessutom konkurrensprompts som visar hur ditt varumärke syns i direkt jämförelse med specifika konkurrenter samt attributbaserade prompts som testar synlighet för specifika produktfunktioner, fördelar eller unika egenskaper. Denna multidimensionella struktur säkerställer att övervakningen fångar hela spektrumet av hur potentiella kunder kan upptäcka och utvärdera ditt varumärke genom AI-system.
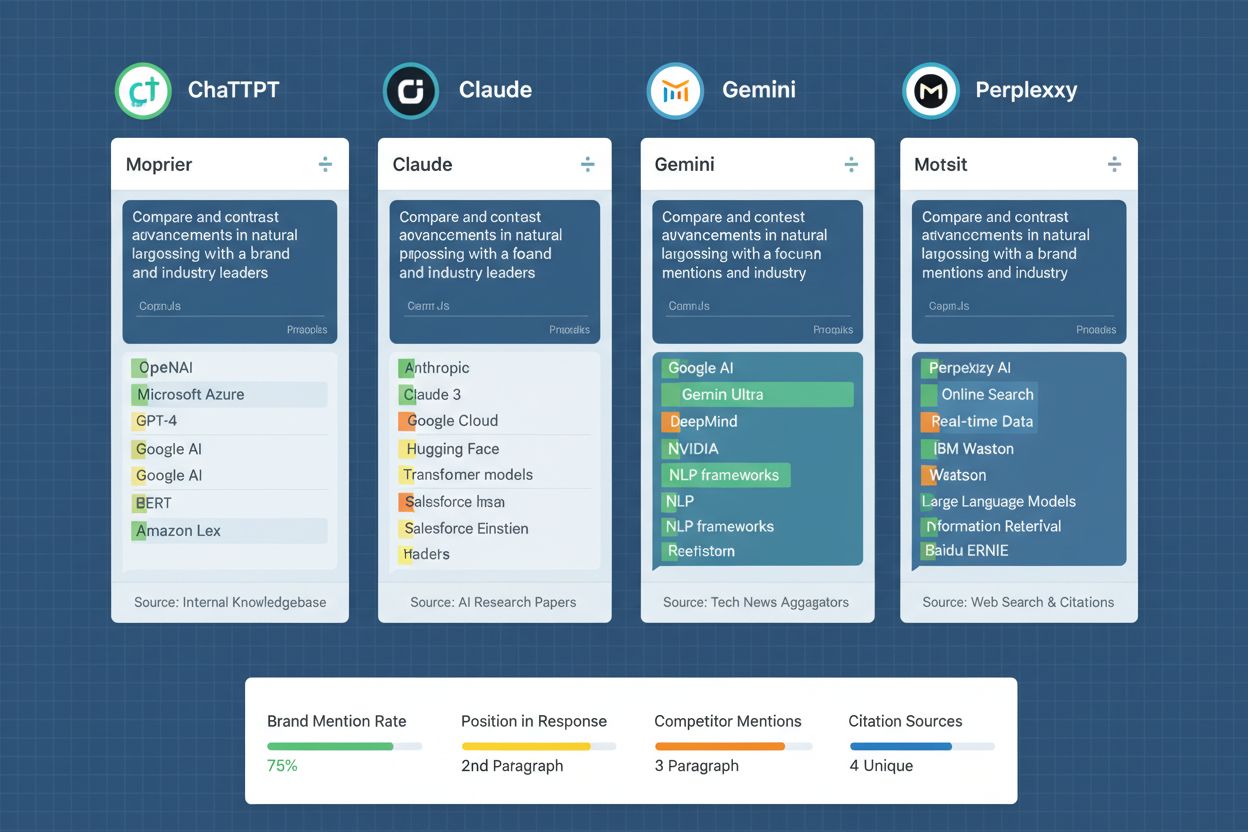
Att genomföra ett promptbibliotek över flera AI-plattformar kräver systematiska processer för datainsamling, analys och tolkning. Organisationer testar vanligtvis sitt promptbibliotek mot ChatGPT (det mest använda AI-systemet), Claude (känd för detaljerade och nyanserade svar), Gemini (Googles AI med integrerad sökfunktion) och Perplexity (en AI-sökmotor med citeringsfunktioner). Testfrekvensen styrs av affärsprioriteringar och resurser—många organisationer genomför veckovisa eller tvåveckors testcykler för att upptäcka förändringar i varumärkesexponering, medan andra implementerar kontinuerlig övervakning via automatiserade verktyg. För varje prompt registrerar testare om varumärket nämns, sammanhang och positionering för nämningen, informationsprecision samt hur framstående nämningen är jämfört med konkurrenter. Datainsamlingen går längre än enkla ja/nej-nämningar och inkluderar kvalitativ bedömning av hur varumärket beskrivs—om beskrivningarna är korrekta, om nyckeldifferentierare lyfts fram och om AI-systemets svar stämmer överens med varumärkets avsedda positionering. Analysen innebär att följa trender över tid för att se om varumärkesexponeringen förbättras eller försämras, koppla förändringar till innehållsuppdateringar eller konkurrensaktiviteter samt identifiera mönster i vilka prompts som genererar nämningar respektive där varumärket saknas. Organisationer skapar ofta dashboards som visualiserar denna data, vilket gör det lätt för intressenter att snabbt förstå trender och identifiera områden där innehåll eller strategi behöver justeras. Testfrekvens och djup bör anpassas efter hur snabbt AI-modeller och konkurrenslandskap förändras i din bransch.
| Verktygsnamn | Bäst för | Nyckelfunktioner | Startpris |
|---|---|---|---|
| AmICited.com | Omfattande AI-varumärkesövervakning | Multiplattformstestning, automatiserad promptkörning, konkurrensjämförelse, detaljerade analysdashboards, spårning av varumärkesnämningar | Anpassat pris |
| FlowHunt.io | Organisation och testning av promptbibliotek | Versionshantering av prompts, A/B-testning, prestationsanalys, samarbetsfunktioner för team, integration med stora AI-plattformar | Anpassat pris |
| Braintrust | Utvärdering och optimering av prompts | Automatiserad testning, prestationsbetyg, kostnadsspårning över modeller, detaljerad loggning och analys | Gratisnivå tillgänglig |
| LangSmith | Utveckling och övervakning av LLM-applikationer | Versionshantering av prompts, körningsspårning, prestationsmått, felsökningsverktyg, integration med LangChain-ekosystemet | Gratisnivå tillgänglig |
| Promptfoo | Open source-testning och utvärdering av prompts | Lokal testning, stöd för flera modeller, testning baserat på assertions, detaljerad rapportering, anpassningsbara utvärderingsmått | Open source (gratis) |
| Weights & Biases | Experimentspårning och modelevaluering | Omfattande loggning, visualisering, jämförelseverktyg, teamsamarbete, integration med ML-arbetsflöden | Gratisnivå tillgänglig |
Att hantera promptbibliotek i stor skala kräver specialiserade verktyg utformade för att hantera testning över flera AI-plattformar, följa resultat över tid och möjliggöra teamsamarbete. AmICited.com utmärker sig som den ledande plattformen specifikt framtagen för varumärkesövervakning över AI-system, med automatiserad promptkörning, konkurrensjämförelser och detaljerad analys som direkt möter behoven hos organisationer som följer varumärkespresens i AI-genererade svar. FlowHunt.io är det bästa valet för organisation och optimering av promptbibliotek, med avancerad versionshantering, A/B-testning och prestationsanalys som gör det möjligt för team att kontinuerligt förfina sina promptsamlingar. Braintrust är utmärkt för automatiserad utvärdering och betygsättning av promptprestanda, vilket är värdefullt för organisationer som systematiskt vill mäta vilka prompts som ger bäst varumärkesexponering. LangSmith, utvecklat av LangChain, erbjuder omfattande spårning och felsökning, särskilt användbart för team som bygger AI-applikationer där varumärkesövervakning ingår. Promptfoo är ett open source-alternativ för organisationer som föredrar lokal kontroll och anpassning, med starka assertionsbaserade testfunktioner. Weights & Biases erbjuder experimentspårning och visualisering på företagsnivå, användbart för team som driver storskaliga testinitiativ. Valet beror på om din organisation prioriterar användarvänlighet och varumärkesspecifika funktioner (AmICited.com, FlowHunt.io), kostnadseffektivitet (open source-alternativ) eller integration med befintliga utvecklingsflöden (LangSmith, Weights & Biases).
Att bibehålla ett effektivt promptbibliotek kräver kontinuerlig förfining och systematisk optimering. Organisationer bör etablera en regelbunden granskningscykel—vanligtvis kvartalsvis—för att utvärdera om prompts förblir relevanta för affärsprioriteringar, om nya kundfrågor eller marknadshändelser motiverar nya prompts samt om befintliga prompts bör tas bort eller ändras. Testfrekvensen bör balansera omfattning mot resurser; de flesta organisationer finner att veckovisa eller tvåveckors testcykler ger tillräckliga data för att upptäcka meningsfulla förändringar i varumärkesexponering utan att skapa ohållbar arbetsbörda. Prestandaspårning bör gå utöver enbart antal varumärkesnämningar till att inkludera kvalitativa mått som nämningskvalitet, positioneringsprecision och konkurrenskontext. Team bör dokumentera grundprestanda för varje prompt och etablera tydliga riktmärken för att mäta förbättring eller försämring. Om varumärkesexponeringen minskar för specifika prompts bör orsaken undersökas—är det externa faktorer (AI-modelluppdateringar, konkurrensaktiviteter, marknadsförändringar) eller interna (föråldrat innehåll, budskapsmissanpassning, tekniska problem)? Iterativ optimering innebär att testa promptvariationer för att identifiera vilka formuleringar som genererar mest korrekt eller framträdande varumärkesnämning, och sedan uppdatera biblioteket utifrån dessa insikter. Organisationer bör även införa en feedbackloop där insikter från prompttestning direkt påverkar innehållsstrategin, så att synlighetsluckor som identifieras genom testning adresseras genom innehållsskapande eller optimering. Dokumentation av promptprestanda, testmetodik och optimeringsbeslut bygger upp institutionell kunskap som möjliggör konsekvent genomförande och kontinuerlig förbättring över tid.
Utveckling av promptbibliotek fungerar som en avgörande del i en bredare AI-synlighet- och innehållsstrategi och informerar direkt hur varumärken positionerar sig i en AI-drivna informationsvärld. Insikterna som genereras genom systematisk prompttestning avslöjar skillnader mellan hur ett varumärke vill uppfattas och hur AI-system faktiskt karaktäriserar det, vilket möjliggör riktade innehålls- och budskapsjusteringar. När testning visar att ett varumärke saknas i AI-svar på relevanta frågor signalerar det en innehållsmöjlighet—organisationen bör då skapa innehåll som möter dessa specifika informationsbehov och kontexter. Om testningen däremot visar att varumärket syns men beskrivs felaktigt eller positioneras ogynnsamt jämfört med konkurrenter, krävs innehåll som korrigerar missuppfattningar eller stärker de viktigaste differentierarna. Data från promptbiblioteket stöder direkt konkurrensanalys genom att visa vilka konkurrenter som syns mest frekvent i AI-svar, hur konkurrenspositionering skiljer sig mellan plattformar och vilka attribut eller fördelar konkurrenterna betonar. Denna insikt påverkar produktpositionering, budskapsstrategi och innehållsprioriteringar. ROI:n av promptbiblioteksutveckling visar sig genom förbättrad varumärkesexponering i AI-system, mer korrekt representation av varumärkesegenskaper och fördelar, samt snabbare upptäckt av konkurrenshot eller marknadsförändringar. Organisationer som systematiskt övervakar och optimerar sin AI-synlighet med hjälp av promptbibliotek får konkurrensfördelar genom att säkerställa att deras varumärke syns i relevanta AI-genererade svar, att informationen är korrekt och positiv, och att deras positionering är i linje med marknadsmöjligheterna. Integration av promptbiblioteksinsikter i innehållsstrategi, produktutveckling och konkurrenspositionering skapar en feedbackloop där synlighetsövervakning direkt driver affärsstrategisk förfining.
Ett promptbibliotek fokuserar på att testa hur varumärken syns på AI-plattformar genom konversationsbaserade frågor, medan traditionell sökordsanalys riktar sig mot placeringar i sökmotorer. Promptbibliotek fångar hur AI-system tolkar och svarar på olika formuleringar, intentioner och kontextuella variationer—och ger insikter om varumärkesexponering i AI-genererade svar snarare än sökrankingar.
De flesta organisationer genomför veckovisa eller tvåveckors testcykler för att upptäcka meningsfulla förändringar i varumärkesexponering. Frekvensen beror på hur snabbt din bransch förändras, konkurrensaktivitet samt uppdateringar av AI-modeller. Veckotestning ger tillräckligt med data för att identifiera trender utan att skapa en ohållbar arbetsbörda.
Effektiva promptbibliotek innehåller vanligtvis 50–150 prompts, organiserade över trattsteg (TOFU, MOFU, BOFU) och intentionskategorier. Börja med 20–50 kärnprompts som representerar dina mest kritiska exponeringsmöjligheter och utöka därefter baserat på affärsprioriteringar, konkurrenslandskap och kundinsikter.
Testa mot ChatGPT (mest använda), Claude (detaljerade svar), Gemini (integrerad sökfunktion) och Perplexity (AI-sökmotor). Dessa fyra plattformar utgör majoriteten av AI-drivet upptäckande. Inkludera även andra plattformar som Google AI Översikter eller specialiserade AI-system relevanta för din bransch.
Effektivitet mäts genom hur ofta varumärket nämns, positioneringsprecision, konkurrenskontext och i vilken grad det stämmer överens med affärsmål. Följ om ditt varumärke syns i relevanta AI-svar, om beskrivningarna är korrekta samt om synlighetstrenderna förbättras över tid när du optimerar innehåll och strategi.
Ja. Plattformar som AmICited.com, Braintrust och LangSmith möjliggör automatiserad testning över flera AI-plattformar. Automatisering hanterar genomförande, datainsamling och grundläggande analys, vilket frigör tid för ditt team att fokusera på strategisk tolkning och optimering.
Testning av promptbibliotek avslöjar synlighetsluckor och felaktiga beskrivningar som direkt informerar innehållsprioriteringar. Om testning visar att ditt varumärke saknas i relevanta AI-svar, signalerar det en innehållsmöjlighet. Om det visar sig felaktiga beskrivningar, behöver du korrigerande innehåll.
ROI märks genom förbättrad varumärkesexponering i AI-system, mer korrekt varumärkesrepresentation, snabbare upptäckt av konkurrenshot och datadriven innehållsstrategi. Organisationer får konkurrensfördelar genom att säkerställa korrekt varumärkespositionering i AI-genererade svar, som i allt högre grad påverkar kundupptäckt och beslutsfattande.
Följ hur ditt varumärke syns i ChatGPT, Claude, Gemini, Perplexity och Google AI Översikter med AmICiteds omfattande plattform för AI-varumärkesövervakning.
Lär dig hur du bygger och använder promptbibliotek för manuell AI-synlighetstestning. Gör-det-själv-guide till att testa hur AI-system refererar till ditt varum...

Lär dig skapa och organisera ett effektivt promptbibliotek för att spåra ditt varumärke över ChatGPT, Perplexity och Google AI. Steg-för-steg-guide med bästa pr...
Prompt engineering är konsten att strukturera instruktioner för att styra generativa AI-modeller. Lär dig tekniker, bästa praxis och hur det påverkar AI-synligh...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.