Query Fanout: Hur LLM:er Genererar Flera Sökningar Bakom Kulisserna
Upptäck hur moderna AI-system som Google AI Mode och ChatGPT delar upp enskilda frågor i flera sökningar. Lär dig om query fanout-mekanismer, betydelsen för AI-...
8 min läsning
Query Fanout är AI-processen där en enskild användarfråga automatiskt utökas till flera relaterade underfrågor för att samla in omfattande information ur olika perspektiv. Denna teknik hjälper AI-system att förstå användarens verkliga avsikt och leverera mer exakta och kontextuellt relevanta svar genom att utforska olika tolkningar och aspekter av den ursprungliga frågan.
Query Fanout är AI-processen där en enskild användarfråga automatiskt utökas till flera relaterade underfrågor för att samla in omfattande information ur olika perspektiv. Denna teknik hjälper AI-system att förstå användarens verkliga avsikt och leverera mer exakta och kontextuellt relevanta svar genom att utforska olika tolkningar och aspekter av den ursprungliga frågan.
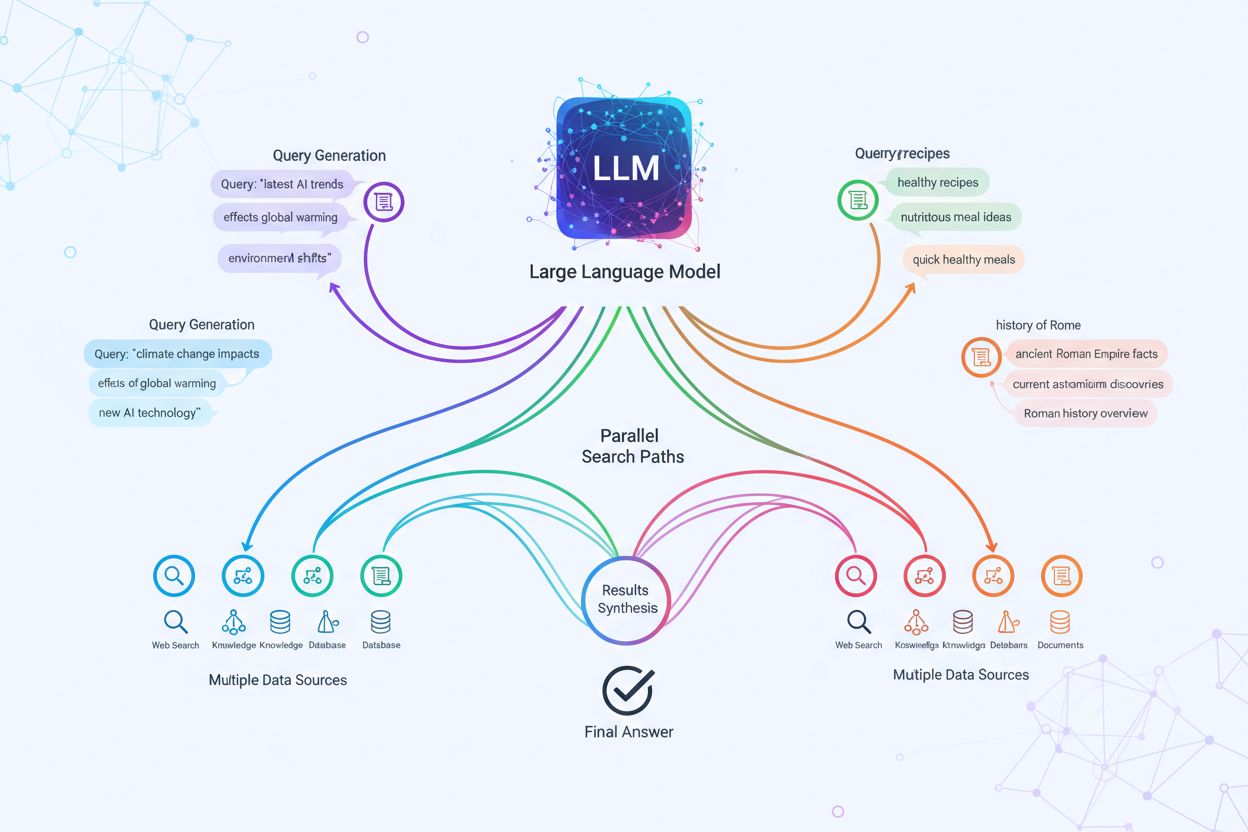
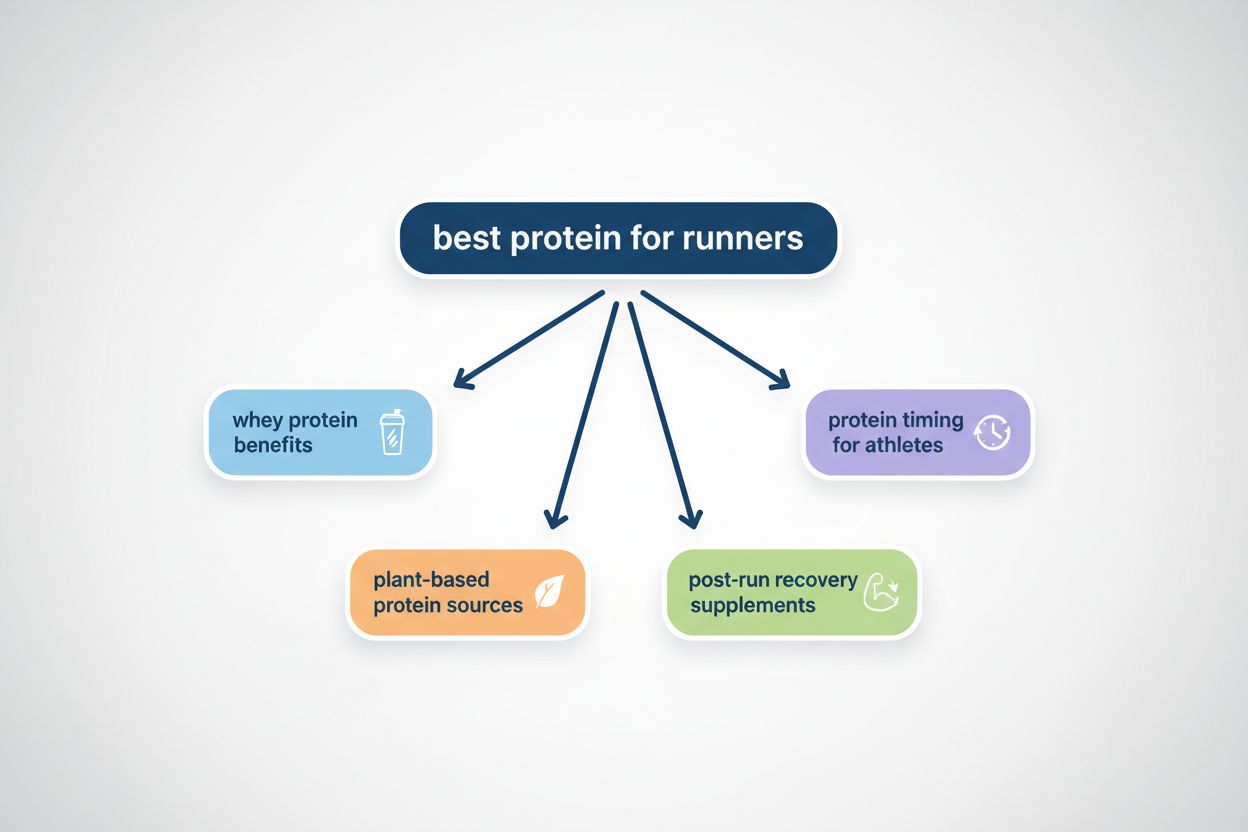
Query Fanout är processen där AI-system automatiskt utökar en enskild användarfråga till flera relaterade underfrågor för att samla in heltäckande information ur olika perspektiv. Istället för att bara matcha nyckelord som traditionella sökmotorer, gör query fanout det möjligt för AI att förstå den verkliga avsikten bakom en fråga genom att utforska olika tolkningar och relaterade ämnen. Till exempel, när en användare söker efter “bästa protein för löpare” kan ett AI-system som använder query fanout automatiskt generera underfrågor som “fördelar med vassleprotein”, “växtbaserade proteinkällor” och “kosttillskott för återhämtning efter löpning”. Denna teknik är grundläggande för hur moderna AI-söksystem som Google AI Mode, ChatGPT, Perplexity och Gemini levererar mer exakta och kontextuellt relevanta svar. Genom att bryta ned komplexa frågor till enklare, mer fokuserade underfrågor kan AI-system hämta mer målinriktad information och syntetisera den till heltäckande svar som täcker flera dimensioner av vad användaren faktiskt söker.
Den tekniska mekanismen bakom query fanout följer en systematisk femstegsprocess som omvandlar en enskild fråga till handlingsbar intelligens. Först tolkar AI-systemet den ursprungliga frågan för att identifiera dess kärnavsikt och eventuella oklarheter. Därefter genereras flera underfrågor baserat på härledda teman, ämnen och relaterade koncept som kan hjälpa till att besvara den ursprungliga frågan mer fullständigt. Dessa underfrågor körs sedan parallellt över sökinfrastrukturen, där Googles metod använder sin egen version av Gemini för att dela upp frågor i olika underämnen och utföra flera frågor samtidigt åt användaren. Systemet klustrar och grupperar sedan de hämtade resultaten efter ämne, enhetstyp och avsikt, och lager på lager med citeringar så att olika aspekter av svaret får rätt källa. Slutligen syntetiserar AI all denna information till ett enda sammanhängande svar som adresserar ursprungsfrågan ur flera perspektiv. I praktiken kan Googles AI Mode utföra åtta eller fler bakgrundssökningar för en måttligt komplex fråga, medan det mer avancerade Deep Search-läget kan utföra dussintals eller till och med hundratals frågor under flera minuter för att ge exceptionellt grundlig research kring komplexa ämnen som köpbeslut.
| Steg | Beskrivning | Exempel |
|---|---|---|
| 1. Tolkning | AI analyserar ursprungsfrågan för avsikt | “bästa CRM för småföretag” |
| 2. Underfrågegenerering | Systemet skapar relaterade varianter | “gratis CRM-verktyg”, “CRM med e-postautomation” |
| 3. Parallell körning | Flera sökningar körs samtidigt | Alla underfrågor söks samtidigt |
| 4. Resultatklustring | Resultat grupperas efter ämne/enhet | Grupp 1: Gratisverktyg, Grupp 2: Betalda lösningar |
| 5. Syntes | AI kombinerar resultat till sammanhängande svar | Ett heltäckande svar med citat |
AI-system använder query fanout av flera strategiska anledningar som grundläggande förbättrar svarskvalitet och tillförlitlighet:
Avsikts- och tvetydighetslösning – En enskild fråga som “Jaguar hastighet” kan syfta på antingen biltillverkarens prestandaspecifikationer eller djurets jaktfart. Query fanout hjälper systemet att testa flera tolkningar för att hitta den troligaste användaravsikten.
Faktagranskning och minskning av hallucinationer – Genom att hämta bevis från flera oberoende källor för varje gren av frågan kan AI korskontrollera påståenden och verifiera information innan svaret presenteras, vilket minskar risken för självsäkra men felaktiga svar avsevärt.
Perspektivmångfald – Query fanout hämtar information från olika innehållstyper – kliniska studier, köpguider, forumdiskussioner och varumärkessajter – vilket säkerställer att svaren balanserar auktoritet med praktisk användbarhet.
Hantering av komplexa frågor – Tekniken utmärker sig vid hantering av komplexa, lager-på-lager-frågor som kräver syntes av information från flera domäner.
Generering av nya svar – Query fanout möjliggör för AI-system att besvara frågor som aldrig tidigare besvarats tydligt på nätet, genom att kombinera flera informationsbitar och dra nya slutsatser som ingen enskild källa uttryckligen adresserar.
Skillnaden mellan query fanout och traditionell sökning utgör ett grundläggande skifte i hur informationsinhämtning fungerar. Traditionella sökmotorer arbetar huvudsakligen med nyckelords-matchning och returnerar en rankad lista med resultat baserat på hur väl enskilda sidor matchar exakta termer i frågan, där användaren själv måste förfina sina sökningar om de första resultaten inte räcker till. Query fanout fokuserar däremot på avsiktsförståelse istället för nyckelords-matchning, och systemet utforskar automatiskt flera vinklar och tolkningar utan att användaren behöver ingripa. I traditionell sökning måste användaren ofta göra flera följdsökningar för att få en helhetsbild – söka på “bästa CRM-program”, sedan “gratis CRM-verktyg”, sedan “CRM med e-postautomation” – medan query fanout automatiskt hanterar denna utforskning inom en enda interaktion. Detta skifte har djupgående konsekvenser för innehållsskapare och marknadsförare, som inte längre kan förlita sig på att optimera för enskilda nyckelord utan istället måste säkerställa att deras innehåll täcker hela klustret av relaterade ämnen och avsikter som AI-system kommer att utforska. Förändringen omformar även SEO-strategin, genom att flytta fokus från ranking på specifika sökord till att uppnå synlighet i flera relaterade frågor och bygga ämnesauktoritet som positionerar innehållet som relevant för bredare ämneskluster.
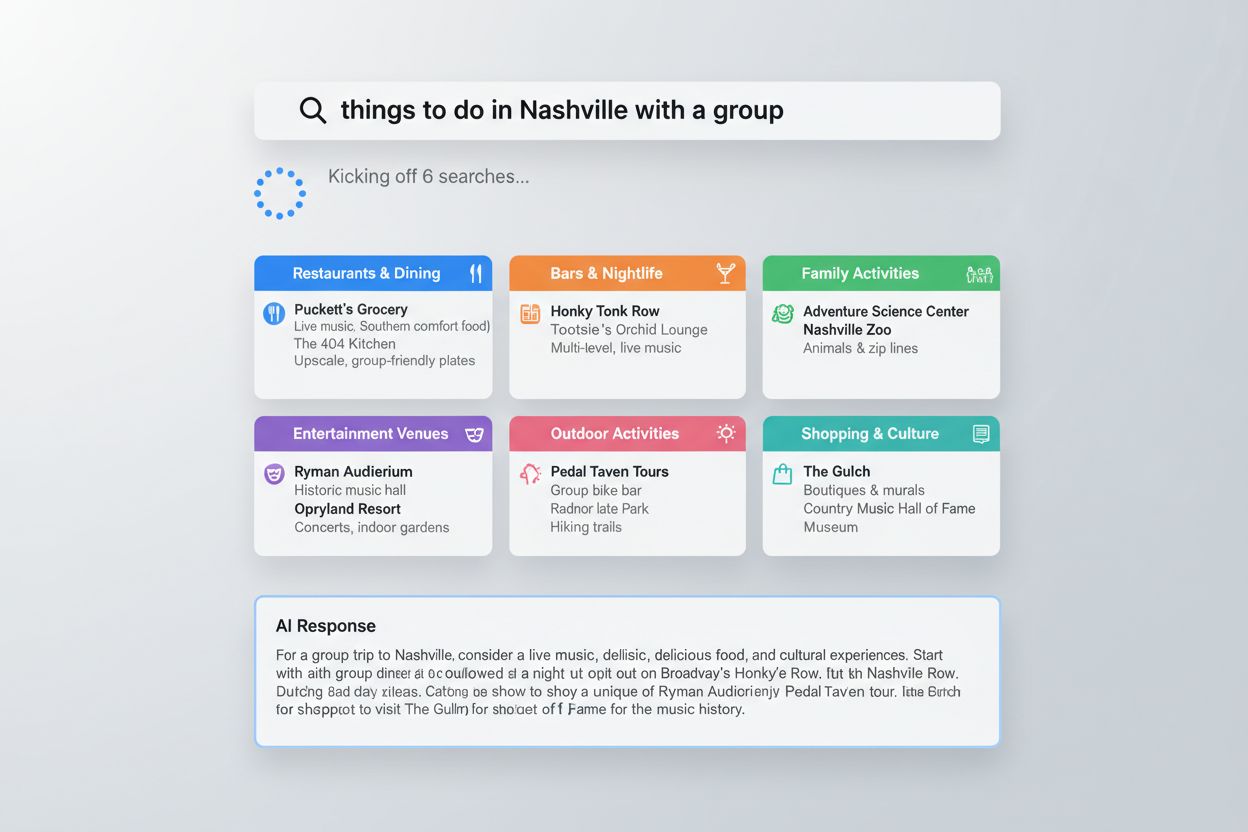
Query fanout visar sig på praktiska, observerbara sätt över stora AI-plattformar. När en användare frågar Google AI Mode “saker att göra i Nashville med en grupp”, sprider systemet automatiskt ut frågan i underfrågor om bra restauranger, barer, familjevänliga aktiviteter och nöjesställen, och syntetiserar resultaten till en heltäckande guide anpassad för gruppaktiviteter. ChatGPT uppvisar liknande beteende vid hantering av “bästa X”-frågor, där flera vinklar som “bäst för budget”, “bäst för funktioner” och “bäst för specifika användningsområden” behandlas i ett och samma svar. Deep Search-funktionen visar teknikens styrka för komplexa beslut—vid research om kassaskåp för hemmet kan systemet ägna flera minuter åt att utföra dussintals frågor om brandsäkerhetsbetyg, försäkringsaspekter, specifika produktmodeller och användarrecensioner, och leverera ett mycket grundligt svar med länkar till specifika produkter och detaljerade jämförelser. Utöver dessa exempel driver query fanout shoppingrekommendationer, restaurangtips och aktiejämförelser, där olika AI-plattformar implementerar tekniken via integration med interna verktyg som Google Finance och Shopping Graph, vilken uppdateras 2 miljarder gånger i timmen för att säkerställa realtidsnoggrannhet. Denna kapacitet för realtidsdataintegration innebär att query fanout inte är begränsad till statisk information utan kan omfatta aktuella priser, tillgänglighet, marknadsdata och annan dynamisk information som ständigt förändras.
Query fanout förändrar i grunden hur varumärken uppnår synlighet i AI-genererade svar, och skapar både möjligheter och utmaningar för organisationer som vill påverka hur de framställs i AI-svar. Eftersom query fanout får AI-system att utforska flera underfrågor, måste varumärken nu synas i resultat för flera relaterade sökningar, inte bara den primära frågan – vilket innebär att ett företag som endast är optimerat för “CRM-program” kan missa möjligheter att synas i resultat för “gratis CRM-verktyg” eller “CRM med e-postautomation”. Betydelsen av att synas positivt i AI-svar har ökat exponentiellt, då dessa svar direkt påverkar konsumentbeslut och ofta minskar användarens behov av att söka ytterligare information. Att förstå skillnaden mellan AI-nämningar (olänkade referenser till ditt varumärke i AI-svar) och AI-citeringar (länkade referenser till ditt innehåll) är avgörande, eftersom citeringar ger både synlighet och trovärdighet medan nämningar ökar kännedomen utan direkt trafik. Här blir övervakningsverktyg som AmICited.com oumbärliga – de följer hur ditt varumärke syns på flera AI-plattformar (Google AI Mode, ChatGPT, Perplexity, Gemini m.fl.), och visar inte bara om du nämns, utan även var du syns i svarshierarkin, hur ofta du citeras och vilket sentiment som omger dina varumärkesnämningar. Organisationer som förstår query fanout och aktivt optimerar för det får betydande konkurrensfördelar i AI-synlighet, eftersom de har större chans att synas i de många underfrågeresultat som tillsammans avgör AI-svarens totala kvalitet.
Optimering för query fanout kräver ett fundamentalt annorlunda tillvägagångssätt än traditionell nyckelordsfokuserad SEO. Första steget är att identifiera kärnämnen direkt relaterade till din verksamhet och expertis, eftersom dessa är områden där du mest trovärdigt och auktoritativt kan adressera de många vinklar som query fanout utforskar. Skapa sedan ämneskluster bestående av en central pelarsida som ger översikt över ett kärnämne, omgiven av klustersidor som adresserar specifika underämnen – denna struktur hjälper AI-system att känna igen ditt innehåll som en heltäckande resurs över flera relaterade frågor. Planera heltäckande innehåll som täcker inte bara huvudämnet utan även alla underämnen, jämförelser och frågevarianter som AI-system kan utforska när de sprider ut en fråga, och se till att varje sida fungerar som en navpunkt som uppfyller flera avsikter samtidigt. Skriv för NLP (naturlig språkbearbetning) genom att använda tydliga definitioner, fullständiga meningar och självständiga avsnitt som AI-system enkelt kan tolka och extrahera information från, istället för att förlita sig på nyckelordsdensitet eller andra traditionella SEO-taktiker. Implementera schema-markering för att lägga till maskinläsbara etiketter på olika datatyper på dina sidor, vilket hjälper AI-system att tolka ditt innehåll mer korrekt – till exempel genom att använda Product schema för produktnamn och bilder, eller Offer schema för pris- och tillgänglighetsinformation. Fokusera på semantisk fullständighet genom att säkerställa att ditt innehåll tydligt refererar till relaterade entiteter, koncept och relationer som dyker upp över fan-out-grenarna, och bygg en stark intern länkstruktur med kontextuell ankartext för att signalera ämnesdjup och hjälpa AI-system förstå hur dina innehållsdelar hänger ihop.
Hur du strukturerar och formaterar innehåll påverkar direkt hur effektivt AI-system kan extrahera och använda information för query fanout-svar. Skriv i block – självständiga, meningsfulla sektioner som kan stå för sig själva och enkelt bearbetas, hämtas och sammanfattas av AI-system – med fullständiga meningar och återupprepa kontext där det är hjälpsamt, istället för att förlita dig på fragmenterade punktlistor eller nyckelordstung text. Ge tydliga definitioner när du introducerar nya begrepp, eftersom AI-system ofta letar efter definitioner som en del av query fanout-processen och prioriterar sidor som uttryckligen definierar termer. Använd beskrivande underrubriker för att dela upp innehåll i logiska sektioner och använd korrekt rubrikhierarki (H2, H3, H4) för att visa relationer mellan ämnen, vilket hjälper AI-system att identifiera innehåll relaterat till mycket specifika frågor. Strukturera innehåll med tabeller och listor för att skapa lättbearbetad information som AI-system kan extrahera och omorganisera, och använd tydligt, samtalsmässigt språk som undviker jargong, alltför komplexa meningsbyggnader och onödigt utfyllnad. Stripe-webbplatsen är ett exempel på dessa bästa praxis, med lösningssidor anpassade för olika affärsstadier och användningsområden, undersektioner med direkt detaljerad information om relevanta underämnen och heltäckande täckning över blogginlägg, kundberättelser, supportdokumentation och andra resurser. Detta multiformats-, djupt strukturerade tillvägagångssätt hjälper AI-system känna igen Stripes relevans för olika avsikter och extrahera användbar information för utspridda frågor, vilket bidrar till deras exceptionella synlighet i AI-sök på plattformar som Google AI Mode, SearchGPT, ChatGPT, Perplexity och Gemini.
Att mäta framgång i query fanout-optimering kräver specialiserade verktyg och mätetal som går utöver traditionell SEO-analys. Verktyg som Semrush’s AI Visibility Toolkit och AmICited ger insikter om ditt varumärkes prestation över flera AI-plattformar och visar din share of voice för icke-varumärkesbundna frågor i Google AI Mode, SearchGPT, ChatGPT, Perplexity, Gemini och andra system. Dessa plattformar visar inte bara om ditt varumärke nämns, utan var det syns i svarshierarkin – om du citeras först, som nummer två eller längre ned – vilket direkt korrelerar med synlighet och inflytande. Att spåra nämningar kontra citeringar separat är avgörande, eftersom citeringar ger både synlighet och trafik medan nämningar ökar kännedomen; att förstå denna skillnad hjälper dig att prioritera optimeringsarbetet. Sentimentanalys i AI-svar visar hur ditt varumärke framställs – om AI-systemen betonar dina styrkor eller lyfter fram svagheter – så att du kan identifiera förbättringsområden i hur du diskuteras. Konkurrensjämförelser mot rivaler avslöjar luckor i din AI-synlighetsstrategi och möjligheter att överträffa konkurrenterna i specifika frågekluster. Vikten av kontinuerlig övervakning kan inte överskattas, eftersom AI-system utvecklas snabbt, nya plattformar dyker upp och frågemönster förändras; regelbunden uppföljning säkerställer att du kan anpassa din strategi och behålla synligheten när landskapet förändras.
Utvecklingen för query fanout pekar mot allt mer sofistikerad frågeförståelse och mer komplex AI-resonemang. När AI-system utvecklas kommer de troligen att få ännu mer nyanserade förmågor att bryta ned frågor i underfrågor, förstå implicit kontext och syntetisera information över alltmer varierade källor. Gränserna mellan traditionell och AI-sökning kommer att fortsätta suddas ut, då traditionella sökmotorer inkorporerar allt mer AI-drivna frågeförståelsefunktioner samtidigt som AI-systemen i ökande grad integrerar realtidssökning, vilket skapar ett hybridlandskap där optimeringsstrategier måste ta hänsyn till båda paradigmerna. Denna utveckling kräver ett grundläggande skifte i hur organisationer närmar sig sökoptimering, bort från nyckelordsranking och mot kontextuell synlighet och säkerställande av att innehållet syns över hela spektrat av relaterade frågor som AI-system utforskar. Ämnesauktoritet – att etablera djup, heltäckande expertis över relaterade ämnen – blir allt viktigare i takt med att AI-system premierar innehåll som visar mästerskap över hela ämneskluster snarare än enskilda nyckelord. De framväxande bästa praxis för query fanout-optimering betonar semantisk fullständighet, entitetsrelationer, innehållsstruktur och övervakning av synlighet över plattformar, och kräver att organisationer tänker holistiskt kring hur deras innehållsekosystem adresserar de många vinklar och tolkningar som AI-system kommer att utforska när de svarar på användarfrågor.
Query Fanout är den automatiska processen där AI-system delar upp en enskild fråga i flera underfrågor för att förstå den verkliga avsikten och samla in heltäckande information. Query Expansion är däremot en teknik för att lägga till relaterade termer för att förbättra hämtningen, vilket kan vara antingen manuellt eller automatiserat. Query Fanout är mer sofistikerad och inriktad på avsikt, medan query expansion främst fokuserar på nyckelord.
Antalet varierar beroende på frågans komplexitet. Enkla frågor kan generera 1–3 underfrågor, medan måttligt komplexa frågor vanligtvis resulterar i 5–8 underfrågor. Avancerade funktioner som Googles Deep Search kan utföra dussintals eller till och med hundratals bakgrundsfrågor under flera minuter för särskilt noggrann research om komplexa ämnen.
Ja, indirekt. Innehåll som är optimerat för Query Fanout tenderar att prestera bättre även i traditionell sökning, eftersom optimeringsprocessen kräver heltäckande ämnesbevakning, tydlig struktur och semantisk fullständighet – faktorer som sökmotorer belönar. Den primära fördelen är dock förbättrad synlighet i AI-genererade svar snarare än traditionella sökrankningar.
Stora AI-plattformar som implementerar Query Fanout inkluderar Google AI Mode, ChatGPT, Perplexity, Gemini och andra LLM-baserade söksystem. Varje plattform implementerar tekniken på sitt eget sätt, men alla använder någon form av frågedecomposition för att förbättra svarskvalitet och relevans.
Skapa ämneskluster med pelar- och klustersidor, skriv heltäckande innehåll som täcker underämnen och relaterade frågor, implementera schema-markering för strukturerad data, använd tydliga rubriker och format, bygg stark intern länkning och fokusera på semantisk fullständighet. Skriv för naturlig språkbearbetning genom att använda tydliga definitioner och självständiga avsnitt som AI-system enkelt kan tolka.
Query Fanout ökar möjligheterna till AI-citeringar genom att säkerställa att ditt innehåll visas i resultat för flera relaterade underfrågor. När AI-system utforskar olika vinklar av en fråga är de mer benägna att upptäcka och citera ditt innehåll om det heltäckande tar upp dessa olika perspektiv.
Query Fanout förbättrar användarupplevelsen avsevärt genom att möjliggöra för AI-system att leverera mer exakta och heltäckande svar utan att användaren behöver omformulera sina frågor flera gånger. Användare får mer målinriktade svar som täcker flera dimensioner av deras fråga i en enda interaktion.
Ja, Query Fanout hjälper till att minska hallucinationer genom att korsverifiera information från flera källor. När AI-system hämtar bevis från olika källor för varje gren av en utspridd fråga kan de verifiera påståenden och identifiera avvikelser, vilket avsevärt minskar risken för självsäkra men felaktiga svar.
Följ hur ditt innehåll visas på AI-plattformar när frågor expanderas. Förstå din AI-synlighet och citeringar med AmICiteds heltäckande övervakningsplattform.
Upptäck hur moderna AI-system som Google AI Mode och ChatGPT delar upp enskilda frågor i flera sökningar. Lär dig om query fanout-mekanismer, betydelsen för AI-...

Lär dig de viktigaste första stegen för att optimera ditt innehåll för AI-sökmotorer som ChatGPT, Perplexity och Google AI Overviews. Upptäck hur du strukturera...
Lär dig hur Förutseende av Frågor hjälper ditt innehåll att fånga utökade AI-konversationer genom att ta upp uppföljande frågor. Upptäck strategier för att iden...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.