
Semantisk sökmatchning
Lär dig hur semantisk sökmatchning gör det möjligt för AI-system att förstå användarens avsikt och leverera relevanta resultat bortom nyckelordsbaserad sökning....
5 min läsning
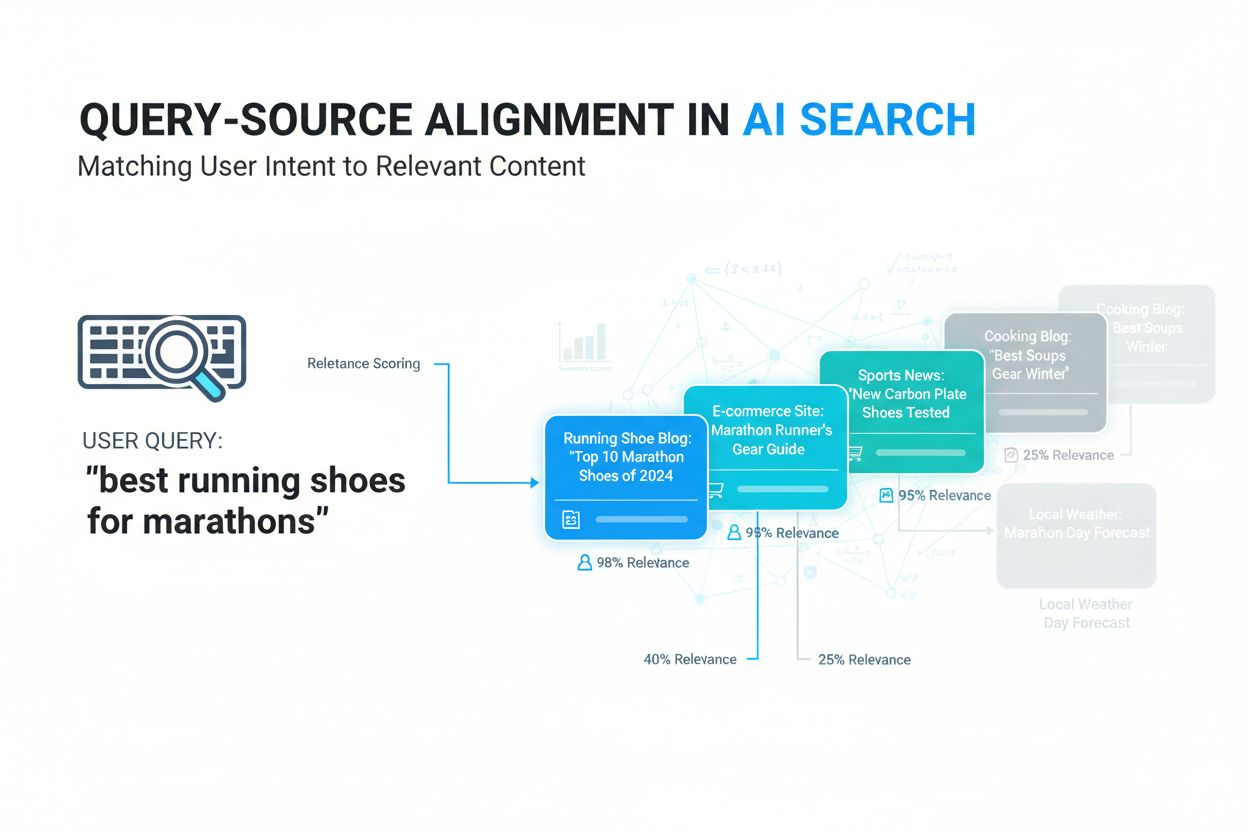
Query-source alignment är processen att matcha användarens sökfrågor med de mest relevanta informationskällorna baserat på semantisk betydelse och kontextuell relevans. Det använder AI och maskininlärning för att förstå avsikten bakom frågor och koppla dem till källor som verkligen besvarar användarens informationsbehov, istället för att endast förlita sig på enkel nyckelords-matchning. Denna teknik är grundläggande för moderna AI-söksystem som Google AI Overviews, ChatGPT och Perplexity. Effektiv alignment säkerställer att AI-system ger korrekta, relevanta resultat som förbättrar användarnöjdhet och innehållets synlighet.
Query-source alignment är processen att matcha användarens sökfrågor med de mest relevanta informationskällorna baserat på semantisk betydelse och kontextuell relevans. Det använder AI och maskininlärning för att förstå avsikten bakom frågor och koppla dem till källor som verkligen besvarar användarens informationsbehov, istället för att endast förlita sig på enkel nyckelords-matchning. Denna teknik är grundläggande för moderna AI-söksystem som Google AI Overviews, ChatGPT och Perplexity. Effektiv alignment säkerställer att AI-system ger korrekta, relevanta resultat som förbättrar användarnöjdhet och innehållets synlighet.
Query-source alignment avser processen att matcha användarens sökfrågor med de mest relevanta informationskällorna baserat på semantisk betydelse och kontextuell relevans, snarare än endast enkel nyckelordsöverensstämmelse. I grunden adresserar detta koncept en grundläggande utmaning inom informationssökning: att säkerställa att när användare söker information så är resultaten de får inte bara tekniskt relaterade till deras söktermer, utan verkligen besvarar deras underliggande informationsbehov.
Traditionellt förlitade sig söksystem på nyckelords-matchning – att hitta dokument som innehöll exakt de ord eller fraser en användare skrev in. Även om detta är enkelt leder det ofta till irrelevanta resultat eftersom det ignorerar kontext, avsikt och den djupare betydelsen bakom frågorna. Query-source alignment löser detta problem genom att använda semantiska matchningstekniker som förstår det konceptuella sambandet mellan vad användaren frågar efter och vad informationskällorna innehåller. Det innebär att en sökning på “fordonsunderhåll” effektivt kan hitta artiklar om “bilvård” eller “service av bil”, även utan exakta nyckelordsmatchningar.
I moderna AI-söksystem har query-source alignment blivit allt viktigare i takt med att artificiell intelligens möjliggör mer sofistikerad förståelse av språkliga nyanser och användarens avsikt. Istället för att behandla frågor som enbart samlingar av ord analyserar AI-drivna alignment-system det semantiska innehållet i både användarens fråga och tillgängliga källor, och skapar meningsfulla kopplingar baserat på relevans snarare än ytlig likhet.
Denna åtskillnad är viktig eftersom den direkt påverkar sökkvaliteten och användarnöjdheten. Effektiv query-source alignment säkerställer att informationssökningssystem levererar resultat som verkligen besvarar användarens frågor, minskar irrelevant brus i sökresultaten och hjälper användare att upptäcka information de annars kanske inte skulle hitta med traditionell nyckelordsbaserad sökning. I takt med att AI-sökteknik fortsätter att utvecklas förblir query-source alignment en hörnsten för att bygga system som verkligen förstår och svarar på användarnas informationsbehov.
Den tekniska processen för query-source alignment innefattar flera sofistikerade steg som omvandlar användarfrågor till meningsfulla kopplingar med relevanta källor:
Frågebehandling och Tokenisering – När en användare skickar in en sökfråga bryter systemet först ner den i individuella tokens (ord och fraser) och analyserar den grammatiska strukturen. Algoritmer för naturlig språkbehandling identifierar kärnbegrepp, entiteter och avsikt bakom frågan, tar bort stoppord och identifierar de mest meningsfulla komponenterna som ska styra alignment-processen.
Generering av frågeinbäddning – Den bearbetade frågan omvandlas till en semantisk vektor – en matematisk representation som fångar frågans betydelse och kontext i ett multidimensionellt rum. Denna inbäddning skapas med hjälp av neurala språkmodeller tränade på stora mängder textdata, vilket gör att systemet kan representera frågans semantiska kärna istället för endast dess bokstavliga ord.
Vektorisering av källdokument – Samtidigt omvandlas alla tillgängliga källdokument i systemet till semantiska vektorer med samma inbäddningsmodell. Detta säkerställer att både frågor och källor representeras i samma semantiska rum, vilket möjliggör direkt jämförelse. Varje dokuments vektor fångar dess övergripande betydelse, ämnen och relevanssignaler.
Beräkning av vektorsimilaritet – Systemet beräknar likheten mellan frågevektorn och varje källdokuments vektor med hjälp av matematiska distansmått, vanligen cosinuslikhet. Denna beräkning avgör hur nära den semantiska betydelsen av varje källa ligger frågans semantiska betydelse, och ger ett likhetspoäng mellan 0 och 1.
Relevanspoäng och ranking – Utöver semantisk likhet tillämpar systemet ytterligare rankningsfaktorer som domänauktoritet, innehållsaktualitet, användarengagemang och ämnesrelevans. Dessa faktorer kombineras med semantiska likhetspoäng för att skapa en helhetsbedömning av varje källas relevans, vilket avgör dess position i den rankade resultatlistan.
Validering av innehållsmatchning – Systemet validerar att de valda källorna faktiskt innehåller relevant information genom att analysera specifika delar av innehållet. Detta säkerställer att källor inte rankas högt bara för att de nämner relevanta nyckelord, utan för att de verkligen besvarar användarens informationsbehov med substantiellt, korrekt innehåll.
Slutligt urval och ranking av källor – De högst rankade källorna väljs ut för att presenteras för användaren eller för att citeras i AI-genererade svar. Den slutliga rankingen speglar den samlade bedömningen av semantisk alignment, auktoritet, relevans och innehållskvalitet, vilket säkerställer att användaren får de mest lämpliga källorna för sin specifika fråga.
| Metod/Tilvägagångssätt | Så här fungerar det | Fördelar | Nackdelar | Bäst för |
|---|---|---|---|---|
| Nyckelords-matchning (Traditionell) | Söker efter exakta ord eller fraser i dokument; rankar baserat på frekvens och position | Enkel att implementera; snabb bearbetning; transparent matchningslogik | Ignorerar kontext och avsikt; ger irrelevanta resultat; fungerar dåligt med synonymer | Enkla, faktabaserade frågor; äldre system |
| Semantisk likhet (Vektorbaserad) | Omvandlar frågor och dokument till semantiska vektorer; beräknar likhet med matematiska distansmått | Förstår betydelse bortom nyckelord; hanterar synonymer och kontext; mycket noggrann | Resurskrävande; kräver stora träningsdatamängder; mindre transparent | Komplexa frågor; avsiktsstyrd sökning; moderna AI-system |
| Entitetsigenkänning | Identifierar och klassificerar viktiga entiteter (personer, platser, organisationer, produkter) i frågor och innehåll | Förbättrar förståelsen av specifika ämnen; löser tvetydigheter; möjliggör integration med kunskapsgrafer | Kräver omfattande entitetsdatabaser; svårigheter med nya eller nischade entiteter | Frågor om specifika entiteter; kunskapsbaserad sökning |
| Kontextuell förståelse | Analyserar omgivande kontext, användarhistorik och frågemönster för att tolka betydelse | Fångar nyanserad avsikt; personaliserar resultat; förbättrar noggrannheten för tvetydiga frågor | Integritetsproblem med användardata; kräver historisk data; komplex implementation | Konversationell sökning; personliga rekommendationer |
| Hybridtilvägagångssätt | Kombinerar flera metoder (semantisk likhet, entitetsigenkänning, kontextuell förståelse) för heltäckande matchning | Utnyttjar flera metoders styrkor; mer robust och noggrant; hanterar olika frågetyper | Komplex att implementera och underhålla; högre beräkningskostnader; svårare att felsöka | Företagssökning; AI-söksystem |
| Kunskapsgrafsbaserad | Använder sammankopplade entiteter och relationer för att förstå frågor och matcha relevanta källor | Fångar verkliga relationer; möjliggör avancerad resonerande; stödjer komplexa frågor | Kräver omfattande uppbyggnad av kunskapsgrafer; underhållskrävande; domänspecifik | Komplexa forskningsfrågor; semantiska webbapplikationer |
Query-source alignment är grundläggande för hur moderna AI-söksystem fungerar och väljer källor för sina svar:
Google AI Overviews – Använder query-source alignment för att välja de mest relevanta källorna att citera när AI-drivna söksammanfattningar genereras. Systemet analyserar semantisk alignment mellan användarens fråga och tillgängliga webbsidor och prioriterar källor med stark semantisk relevans och hög auktoritet. Forskning visar att ungefär 70% av källorna i AI Overviews kommer från de 10 översta organiska sökresultaten, vilket indikerar att traditionell ranking och semantisk alignment samverkar.
ChatGPT med webbläsning – När ChatGPT:s webbläsarfunktion är aktiverad används query-source alignment för att identifiera och hämta de mest relevanta webbsidorna för att besvara användarens fråga. Systemet prioriterar auktoritativa källor med stark semantisk alignment till frågan, vilket säkerställer att genererade svar baseras på tillförlitlig, relevant information från webben.
Perplexity AI – Implementerar query-source alignment för att välja källor för sina konversationella svar. Plattformen visar citerade källor tillsammans med svaren, vilket gör alignment-processen transparent för användaren. Stark semantisk alignment mellan frågor och källor säkerställer att Perplexitys svar är välgrundade och verifierbara.
Bing AI Chat – Utnyttjar query-source alignment för att integrera sökresultat i konversationella svar. Systemet matchar användarfrågor med relevanta Bing-sökresultat med hjälp av semantisk förståelse, och sammanställer information från flera alignade källor till koherenta svar.
Kärnkällor-konceptet – AI-system identifierar “kärnkällor” – URL:er som konsekvent förekommer i flera svar på relaterade frågor. Dessa källor har exceptionellt stark semantisk alignment med frågeteman och anses vara mycket auktoritativa. Att bli en kärnkälla för din nisch är ett viktigt mål för innehållssynlighet i AI-sök.
Semantisk relevanspoäng – AI-plattformar tilldelar relevanspoäng baserat på hur väl källinnehållet semantiskt stämmer överens med frågeavsikt. Källor med högre semantisk alignment-poäng är mer sannolika att väljas, citeras och synas tydligt i AI-genererade svar.
Multi-Query Alignment – När AI-system genererar svar bryter de ofta ner användarfrågor i flera del-frågor (fan-out queries). Query-source alignment tillämpas på varje del-fråga, och källor som alignar väl med flera relaterade frågor prioriteras, vilket ger mer heltäckande och välgrundade svar.
AmICited-övervakning – AmICited spårar query-source alignment genom att övervaka vilka av dina sidor som väljs som källor för specifika frågor på AI-plattformar. Plattformen visar dina alignment-poäng, spårar kärnkällestatus och identifierar möjligheter att förbättra alignment mot högt värderade frågor i din nisch.
Balans mellan auktoritet och semantik – Även om domänauktoritet förblir viktig visar forskning att semantisk alignment blir alltmer avgörande. Källor med stark semantisk alignment men måttlig auktoritet kan ranka högre än högauktoritativa källor med svag semantisk alignment, vilket visar att betydelsen är lika viktig som rykte.
Spårning av alignment i realtid – Moderna AI-övervakningsplattformar spårar hur query-source alignment förändras över tid i takt med att innehåll uppdateras och nya källor tillkommer. Detta gör det möjligt för marknadsförare att förstå vilka innehållsuppdateringar som förbättrar alignment och vilka frågor som ger bäst synlighetsmöjligheter.
Att förstå och optimera query-source alignment har blivit avgörande för innehållsskapare, marknadsförare och varumärken i AI-sökningens tid:
Spårning av varumärkesciteringar – Query-source alignment avgör direkt om ditt varumärke och innehåll citeras i AI-genererade svar. Plattformar som AmICited övervakar denna alignment och visar vilka frågor ditt innehåll rankas för i AI-svar och hur ofta ditt varumärke nämns i AI-söksystem.
Semantisk relevans och upptäckt – Stark semantisk alignment med användarfrågor ökar sannolikheten att ditt innehåll upptäcks och citeras av AI-system. Detta är särskilt viktigt för long-tail-frågor och nischade ämnen där traditionell SEO-konkurrens kan vara lägre men semantisk relevans avgörande.
Konkurrensfördelar i AI-sök – I takt med att AI-sök blir vanligare får varumärken med stark query-source alignment för högt värderade frågor betydande konkurrensfördelar. Tidig optimering för semantisk alignment positionerar ditt innehåll för att ta synlighet innan konkurrenterna hinner anpassa sina strategier.
Källspårning och attribution – Att förstå query-source alignment hjälper dig att spåra vilka av dina sidor som väljs som källor för specifika frågor. Denna attributionsdata visar vilket innehåll som presterar bäst i AI-svar och vilka ämnen som är möjligheter till förbättring.
Optimering för AI-svar – Istället för att bara optimera för traditionella sökrankningar måste modern innehållsstrategi ta hänsyn till query-source alignment. Innehåll som rankar högt i vanlig sökning men har svag semantisk alignment kan väljas bort av AI-system och gå miste om synlighetsmöjligheter.
Riskhantering och varumärkesstyrning – Genom att övervaka query-source alignment förstår du hur ditt varumärke representeras i AI-svar. Om konkurrenters innehåll har starkare alignment för viktiga frågor kan du identifiera luckor och skapa innehåll som bättre möter användarens avsikt.
Förfining av innehållsstrategi – Query-source alignment-mått visar vilka ämnen, nyckelord och innehållsformat som bäst resonerar med AI-system. Denna data vägleder innehållsstrategin och hjälper dig fokusera på ämnen där semantisk alignment är möjlig och värdefull.
Konkurrensanalys – Genom att analysera query-source alignment i din bransch kan du se vilka konkurrenters innehåll som oftast citeras i AI-svar. Denna konkurrensinformation avslöjar luckor i din strategi och möjligheter att ta synlighet.
Långsiktig synlighetsplanering – Query-source alignment är mer stabilt än traditionella sökrankningar eftersom det bygger på semantisk betydelse snarare än algoritmfaktorer som ofta ändras. Stark semantisk alignment ger mer varaktig synlighet i AI-sök över tid.
Mätbar ROI för innehållsinvesteringar – Genom att spåra query-source alignment och synlighet i AI-svar får du tydliga mått för att mäta innehållets ROI. Du kan direkt se hur innehållsinvesteringar ger varumärkesciteringar och trafik från AI-söksystem.
Optimering för query-source alignment kräver en strategisk metod som går bortom traditionell SEO. Målet är att säkerställa att ditt innehåll har stark semantisk alignment med de frågor din målgrupp använder, så att det är mer sannolikt att AI-system väljer det som relevant källa.
Förståelse för semantisk optimering – Semantisk optimering handlar om att säkerställa att ditt innehåll på djupet adresserar specifika användaravsikter och frågor, inte bara rankar på nyckelord. Det innebär att förstå de semantiska sambanden mellan begrepp, använda konsekvent terminologi och strukturera innehållet så att både människor och AI-system tydligt kan tolka betydelsen.
Bästa praxis för Query-Source Alignment:
Utför semantisk nyckelordsanalys – Gå bortom traditionell nyckelordsanalys och identifiera semantiska kluster av relaterade termer och begrepp. Använd verktyg som SEMrush eller Ahrefs för att hitta inte bara högvolymnyckelord utan även semantiska varianter och relaterade frågor som adresserar samma användaravsikt. Gruppera dessa i semantiska kluster och skapa heltäckande innehåll som behandlar alla varianter.
Implementera semantisk HTML5-markup – Använd semantiska HTML5-element som <article>, <section>, <header>, <nav> och <main> för att tydligt strukturera ditt innehåll. Dessa element hjälper AI-system förstå organisationen och hierarkin i ditt innehåll och förbättrar semantisk tolkning. Använd rubriktaggar (<h1>, <h2>, etc.) hierarkiskt för att etablera tydliga ämnesrelationer.
Skapa entitetsrikt innehåll – Identifiera nyckelentiteter (personer, organisationer, produkter, begrepp) som är relevanta för ditt ämne och nämn dem tydligt i ditt innehåll. Använd konsekvent terminologi och ge kontext som hjälper AI-system att förstå vilka entiteter du diskuterar. Om du till exempel diskuterar “Apple,” förtydliga genom kontext om du syftar på teknikföretaget eller frukten.
Använd strukturerad data (JSON-LD) – Implementera schema.org-markup med JSON-LD-format för att ge explicit semantisk information om ditt innehåll. Använd lämpliga schema-typer som Article, NewsArticle, HowTo, FAQPage eller Product beroende på innehållstyp. Detta hjälper AI-system att exakt förstå vad ditt innehåll handlar om och hur det relaterar till användarens frågor.
Optimera för varianter av sökavsikt – Identifiera de olika sätt användare uttrycker samma informationsbehov och skapa innehåll som adresserar alla varianter. Till exempel kan användare söka efter “hur lagar man en droppande kran,” “guide för kranreparation” eller “lösningar för läckande kran.” Skapa heltäckande innehåll som täcker alla dessa avsiktsvarianter med konsekvent semantisk betydelse.
Utveckla heltäckande ämnesbevakning – Istället för att skapa flera ytliga artiklar om liknande ämnen, skapa heltäckande guider som noggrant behandlar specifika ämnen. AI-system föredrar djupgående innehåll som ger kompletta svar på användarens frågor. Använd ämnesklustring för att säkerställa att ditt innehåll täcker alla aspekter av ett ämne med starka semantiska relationer mellan avsnitten.
Bibehåll konsekvent terminologi – Använd konsekvent språk och terminologi genom hela ditt innehåll och din webbplats. Om du introducerar ett begrepp med en viss term, använd samma term genomgående istället för att byta till synonymer. Denna konsekvens hjälper AI-system att känna igen att du diskuterar samma koncept i hela ditt innehåll.
Skapa tydliga innehållshierarkier – Strukturera ditt innehåll med tydliga hierarkier som visar hur begrepp relaterar till varandra. Använd rubriker, punktlistor och numrerade listor för att etablera relationer mellan idéer. Denna struktur hjälper AI-system att förstå den semantiska organisationen av ditt innehåll och hur olika begrepp hänger samman.
Optimera metabeskrivningar och titlar – Skriv metabeskrivningar och sidtitlar som tydligt kommunicerar sidans semantiska innehåll. Dessa element används ofta av AI-system för att tolka sidans innehåll, så se till att de korrekt speglar sidans huvudämne och nyckelbegrepp. Inkludera relevanta entiteter och begrepp i titlar och beskrivningar.
Övervaka semantiska alignment-poäng – Använd AI-övervakningsplattformar som AmICited för att spåra dina alignment-poäng för viktiga frågor. Övervaka hur din alignment förändras när du uppdaterar innehåll och identifiera vilka uppdateringar som förbättrar alignment. Spåra vilka frågor som visar starkast alignment och fokusera på att utveckla innehåll inom dessa områden.
Exempel från verkligheten inom olika branscher:
E-handel – En nätbutik som säljer löparskor kan optimera för query-source alignment genom att skapa heltäckande guider om “maratonträningsskor,” “bästa löparskor för olika fottyper” och “jämförelse av skonsteknologi.” Genom att adressera semantiska varianter av användaravsikt och använda konsekvent terminologi om skofunktioner ökar sannolikheten att bli vald som källa i AI-svar om löparskor.
Hälso- och sjukvård – En vårdcentral kan förbättra query-source alignment genom att skapa detaljerat innehåll om specifika tillstånd, behandlingar och vårdgivare. Genom att använda korrekt medicinsk terminologi, entitetsigenkänning för tillstånd och behandlingar samt strukturerad data-markup hjälper det AI-system att förstå det semantiska innehållet och matcha det till relevanta hälsorelaterade frågor.
Teknologi – Ett mjukvaruföretag kan optimera alignment genom att skapa heltäckande dokumentation och guider som adresserar semantiska varianter av användarproblem. Genom att använda konsekvent terminologi för funktioner, tydliga konceptuella hierarkier och strukturerad data hjälper det AI-system att känna igen innehållet som en relevant källa för teknikrelaterade frågor.
Traditionell nyckelords-matchning letar endast efter exakta ord eller fraser i dokument, medan query-source alignment använder semantisk förståelse för att matcha betydelsen och avsikten bakom frågor. Detta innebär att en sökning på 'fordonsunderhåll' kan hitta artiklar om 'bilvård' även utan exakta nyckelordsmatchningar. Query-source alignment ger mer relevanta resultat eftersom det förstår kontext och användarens avsikt istället för bara ordlikhet på ytan.
AI-söksystem använder query-source alignment för att välja de mest relevanta källorna att citera i sina genererade svar. Systemet analyserar både den semantiska betydelsen av användarens fråga och innehållet i tillgängliga källor, och rankar sedan källorna baserat på relevans, auktoritet och semantisk alignment. Detta säkerställer att AI-genererade svar baseras på högkvalitativa, relevanta källor som verkligen möter användarens informationsbehov.
Query-source alignment påverkar direkt om ditt innehåll väljs som källa i AI-genererade svar. Om ditt innehåll har stark semantisk alignment med vanliga frågor inom din nisch är det mer sannolikt att det citeras av AI-system. Denna synlighet i AI-svar driver trafik och bygger varumärkesauktoritet. Att förstå och optimera för query-source alignment är avgörande för att bibehålla synlighet i AI-sökningens tid.
För att optimera för query-source alignment, fokusera på att skapa innehåll som på djupet besvarar specifika användaravsikter och frågor. Använd semantisk HTML-markup, implementera strukturerad data (JSON-LD), säkerställ tydlig entitetsigenkänning och håll konsekvent terminologi. Skriv heltäckande, lösningsfokuserat innehåll som besvarar frågor grundligt. Övervaka dina semantiska alignment-poäng och spåra hur ditt innehåll presterar i AI-svar med hjälp av verktyg som AmICited.
Semantisk likhet är den centrala mekanismen i query-source alignment. Den mäter hur nära en frågas betydelse ligger innehållets betydelse i källorna. Detta beräknas med hjälp av vektorinbäddningar – matematiska representationer av text som fångar semantisk betydelse. Källor med högre semantisk likhetspoäng till frågan rankas högre och är mer benägna att väljas av AI-system som relevanta källor för att besvara användarfrågor.
AmICited är en AI-övervakningsplattform som spårar hur ditt varumärke och innehåll citeras över AI-söksystem. Den övervakar query-source alignment genom att visa vilka av dina sidor som väljs som källor för specifika frågor, hur ofta ditt varumärke nämns i AI-svar och hur din semantiska alignment står sig mot konkurrenter. Denna data hjälper dig att förstå och optimera din innehållsstrategi för bättre synlighet i AI-sök.
Kärnkällor är URL:er som konsekvent förekommer i flera AI-genererade svar för samma eller relaterade frågor. Dessa källor har stark semantisk alignment med frågeteman och anses vara mycket relevanta av AI-system. Kärnkällor rankas ofta högre i traditionella sökresultat och har bättre semantisk alignment med frågeavsikt. Att bli en kärnkälla för dina nischade frågor är ett viktigt mål för innehållssynlighet i AI-sök.
Entitetsigenkänning hjälper AI-system att identifiera och förstå viktiga begrepp, personer, organisationer och ämnen i både frågor och källinnehåll. Genom att känna igen entiteter kan AI-system bättre förstå vad en fråga egentligen handlar om och matcha den till källor som diskuterar samma entiteter i relevanta sammanhang. Till exempel, att känna igen att 'Apple' syftar på teknikföretaget och inte frukten hjälper till att matcha frågor om Apple-produkter med relevanta teknik-källor.
Spåra hur ditt innehåll citeras över AI-söksystem och optimera för bättre query-source alignment med AmICiteds AI-övervakningsplattform.
Lär dig hur semantisk sökmatchning gör det möjligt för AI-system att förstå användarens avsikt och leverera relevanta resultat bortom nyckelordsbaserad sökning....

Lär dig hur semantisk sökning använder AI för att förstå användarens avsikt och kontext. Upptäck hur det skiljer sig från nyckelordssökning och varför det är av...

Lär dig vad query-to-citation mapping är och hur du spårar vilka sökfrågor som utlöser citeringar till ditt varumärke i AI-genererade svar på ChatGPT, Gemini oc...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.