Sonar-algoritmen i Perplexity: Förklaring av realtids-sökmodell
Lär dig hur Perplexitys Sonar-algoritm driver realtids AI-sökning med kostnadseffektiva modeller. Utforska Sonar, Sonar Pro och Sonar Reasoning-varianter.
8 min läsning
Sonar-algoritmen är Perplexitys egenutvecklade retrieval-augmented generation (RAG) rankningssystem som kombinerar hybrid semantisk och nyckelordsbaserad sökning med neural omrankning för att hämta, ranka och citera webbkällor i realtid i AI-genererade svar. Den prioriterar innehållets aktualitet, semantisk relevans och citerbarhet för att leverera förankrade, källstödda svar samtidigt som hallucinationer minimeras.
Sonar-algoritmen är Perplexitys egenutvecklade retrieval-augmented generation (RAG) rankningssystem som kombinerar hybrid semantisk och nyckelordsbaserad sökning med neural omrankning för att hämta, ranka och citera webbkällor i realtid i AI-genererade svar. Den prioriterar innehållets aktualitet, semantisk relevans och citerbarhet för att leverera förankrade, källstödda svar samtidigt som hallucinationer minimeras.
Sonar-algoritmen är Perplexitys egenutvecklade retrieval-augmented generation (RAG) rankningssystem som driver dess svarsmotor genom att kombinera hybrid semantisk och nyckelordsbaserad sökning, neural omrankning och realtidsgenerering av citat. Till skillnad från traditionella sökmotorer som rankar sidor för visning i en resultatlista rankar Sonar innehållssnuttar för syntes till ett enda, enhetligt svar med inbäddade citat till källdokument. Algoritmen prioriterar innehållets aktualitet, semantisk relevans och citerbarhet för att leverera förankrade, källstödda svar samtidigt som hallucinationer minimeras. Sonar representerar ett fundamentalt skifte i hur AI-system hämtar och rankar information—från länkburna auktoritetssignaler till svarsfokuserade nyttomått som betonar om innehållet direkt uppfyller användarens avsikt och kan citeras rent i syntetiserade svar. Denna åtskillnad är avgörande för att förstå hur synlighet i AI-svarsmotorer skiljer sig från traditionell SEO, eftersom Sonar utvärderar innehåll inte efter dess förmåga att ranka i en lista, utan efter dess förmåga att extraheras, syntetiseras och tillskrivas i ett AI-genererat svar.
Framväxten av Sonar-algoritmen speglar ett bredare branschskifte mot retrieval-augmented generation som den dominerande arkitekturen för AI-svarsmotorer. När Perplexity lanserades i slutet av 2022 identifierade företaget en kritisk lucka i AI-landskapet: medan ChatGPT erbjöd kraftfulla konversationsfunktioner saknade den realtidsåtkomst till information och källhänvisningar, vilket ledde till hallucinationer och föråldrade svar. Perplexitys grundarteam, som initialt arbetade på ett verktyg för databasfrågeöversättning, ställde om helt för att bygga en svarsmotor som kunde kombinera live webbsökning med LLM-syntes. Detta strategiska beslut formade Sonars arkitektur från början—algoritmen konstruerades inte för att ranka sidor för mänsklig bläddring, utan för att hämta och ranka innehållsfragment för maskinell syntes och citering. Under de senaste två åren har Sonar utvecklats till ett av de mest sofistikerade rankningssystemen i AI-ekosystemet, med Perplexitys Sonar-modeller på platserna 1 till 4 i Search Arena Evaluation, och överträffar därmed konkurrerande modeller från Google och OpenAI. Algoritmen hanterar nu över 400 miljoner sökfrågor per månad, indexerar över 200 miljarder unika URL:er och upprätthåller realtidsaktualitet genom tiotusentals indexuppdateringar per sekund. Denna skala och sofistikering understryker Sonars betydelse som ett avgörande rankningsparadigm i AI-sökningens tidevarv.
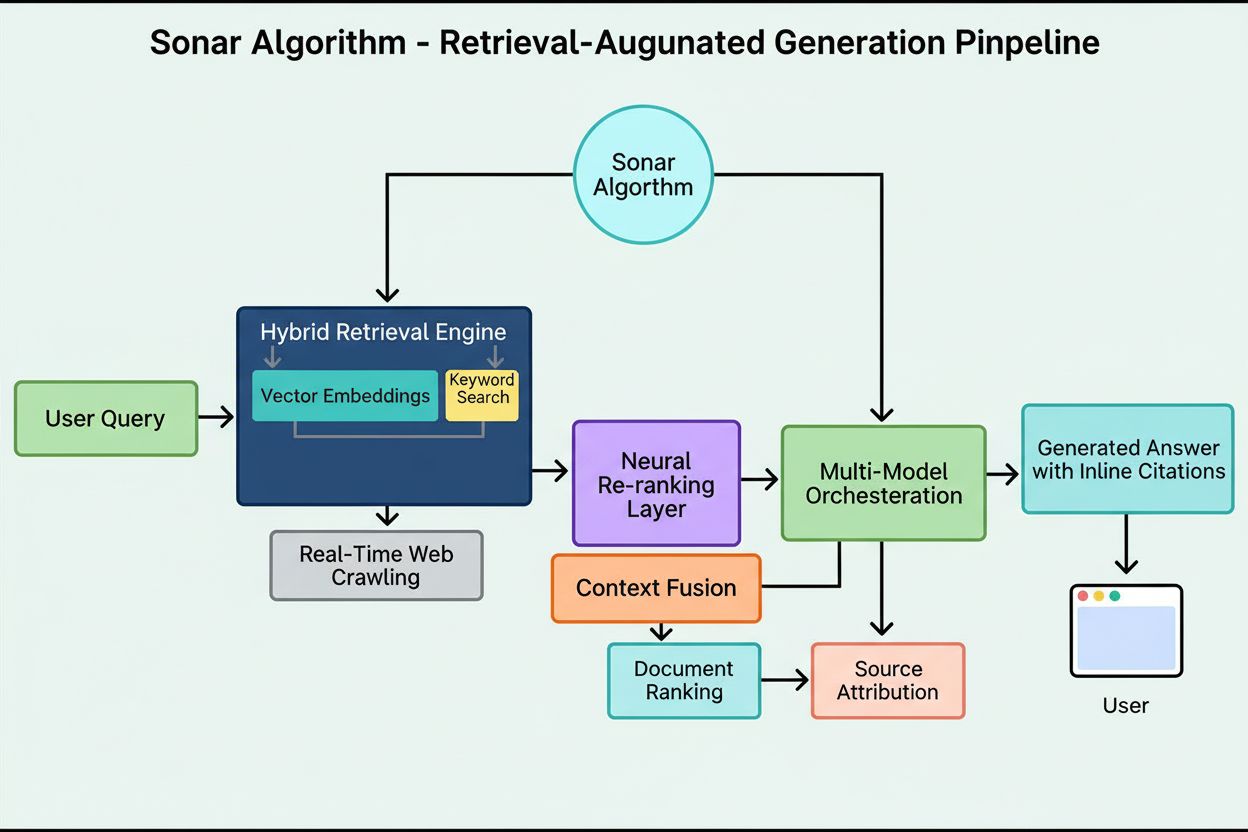
Sonars rankningssystem fungerar genom en noggrant orkestrerad femstegs retrieval-augmented generation-pipeline som omvandlar användarfrågor till förankrade, citerade svar. Det första steget, tolkning av frågeavsikt, använder en LLM för att gå bortom enkel nyckelords-matchning och uppnå semantisk förståelse för vad användaren verkligen frågar om, inklusive kontext, nyans och underliggande intention. Det andra steget, live webbhämtning, skickar den tolkade frågan till Perplexitys massiva distribuerade index som drivs av Vespa AI, vilket i realtid söker efter relevanta sidor och dokument. Detta återhämtningssystem kombinerar tät återhämtning (vektorsökning med semantiska inbäddningar) och gles återhämtning (lexikalisk/nyckelordsbaserad sökning) och slår samman resultaten till cirka 50 olika kandidatdokument. Det tredje steget, utdrag och kontextualisering av snuttar, skickar inte hela sidans text till den generativa modellen; istället extraherar algoritmer de mest relevanta snuttarna, styckena eller delarna som direkt berör frågan och samlar dem till ett fokuserat kontextfönster. Det fjärde steget, syntetiserad svarsgenerering med citat, skickar denna utvalda kontext till en vald LLM (från Perplexitys egen Sonar-familj eller tredjepartsmodeller som GPT-4 eller Claude), som genererar ett svar på naturligt språk strikt baserat på hämtad information. Avgörande är att inbäddade citat länkar varje påstående tillbaka till källdokument, vilket garanterar transparens och möjliggör verifiering. Det femte steget, konversationell förfining, upprätthåller samtalskontext över flera frågor, så att följdfrågor kan förfina svaren genom iterativa webbsökningar. Pipeline:ns grundprincip—“du får inte säga något som du inte hämtat”—säkerställer att Sonar-drivna svar är förankrade i verifierbara källor och minskar fundamentalt hallucinationer jämfört med modeller som enbart förlitar sig på träningsdata.
| Aspekt | Traditionell sökning (Google) | Sonar-algoritm (Perplexity) | ChatGPT-rankning | Gemini-rankning | Claude-rankning |
|---|---|---|---|---|---|
| Primär enhet | Rankad länklista | Enkelt syntetiserat svar med citat | Konsensusbaserade entitetsomnämnanden | E-E-A-T-anpassat innehåll | Neutrala, faktabaserade källor |
| Återhämtningsfokus | Nyckelord, länkar, ML-signaler | Hybrid semantisk + nyckelordssökning | Träningsdata + webbläsning | Kunskapsgrafsintegration | Konstitutionella säkerhetsfilter |
| Aktualitetsprioritet | Query-deserves-freshness (QDF) | Realtidswebbhämtning, 37 % lyft inom 48 timmar | Lägre prioritet, träningsdataberoende | Måttlig, integrerad med Google Search | Lägre prioritet, fokus på stabilitet |
| Rankningssignaler | Bakåtlänkar, domänauktoritet, CTR | Innehållets aktualitet, semantisk relevans, citerbarhet, auktoritetsförstärkning | Entitetsigenkänning, konsensusomnämnanden | E-E-A-T, samtalsanpassning, strukturerad data | Transparens, verifierbara citat, neutralitet |
| Citeringsmekanism | URL-snuttar i resultat | Inbäddade citat med källlänkar | Implicit, ofta inga citat | AI-översikter med attribution | Explicit källhänvisning |
| Innehållsmångfald | Flera resultat över sajter | Utvalda få källor för syntes | Syntetiserat från flera källor | Flera källor i översikt | Balanserade, neutrala källor |
| Personaliseringsgrad | Subtil, oftast implicit | Explicita fokuslägen (Webb, Akademiskt, Finans, Skrivande, Socialt) | Implicit baserat på konversation | Implicit utifrån frågetyp | Minimal, fokus på konsekvens |
| PDF-hantering | Standardindexering | 22 % citeringsfördel mot HTML | Standardindexering | Standardindexering | Standardindexering |
| Schemaeffekt | FAQ-schema i featured snippets | FAQ-schema ökar citat med 41 %, minskar citattid med 6 timmar | Minimal direkt påverkan | Måttlig påverkan på kunskapsgraf | Minimal direkt påverkan |
| Latensoptimering | Millisekunder för rankning | Under sekund för hämtning + generering | Sekunder för syntes | Sekunder för syntes | Sekunder för syntes |
Den tekniska grunden för Sonar-algoritmen vilar på en hybridåterhämtningsmotor som kombinerar flera sökstrategier för att maximera både återkallning och precision. Tät återhämtning (vektorsökning) använder semantiska inbäddningar för att förstå den konceptuella betydelsen bakom frågor och hitta kontextuellt liknande dokument även utan exakta nyckelordsöverensstämmelser. Detta angreppssätt använder transformerbaserade inbäddningar som placerar frågor och dokument i högdimensionella vektorrum där semantiskt liknande innehåll grupperas. Gles återhämtning (lexikalisk sökning) kompletterar tät återhämtning genom att ge precision för ovanliga termer, produktnamn, interna företagsidentifierare och specifika entiteter där semantisk tvetydighet är oönskad. Systemet använder rankningsfunktioner som BM25 för att göra exakta matchningar på dessa kritiska termer. Dessa två återhämtningsmetoder slås ihop och avdubbleras för att ge cirka 50 olika kandidatdokument, vilket förhindrar domänöveranpassning och säkerställer bred täckning över flera auktoritativa källor. Efter den initiala återhämtningen använder Sonars neurala omrankningslager avancerade maskininlärningsmodeller (såsom DeBERTa-v3 cross-encoders) för att utvärdera kandidater med en rik uppsättning funktioner inklusive lexikala relevanspoäng, vektorsimilaritet, dokumentauktoritet, aktualitetssignaler, användarengagemang och metadata. Denna flerfasiga rankningsarkitektur gör att Sonar successivt kan förfina resultaten under strikta latenskrav och säkerställer att den slutliga rankade uppsättningen representerar de högst kvalitativa, mest relevanta källorna för syntes. Hela återhämtningsinfrastrukturen är byggd på Vespa AI, en distribuerad sökplattform som klarar webbskalig indexering (200+ miljarder URL:er), realtidsuppdateringar (tiotusentals per sekund) och detaljerad innehållsförståelse genom dokumentchunking. Detta arkitekturval gör att Perplexitys relativt lilla ingenjörsteam kan fokusera på differentierande komponenter—RAG-orkestrering, Sonar-modellens finjustering och inferensoptimering—istället för att återuppfinna distribuerad sökning från grunden.
Innehållets aktualitet är en av Sonars mest kraftfulla rankningssignaler, med empirisk forskning som visar att nyligen uppdaterade sidor får dramatiskt högre citeringsfrekvens. I kontrollerade A/B-tester under 24 veckor över 120 URL:er blev artiklar som uppdaterats inom de senaste 48 timmarna 37 % oftare citerade än identiskt innehåll med äldre tidsstämplar. Denna fördel kvarstod vid cirka 14 % efter två veckor, vilket indikerar att aktualitet ger ett bestående men gradvis avtagande lyft. Mekanismen bakom denna prioritering ligger i Sonars designfilosofi: algoritmen behandlar föråldrat innehåll som högre hallucinationsrisk, eftersom den antar att inaktuell information kan ha ersatts av nyare utveckling. Perplexitys infrastruktur hanterar tiotusentals indexuppdateringsförfrågningar per sekund, vilket möjliggör signaler om realtidsaktualitet. En ML-modell förutser om en URL behöver omindexeras och schemalägger uppdateringar baserat på sidans betydelse och historiska uppdateringsfrekvens, så att värdefullt innehåll uppdateras mer aggressivt. Även mindre kosmetiska ändringar nollställer aktualitetsklockan, förutsatt att CMS publicerar den ändrade tidsstämpeln. För publicister innebär detta ett strategiskt imperativ: antingen anta nyhetsrumsfrekvens med veckovisa eller dagliga uppdateringar, eller se hur evergreen-innehåll gradvis tappar synlighet. Implkationen är djupgående—i Sonar-eran är innehållsvelocity inte en fåfänga utan en överlevnadsmekanism. Varumärken som automatiserar veckovisa mikroändringar, lägger till live changelogs eller upprätthåller kontinuerliga optimeringsprocesser för innehåll kommer att säkra oproportionerligt hög andel citat jämfört med konkurrenter som litar på statiska, sällan uppdaterade sidor.
Sonar prioriterar semantisk relevans framför nyckelordsdensitet, och belönar i grunden innehåll som direkt besvarar användarfrågor på naturligt, konverserande språk. Algoritmens återhämtningssystem använder täta vektor-inbäddningar för att matcha frågor till innehåll på konceptuell nivå, vilket innebär att sidor som använder synonymer, relaterad terminologi eller kontextuellt rikt språk kan överträffa sidor som är fulla av nyckelord men saknar semantiskt djup. Detta skifte från nyckelordscentrerad till meningscentrerad rankning har djupgående betydelse för innehållsstrategi. Innehåll som vinner i Sonar uppvisar flera strukturella kännetecken: det inleder med en kort, faktabaserad sammanfattning innan det går in på detaljer, använder beskrivande H2/H3-rubriker och korta stycken för att förenkla extrahering, inkluderar tydliga källhänvisningar och länkar till primärkällor och har synliga tidsstämplar och versionsanteckningar som signalerar aktualitet. Varje stycke fungerar som en atomisk semantisk enhet, optimerad för copy-paste-klarhet och LLM-förståelse. Tabeller, punktlistor och etiketterade diagram är särskilt värdefulla eftersom de presenterar information i strukturerat, lättciterat format. Algoritmen belönar även egen analys och unik data framför ren aggregering, eftersom Sonars syntesmotor söker källor som tillför nya vinklar, primärdokument eller egna insikter som särskiljer dem från generella översikter. Denna betoning på semantisk rikedom och svarsförst-struktur innebär ett grundläggande avsteg från traditionell SEO, där nyckelordsplacering och länkkraft dominerade. I Sonar-eran måste innehåll byggas för maskinell återhämtning och syntes, inte för mänsklig bläddring.
Publikt tillgängliga PDF:er utgör en betydande, ofta förbisedd fördel i Sonars rankningssystem, där empiriska tester visar att PDF-versioner av innehåll överträffar HTML-ekvivalenter med cirka 22 % i citeringsfrekvens. Denna fördel beror på att Sonars crawler behandlar PDF:er mer gynnsamt än HTML-sidor. PDF:er saknar cookie-banners, JavaScript-krav, betalväggsautentisering och andra HTML-komplikationer som kan fördröja eller fördunkla åtkomst. Sonars crawler kan läsa PDF:er rent och förutsägbart, och extrahera text utan tolkningsproblem som uppstår med komplex HTML. Publicister kan strategiskt utnyttja denna fördel genom att lagra PDF:er i publikt tillgängliga kataloger, använda semantiska filnamn som reflekterar innehållets ämne och signalera PDF:en som kanonisk med <link rel="alternate" type="application/pdf">-taggar i HTML-huvudet. Detta skapar vad forskare beskriver som en “LLM-honungsfälla”—en högsynlig tillgång som konkurrenters spårningsskript inte enkelt kan upptäcka eller övervaka. För B2B-företag, SaaS-leverantörer och forskningsdrivna organisationer är denna strategi särskilt kraftfull: publicering av whitepapers, forskningsrapporter, fallstudier och teknisk dokumentation som PDF kan dramatiskt öka Sonars citeringsfrekvens. Nyckeln är att behandla PDF:en inte som en nedladdningsbar eftertanke utan som en kanonisk kopia värd lika mycket eller mer optimeringsinsats än HTML-versionen. Detta har visat sig särskilt effektivt för företagsinnehåll där PDF:er ofta innehåller mer strukturerad, auktoritativ information än webbsidor.
JSON-LD FAQ-schema ökar Sonars citeringsfrekvens kraftigt, där sidor med tre eller fler FAQ-block får citat 41 % oftare än kontrollsidor utan schema. Denna dramatiska ökning speglar Sonars preferens för strukturerat, chunk-baserat innehåll som harmonierar med dess återhämtnings- och synteslogik. FAQ-schema presenterar diskreta, självständiga Q&A-enheter som algoritmen enkelt kan extrahera, ranka och citera som atomiska semantiska block. Till skillnad från traditionell SEO, där FAQ-schema var ett “nice-to-have”, behandlar Sonar strukturerad Q&A-inmärkning som en central rankningsfaktor. Dessutom citerar Sonar ofta FAQ-frågor som ankartext, vilket minskar risken för kontextförskjutning som kan ske när LLM sammanfattar slumpmässiga meningar mitt i ett stycke. Schemat snabbar också upp tiden till första citat med cirka sex timmar, vilket tyder på att Sonars parser prioriterar strukturerade Q&A-block tidigt i rankningskedjan. För publicister är optimeringsstrategin enkel: bädda in tre till fem riktade FAQ-block under sidbrytningen, med konversationella triggerfraser som speglar riktiga användarfrågor. Frågor bör använda long-tail-sökfraser och semantisk symmetri med sannolika Sonar-frågor. Varje svar bör vara koncist, faktabaserat och direkt svarande, utan utfyllnad eller reklamspråk. Detta har visat sig särskilt effektivt för SaaS-bolag, kliniker och professionella tjänster, där FAQ-innehåll naturligt matchar användarens avsikt och Sonars syntesbehov.
Sonars rankningssystem integrerar flera signaler i ett enhetligt citeringsramverk, där forskningen identifierar åtta huvudfaktorer som påverkar källval och citeringsfrekvens. För det första dominerar semantisk relevans för frågan återhämtningen, med algoritmen som prioriterar innehåll som tydligt besvarar frågan på naturligt språk. För det andra spelar auktoritet och trovärdighet stor roll, där Perplexitys utgivarpartnerskap och algoritmiska förstärkningar gynnar etablerade nyhetsorganisationer, akademiska institutioner och erkända experter. För det tredje får aktualitet exceptionell vikt, som tidigare nämnt, med uppdateringar som utlöser 37 % fler citat. För det fjärde värderas mångfald och täckning, eftersom Sonar föredrar flera högkvalitativa källor framför ensidiga svar, vilket minskar hallucinationsrisken genom korsvalidering. För det femte avgör läge och räckvidd vilka index Sonar söker i—fokuslägen som Akademiskt, Finans, Skrivande och Socialt begränsar källtyper, medan källväljare (Webb, Org-filer, Webb + Org-filer, Ingen) avgör om hämtning sker från öppna webben, interna dokument eller båda. För det sjätte är citerbarhet och åtkomst avgörande; om PerplexityBot kan genomsöka och indexera innehåll är det lättare att citera, vilket gör robots.txt-efterlevnad och sidladdningshastighet viktiga. För det sjunde möjliggör anpassade källfilter via API för företagsdistribution att begränsa eller föredra vissa domäner, vilket förändrar rankningen inom vitlistade samlingar. För det åttonde påverkar konversationskontexten följdfrågor, där sidor som matchar förändrad avsikt överträffar mer generiska referenser. Tillsammans skapar dessa faktorer ett mångdimensionellt rankningsutrymme där framgång kräver optimering över flera dimensioner samtidigt, inte bara en enskild hävstång som bakåtlänkar eller nyckelordsdensitet.
Sonar-algoritmen utvecklas snabbt i takt med framsteg inom LLM-inferens och återhämtningsteknik. Perplexitys teknikblogg lyfte nyligen fram spekulativ decoding, en teknik som halverar tokenlatens genom att förutsäga flera framtida token samtidigt. Snabbare genereringsloopar gör det möjligt för systemet att hämta färskare resultat för varje fråga, vilket pressar det tids
**Sonar-algoritmen** är Perplexitys egenutvecklade rankningssystem som driver dess svarsmotor och är fundamentalt annorlunda än traditionella sökmotorer som Google. Medan Google rankar sidor för att visas i en lista med blå länkar, rankar Sonar innehållssnuttar för syntes till ett enda, enhetligt svar med inbäddade citat. Sonar använder retrieval-augmented generation (RAG), som kombinerar hybrid-sökning (vektorinbäddningar plus nyckelords-matchning), neural omrankning och realtidswebbåterhämtning för att förankra svar i verifierbara källor. Denna metod prioriterar semantisk relevans och innehållets aktualitet över äldre SEO-signaler som bakåtlänkar, vilket gör det till ett unikt rankningsparadigm optimerat för AI-genererad syntes snarare än länkburen auktoritet.
Sonar implementerar en **hybridåterhämtningsmotor** som kombinerar två kompletterande sökstrategier: tät återhämtning (vektorsökning med semantiska inbäddningar) och gles återhämtning (lexikalisk/nyckelordsbaserad sökning med BM25). Tät återhämtning fångar upp konceptuell mening och kontext, vilket gör att systemet kan hitta semantiskt liknande innehåll även utan exakta nyckelordsmatchningar. Gles återhämtning ger precision för ovanliga termer, produktnamn och specifika identifierare där semantisk tvetydighet är oönskad. Dessa två återhämtningsmetoder slås samman och avdubbleras för att generera cirka 50 olika kandidatdokument, vilket förhindrar domänöveranpassning och säkerställer bred täckning. Detta hybrida tillvägagångssätt överträffar system med endast en metod både i återkallning och relevansnoggrannhet.
De viktigaste rankningsfaktorerna för Sonar inkluderar: (1) **Innehållets Aktualitet** – nyligen uppdaterade eller publicerade sidor får 37 % fler citat inom 48 timmar efter uppdatering; (2) **Semantisk Relevans** – innehållet måste direkt besvara frågan på naturligt språk och prioritera tydlighet över nyckelordstäthet; (3) **Auktoritet och Trovärdighet** – källor från etablerade utgivare, akademiska institutioner och nyhetsorganisationer får algoritmiska fördelar; (4) **Citerbarhet** – innehållet måste vara lätt att citera och strukturerat med tydliga rubriker, tabeller och stycken; (5) **Mångfald** – Sonar föredrar flera högkvalitativa källor framför ensidiga svar; och (6) **Teknisk Tillgänglighet** – sidor måste kunna genomsökas av PerplexityBot och ladda snabbt för on demand-läsning.
**Aktualitet är en av Sonars viktigaste rankningssignaler**, särskilt för tidskänsliga ämnen. Perplexitys infrastruktur hanterar tiotusentals indexuppdateringsförfrågningar per sekund, vilket säkerställer att indexet återspeglar den mest aktuella informationen som finns tillgänglig. En ML-modell förutser om en URL behöver omindexeras och schemalägger uppdateringar baserat på sidans betydelse och uppdateringsfrekvens. Vid empiriska tester fick innehåll som uppdaterats inom de senaste 48 timmarna 37 % fler citat än identiskt innehåll med äldre tidsstämplar, och denna fördel kvarstod vid 14 % efter två veckor. Även mindre ändringar nollställer aktualitetsklockan, vilket gör kontinuerlig optimering av innehållet avgörande för att behålla synlighet i Sonar-drivna svar.
**PDF:er är en betydande fördel i Sonars rankningssystem**, och överträffar ofta HTML-versioner av samma innehåll med 22 % i citeringsfrekvens. Sonars crawler behandlar PDF:er fördelaktigt eftersom de saknar cookie-banners, betalväggar, JavaScript-renderingsproblem och andra HTML-komplikationer som kan fördunkla innehållet. Publicister kan optimera PDF-synlighet genom att lagra dem i publikt tillgängliga kataloger, använda semantiska filnamn och signalera PDF:en som kanonisk med ``-taggar i HTML-huvudet. Detta skapar vad forskare kallar en "LLM-honungsfälla" som konkurrenters spårningsskript inte enkelt kan upptäcka, vilket gör PDF:er till ett strategiskt verktyg för att säkra Sonar-citat.
**JSON-LD FAQ-schema ökar Sonars citeringsfrekvens avsevärt**, där sidor med tre eller fler FAQ-block får citat 41 % oftare än kontrollsidor utan schema. FAQ-markeringen passar perfekt med Sonars chunk-baserade återhämtningslogik eftersom den presenterar diskreta, självständiga Q&A-enheter som algoritmen enkelt kan extrahera och citera. Dessutom citerar Sonar ofta FAQ-frågor som ankartext, vilket minskar risken för kontextförskjutning som kan uppstå när LLM summerar slumpmässiga meningar mitt i stycken. Schemat minskar också tiden till första citat med cirka sex timmar, vilket tyder på att Sonars parser prioriterar strukturerade Q&A-block tidigt i rankningskedjan.
Sonar implementerar en **trestegs retrieval-augmented generation (RAG) pipeline** utformad för att förankra svar i verifierad extern kunskap. Steg ett hämtar relevanta dokument med hjälp av hybridsökning; steg två extraherar och kontextualiserar de mest relevanta snuttarna; steg tre syntetiserar ett svar genom att endast använda den tillhandahållna kontexten, med strikt princip: "du får inte säga något som du inte hämtat". Denna arkitektur kopplar tätt samman hämtning och generering, så att varje påstående går att spåra tillbaka till en källa. Inbäddade citat länkar genererad text tillbaka till källdokument, vilket möjliggör användarverifiering. Detta grundningssätt minskar hallucinationer avsevärt jämfört med modeller som enbart litar på träningsdata, vilket gör Sonars svar mer faktamässigt tillförlitliga och trovärdiga.
Medan **ChatGPT prioriterar entitetsigenkänning och konsensus** från sin träningsdata, **betonar Gemini E-E-A-T-signaler och samtalsanpassning**, och **Claude fokuserar på konstitutionell säkerhet och neutralitet**, **prioriterar Sonar unikt realtidsaktualitet och semantiskt djup**. Sonars trelagers maskininlärnings-omrankare tillämpar striktare kvalitetsfilter än traditionell sökning och kastar bort hela resultatuppsättningar om innehållet inte når kvalitetsgränserna. Till skillnad från ChatGPT:s beroende av historiska träningsdata utför Sonar live-webbåterhämtning för varje fråga, vilket säkerställer att svaren återspeglar aktuell information. Sonar skiljer sig också från Geminis kunskapsgrafsintegration genom att betona semantisk relevans på styckenivå och från Claudes neutralitetsfokus genom att acceptera auktoritetsförstärkningar från etablerade utgivare.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig hur Perplexitys Sonar-algoritm driver realtids AI-sökning med kostnadseffektiva modeller. Utforska Sonar, Sonar Pro och Sonar Reasoning-varianter.
Lär dig hur Googles RankBrain AI-system påverkar sökrankningar genom semantisk förståelse, tolkning av användarintention och maskininlärningsalgoritmer som förb...
Lär dig hur Googles AI-rankningssystem såsom RankBrain, BERT och Neural Matching fungerar för att förstå sökfrågor och rangordna webbsidor för relevans och kval...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.