
Strukturerad data
Strukturerad data är standardiserad märkning som hjälper sökmotorer att förstå webbplatsers innehåll. Lär dig hur JSON-LD, schema.org och microdata förbättrar S...
9 min läsning

Schema-markering som är specifikt utformad för att hjälpa AI-system att förstå och citera innehåll korrekt. Strukturerad data använder standardiserade format som JSON-LD för att tillhandahålla explicit kontext om sidans innehåll, vilket gör att stora språkmodeller kan tolka information mer pålitligt och citera källor med större säkerhet.
Schema-markering som är specifikt utformad för att hjälpa AI-system att förstå och citera innehåll korrekt. Strukturerad data använder standardiserade format som JSON-LD för att tillhandahålla explicit kontext om sidans innehåll, vilket gör att stora språkmodeller kan tolka information mer pålitligt och citera källor med större säkerhet.
Strukturerad data för AI avser organiserad, maskinläsbar information formaterad enligt standardiserade scheman som gör det möjligt för artificiell intelligens att förstå, tolka och använda innehåll med precision. Till skillnad från ostrukturerad text, som kräver komplex naturlig språkbehandling för att tyda betydelse, ger strukturerad data explicit kontext om vad informationen representerar. Denna tydlighet är avgörande eftersom AI-system—särskilt stora språkmodeller och sökmotorer—bearbetar miljarder datapunkter dagligen. När innehåll struktureras med standarder som schema.org, JSON-LD eller microdata kan AI omedelbart identifiera entiteter, relationer och attribut utan tvetydighet. Detta strukturerade tillvägagångssätt ger 300% högre noggrannhet i AI-förståelse jämfört med ostrukturerade alternativ. För organisationer som vill synas i AI Overviews och andra AI-genererade resultat har strukturerad data blivit en icke-förhandlingsbar infrastruktur. Det förvandlar rått innehåll till intelligens som AI-system tryggt kan citera, referera och integrera i sina svar, vilket i grunden förändrar hur digitalt innehåll uppnår synlighet i en AI-driven värld.

AI-system behandlar strukturerad data genom en sofistikerad process som omvandlar markerat innehåll till användbar intelligens. När ett AI-system stöter på korrekt formaterad strukturerad data kan det omedelbart extrahera nyckelinformation utan den beräkningsmässiga belastning som krävs för naturlig språk-tolkning. Den tekniska processen följer dessa huvudsteg:
Denna process gör det möjligt för AI att leverera 30%+ högre synlighet i AI Overviews för korrekt strukturerat innehåll. Det strukturerade tillvägagångssättet minskar risken för hallucinationer genom att förankra AI-svar i explicit, verifierbar data istället för sannolikhetsbaserad textgenerering. Organisationer som implementerar omfattande strategier för strukturerad data ser mätbara förbättringar i hur AI-system upptäcker, förstår och marknadsför deras innehåll över flera plattformar och applikationer.
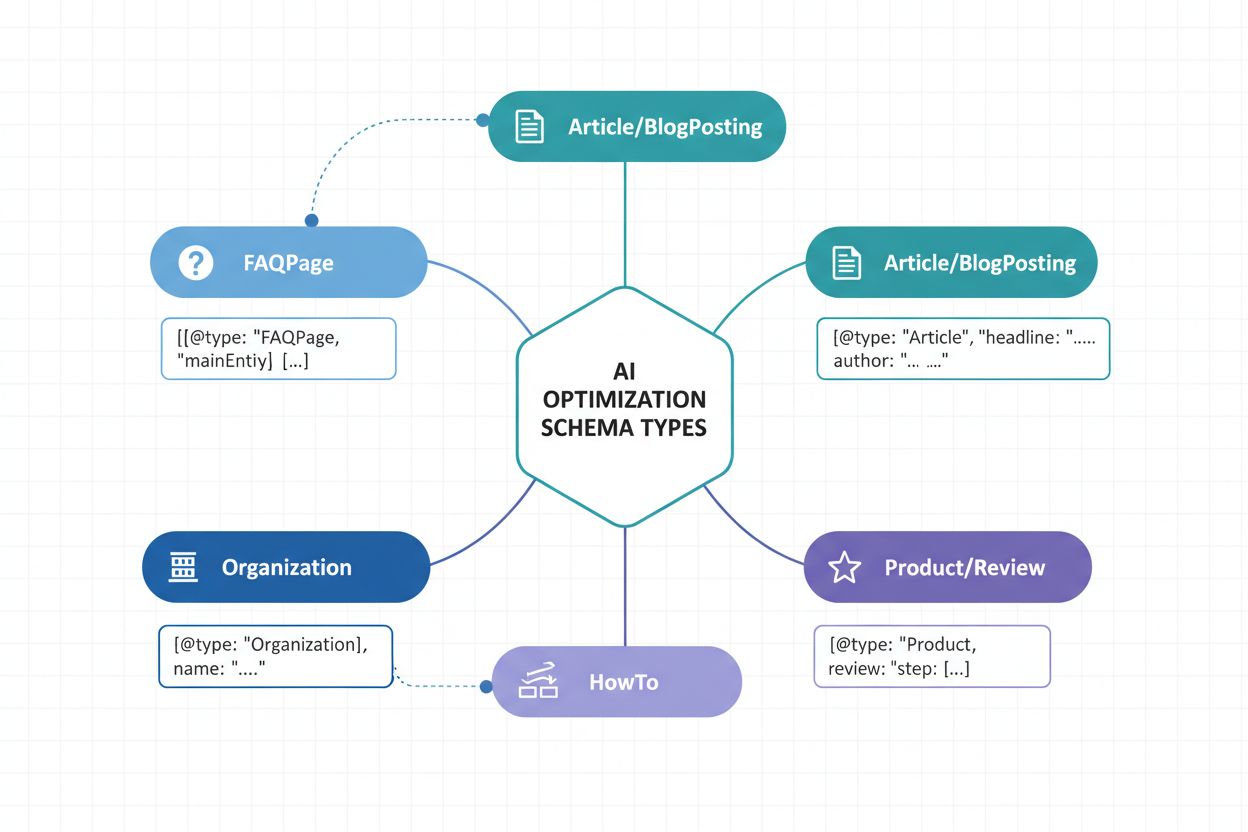
Att implementera rätt schema-typer är grundläggande för AI-synlighetsstrategin. Olika innehållstyper kräver specifik strukturerad data-markering för att kommunicera sitt syfte och värde till AI-system. Här är de viktigaste schema-typerna för maximal AI-igenkänning:
Article Schema – Markerar upp nyhetsartiklar, blogginlägg och längre innehåll med rubrik, författare, publiceringsdatum och huvudinnehåll. Avgörande för AI-system som identifierar auktoritativa källor och fastställer publicerings-trovärdighet.
Organization Schema – Definierar företagsidentitet, inklusive namn, logotyp, kontaktuppgifter och sociala profiler. Gör att AI kan känna igen och korrekt tillskriva organisationsinnehåll i olika sammanhang.
Product Schema – Strukturerar produktinformation inklusive namn, beskrivning, pris, tillgänglighet och recensioner. Viktigt för e-handelssynlighet i AI-shoppingassistenter och produktsystem för rekommendationer.
LocalBusiness Schema – Markerar upp företagsplats, öppettider, kontaktuppgifter och tjänster. Avgörande för lokala AI-frågor och platsbaserade AI Overviews som alltmer dominerar sökresultat.
BreadcrumbList Schema – Definierar webbplatsens navigationshierarki, vilket hjälper AI att förstå innehållsstruktur och relationer mellan sidor i din informationsarkitektur.
FAQPage Schema – Strukturerar vanliga frågor med svar, vilket gör att AI-system direkt kan extrahera och citera specifika Q&A i sina svar.
NewsArticle och BlogPosting Scheman – Specialiserade artikelscheman som signalerar innehållskategori till AI-system, vilket förbättrar kategoriseringsnoggrannhet och relevansmatchning.
Event Schema – Markerar upp evenemangsdetaljer som datum, plats, beskrivning och registreringsinformation, vilket är nödvändigt för AI-evenemangsupptäckt och kalenderintegration.
För närvarande använder 45 miljoner domäner schema.org-markering, vilket motsvarar 12,4% av alla domäner globalt. Organisationer som implementerar flera schema-typer samtidigt ser sammansatta synlighetsfördelar, då AI-system får rikare kontextuell förståelse för deras innehåll.
Lyckad implementering av strukturerad data kräver strategisk planering och teknisk noggrannhet. Organisationer bör följa dessa etablerade bästa praxis för att maximera AI-synlighet och säkerställa datanoggrannhet:
Här är ett praktiskt JSON-LD-exempel för en artikel:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Strukturerad data för AI: Strategisk implementeringsguide",
"author": {
"@type": "Person",
"name": "Content Author"
},
"datePublished": "2024-01-15",
"image": "https://example.com/image.jpg",
"articleBody": "Full article text here...",
"publisher": {
"@type": "Organization",
"name": "Your Organization",
"logo": "https://example.com/logo.png"
}
}
Korrekt implementering ger 35% förbättring av klickfrekvens från rika resultat i traditionell sökning, med ytterligare fördelar i takt med att AI Overviews blir den främsta kanalen för upptäckt. Organisationer som övervakar prestandan för sin strukturerade data med lösningar som AmICited.com får ett konkurrensförsprång genom att identifiera vilka innehållstyper och schema-implementeringar som ger högst AI-synlighet.
Både strukturerad data och llms.txt tjänar AI-upptäckbarhet men fungerar genom fundamentalt olika mekanismer. Strukturerad data använder standardiserade scheman (schema.org, JSON-LD) inbäddade i HTML för att märka upp specifika innehållselement med explicit semantisk betydelse. Detta tillvägagångssätt integreras direkt i webbsidor, vilket gör informationen omedelbart tillgänglig för både sökmotorer och AI-system vid genomsökning. Strukturerad data möjliggör detaljerad markering av enskilda artiklar, produkter, evenemang och organisationer, vilket gör att AI kan förstå exakta relationer och attribut.
llms.txt, däremot, är en textfil placerad i webbplatsens rotkatalog med instruktioner och riktlinjer för stora språkmodeller. Den fungerar som en manifestfil som kommunicerar preferenser om hur AI-system ska interagera med och citera ditt innehåll. Även om llms.txt ger övergripande vägledning kring användningsrättigheter och citeringspreferenser, saknar den den semantiska precisionen hos strukturerad data. Strukturerad data svarar på frågan “vad är detta innehåll?” med explicita, maskinläsbara svar, medan llms.txt svarar på “hur bör du använda detta innehåll?” som vägledning.
Den mest effektiva strategin kombinerar båda tillvägagångssätten: strukturerad data säkerställer att AI-system korrekt förstår och kan citera ditt innehåll, medan llms.txt etablerar tydliga användningspolicyer och krav för attribution. Organisationer som implementerar båda ser 36% större sannolikhet att synas i AI-genererade sammanfattningar jämfört med de som inte använder något av dessa tillvägagångssätt. Strukturerad data utgör grunden för AI-förståelse, medan llms.txt utgör styrningsramverket för korrekt attribution och efterlevnad.
Att mäta effektiviteten av strukturerad data kräver spårning av specifika mått som visar hur AI-system upptäcker, förstår och citerar ditt innehåll. Organisationer bör övervaka dessa nyckeltal:
AmICited.com erbjuder specialiserad övervakning av AI-citatprestanda, vilket gör det möjligt för organisationer att spåra hur deras investeringar i strukturerad data omsätts i faktisk AI-synlighet och attribution. Plattformen visar vilket innehåll som får AI-citat, vilka frågor som triggar ditt innehåll och hur din citatsfrekvens står sig mot konkurrenter. Detta datadrivna tillvägagångssätt omvandlar implementering av strukturerad data från teoretisk bästa praxis till mätbar affärseffekt.
Organisationer som implementerar omfattande strategier för strukturerad data rapporterar att 93% av frågor besvaras av AI utan klick, vilket gör citatsynlighet alltmer avgörande för att driva trafik. Att mäta citatprestanda säkerställer att dina investeringar i strukturerad data ger kvantifierbara resultat genom förbättrad AI-upptäckbarhet och varumärkesattribution.
Lyckad implementering av strukturerad data följer en fasindelad process som gradvis bygger upp förmåga samtidigt som den levererar mätbart värde i varje steg. Organisationer bör strukturera sin implementation enligt följande:
Fas 1: Grund (Månad 1–2)
Fas 2: Expansion (Månad 3–4)
Fas 3: Optimering (Månad 5–6)
Fas 4: Strategisk integration (Månad 7+)
Denna tidslinje gör det möjligt för organisationer att uppnå betydande förbättringar av AI-synlighet inom 2–3 månader samtidigt som de bygger mot en omfattande, företagsövergripande infrastruktur för strukturerad data. Tidiga användare av denna färdplan får konkurrensfördelar i takt med att AI Overviews blir den främsta kanalen för upptäckt.
Strukturerad data har utvecklats från ett valfritt SEO-tillägg till en nödvändig strategisk infrastruktur i ett AI-drivet digitalt landskap. Eftersom AI-system i allt högre grad styr hur användare hittar information riskerar organisationer utan omfattande strukturerad data systematiska synlighetsnackdelar. Förändringen återspeglar en grundläggande förändring i informationsflödet: traditionell sök krävde att användare klickade sig in på webbplatser, men AI Overviews besvarar frågor direkt, vilket gör citatsynlighet till den nya konkurrensarenan.
Organisationer som strategiskt implementerar strukturerad data positionerar sig för långsiktig framgång över flera AI-plattformar och nya upptäcktskanaler. Infrastrukturinvesteringen ger utdelning bortom omedelbar AI-synlighet—strukturerad data förbättrar intern innehållshantering, möjliggör bättre personalisering, stödjer optimering för röstsök och skapar dataresurser värdefulla för framtida AI-applikationer. Tidiga användare som etablerar omfattande strukturerad data får sammansatta fördelar när AI-system i allt högre grad prioriterar väl markerat innehåll.
Konkurrensfördelen av tidig implementering kan inte överskattas. I takt med att allt fler inser betydelsen av strukturerad data blir implementering en hygienfaktor för synlighet. Organisationer som etablerar robust infrastruktur för strukturerad data nu kommer att dominera AI-genererade resultat i takt med att dessa kanaler mognar. Omvänt får organisationer som väntar med implementering allt svårare att nå synlighet när AI-system lär sig föredra helt markerat innehåll. Strukturerad data är inte bara en teknisk implementation, utan ett fundamentalt strategiskt åtagande för att förbli upptäckbar och citerbar i ett AI-medierat informations-ekosystem.
Strukturerad data påverkar inte Googles ranking direkt, men förbättrar avsevärt utseendet på sökresultat genom rika utdrag, vilket ökar klickfrekvensen med upp till 35%. För AI-system har strukturerad data en mer direkt inverkan på om ditt innehåll citeras i AI-genererade svar.
Ja, AI-system bearbetar strukturerad data både under träning och vid realtidsfrågor. Även om OpenAI inte har gjort några offentliga uttalanden, tyder bevis på att GPTBot och andra AI-crawlers tolkar JSON-LD-markering. Microsoft har officiellt bekräftat att Bings AI-system använder schema-markering för att bättre förstå innehåll.
JSON-LD är det rekommenderade formatet eftersom det separerar schema från HTML-innehåll, vilket gör det enklare att implementera och underhålla i stor skala. Google rekommenderar uttryckligen JSON-LD och det är mindre benäget för implementeringsfel än Microdata eller RDFa.
Rika utdrag kan visas inom 1–4 veckor efter implementering. Förbättringar i klickfrekvens är ofta mätbara inom 2 veckor. För förbättringar av AI-citat, räkna med 4–8 veckor för att grundarbetet ska ge effekt, med fördelar för auktoritetsuppbyggnad som ökar över 3–6 månader.
Prioritera schema-markering först—det är beprövat och allmänt stöds. llms.txt är fortfarande en framväxande standard med begränsat antagande bland AI-crawlers. Om du är ett utvecklarfokuserat företag med omfattande dokumentation kan det lilla arbetet med att skapa llms.txt vara värt för framtidssäkring.
Börja med Organization-schema på din startsida (med sameAs-egenskaper), sedan Article-schema på viktiga innehållssidor. FAQPage-schema ska vara nästa steg—det är mest direkt användbart för AI-extraktion. Därefter lägger du till HowTo-schema till guider och SoftwareApplication-schema till produktsidor.
Endast felaktigt implementerad markering skadar prestandan. Googles riktlinjer är tydliga: använd relevanta schema-typer som matchar synligt innehåll, håll priser och datum korrekta och markera inte upp innehåll som användare inte kan se. Validera alltid med Googles Rich Results Test innan publicering.
Strukturerad data ger explicit kontext som hjälper AI-system att förstå vad informationen representerar—entiteter, relationer, attribut. Denna tydlighet gör att AI tryggt kan extrahera och citera ditt innehåll. LLM:er grundade i kunskapsgrafer uppnår 300% högre noggrannhet jämfört med de som enbart förlitar sig på ostrukturerad data.
Spåra hur AI-system citerar ditt innehåll på ChatGPT, Perplexity, Google AI Overviews och andra plattformar. Få realtidsinsyn i din AI-närvaro.
Strukturerad data är standardiserad märkning som hjälper sökmotorer att förstå webbplatsers innehåll. Lär dig hur JSON-LD, schema.org och microdata förbättrar S...
Lär dig hur AI-crawlers bearbetar strukturerad data. Upptäck varför JSON-LD-implementeringen är avgörande för synlighet i ChatGPT, Perplexity, Claude och Google...

Lär dig hur jämförande innehållsstrukturer optimerar information för AI-system. Upptäck varför AI-plattformar föredrar jämförelsetabeller, matriser och sida-vid...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.