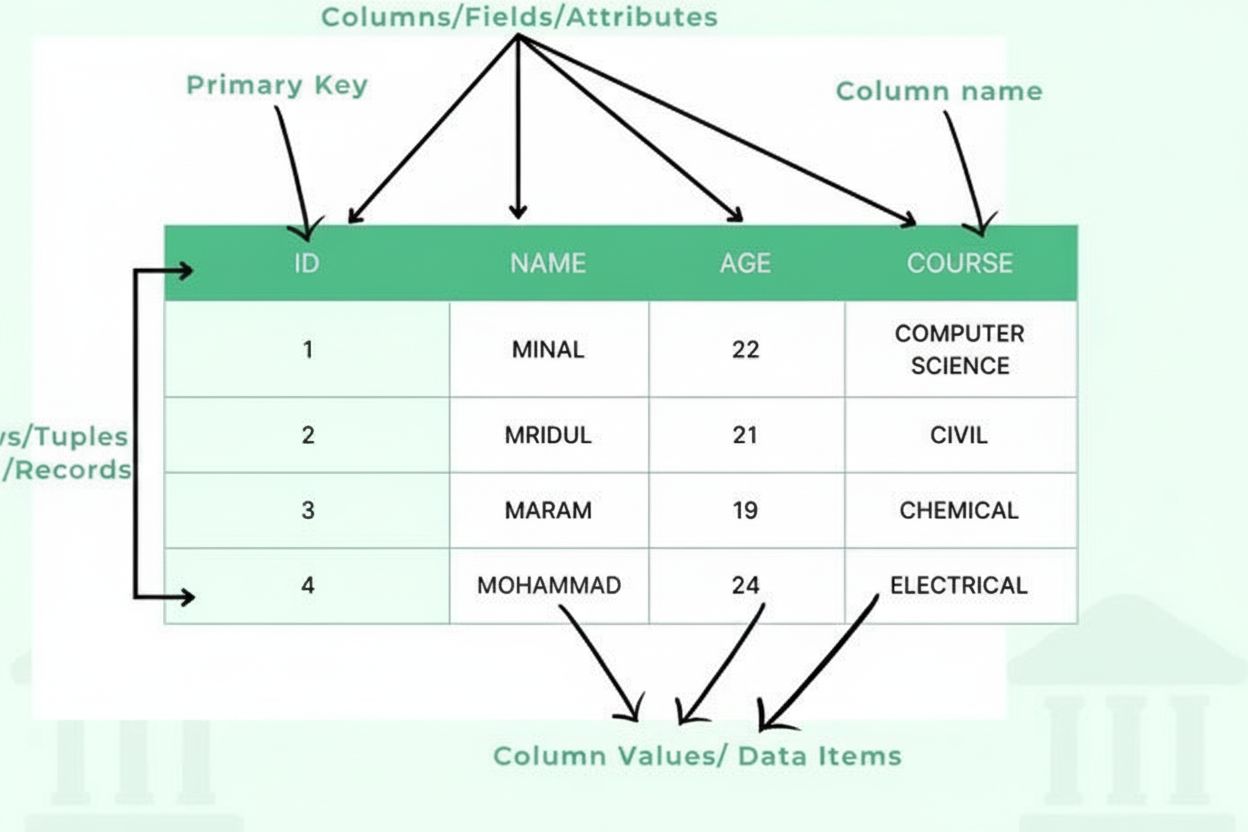
Definition av tabell: Organiserad data i rader och kolumner
En tabell är en grundläggande datastruktur som organiserar information i ett tvådimensionellt rutnätsformat bestående av horisontella rader och vertikala kolumner. I sin enklaste form representerar en tabell en samling relaterad data som är ordnad på ett strukturerat sätt där varje korsning mellan rad och kolumn innehåller ett enskilt dataelement eller cell. Tabeller fungerar som hörnstenen i relationsdatabaser, kalkylblad, datalager och praktiskt taget alla system som kräver organiserad informationslagring och åtkomst. Styrkan hos tabeller ligger i deras förmåga att möjliggöra snabb visuell översikt, logisk jämförelse av data över flera dimensioner samt programmatisk åtkomst till specifik information via standardiserade frågespråk. Oavsett om de används i affärsanalys, vetenskaplig forskning eller AI-övervakningsplattformar ger tabeller ett universellt förståeligt format för presentation av strukturerad data som lätt kan tolkas av både människor och maskiner.
Historisk kontext och utveckling av tabulär dataorganisation
Konceptet att organisera information i rader och kolumner är flera hundra år äldre än modern databehandling. Forntida civilisationer använde tabulära format för att dokumentera lager, finansiella transaktioner och astronomiska observationer. Den formella etableringen av tabellstrukturer inom databehandling uppstod dock med utvecklingen av relationsdatabasteori av Edgar F. Codd 1970, vilket revolutionerade hur data kunde lagras och sökas. Den relationella modellen fastslog att data bör organiseras i tabeller med tydligt definierade relationer, vilket i grunden förändrade principerna för databasutformning. Under 1980- och 1990-talen demokratiserade kalkylbladsapplikationer som Lotus 1-2-3 och Microsoft Excel användningen av tabeller och gjorde tabulär dataorganisation tillgänglig för icke-tekniska användare. Idag använder cirka 97 % av organisationerna kalkylbladsapplikationer för datalagring och analys, vilket visar på den bestående betydelsen av tabellbaserad dataorganisation. Utvecklingen fortsätter med moderna lösningar som kolumnära databaser, NoSQL-system och data lakes, som utmanar traditionella radorienterade tillvägagångssätt men fortfarande upprätthåller grundläggande tabelliknande strukturer för informationsorganisation.
Kärnkomponenter och struktur för tabeller
En tabell består av flera väsentliga strukturella komponenter som samverkar för att skapa en organiserad data-ram. Kolumner (även kallade fält eller attribut) löper vertikalt och representerar informationskategorier, såsom “Kundnamn”, “E-postadress” eller “Köpedatum”. Varje kolumn har en definierad datatyp som anger vilken typ av information den kan innehålla – heltal, textsträngar, datum, decimaltal eller mer komplexa strukturer. Rader (även kallade poster eller tupler) löper horisontellt och representerar individuella datainmatningar eller entiteter, där varje rad innehåller en komplett post. Korsningen mellan en rad och en kolumn skapar en cell eller ett dataelement som innehåller en enskild informationsbit. Kolumnrubriker identifierar varje kolumn och visas högst upp i tabellen och ger sammanhang för datan nedanför. Primärnycklar är särskilda kolumner som unikt identifierar varje rad och säkerställer att inga dubblettposter finns. Främmande nycklar etablerar relationer mellan tabeller genom att referera till primärnycklar i andra tabeller. Denna hierarkiska organisation gör det möjligt för databaser att upprätthålla dataintegritet, förhindra redundans och stödja komplexa frågor som hämtar information baserat på flera kriterier.
Jämförelse av tabellorganisationsmetoder
| Aspekt | Radorienterade tabeller | Kolumnorienterade tabeller | Hybridmetoder |
|---|
| Lagringsmetod | Data lagras och hämtas per komplett post | Data lagras och hämtas per enskild kolumn | Kombinerar fördelar av båda tillvägagångssätten |
| Frågeprestanda | Optimerad för transaktionsfrågor som hämtar hela poster | Optimerad för analytiska frågor på specifika kolumner | Balanserad prestanda för blandade arbetsbelastningar |
| Användningsområden | OLTP (Online Transaction Processing), affärsverksamhet | OLAP (Online Analytical Processing), datalager | Realtidsanalys, operationell intelligens |
| Databasexempel | MySQL, PostgreSQL, Oracle, SQL Server | Vertica, Cassandra, HBase, Parquet | Snowflake, BigQuery, Apache Iceberg |
| Komprimeringseffektivitet | Lägre komprimeringsgrad p.g.a. datamångfald | Högre komprimeringsgrad för liknande kolumnvärden | Optimerad komprimering för specifika mönster |
| Skrivprestanda | Snabb skrivning av kompletta poster | Långsammare skrivning som kräver kolumnuppdateringar | Balanserad skrivprestanda |
| Skalbarhet | Skalar bra för transaktionsvolym | Skalar bra för datavolym och frågekomplexitet | Skalar för båda dimensionerna |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Teknisk implementering och databasarkitektur
I relationsdatabashanteringssystem (RDBMS) implementeras tabeller som strukturerade samlingar av rader där varje rad följer ett fördefinierat schema. Schemat definierar tabellens struktur, inklusive kolumnnamn, datatyper, begränsningar och relationer. När data infogas i en tabell validerar databashanteringssystemet att varje värde matchar sin kolumns datatyp och uppfyller eventuella definierade begränsningar. Till exempel kommer en kolumn definierad som INTEGER att avvisa textvärden och en kolumn markerad som NOT NULL kommer att avvisa tomma inmatningar. Index skapas på ofta frågade kolumner för att snabba upp datahämtning och fungerar som organiserade referenser som gör det möjligt för databasen att hitta specifika rader utan att skanna hela tabellen. Normalisering är en designprincip som organiserar tabeller för att minimera dataredundans och förbättra dataintegritet genom att dela upp information i relaterade tabeller som kopplas samman med hjälp av nycklar. Moderna databaser stöder transaktioner, vilket säkerställer att flera operationer på tabeller antingen lyckas fullt ut eller misslyckas tillsammans och därmed upprätthåller konsistens även vid systemfel. Frågeoptimeraren i databasmotorer analyserar SQL-frågor och avgör det mest effektiva sättet att komma åt tabelldata med hänsyn till tillgängliga index och tabellstatistik.
Datapresentation och visualisering i tabeller
Tabeller fungerar som det primära verktyget för att presentera strukturerad data för användare både digitalt och i tryck. I affärsintelligens- och analysapplikationer visar tabeller aggregerade mått, prestationsindikatorer och detaljerade transaktionsposter som ger beslutsfattare möjlighet att förstå komplexa datamängder snabbt. Forskning visar att 83 % av affärsproffs förlitar sig på datatabeller som sitt huvudsakliga verktyg för informationsanalys, eftersom tabeller möjliggör exakt värdejämförelse och mönsterigenkänning. HTML-tabeller på webbsidor använder semantisk markup med <table>, <tr> (tabellrad), <td> (tabellcell) och <th> (tabellrubrik) för att strukturera data för både visuell presentation och programmatisk tolkning. Kalkylbladsapplikationer som Microsoft Excel, Google Sheets och LibreOffice Calc utökar grundläggande tabellfunktionalitet med formler, villkorsstyrd formatering och pivottabeller, vilket gör att användare kan utföra beräkningar och omorganisera data dynamiskt. Best practice för datavisualisering rekommenderar att använda tabeller när exakta värden är viktigare än visuella mönster, vid jämförelse av flera attribut för individuella poster eller när användare behöver göra uppslag eller beräkningar. W3C Web Accessibility Initiative betonar att korrekt strukturerade tabeller med tydliga rubriker och lämplig markup är avgörande för att göra data tillgänglig för användare med funktionsnedsättning, särskilt de som använder skärmläsare.
Tabeller inom AI-övervakning och innehållsspårning
Inom ramen för AI-övervakningsplattformar som AmICited spelar tabeller en avgörande roll för att organisera och presentera data om hur innehåll förekommer över olika AI-system. Övervakningstabeller spårar mätvärden som citeringsfrekvens, förekomstdatum, AI-plattforms-källor (ChatGPT, Perplexity, Google AI Overviews, Claude) och kontextuell information om hur domäner och URL:er refereras. Dessa tabeller gör det möjligt för organisationer att förstå sin varumärkesexponering i AI-genererade svar och identifiera trender i hur olika AI-system citerar eller refererar till deras innehåll. Den strukturerade karaktären hos övervakningstabeller möjliggör filtrering, sortering och aggregering av citeringsdata, vilket gör det möjligt att besvara frågor som “Vilka av våra URL:er förekommer oftast i Perplexity-svar?” eller “Hur har vår citeringsfrekvens förändrats under den senaste månaden?” Datatabeller i övervakningssystem möjliggör även jämförelser över flera dimensioner – jämföra citeringsmönster mellan olika AI-plattformar, analysera citeringstillväxt över tid eller identifiera vilka innehållstyper som får flest AI-referenser. Möjligheten att exportera övervakningsdata från tabeller till rapporter, dashboards och vidare analysverktyg gör tabeller oumbärliga för organisationer som vill förstå och optimera sin närvaro i AI-genererat innehåll.
Effektiv tabellutformning kräver noggrann övervägning av struktur, namngivningskonventioner och principer för dataorganisation. Kolumnnamn bör använda tydliga, beskrivande identifierare som korrekt återspeglar datan de innehåller, och undvika förkortningar som kan förvirra användare eller utvecklare. Val av datatyper är avgörande – rätt typ förhindrar ogiltig datainmatning och möjliggör korrekt sortering och jämförelse. Primärnyckelsdefinition säkerställer att varje rad kan identifieras unikt, vilket är viktigt för dataintegritet och etablering av relationer med andra tabeller. Normalisering minskar dataredundans genom att organisera information i relaterade tabeller istället för att lagra dubblettdata på flera platser. Indexeringsstrategi bör balansera frågeprestanda mot den overhead som uppstår vid indexunderhåll under datamodifieringar. Dokumentation av tabellstruktur, inklusive kolumndefinitioner, datatyper, begränsningar och relationer, är avgörande för långsiktig underhållbarhet. Åtkomstkontroll bör implementeras för att säkerställa att känslig data i tabeller skyddas mot obehörig åtkomst. Prestandaoptimering innebär att övervaka frågeexekveringstider och justera tabellstrukturer, index eller frågor för att förbättra effektiviteten. Backup- och återställningsrutiner måste etableras för att skydda tabelldata mot förlust eller korruption.
Grundläggande aspekter av tabellorganisation och hantering
- Strukturella komponenter: Tabeller består av kolumner (fält), rader (poster), rubriker, dataelement (celler), datatyper, primärnycklar och främmande nycklar som tillsammans skapar organiserade datastrukturer
- Dataintegritet: Begränsningar, valideringsregler och nyckelrelationer upprätthåller datakvalitet och förhindrar inkonsekvenser eller dubblettposter
- Frågeeffektivitet: Rätt indexering, normalisering och frågeoptimering möjliggör snabb hämtning av specifik information från stora tabeller
- Tillgänglighet: Semantisk HTML-markup, tydliga rubriker och korrekt struktur gör tabeller tillgängliga för användare med funktionsnedsättning och hjälpmedel
- Skalbarhet: Välutformade tabeller kan effektivt hantera ökande datavolymer med hjälp av lämplig indexering, partitionering och databasoptimering
- Relationshantering: Främmande nycklar skapar kopplingar mellan tabeller och möjliggör komplexa frågor som kombinerar information från flera källor
- Datatypstyrning: Definierade datatyper säkerställer att endast giltig information lagras i varje kolumn, förhindrar fel och möjliggör korrekt sortering
- Dokumentation och underhåll: Tydlig dokumentation av tabellstruktur och regelbundet underhåll säkerställer långsiktig användbarhet och prestanda
Utveckling och framtid för tabellbaserad dataorganisation
Framtiden för tabellbaserad dataorganisation utvecklas för att möta alltmer komplexa datakrav samtidigt som de grundläggande principer som gör tabeller effektiva bibehålls. Kolumnära lagringsformat som Apache Parquet och ORC blir standard i big data-miljöer och optimerar tabeller för analytiska arbetslaster samtidigt som den tabulära strukturen bibehålls. Semistrukturerad data i JSON- och XML-format lagras allt oftare i tabellkolumner, vilket gör att tabeller kan hantera både strukturerad och flexibel data. Maskinintegrering gör det möjligt för databaser att automatiskt optimera tabellstrukturer och frågeexekvering baserat på användningsmönster. Realtidsanalysplattformar utökar tabeller för att stödja strömmande data och kontinuerliga uppdateringar, vilket går bortom traditionella batchinriktade tabelloperationer. Molnbaserade databaser omdesignar tabellimplementationer för att dra nytta av distribuerad databehandling, vilket gör det möjligt för tabeller att skala över flera servrar och geografiska regioner. Datastyrningsramverk lägger större vikt vid tabellmetadata, härledningsspårning och kvalitetsmått för att säkerställa datatillförlitlighet. Framväxten av AI-drivna dataplattformar skapar nya möjligheter för tabeller att fungera som strukturerade källor för träning av maskininlärningsmodeller, samtidigt som frågor väcks om hur tabeller bör utformas för att ge högkvalitativ träningsdata. I takt med att organisationer fortsätter att generera exponentiellt mer data förblir tabeller den grundläggande strukturen för att organisera, fråga och analysera information, där innovationer fokuserar på förbättrad prestanda, skalbarhet och integration med modern datateknik.