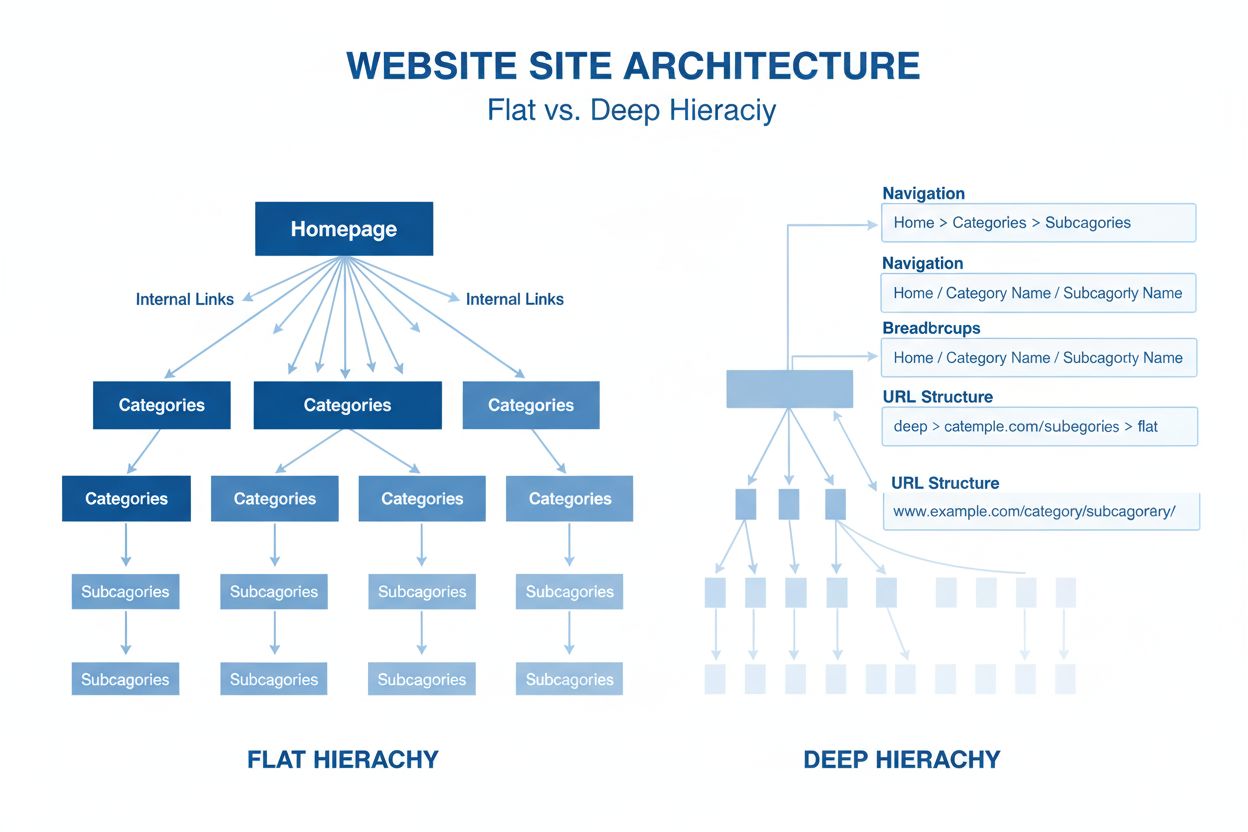
Webbplatsarkitektur
Webbplatsarkitektur är den hierarkiska organisationen av webbplatsens sidor och innehåll. Lär dig hur en korrekt webbplatsstruktur förbättrar SEO, användarupple...
8 min läsning

En neuronnätsarkitektur baserad på multi-head self-attention-mekanismer som behandlar sekventiell data parallellt, vilket möjliggör utvecklingen av moderna stora språkmodeller som ChatGPT, Claude och Perplexity. Introducerad i den banbrytande artikeln ‘Attention is All You Need’ från 2017 har transformerarkitekturen blivit den grundläggande teknologin bakom praktiskt taget alla toppmoderna AI-system.
En neuronnätsarkitektur baserad på multi-head self-attention-mekanismer som behandlar sekventiell data parallellt, vilket möjliggör utvecklingen av moderna stora språkmodeller som ChatGPT, Claude och Perplexity. Introducerad i den banbrytande artikeln 'Attention is All You Need' från 2017 har transformerarkitekturen blivit den grundläggande teknologin bakom praktiskt taget alla toppmoderna AI-system.
Transformerarkitektur är en banbrytande neuronnätsdesign som introducerades i den inflytelserika artikeln “Attention is All You Need” från 2017 av forskare på Google. Arkitekturen bygger i grunden på multi-head self-attention-mekanismer som gör det möjligt för modeller att behandla hela dataserier parallellt, istället för sekventiellt. Arkitekturen består av staplade kodar- och avkodarlager, där varje lager innehåller self-attention-dellager och feed-forward-neuronnät, sammankopplade via residuala kopplingar och lagernormalisering. Transformerarkitekturen har blivit den grundläggande teknologin bakom praktiskt taget alla moderna stora språkmodeller (LLMs), inklusive ChatGPT, Claude, Perplexity och Google AI Overviews, och är utan tvekan den viktigaste neuronnätsinnovationen under det senaste decenniet.
Betydelsen av Transformerarkitektur sträcker sig långt bortom dess tekniska elegans. Den ursprungliga artikeln “Attention is All You Need” från 2017 har citerats över 208 000 gånger och är en av de mest inflytelserika forskningsartiklarna i maskininlärningens historia. Arkitekturen förändrade i grunden hur AI-system bearbetar och förstår språk och möjliggjorde utvecklingen av modeller med miljarder parametrar som kan utföra sofistikerad slutledning, kreativt skrivande och komplex problemlösning. Företagsmarknaden för LLM:er, som nästan helt bygger på transformer-teknologi, värderades till 6,7 miljarder USD år 2024 och förväntas växa med en årlig tillväxttakt (CAGR) på 26,1 % fram till 2034, vilket visar arkitekturens avgörande betydelse för modern AI-infrastruktur.
Utvecklingen av Transformerarkitektur markerar ett avgörande ögonblick i djupinlärningens historia, efter decennier av forskning om neuronnät för sekventiell databehandling. Innan transformerarkitekturen dominerade rekurrenta neuronnät (RNNs) och deras varianter, särskilt long short-term memory (LSTM)-nätverk, uppgifter inom naturlig språkbehandling. Dessa arkitekturer hade dock grundläggande begränsningar: de behandlade sekvenser sekventiellt, ett element i taget, vilket gjorde dem långsamma att träna och svaga på att fånga beroenden mellan avlägsna element i långa sekvenser. Vanishing gradient-problemet begränsade ytterligare RNN:ers förmåga att lära sig långväga relationer, eftersom gradienterna blev exponentiellt mindre bakåt genom många lager.
Introduktionen av attention-mekanismer år 2014 av Bahdanau med flera var ett genombrott, som gjorde det möjligt för modeller att fokusera på relevanta delar av en indata oavsett avstånd. Attention användes dock initialt som ett komplement till RNNs snarare än som ersättning. Transformermodellen från 2017 tog konceptet längre och föreslog att attention är allt som behövs—det vill säga att ett helt neuronnät kan byggas med enbart attention-mekanismer och feed-forward-lager, helt utan rekurrens. Denna insikt blev avgörande. Genom att ta bort sekventiell bearbetning möjliggjorde transformerarkitekturen massiv parallellisering, vilket gjorde det möjligt att träna på aldrig tidigare skådade datamängder med hjälp av GPUs och TPUs. Den största transformermodellen i originalartikeln, tränad på 8 GPU:er i 3,5 dagar, visade att skala och parallellisering kan leda till dramatiskt förbättrad prestanda.
Efter den ursprungliga transformerartikeln utvecklades arkitekturen snabbt. BERT (Bidirectional Encoder Representations from Transformers), släppt av Google 2019, visade att kodardelen kunde förtränas på massiva textkorpusar och finjusteras för en mängd olika uppgifter. BERT:s största modell hade 345 miljoner parametrar och tränades på 64 specialiserade TPUs i fyra dagar till en uppskattad kostnad av 7 000 USD, men nådde ändå toppresultat inom många språkförståelsetester. Samtidigt tog OpenAI:s GPT-serie en annan väg och använde endast avkodararkitektur, tränad på språkmodellering. GPT-2 med 1,5 miljarder parametrar överraskade forskarvärlden genom att visa att enbart språkmodellering kunde ge mycket kapabla system. GPT-3, med 175 miljarder parametrar, visade emergenta förmågor—egenskaper som bara uppträdde vid tillräcklig skala, som fåskottsinlärning och komplex slutledning—vilket fundamentalt förändrade förväntningarna på vad AI-system kan åstadkomma.
Transformerarkitektur består av flera samverkande tekniska komponenter som tillsammans möjliggör effektiv parallell bearbetning och avancerad kontextförståelse. Inbäddningslagret omvandlar diskreta token (ord eller delord) till kontinuerliga vektorrepresentationer, ofta av dimension 512 eller högre. Dessa inbäddningar kompletteras med positionskodning, som lägger till information om varje tokens position i sekvensen med hjälp av sinus- och cosinusfunktioner på olika frekvenser. Denna positionsinformation är avgörande eftersom transformerarkitekturen, till skillnad från RNNs som bevarar ordning via rekurrens, behandlar alla token parallellt och behöver explicita positionssignaler för att förstå ordningsföljd och relativa avstånd.
Self-attention-mekanismen är den arkitektoniska innovation som särskiljer transformerarkitekturen från tidigare neuronnätsdesigner. För varje token i indatasekvensen beräknar modellen tre vektorer: en Query-vektor (vad token söker för information), Key-vektorer (vilken information varje token innehåller) och Value-vektorer (själva informationen som ska förmedlas). Attention-mekanismen beräknar en likhetspoäng mellan varje tokens Query och alla tokens Key genom skalärprodukt, normaliserar poängen med softmax för att skapa attention-vikter mellan 0 och 1, och använder dessa vikter för att skapa en viktad summa av Value-vektorerna. Denna process gör att varje token selektivt kan fokusera på andra relevanta token, vilket möjliggör kontextförståelse och relationsinlärning.
Multi-head attention utökar konceptet genom att köra flera parallella attention-mekanismer samtidigt, vanligtvis 8, 12 eller 16 huvuden. Varje huvud arbetar på olika linjära projektioner av Query, Key och Value-vektorer, vilket gör att modellen kan uppmärksamma olika typer av relationer och mönster i olika representationssubrymden. Exempelvis kan ett attentionhuvud fokusera på syntaktiska relationer mellan ord, medan ett annat fokuserar på semantiska relationer eller långväga beroenden. Utdata från alla huvuden sammanfogas och transformeras linjärt, vilket ger modellen rik och mångfacetterad kontextinformation. Studier visar att olika huvud spontant specialiserar sig på olika språkliga fenomen.
Kodar-avkodarstrukturen organiserar dessa attention-mekanismer i en hierarkisk bearbetningspipeline. Kodaren består av flera staplade lager (ofta 6 eller fler), där varje lager innehåller ett multi-head self-attention-dellager följt av ett positionellt feed-forward-nätverk. Residuala kopplingar runt varje dellager möjliggör att gradienter kan flöda direkt genom nätverket under träning, vilket förbättrar stabiliteten och möjliggör djupare arkitekturer. Lagernormalisering appliceras efter varje dellager för att normalisera aktiveringar och hålla dem på en jämn nivå genom nätverket. Avkodaren har en liknande struktur men inkluderar ett extra kodar-avkodar-attention-lager som gör att avkodaren kan uppmärksamma kodarens utdata, vilket är avgörande när output genereras. I avkodarbaserade arkitekturer som GPT genereras utdata token för token, där varje nytt token är villkorat av alla tidigare genererade token.
| Aspekt | Transformerarkitektur | RNN/LSTM | Konvolutionella neuronnät (CNN) |
|---|---|---|---|
| Bearbetningsmetod | Parallell bearbetning av hela sekvenser med attention | Sekventiell bearbetning, ett element i taget | Lokala konvolutioner på fasta fönster |
| Långväga beroenden | Utmärkt; attention kopplar direkt avlägsna token | Svag; begränsas av ‘vanishing gradients’ och sekventiell flaskhals | Begränsad; lokalt område kräver många lager |
| Träningshastighet | Mycket snabb; massiv parallellisering på GPU/TPU | Långsam; sekventiell bearbetning hindrar parallellisering | Snabb för fasta indata; mindre lämplig för variabla sekvenser |
| Minneskrav | Höga; kvadratiska i sekvenslängd pga attention | Låg; linjär i sekvenslängd | Måttliga; beror på filterstorlek och djup |
| Skalbarhet | Utmärkt; skalas till miljarder parametrar | Begränsad; svårt att träna mycket stora modeller | Bra för bilder; mindre lämpad för sekvenser |
| Typiska tillämpningar | Språkmodellering, maskinöversättning, textgenerering | Tidsserier, sekventiell prediktion (mindre vanligt nu) | Bildklassificering, objektigenkänning, datorseende |
| Gradientflöde | Stabilt; residuala kopplingar möjliggör djupa nät | Problematiskt; vanishing/exploding gradients | Oftast stabilt; lokala kopplingar underlättar gradientflöde |
| Positionsinformation | Explicit positionskodning krävs | Implicit via sekventiell bearbetning | Implicit via spatial struktur |
| State-of-the-art LLM:er | GPT, Claude, Llama, Granite, Perplexity | Sällan använda i moderna LLM:er | Ej använda för språkmodellering |
Relationen mellan transformerarkitektur och moderna stora språkmodeller är fundamental och oskiljaktig. Varje större LLM som släppts de senaste fem åren—including OpenAI:s GPT-4, Anthropics Claude, Metas Llama, Googles Gemini, IBMs Granite och Perplexitys AI-modeller—bygger på transformerarkitektur. Arkitekturens förmåga att effektivt skala med både modellstorlek och träningsdata har varit avgörande för att uppnå de kapaciteter som utmärker moderna AI-system. När forskare ökade modellstorleken från miljoner till miljarder och sedan hundratals miljarder parametrar möjliggjorde transformerarkitekturens parallellisering och attention-mekanismer denna skalning utan proportionerlig ökning av träningstid.
Autoregressiv avkodning som används av de flesta moderna LLM:er är en direkt tillämpning av transformeravkodararkitektur. Vid textgenerering bearbetar dessa modeller inmatningsprompten genom kodaren (eller i endast-avkodar-modeller genom hela avkodaren) och genererar sedan utdata token för token. Varje nytt token genereras genom att beräkna sannolikhetsfördelningar över hela vokabulären med softmax, där modellen väljer det mest sannolika token (eller sampelar från fördelningen baserat på temperaturinställningar). Denna process, som upprepas hundratals eller tusentals gånger, producerar sammanhängande och kontextuellt passande text. Self-attention-mekanismen gör att modellen kan behålla kontext över hela den genererade sekvensen, vilket möjliggör långa, koherenta texter med konsekventa teman, karaktärer och logik.
De emergenta förmågor som observerats i stora transformermodeller—egenskaper som bara uppträder vid tillräcklig skala, såsom fåskottsinlärning, kedjeslutledning och in-kontext-inlärning—är direkta konsekvenser av transformerarkitekturens design. Multi-head attention-mekanismens förmåga att fånga mångsidiga relationer, kombinerat med modellens stora parameterantal och träning på varierad data, gör att dessa system kan utföra uppgifter de aldrig explicit tränats för. Exempelvis kunde GPT-3 utföra aritmetik, skriva kod och svara på allmänbildningsfrågor trots att den endast tränades på språkmodellering. Dessa egenskaper har gjort transformerbaserade LLM:er till grunden för den moderna AI-revolutionen, med tillämpningar från konversations-AI och innehållsgenerering till kodsyntes och vetenskaplig forskningsassistans.
Self-attention-mekanismen är den innovation som i grunden skiljer transformerarkitekturen och förklarar dess överlägsna prestanda jämfört med tidigare metoder. För att förstå self-attention kan man överväga utmaningen att tolka tvetydiga pronomen i språk. I meningen “Pokalen får inte plats i resväskan eftersom den är för stor” kan “den” syfta på antingen pokalen eller resväskan, men kontexten gör det tydligt att det syftar på pokalen. I meningen “Pokalen får inte plats i resväskan eftersom den är för liten” syftar “den” nu på resväskan. En transformermodell måste lära sig att lösa sådana tvetydigheter genom att förstå relationer mellan ord.
Self-attention löser detta genom en elegant matematisk process. För varje token i sekvensen beräknar modellen en Query-vektor genom att multiplicera embeddingvektorn med en inlärd viktmatris WQ. På motsvarande sätt beräknas Key-vektorer (med WK) och Value-vektorer (med WV) för alla token. Attention-poängen mellan en tokens Query och en annan tokens Key beräknas som deras skalärprodukt, normaliserad med roten ur nyckeldimensionen (vanligtvis √64 ≈ 8). Dessa råpoäng skickas sedan genom en softmax-funktion, som omvandlar dem till normaliserade attention-vikter som summerar till 1. Slutligen beräknas utdata för varje token som en viktad summa av alla Value-vektorer där vikterna är attention-poängen. Processen gör att varje token selektivt kan samla information från alla andra token, med vikter som lärs in under träningen för att fånga meningsfulla relationer.
Den matematiska elegansen i self-attention möjliggör effektiv beräkning. Hela processen kan uttryckas som matrisoperationer: Attention(Q, K, V) = softmax(QK^T / √d_k)V, där Q, K och V är matriser med alla queries, keys och values. Denna matrisformulering möjliggör GPU-acceleration, så att transformerarkitekturen kan behandla hela sekvenser parallellt istället för sekventiellt. En sekvens på 512 token kan bearbetas på ungefär samma tid som en token i ett RNN, vilket gör transformerarkitekturen mångdubbelt snabbare att träna. Denna beräkningseffektivitet, kombinerad med attention-mekanismens förmåga att fånga långväga beroenden, förklarar varför transformerarkitekturen blivit den dominerande arkitekturen för språkmodellering.
Multi-head attention utökar self-attention-mekanismen genom att köra flera parallella attention-operationer, var och en lär sig olika aspekter av tokenrelationer. I en typisk transformer med 8 attention-huvuden projiceras inbäddningarna linjärt till 8 olika representationssubrymden med egna viktmatriser för Query, Key och Value. Varje huvud beräknar självständigt attention-vikter och producerar utdata. Dessa utdata sammanfogas och transformeras linjärt genom en sista viktmatris, vilket ger den slutliga multi-head attention-utgången. Arkitekturen möjliggör att modellen samtidigt kan uppmärksamma information från olika representationssubrymden på olika positioner.
Analyser av tränade transformermodeller har visat att olika attention-huvuden specialiserar sig på olika språkliga fenomen. Vissa huvuden fokuserar på syntaktiska relationer och lär sig att uppmärksamma grammatiskt relaterade ord (t.ex. verb som uppmärksammar sina subjekt och objekt). Andra huvuden fokuserar på semantiska relationer och lär sig att uppmärksamma ord med liknande betydelse. Ytterligare andra fångar långväga beroenden och uppmärksammar ord som är långt ifrån varandra i sekvensen men semantiskt relaterade. Vissa huvuden lär sig till och med att mestadels uppmärksamma den aktuella tokenen själv och fungerar därmed som identitetsoperationer. Denna specialisering uppstår spontant under träning utan explicit handledning, vilket visar multi-head-arkitekturens styrka att lära olika och kompletterande representationer.
Antalet attention-huvuden är en viktig arkitektonisk hyperparameter. Större modeller använder vanligtvis fler huvuden (16, 32 eller ännu fler), vilket gör att de kan fånga fler olika relationer. Dock hålls den totala dimensionsstorleken för attention-beräkningen oftast konstant, vilket innebär att fler huvuden ger lägre dimension per huvud. Detta designval balanserar fördelarna med flera representationssubrymden mot beräkningseffektiviteten. Multi-head-metoden har visat sig så effektiv att den blivit standard i praktiskt taget alla moderna transformerimplementationer, från BERT och GPT till specialiserade arkitekturer för bild, ljud och multimodal data.
Den ursprungliga transformerarkitekturen, som beskrivs i “Attention is All You Need”, använder en kodar-avkodar-struktur optimerad för sekvens-till-sekvens-uppgifter som maskinöversättning. Kodaren bearbetar indatasekvensen och producerar en sekvens av kontextuella representationer. Varje kodarlager innehåller två huvudkomponenter: ett multi-head self-attention-dellager som gör att token kan uppmärksamma andra token i indata, och ett positionsbundet feed-forward-nätverk som applicerar samma icke-linjära transformation på varje position oberoende. Dessa dellager sammankopplas via residuala kopplingar (även kallat skip connections), vilka adderar indatan till utdata från varje dellager. Denna design, inspirerad av residualnätverk inom datorseende, möjliggör träning av mycket djupa nätverk genom att tillåta gradienter att flöda direkt genom nätverket.
Avkodaren genererar utdatasekvensen en token i taget, med information från både kodaren och tidigare genererade token. Varje avkodarlager innehåller tre huvudkomponenter: ett maskerat self-attention-dellager som gör att varje token endast kan uppmärksamma tidigare token (för att förhindra att modellen “fuskar” genom att se framtida token under träningen), ett kodar-avkodar-attention-dellager som gör att avkodartoken kan uppmärksamma kodarens utdata samt ett positionsbundet feed-forward-nätverk. Maskningen i self-attention-dellagret är avgörande: den hindrar information från att flöda från framtida positioner till tidigare, vilket säkerställer att prediktioner för position i endast beror på kända utdata vid positioner < i. Denna autoregressiva struktur är avgörande för att generera sekvenser en token i taget.
Kodar-avkodararkitekturen har visat sig särskilt effektiv för uppgifter där indata och utdata har olika struktur eller längd, såsom maskinöversättning (översättning mellan språk), summering (kondensering av långa dokument) och frågesvar (generera svar baserat på kontext). Moderna LLM:er som GPT använder dock endast avkodararkitektur, där en enda stack av avkodarlager bearbetar både inmatningsprompt och genererar utdata. Denna förenkling minskar modellkomplexiteten och har visat sig vara lika eller mer effektiv för språkmodellering, troligen eftersom modellen kan lära sig att använda self-attention för att behandla indata och generera utdata i en och samma struktur.
En avgörande utmaning i transformerarkitekturen är att representera ordningen av token i en sekvens. Till skillnad från RNNs, som implicit bevarar sekvensordning genom rekurrens, behandlar transformerarkitekturen alla token parallellt och har ingen inbyggd förståelse för position. Utan explicit positionsinformation skulle en transformer behandla sekvensen “Katten satt på mattan” identiskt med “mattan på satt katten”, vilket vore katastrofalt för språkförståelse. Lösningen är positionskodning, som adderar positionsberoende vektorer till tokeninbäddningarna innan bearbetning.
Originalartikeln använder sinusformade positionskodningar, där positionsvektorn för position pos och dimension i beräknas som:
Dessa sinusfunktioner skapar ett unikt mönster för varje position, med olika frekvenser för olika dimensioner. Lägre frekvenser (lägre i) varierar långsamt med position och fångar långväga positionsinformation, medan högre frekvenser varierar snabbt och fångar detaljerad positionsinformation. Designen har flera fördelar: den generaliserar naturligt till sekvenser längre än de som modellen såg vid träning, ger mjuka övergångar mellan positioner och gör det möjligt för modellen att lära sig relativa positionsrelationer. Positionskodningsvektorerna adderas helt enkelt till tokeninbäddningarna före första attentionlagret, och modellen lär sig hur denna positionsinformation ska användas under träning.
Alternativa positionskodningsmetoder har föreslagits och studerats, bland annat relativa positionsrepresentationer (som kodar avstånd mellan token istället för absoluta positioner) och roterande positionsinbäddningar (RoPE) (som roterar inbäddningsvektorer baserat på position). Dessa alternativ har visat förbättringar i vissa scenarier, särskilt för mycket långa sekvenser eller vid finjustering på sekvenser längre än de som användes vid träning. Valet av positionskodning kan ha stor inverkan på modellens prestanda och är fortsatt ett aktivt forskningsområde inom transformeroptimering.
Att förstå Transformerarkitektur är avgörande för att förstå hur moderna AI-system genererar svar på plattformar som ChatGPT, Claude, Perplexity och Google AI Overviews. Dessa system, alla byggda på transformer-teknologi, bearbetar användarfrågor genom flera lager av self-attention, vilket gör att de kan förstå kontext och generera sammanhängande, relevanta svar. När en användare ställer en fråga om ett varumärke, produkt eller domän avgör modellens attention-mekanismer vilka delar av träningsdatan som är mest relevanta, och avkodaren genererar ett svar som kan nämna eller referera till varumärket.
För organisationer som använder AI-övervakningsplattformar som AmICited ger förståelse för transformerarkitektur viktig kontext för att tolka hur och varför varumärken syns i AI-genererat innehåll. Self-attention-mekanismens förmåga att fånga relationer mellan begrepp innebär att varumärken som nämns i träningsdata kan associeras med specifika ämnen, branscher eller användningsområden. När en användare frågar ett AI-system om dessa ämnen kan attention-mekanismen aktivera kopplingar till varumärket och därmed resultera i nämningar i det genererade svaret. Multi-head-strukturen innebär att olika aspekter av ditt varumärkes närvaro i träningsdata kan fångas av olika attention-huvuden, vilket påverkar hur heltäckande modellen förstår och representerar ditt varumärke.
Transformerarkitekturens beroende av träningsdata förklarar också varför varumärkets synlighet i AI-utdata beror mycket på kvaliteten och mängden av din närvaro online. Modeller som tränats på internettexter får rika representationer av varumärken med omfattande, högkvalitativt webbmaterial, frekventa nämningar i trovärdiga källor
Transformerarkitektur behandlar hela sekvenser parallellt med hjälp av self-attention, medan RNNs och LSTMs behandlar sekvenser sekventiellt, ett element i taget. Denna parallellisering gör transformermodeller avsevärt snabbare att träna och bättre på att fånga långväga beroenden mellan avlägsna ord eller token. Transformermodeller undviker också det så kallade 'vanishing gradient'-problemet som drabbade RNNs, vilket gör att de effektivt kan lära sig från mycket längre sekvenser.
Self-attention beräknar tre vektorer (Query, Key och Value) för varje token i indatasekvensen. Query-vektorn från en token jämförs med Key-vektorerna för alla token för att avgöra relevanspoäng, vilka normaliseras med hjälp av softmax. Dessa attention-vikter appliceras sedan på Value-vektorerna för att skapa kontextmedvetna representationer. Denna mekanism gör att varje token kan 'uppmärksamma' eller fokusera på andra relevanta token i sekvensen, vilket gör att modellen kan förstå kontext och relationer.
Huvudkomponenterna inkluderar: (1) Inbäddningar och positionskodning för att representera token och deras positioner, (2) Multi-head self-attention-lager som beräknar attention över flera representationssubrymden, (3) Feed-forward-neuronnät som appliceras på varje position oberoende, (4) En kodarstack som bearbetar indatasekvenser, (5) En avkodarstack som genererar utdata, samt (6) Residuala kopplingar och lagernormalisering för stabil träning. Dessa komponenter samverkar för att möjliggöra effektiv parallell bearbetning och kontextförståelse.
Transformerarkitekturen är överlägsen för LLM:er eftersom den möjliggör parallell bearbetning av hela sekvenser, vilket dramatiskt minskar träningstiden jämfört med sekventiella RNNs. Den fångar långväga beroenden effektivare via self-attention, vilket gör att modeller kan förstå kontext över hela dokument. Arkitekturen skalas också effektivt med större datamängder och fler parametrar, vilket har varit avgörande för att träna modeller med miljarder parametrar som uppvisar emergenta förmågor.
Multi-head attention kör flera parallella attention-mekanismer (vanligtvis 8 eller 16 huvuden) samtidigt, där var och en verkar på olika representationssubrymden. Varje huvud lär sig att fokusera på olika typer av relationer och mönster i datan. Utdata från alla huvuden sammanfogas och transformeras linjärt, vilket gör att modellen kan fånga mångsidig kontextinformation. Detta förbättrar modellens förmåga att förstå komplexa relationer och förbättrar den övergripande prestandan.
Positionskodning lägger till information om tokenpositioner till inbäddningarna genom att använda sinus- och cosinusfunktioner med olika frekvenser. Eftersom transformermodeller behandlar alla token parallellt (till skillnad från sekventiella RNNs) behöver de explicit positionsinformation för att förstå ordningsföljd. Positionskodningsvektorerna adderas till tokeninbäddningarna innan bearbetning, vilket gör att modellen kan lära sig hur position påverkar betydelsen och möjliggör generalisering till längre sekvenser än de som användes vid träning.
Kodaren bearbetar indatasekvensen och skapar rika kontextuella representationer via flera lager av self-attention och feed-forward-nätverk. Avkodaren genererar utdatasekvensen en token i taget, med kodar-avkodar-attention för att fokusera på relevanta delar av indata. Denna struktur är särskilt användbar för sekvens-till-sekvens-uppgifter som maskinöversättning, men moderna LLM:er använder ofta endast avkodararkitektur för textgenerering.
Transformerarkitekturen driver de AI-system som genererar svar i plattformar som ChatGPT, Claude, Perplexity och Google AI Overviews. Att förstå hur transformermodeller bearbetar och genererar text är avgörande för AI-övervakningsplattformar som AmICited, som spårar var varumärken och domäner förekommer i AI-genererade svar. Modellens förmåga att förstå kontext och generera sammanhängande text påverkar direkt hur varumärken nämns och representeras i AI-utdata.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Webbplatsarkitektur är den hierarkiska organisationen av webbplatsens sidor och innehåll. Lär dig hur en korrekt webbplatsstruktur förbättrar SEO, användarupple...
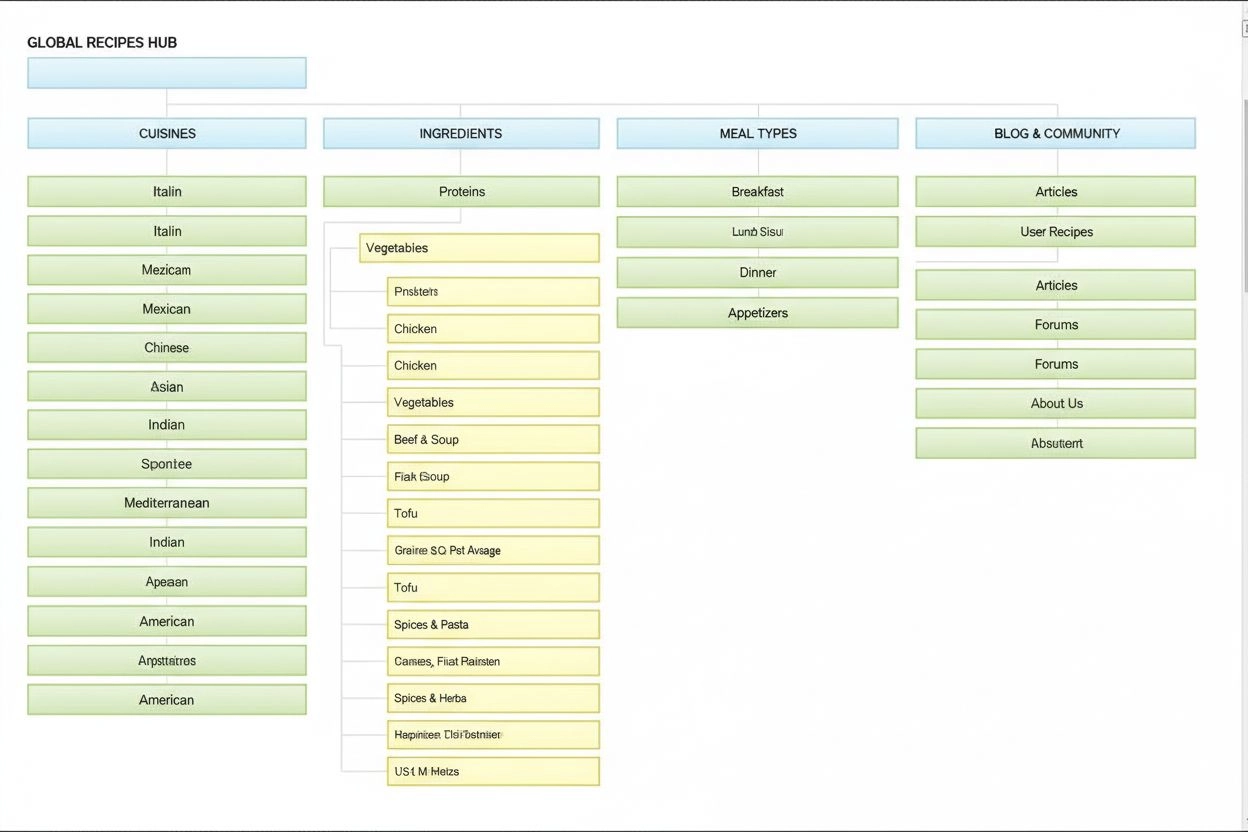
Informationsarkitektur är praktiken att organisera och strukturera innehåll för optimal användbarhet. Lär dig hur IA förbättrar sökbarhet, användarupplevelse oc...

GPT-4 är OpenAI:s avancerade multimodala LLM som kombinerar text- och bildbehandling. Lär dig om dess förmågor, arkitektur och påverkan på AI-övervakning och sp...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.