AI-innehållspoäng
Lär dig vad en AI-innehållspoäng är, hur den utvärderar innehållets kvalitet för AI-system och varför det är viktigt för synlighet i ChatGPT, Perplexity och and...
10 min läsning
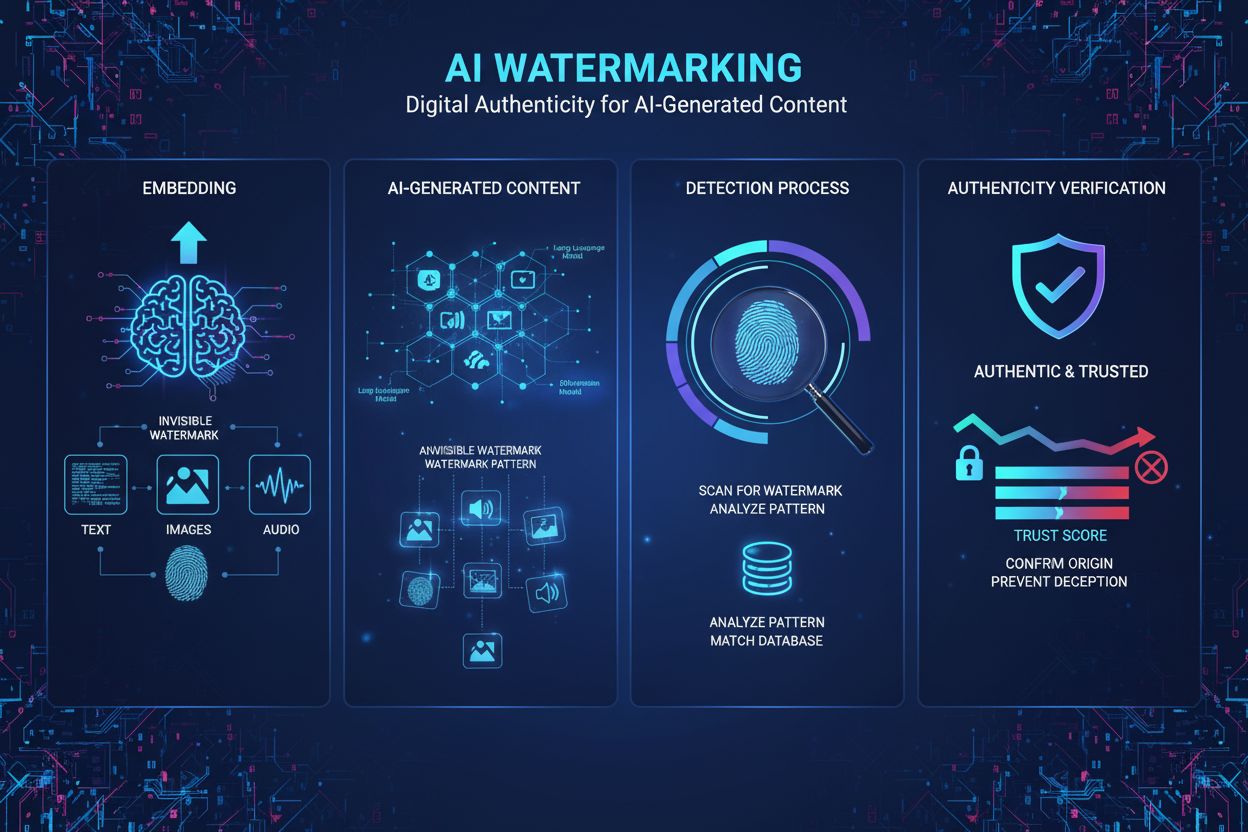
Vattenmärkning av AI-innehåll är processen att bädda in osynliga eller synliga digitala markörer i AI-genererad text, bild, ljud eller video för att identifiera och autentisera innehållet som maskinskapad. Dessa vattenmärken fungerar som digitala fingeravtryck som möjliggör detektering, verifiering och spårning av AI-genererat material över plattformar och applikationer.
Vattenmärkning av AI-innehåll är processen att bädda in osynliga eller synliga digitala markörer i AI-genererad text, bild, ljud eller video för att identifiera och autentisera innehållet som maskinskapad. Dessa vattenmärken fungerar som digitala fingeravtryck som möjliggör detektering, verifiering och spårning av AI-genererat material över plattformar och applikationer.
Vattenmärkning av AI-innehåll avser processen att bädda in digitala markörer, mönster eller signaturer i AI-genererat material för att identifiera, autentisera och spåra dess ursprung. Dessa vattenmärken fungerar som digitala fingeravtryck som särskiljer maskingenererat innehåll från människoskrivet arbete över text-, bild-, ljud- och videoformat. Det primära syftet med vattenmärkning av AI-innehåll är att säkerställa transparens kring innehållets proveniens samtidigt som det motverkar desinformation, skyddar immateriella rättigheter och skapar ansvarstagande i det snabbt växande området för generativ artificiell intelligens. Till skillnad från traditionella vattenmärken som är synliga på fysiska dokument eller bilder, använder moderna AI-vattenmärkningsmetoder ofta osynliga mönster som endast kan upptäckas med specialiserade algoritmer, vilket bevarar innehållskvaliteten och samtidigt bibehåller robust autentisering.
Konceptet vattenmärkning har sitt ursprung i den fysiska världen, där osynliga märken på sedlar och dokument fungerade som åtgärder mot förfalskning. I takt med att digitala medier blev vanligare anpassade forskare vattenmärkningsmetoder för bilder, ljud och video under 1990- och 2000-talen. Men framväxten av sofistikerade generativa AI-modeller som ChatGPT, DALL-E och Midjourney 2022–2023 skapade ett akut behov av standardiserade metoder för autentisering av AI-innehåll. Den snabba utvecklingen av AI:s förmåga att producera allt mer realistiskt syntetiskt innehåll fick regeringar, teknikföretag och civilsamhällesorganisationer att prioritera vattenmärkning som en avgörande skyddsåtgärd. Enligt forskning från Brookings Institution anser över 78 % av företag att AI-drivna verktyg för innehållsövervakning är viktiga för att hantera risker med syntetiska medier. EU:s AI Act, formellt antagen i mars 2024, blev det första större regelverket som kräver vattenmärkning av AI-innehåll, vilket ålägger leverantörer av AI-system att märka sitt utdata som AI-genererat. Denna regulatoriska utveckling har påskyndat forskning och utveckling av vattenmärkningstekniker, där företag som Google DeepMind, OpenAI och Meta investerar kraftigt i robusta vattenmärkningslösningar.
AI-vattenmärkning fungerar genom två huvudsakliga tekniska metoder: synlig vattenmärkning och osynlig vattenmärkning. Synliga vattenmärken inkluderar tydliga etiketter, logotyper eller textmarkörer som läggs till innehållet—till exempel de fem färgade rutorna som DALL-E placerar på genererade bilder eller ChatGPT:s ingress “as a language model trained by OpenAI”. Även om dessa är enkla att implementera är synliga vattenmärken mycket enkla att ta bort med grundläggande redigering. Osynlig vattenmärkning å andra sidan bäddar in subtila mönster som är omärkliga för människor men kan upptäckas av specialiserade algoritmer. För AI-genererade bilder används tekniker som tree-ring watermarking från University of Maryland, som bäddar in mönster i det initiala slumpmässiga bruset före diffusionsprocessen, vilket gör dem motståndskraftiga mot beskärning, rotation och filtrering. För AI-genererad text är statistisk vattenmärkning den mest lovande metoden, där språkmodellen subtilt föredrar vissa token (“gröna token”) och undviker andra (“röda token”) baserat på tidigare kontext. Detta skapar en statistiskt ovanlig ordningsföljd som detekteringsalgoritmer kan identifiera med hög säkerhet. Ljudvattenmärkning bäddar in omärkliga mönster i frekvensområden utanför det mänskliga hörspectrumet (under 20 Hz eller över 20 000 Hz), liknande bildvattenmärkning men anpassad för akustiska egenskaper. SynthID-tekniken från Google DeepMind är ett exempel på modern vattenmärkning genom att samtidigt träna genererings- och detekteringsmodeller, vilket säkerställer robusthet mot förändringar samtidigt som innehållskvaliteten bibehålls.
| Vattenmärkningsmetod | Innehållstyp | Robusthet | Kvalitetspåverkan | Kräver åtkomst till modell | Detekterbarhet |
|---|---|---|---|---|---|
| Synlig vattenmärkning | Bild, Video | Mycket låg | Ingen | Nej | Hög (Mänsklig) |
| Statistisk vattenmärkning | Text, Bild | Hög | Minimal | Ja | Hög (Algoritmisk) |
| Maskininlärningsbaserad | Bild, Ljud | Hög | Minimal | Ja | Hög (Algoritmisk) |
| Tree-Ring Vattenmärkning | Bild | Mycket hög | Ingen | Ja | Hög (Algoritmisk) |
| Innehållsproveniens (C2PA) | Alla medier | Medel | Ingen | Nej | Medel (Metadata) |
| Efterhandsdetektering | Alla medier | Låg | N/A | Nej | Låg (Osäker) |
Statistisk vattenmärkning är den mest genomförbara metoden för att autentisera AI-genererad text, då text saknar samma dimensionella utrymme som bilder eller ljud för att bädda in mönster. Under genereringsprocessen får en språkmodell instruktioner att föredra vissa token utifrån en kryptografisk nyckel som endast modellutvecklaren känner till. Modellens slumpmässighet “laddas” enligt detta schema, vilket gör att den föredrar vissa ord eller fraser och undviker andra. Detekteringsprotokoll analyserar den genererade texten för att beräkna sannolikheten att de observerade token-mönstren uppträder av en slump; statistiskt osannolika mönster indikerar närvaro av vattenmärke. Forskning från University of Maryland och OpenAI har visat att denna metod kan ge hög detekteringsnoggrannhet utan att kompromissa med textkvaliteten. Dock har statistisk vattenmärkning för text inneboende begränsningar: faktabaserade svar med liten genereringsfrihet (såsom matematiska lösningar eller historiska fakta) är svårare att vattenmärka effektivt, och omfattande omskrivning eller översättning till andra språk kan försämra detekteringssäkerheten avsevärt. SynthID Text-implementeringen, nu tillgänglig i Hugging Face Transformers v4.46.0+, erbjuder produktionsklar vattenmärkning med konfigurerbara parametrar inklusive kryptografiska nycklar och n-gramlängd för att balansera robusthet och detekterbarhet.
AI-genererade bilder drar nytta av mer avancerade vattenmärkningsmetoder tack vare det högdimensionella utrymmet för att bädda in mönster. Tree-ring watermarking bäddar in dolda mönster i den initiala slumpmässiga bilden före diffusionsprocessen, vilket skapar vattenmärken som överlever vanliga transformationer som beskärning, suddighet och rotation utan att försämra bildkvaliteten. Maskininlärningsbaserad vattenmärkning från Meta och Google använder neurala nätverk för att bädda in och upptäcka omärkliga vattenmärken, med över 96 % noggrannhet på oförändrade bilder samtidigt som de är motståndskraftiga mot attacker på pixelnivå. Ljudvattenmärkning använder liknande principer och bäddar in omärkliga mönster i frekvensområden utanför mänsklig perception. AudioSeal, utvecklad av Meta, tränar genererings- och detekteringsmodeller samtidigt för att skapa vattenmärken som är robusta mot naturliga ljudtransformationer men ändå bibehåller omöjlig att särskilja ljudkvalitet. Tekniken använder perceptuell förlust för att säkerställa att vattenmärkt ljud låter identiskt med originalet, samtidigt som den använder lokaliseringsförlust för att upptäcka vattenmärken oavsett störningar. Dessa metoder visar att osynlig vattenmärkning kan uppnå både robusthet och kvalitetsbevarande om de implementeras korrekt, men kräver åtkomst till den underliggande AI-modellen för att bädda in vattenmärket.
Det regulatoriska landskapet för vattenmärkning av AI-innehåll har utvecklats snabbt, med flera jurisdiktioner som genomfört eller föreslagit obligatoriska krav på vattenmärkning. EU:s AI Act, formellt antagen i mars 2024, representerar det mest omfattande regelverket och kräver att leverantörer av AI-system märker sitt utdata som AI-genererat innehåll. Denna reglering gäller alla generativa AI-system som används inom Europeiska unionen och innebär en juridisk skyldighet att följa vattenmärkningskraven. Californiens AI Transparency Act (SB 942), som träder i kraft 1 januari 2026, kräver att berörda AI-leverantörer tillhandahåller kostnadsfria, publikt tillgängliga verktyg för AI-innehållsdetektering, vilket i praktiken innebär krav på vattenmärkning eller motsvarande autentiseringsmetoder. U.S. National Defense Authorization Act (NDAA) för budgetåret 2024 innehåller bestämmelser om en pristävling för att utvärdera vattenmärkningsteknik och ålägger försvarsdepartementet att studera och pilotera implementering av “industriella öppna tekniska standarder” för att bädda in proveniensinformation i metadata. Vita husets exekutiva order om AI ålägger handelsdepartementet att identifiera och utveckla standarder för märkning av AI-genererat innehåll. Dessa regulatoriska initiativ speglar en växande konsensus kring att AI-vattenmärkning är avgörande för transparens, ansvarstagande och konsumentskydd. Dock kvarstår betydande implementeringsutmaningar, särskilt vad gäller open source-modeller, internationell samordning och den tekniska genomförbarheten av universella vattenmärkningsstandarder.
Trots betydande tekniska framsteg står AI-vattenmärkning inför stora begränsningar som påverkar dess praktiska effektivitet. Borttagning av vattenmärken är möjlig genom olika kringgående tekniker: parafrasering av text, beskärning eller filtrering av bilder, översättning till andra språk eller tillämpning av adversariala störningar. Forskning från Duke University har visat proof-of-concept-attacker mot detektorer för maskininlärningsbaserade vattenmärken, vilket indikerar att även avancerade metoder är sårbara för målmedvetna angripare. Icke-universalitetsproblemet är en annan kritisk begränsning—vattenmärkesdetektorer är modellunika, vilket innebär att användare måste kontrollera varje AI-företags detekteringstjänst separat för att verifiera innehållets ursprung. Utan ett centralt register och standardiserade detekteringsprotokoll blir kontrollen av AI-genererat innehåll en ineffektiv, ad hoc-process. Falska positiva vid vattenmärkesdetektion, särskilt för text, är fortfarande problematiska; detekteringsalgoritmer kan felaktigt flagga människoskrivet innehåll som AI-genererat eller misslyckas att upptäcka vattenmärkt innehåll efter mindre modifieringar. Kompatibilitet med open source-modeller utgör styrningsutmaningar, eftersom vattenmärken kan tas bort genom att radera kod i nedladdade modeller. Kvalitetsförsämring uppstår när vattenmärkningsalgoritmer konstlat begränsar modellens utdata för att bädda in detekterbara mönster, vilket kan minska innehållskvaliteten eller begränsa genereringsfriheten för faktabaserade eller strikt output-krävande uppgifter. Integritetsimplikationerna av vattenmärkning—särskilt om vattenmärken innehåller användaridentifierande information—kräver noggrant policyarbete. Dessutom minskar detekteringssäkerheten avsevärt med innehållets längd; kortare texter och kraftigt modifierat innehåll ger lägre detekteringssäkerhet, vilket begränsar vattenmärkningens nytta i vissa tillämpningar.
Framtiden för AI-vattenmärkning är beroende av fortsatt teknisk innovation, regulatorisk harmonisering och etablering av betrodd infrastruktur för detektion och verifiering av vattenmärken. Forskare utforskar offentligt detekterbara vattenmärken som bibehåller robusthet trots öppenhet kring detekteringsmetoder, vilket kan möjliggöra decentraliserad verifiering utan att man måste lita på tredjepartstjänster. Standardiseringsinitiativ genom organisationer som ICANN eller branschkonsortier kan etablera universella vattenmärkningsprotokoll, minska fragmentering och möjliggöra effektiv detektion över plattformar. Integration med innehållsproveniensstandarder såsom C2PA kan skapa lager av autentisering genom att kombinera vattenmärken med metadata-baserad proveniensspårning. Utvecklingen av vattenmärken som är robusta mot översättning och parafrasering är ett aktivt forskningsområde med potentiella tillämpningar för flerspråkig innehållsautentisering. Blockkedjebaserade verifieringssystem kan erbjuda oföränderliga register för vattenmärkesdetektion och innehållsproveniens, vilket stärker förtroendet för autentiseringsresultat. I takt med att generativa AI-funktioner utvecklas måste vattenmärkningsmetoderna utvecklas för att förbli effektiva mot allt mer sofistikerade kringgående försök. Den regulatoriska drivkraften från EU:s AI Act och Calforniens lagstiftning kommer sannolikt att driva på globalt införande av vattenmärkningsstandarder och skapa marknadsincitament för robusta tekniska lösningar. Realistiskt bör man dock räkna med att vattenmärkning främst kommer att hantera AI-genererat innehåll från populära kommersiella modeller och vara begränsad i högriskscenarier som kräver omedelbar detektion. Integrationen av plattformar för AI-innehållsövervakning såsom AmICited med vattenmärkningsinfrastruktur kommer att göra det möjligt för organisationer att spåra varumärkesattribuering över AI-system och säkerställa korrekt erkännande när deras domäner förekommer i AI-genererade svar. Framtida utveckling kommer sannolikt betona samarbete mellan människa och AI vid innehållsautentisering, där automatiserad vattenmärkesdetektion kombineras med mänsklig verifiering för kritiska tillämpningar inom journalistik, rättsprocesser och akademisk integritet.
Synliga vattenmärken är lätt upptäckbara av människor, såsom logotyper eller textetiketter som lagts till bilder eller ljudklipp, men de är enkla att ta bort eller förfalska. Osynliga vattenmärken bäddar in subtila mönster som är omärkliga för mänsklig perception men upptäckbara av specialiserade algoritmer, vilket gör dem betydligt mer robusta mot manipulation och borttagningsförsök. Osynliga vattenmärken föredras generellt för AI-innehållsautentisering eftersom de bibehåller innehållskvaliteten samtidigt som de ger starkare säkerhet mot undanmanövrer.
Statistisk vattenmärkning för text fungerar genom att subtilt påverka språkmodellens val av token under genereringen. Modellutvecklaren 'laddar tärningen' med hjälp av ett kryptografiskt schema, vilket får modellen att föredra vissa 'gröna token' och undvika 'röda token' baserat på tidigare kontext. Detekteringsalgoritmer analyserar sedan texten för att identifiera om de föredragna token förekommer med statistiskt ovanlig frekvens, vilket indikerar närvaron av ett vattenmärke. Denna metod bevarar textkvaliteten samtidigt som den bäddar in ett upptäckbart fingeravtryck.
Viktiga utmaningar inkluderar enkelheten att ta bort vattenmärken genom mindre redigeringar eller transformationer, avsaknaden av universell detektering mellan olika AI-modeller samt svårigheten att vattenmärka text jämfört med bilder eller ljud. Dessutom kräver vattenmärkning samarbete från AI-modellutvecklare, är inte kompatibelt med open source-modellsläpp, och kan försämra innehållskvaliteten om det inte implementeras noggrant. Falska positiva och falska negativa vid detektering kvarstår också som betydande tekniska hinder.
EU:s AI Act, formellt antagen i mars 2024, kräver att leverantörer av AI-system märker sitt utdata som AI-genererat innehåll. Californiens AI Transparency Act (SB 942), som träder i kraft 1 januari 2026, kräver att berörda AI-leverantörer tillhandahåller kostnadsfria, offentligt tillgängliga verktyg för innehållsdetektering. Den amerikanska National Defense Authorization Act (NDAA) för budgetåret 2024 innehåller bestämmelser om utvärdering av vattenmärkningsteknik och utveckling av industristandarder för innehållsproveniens.
Vattenmärkning bäddar in identifierande mönster direkt i AI-genererat innehåll och skapar ett permanent digitalt fingeravtryck som kvarstår även om innehållet kopieras eller modifieras. Innehållsproveniens, såsom C2PA-standarden, lagrar metadata om innehållets ursprung och ändringshistorik separat i filmetadata. Vattenmärkning är mer robust mot kringgående men kräver samarbete från modellutvecklare, medan proveniens är enklare att implementera men kan tas bort genom att kopiera innehåll utan metadata.
SynthID är Google DeepMinds teknik som vattenmärker och identifierar AI-genererat innehåll genom att bädda in digitala vattenmärken direkt i bilder, ljud, text och video. För text använder SynthID en logits-processor som förstärker modellens genereringspipeline för att koda vattenmärkesinformation utan att nämnvärt påverka kvaliteten. Tekniken använder maskininlärningsmodeller för att både bädda in och detektera vattenmärken, vilket gör den motståndskraftig mot vanliga attacker samtidigt som innehållets integritet bibehålls.
Ja, motiverade aktörer kan ta bort eller kringgå vattenmärken genom olika tekniker såsom att parafrasera text, beskära eller filtrera bilder eller översätta innehåll till olika språk. Att ta bort sofistikerade vattenmärken kräver dock teknisk expertis och kunskap om vattenmärkningsschemat. Statistiska vattenmärken är mer robusta än traditionella metoder, men forskning har visat proof-of-concept-attacker även mot avancerade vattenmärkningsmetoder, vilket indikerar att ingen vattenmärkningsmetod är helt idiotsäker.
Börja spåra hur AI-chatbotar nämner ditt varumärke på ChatGPT, Perplexity och andra plattformar. Få handlingsbara insikter för att förbättra din AI-närvaro.
Lär dig vad en AI-innehållspoäng är, hur den utvärderar innehållets kvalitet för AI-system och varför det är viktigt för synlighet i ChatGPT, Perplexity och and...

Lär dig om AI-innehållslicensieringsavtal som styr hur artificiella intelligenssystem använder upphovsrättsligt skyddat innehåll. Utforska licensieringstyper, n...

Lär dig vad AI-innehållsdetektering är, hur detekteringsverktyg fungerar med maskininlärning och NLP, och varför de är viktiga för varumärkesövervakning, utbild...
Cookie-samtycke
Vi använder cookies för att förbättra din surfupplevelse och analysera vår trafik. See our privacy policy.