

如何允许AI机器人抓取你的网站:完整robots.txt与llms.txt指南
学习如何让GPTBot、PerplexityBot和ClaudeBot等AI机器人抓取你的网站。配置robots.txt,设置llms.txt,并为AI可见性优化。
2 分钟阅读
搜索和内容发现的格局正在发生巨大变化。 随着ChatGPT、Perplexity和Google AI Overviews等AI驱动的搜索工具呈指数级增长,您的内容对AI爬虫的可见性已变得和传统SEO同样关键。如果AI机器人无法访问您的内容,您的网站就会对数百万依赖这些平台获取答案的用户变得隐形。 风险比以往任何时候都更高:谷歌可能在网站出错后重新访问,但AI爬虫遵循的是不同的模式——错过首次关键爬取,可能意味着数月的可见性损失和错失被引用、流量以及品牌权威的机会。
AI爬虫的运行规则与多年来大家优化的Google和Bing机器人根本不同。最关键的区别:AI爬虫不渲染JavaScript,这意味着通过客户端脚本加载的动态内容对它们来说是不可见的——这与谷歌强大的渲染功能形成鲜明对比。此外,AI爬虫访问网站的频率极高,有时比传统搜索引擎高出100倍,这对服务器资源既是机遇也是挑战。与谷歌的索引模式不同,AI爬虫不会维护一个持续更新的索引;它们是在用户查询时按需抓取。这意味着没有再索引队列,没有Search Console重新抓取请求,也没有如果首轮抓取失败就能重新获得机会。理解这些差异对于优化内容策略至关重要。
| 特性 | AI爬虫 | 传统机器人 |
|---|---|---|
| JavaScript渲染 | 不支持(仅静态HTML) | 支持(完全渲染) |
| 抓取频率 | 极高(高出100倍以上) | 中等(每周/月) |
| 再索引能力 | 无(仅按需) | 有(持续更新) |
| 内容要求 | 纯HTML,schema标记 | 灵活(支持动态内容) |
| User-Agent阻止 | 针对特定机器人(GPTBot、ClaudeBot等) | 通用(Googlebot、Bingbot) |
| 缓存策略 | 短期快照 | 长期索引维护 |
您的内容可能因为一些您从未考虑过的原因而对AI爬虫不可见。以下是阻止AI机器人访问和理解您内容的主要障碍:
您的robots.txt文件是控制哪些AI机器人能访问您内容的主要机制,它通过针对特定爬虫的User-Agent规则工作。每个平台的AI使用不同的user-agent字符串——OpenAI的GPTBot、Anthropic的ClaudeBot、Perplexity的PerplexityBot——您可以分别允许或禁止每一个。这种精细化控制让您决定哪些AI系统可以用您的内容进行训练或引用,对于保护专有信息或处理竞争问题至关重要。然而,许多网站却因采用了为旧机器人设计的过于宽泛的规则而无意中阻止了AI爬虫,或者根本没有正确配置规则。
以下是为不同AI机器人配置robots.txt的示例:
# 允许OpenAI的GPTBot
User-agent: GPTBot
Allow: /
# 阻止Anthropic的ClaudeBot
User-agent: ClaudeBot
Disallow: /
# 允许Perplexity,但限制某些目录
User-agent: PerplexityBot
Allow: /
Disallow: /private/
Disallow: /admin/
# 其他所有机器人的默认规则
User-agent: *
Allow: /
与持续抓取并不断再索引的谷歌不同,AI爬虫只给一次机会——它们仅在用户查询其系统时访问,如果那一刻您的内容不可访问,就失去了机会。这一根本区别意味着您的网站必须从第一天起就技术合规;没有宽限期,没有修复问题后再获得可见性的第二次机会。糟糕的首次爬取体验——无论是JavaScript渲染失败、缺失schema标记还是服务器错误——都会导致您的内容数周甚至数月内无法被AI系统引用。没有人工再索引选项,控制台也没有“请求收录”按钮,这使得主动监控和优化变得不可或缺。第一次就做对的压力从未如此之大。
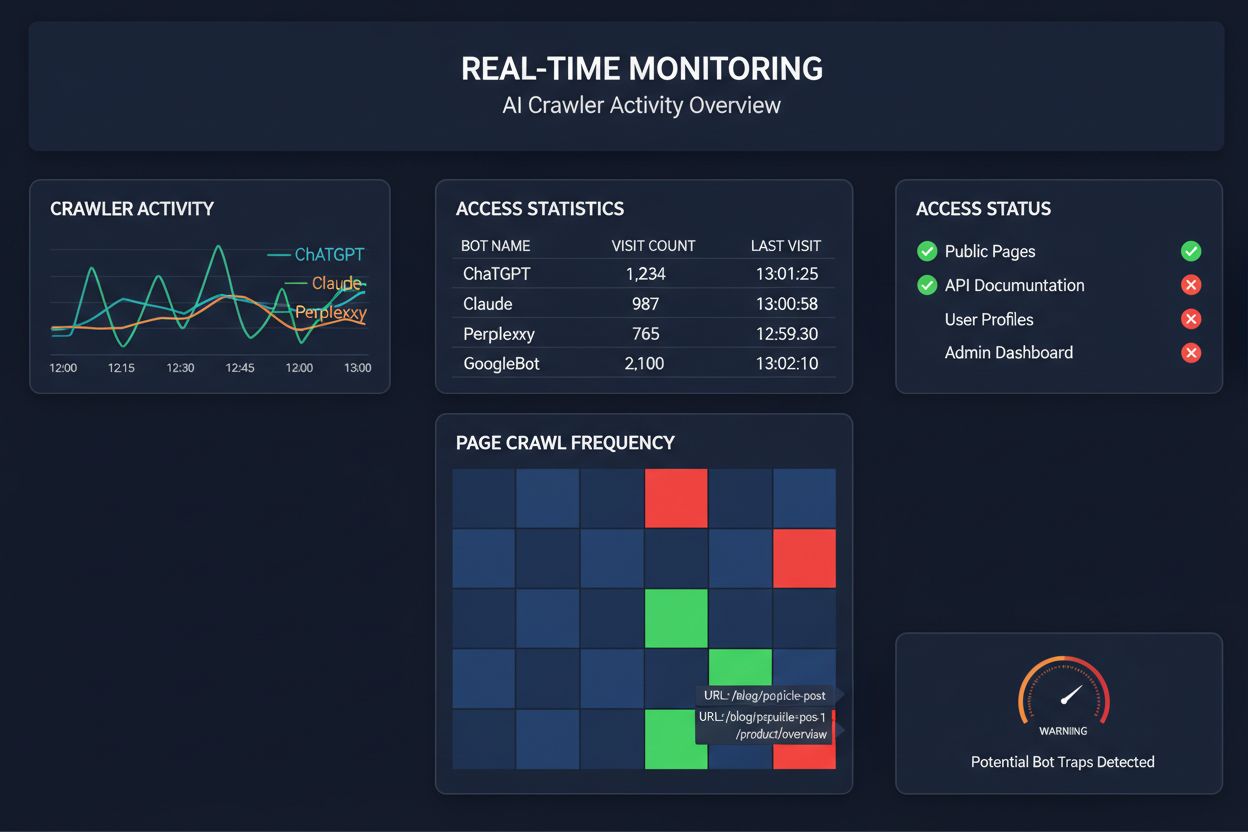
依赖定期抓取来监控AI爬虫访问,就像每月检查一次家里是否着火——您会错过问题发生的关键时刻。实时监控能在问题发生的瞬间发现异常,让您在内容对AI系统变得不可见之前采取措施。定期审计(通常每周或每月进行)会产生危险的盲区,您的网站可能在无人知晓的情况下连续数天无法通过AI爬虫抓取。实时解决方案能够持续跟踪爬虫行为,在JavaScript渲染失败、schema标记错误、防火墙阻挡或服务器异常时即刻提醒您。这种主动方式将您的审计从被动合规检查转变为主动的可见性管理策略。随着AI爬虫流量可能高出传统搜索引擎100倍,哪怕几小时的可访问性丧失也可能造成巨大损失。
目前已有多家平台提供专门用于监控和优化AI爬虫访问的工具。Cloudflare AI Crawl Control 提供基础设施级的AI机器人流量管理,允许您设置速率限制和访问策略。Conductor 提供全面的监控面板,追踪不同AI爬虫与您内容的互动。Elementive 专注于技术SEO审计,特别关注AI爬虫需求。AdAmigo 和 MRS Digital 为AI可见性提供专业咨询和监控服务。然而,若需要针对AI爬虫访问模式进行持续、实时监控并在影响可见性前发出预警,AmICited是专用解决方案中的佼佼者。AmICited专门监控哪些AI系统正在访问您的内容、爬取频率以及是否遇到技术障碍。这种专注于AI爬虫行为(而非传统SEO指标)的解决方案,使其成为重视AI可见性的组织的必备工具。
要进行全面的AI爬虫审计,需要系统化的流程。第1步:建立基线,检查当前robots.txt文件,明确目前允许或阻止了哪些AI机器人。第2步:审查技术架构,测试网站对非JavaScript爬虫的可访问性,检查服务器响应时间,并确认关键内容以静态HTML形式呈现。第3步:实施并验证schema标记,确保作者、发布时间、内容类型等元数据以JSON-LD格式结构化。第4步:监控爬虫行为,使用如AmICited等工具跟踪哪些AI机器人在访问网站、访问频率以及是否遇到错误。第5步:结果分析,审查抓取日志,识别失败模式并根据影响优先修复。第6步:实施修复,优先解决JavaScript渲染问题或缺失schema等高影响问题,再进行后续优化。第7步:建立持续监控,及时发现新问题,设置抓取失败或访问阻止的警报。
无需彻底重构网站,也能大幅提升AI爬虫访问。以纯HTML呈现关键信息,避免依赖JavaScript渲染;如必须用JavaScript,确保重要文本和元数据也在初始HTML中提供。用JSON-LD格式添加完善的schema标记,包括文章schema、作者信息、发布时间和内容关系——这有助于AI爬虫理解语境并正确归属内容。通过schema标记和署名确保作者信息清晰,因为AI系统越来越重视引用权威来源。监控并优化Core Web Vitals(最大内容绘制、首次输入延迟、累计布局偏移),因为加载缓慢的页面可能被爬虫中途放弃。检查并更新robots.txt,确保没有误阻想要被AI访问的机器人。修复技术问题,如重定向链、死链和服务器错误,这些都会导致爬虫中途放弃抓取。
并非所有AI爬虫都服务于同一目标,理解这些差异有助于您更科学地进行访问控制。GPTBot(OpenAI)主要用于训练数据收集和提升模型能力,如果您想让内容影响ChatGPT的回答,它就很重要。OAI-SearchBot(OpenAI)专门负责搜索引用,即它负责将您的内容纳入ChatGPT集成搜索的回答中。ClaudeBot(Anthropic)则为Anthropic的AI助手Claude服务。PerplexityBot(Perplexity)用于Perplexity的AI搜索引擎引用,现已成为许多出版商的重要流量来源。每个机器人在抓取模式、频率和用途上各不相同——有的关注训练数据,有的专注实时搜索引用。允许或阻止哪些机器人应与您的内容策略保持一致:若您希望被AI搜索结果引用,则应允许面向搜索的机器人;若担心训练数据使用,可以阻止数据收集机器人,只允许搜索机器人。这种细致的机器人管理方式远比传统的“全开”或“全关”策略更为科学。
AI爬虫审计是对您网站对AI机器人(如ChatGPT、Claude和Perplexity)可访问性的全面评估。它可以识别技术障碍、JavaScript渲染问题、缺失的schema标记以及其他阻止AI爬虫访问和理解您内容的因素。该审计将提供可执行的建议,以提升您在AI驱动的搜索和问答引擎中的可见性。
我们建议至少每季度进行一次全面审计,或在您对网站技术架构、内容结构或robots.txt文件做出重大更改时进行。不过,持续的实时监控是发现问题发生时立即修复的理想选择。许多组织使用自动化监控工具,实时提醒他们爬取失败,并辅以季度深度审计。
允许AI爬虫意味着您的内容可以被访问、分析并有可能被AI系统引用,这将提升您在AI生成答案和推荐中的可见性。阻止AI爬虫则会防止其访问您的内容,从而保护专有信息,但可能会降低您在AI搜索结果中的曝光。正确的选择取决于您的业务目标、内容敏感度和竞争定位。
当然可以。您的robots.txt文件可以通过User-Agent规则实现精细化控制。例如,您可以阻止GPTBot但允许PerplexityBot,或者允许面向搜索的机器人(如OAI-SearchBot),同时阻止数据收集机器人(如GPTBot)。这种细致的策略可以让您根据对业务最重要的AI平台优化内容策略。
如果AI爬虫无法访问您的内容,意味着您的网站对AI驱动的搜索引擎和问答平台来说实际上是不可见的。即使您的内容非常相关,也不会被引用、推荐或纳入AI生成的回答中。这将导致流量损失、品牌曝光度下降,并错失在AI搜索结果中树立权威的机会。
您可以通过检查服务器日志中已知AI爬虫(如GPTBot、ClaudeBot、PerplexityBot等)的User-Agent字段,或使用如AmICited这样的专业监控工具,实时追踪AI爬虫活动。这些工具能显示哪些机器人在访问您的网站、爬取频率、访问了哪些页面,以及是否遇到错误或被阻止。
这取决于您的具体情况。如果您的内容具有专有性、敏感性,或者您担心其被用作训练数据,则可以选择阻止。不过,如果您希望在AI搜索结果中获得曝光并被AI系统引用,则允许爬虫访问至关重要。许多组织采取中间路线:允许带来引用价值的面向搜索爬虫,同时阻止数据收集爬虫。
AI爬虫不会渲染JavaScript,这意味着通过客户端脚本动态加载的内容对它们来说是不可见的。如果您的网站依赖JavaScript来展示重要内容、导航或结构化数据,AI爬虫只能看到原始HTML,无法获取关键信息。这会显著影响AI系统如何理解和展现您的内容。在静态HTML中提供核心内容对AI可抓取性至关重要。
学习如何让GPTBot、PerplexityBot和ClaudeBot等AI机器人抓取你的网站。配置robots.txt,设置llms.txt,并为AI可见性优化。

了解如何通过服务器日志、工具和最佳实践,追踪并监控AI爬虫在你网站上的活动。识别GPTBot、ClaudeBot及其他AI机器人。
了解如何让 ChatGPT、Perplexity 以及谷歌 AI 等 AI 爬虫能够看到你的内容。发现针对 AI 搜索可见性的技术要求、最佳实践以及监控策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.