

LLMs.txt:它是什么,是否有效,以及你是否应该使用?
了解 LLMs.txt 是什么,它是否真的有效,以及你是否应该在你的网站上实施它。对这一新兴 AI SEO 标准的诚实分析。
2 分钟阅读
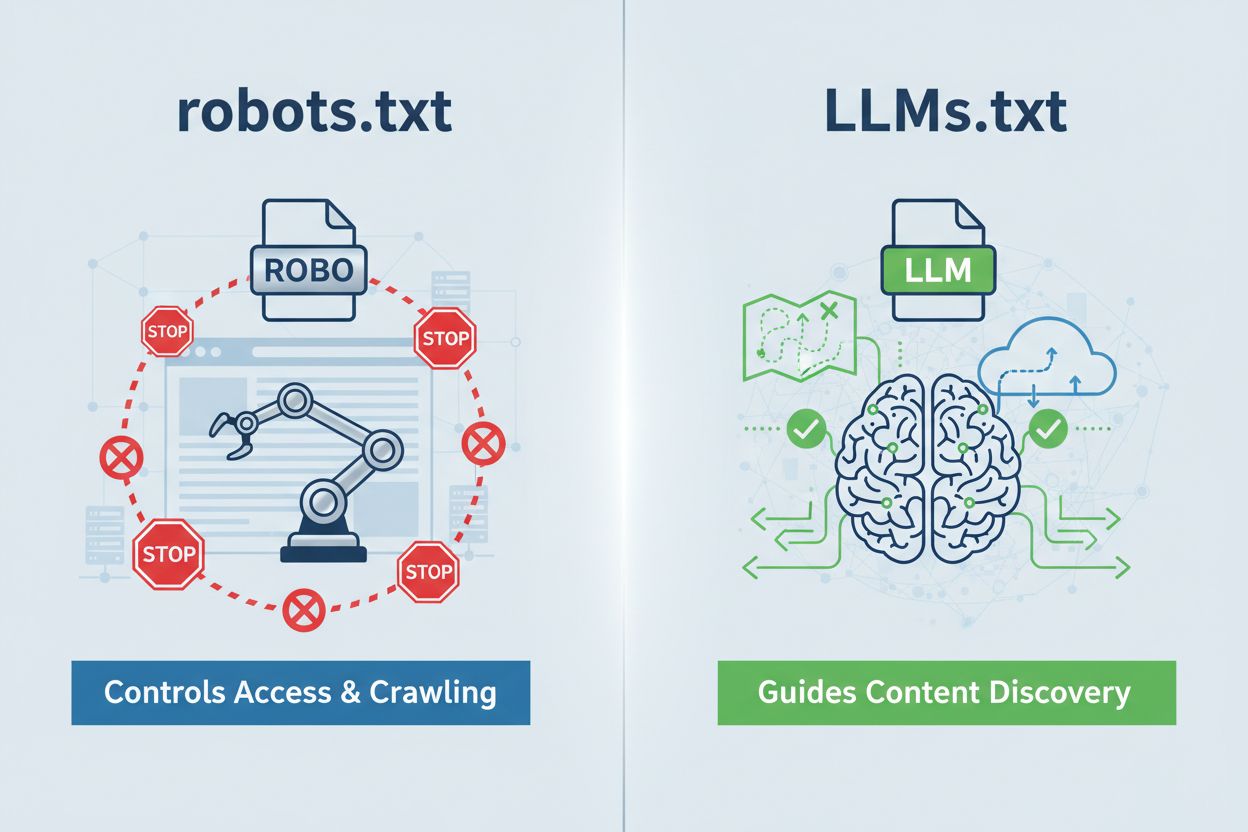
LLMs.txt 是一个放在 domain.com/llms.txt 下的纯文本文件,作为AI系统发现你最优质内容的策划指南。它与robots.txt有本质区别——robots.txt决定AI爬虫是否能访问你的网站,而LLMs.txt作用于推理时访问,帮助AI系统在生成回答时优先考虑哪些页面。与其说是交通警察,不如说是藏宝图:它不会阻止探索,只是突出真正有价值的地方。文件格式极为简单——纯markdown,无需复杂语法——任何类型的组织都能轻松创建,无需高技术门槛。这个区别很重要,因为它重塑了整个讨论方向:LLMs.txt不是控制爬取,而是优化AI可读内容的理解和优先级。
数据表明确有热度:截至2025年10月,已有84.4万+网站部署了LLMs.txt,主要集中在那些看重AI未来作用的公司。包括Anthropic、Cloudflare、Stripe、Vercel和Supabase等主力基础设施公司都已采用这一标准,证明严肃的基础设施企业愿意尝试。Mintlify于2024年11月为数千个文档站点自动生成LLMs.txt,带来采用高峰,显示工具支持可大幅推动实施。现有三个社区目录追踪这一标准的部署,已记录788+个经验证站点。但采用分布暴露出一个现象:部署主要集中在开发者工具和文档平台领域——这些领域最有可能从AI可见性中获益。下表是当前的采用格局:
| 公司/平台 | 已部署 | Token数量 | 状态 |
|---|---|---|---|
| Anthropic | 是 | ~2,000 | 活跃 |
| Cloudflare | 是 | ~5,000 | 活跃 |
| Stripe | 是 | ~8,000 | 活跃 |
| Vercel | 是 | ~3,500 | 活跃 |
| Supabase | 是 | ~4,200 | 活跃 |
| Mintlify(自动生成) | 是 | 不定 | 活跃 |
质疑的理由很充分:没有任何主流AI平台官方确认在检索系统中使用LLMs.txt。Google的John Mueller直言:“目前没有AI系统使用llms.txt”,本应终结讨论,但话题却仍在继续。OpenAI、Anthropic、Google、微软和Perplexity对此均保持战略性沉默——没有官方文档、没有使用确认、没有公开路线图。确有证据表明部分平台会抓取该文件(已观测到微软和OpenAI爬虫获取LLMs.txt),但爬取和实际用来生成内容完全是两回事。乐观派认为平台在低调测试后可能会官宣,悲观派则认为他们永远不会采用,因为这并不解决他们实际遇到的问题。这种沉默正是“过度炒作”论的核心:提案火热18个月,广泛部署,却没有任何官方平台支持。这不是标准,而是期待。
怀疑论基于一个简单事实:没有证据证明LLMs.txt能提升AI检索、带来更多流量或提高内容可见性。信任问题更深层——单独列出一个文件,内容可以和HTML里不同,等于给了操控的空间。LLM行为研究显示,被特别突出或针对性的内容,被推荐概率高2.5倍,这显然会激励“刷榜”。理论上,机构可以只把最优内容放进LLMs.txt,隐藏弱内容,甚至往里放根本不存在于站点的内容。SEO工具商又加剧了压力:Rank Math、SEMrush等把缺少LLMs.txt标为优化机会——大家不是因为有效才部署,而是因为工具告诉你“缺了点啥”。这才是真问题:18个月的部署压力下,没有一例可衡量价值被记录。这就像是在所有人都买彩票,只因彩票公司不断打广告。
支持LLMs.txt的人给出完全不同的理由,着眼于不可避免的变革,而非现成证据。Yoast的Carolyn Shelby说得好:“排名已不再是奖赏,被收录才是。” AI代码编辑器Windsurf报告说,LLMs.txt让解析文档时节省了大量时间和token,说明确有用武之地。Anthropic曾明确要求Mintlify为其文档实现LLMs.txt,虽未公开承认但侧面反映内部认可。Google把LLMs.txt纳入A2A(Agents to Agents)协议,显示其已被视为未来AI-2-AI通信基础设施的一部分。实施只需1-4小时,无负面影响——不会破坏任何东西,不损害SEO,只多了个文件。Jeremy Howard的观点直击要害:“99.9%的注意力将被LLM占据,而不是人类,” 这意味着为AI系统优化已不是可选项,而是必然。Springs Apps称部署后搜索可见性提升了20%,但未被验证,也可能只是相关性而非因果关系。
理解LLMs.txt为何可能失败,得先看其他标准为何成功。robots.txt成功是因为它带来互利、成本极低,并获得了官方RFC支持(RFC 9309)——搜索引擎想高效爬取,站点想控制访问,方案又够简单,推广无阻力。Schema.org通过Google、微软、雅虎、Yandex等多方共同开发——没人能单独主导,从而建立信任。Sitemap.xml是在平台广泛支持后才普及的,而非先部署后等支持。**LLMs.txt缺乏这三大成功要素:无W3C参与,无联盟背书,无官方平台支持,也没有流量提升、排名优化或准确率提升的可证价值。**标准的成功基础是多方参与、明确可衡量的回报和低被操控性。LLMs.txt有希望,有早期拥趸,有工具支持,但缺乏将实验变为基础设施的根本条件。
如果LLMs.txt还没被验证,那么真正能提升AI可见性和AI引用的是什么?答案比新文件格式简单得多:
这些做法之所以有效,是因为它们迎合了AI处理信息的本质逻辑,而不是绕着某个文件标准转。

关于LLMs.txt的讨论反映了内容成功方式的深层转变:人类体验与AI优化的融合。生成引擎优化(GEO)研究显示,能在AI生成答案中胜出的内容共同特征是:清晰、结构良好、具权威性、具体。Vercel报告说,其10%的注册量现在直接来自ChatGPT推荐,而不是传统搜索流量,这在五年前不可想象。内容的成功正逐渐转为出现在AI生成答案中,而不仅仅是自然排名靠前——这两者的优化目标和要求完全不同。工具生态也随之变化:SEMrush AIO、Profound GEO追踪、Ahrefs Brand Radar都开始同步监控AI可见性和传统排名。核心转变是:被引用比被排名更重要,被提及比被收录更有价值。这也解释了为何LLMs.txt在缺乏官方支持下依然流行——它代表了在AI主导流量分配的新注意力经济下的优化尝试。
如果你决定部署,就要做对。文件务必放在domain.com/llms.txt(注意复数),格式为纯文本markdown,不能用XML或JSON。以H1标题写站点名称,可选加一段引用,简述网站内容和AI为何应关注。若有多个板块,用H2分区(如Documentation、Blog、API Reference等),并简要说明每部分内容。单个页面采用[标题](URL): 描述格式,描述简明扼要但信息充分。应包含:常青内容、结构良好的页面、展现专业能力的资料。应避免:首页(单独引用价值低)、全站URL(质量应优先)、脱离上下文无法理解的页面。以下是基本结构示例:
# 公司名称
> 简要说明公司业务及AI为何关注你的内容
## Documentation
[快速入门](https://example.com/docs/getting-started): 新用户分步指南
[API参考](https://example.com/docs/api): 完整API文档及示例
[最佳实践](https://example.com/docs/best-practices): 我们平台的成熟用法
## Blog
[我们为何构建此产品](https://example.com/blog/why-we-built-this): 解决的问题及我们的方案
如需缩短上下文,可选添加跳过URL的部分,但大多数实现并不需要如此细致。
应该实现LLMs.txt。不是因为它已被证实有效,而是反正没坏处,潜在收益却很真实。即便AI平台永远不采纳,它也只是静静地呆在你的服务器上——没有SEO惩罚,没有流量损失,不会影响功能。小站点部署仅需10分钟,大站也不过一小时。与此同时,流量正在多AI系统间分流:ChatGPT、Perplexity、Claude及新晋对手每月处理数亿查询。你已经对AI系统可见——LLMs.txt只是在让它们优先找到你最好的内容。即使LLMs.txt永远成不了官方标准,你也在训练AI更好地理解你网站结构与重点,无论如何都有价值。真正的启示是:免费分散风险。部署标准、用已验证方法优化AI可见性,持续追踪来自AI的流量来源。12个月后,你就能拿到属于自己业务的真实数据——比一切猜测都更有价值。
LLMs.txt 是一个纯文本文件,引导AI系统在推理时访问您最优质的内容,而robots.txt 控制爬虫的访问和索引。LLMs.txt 不做任何限制——它策划并突出展示您最有价值的页面,帮助AI更好理解。可以把robots.txt当作交通警察,而LLMs.txt则像藏宝图。
官方并未确认。尽管已有84.4万+网站部署了它,但没有任何主流AI平台确认会用LLMs.txt生成响应。有证据显示OpenAI和微软的爬虫会抓取文件,但尚无用于推理或引用的确证。这正是“过度炒作”观点的核心。
值得。实施仅需10-30分钟,且没有任何负面影响。如果平台采用,你已抢占先机;如果不采用,文件也不会产生任何危害。对于AI可见性来说,这是低风险、潜在高回报的投资。本质上是押注AI主导内容发现的未来。
应包含常青、结构良好、能解答具体问题的内容:指南、FAQ、API文档、支柱性内容和权威资料。不要包含首页、站点所有URL,以及脱离上下文引用意义不大的页面。关键原则是质量优于数量。
可以,这确实是合理担忧。你可以在LLMs.txt中放与实际页面不同的内容,这会破坏信任。因此一些专家对该标准的长期可行性持怀疑态度,平台采纳也很谨慎。
llms.txt包含经过筛选的优质页面及其描述。llms-full.txt则是包含所有文档的完整版(有时多达40万字)。如果你希望AI系统一次获取全部内容而无需跟踪链接,可以用llms-full.txt。
LLMs.txt是更广泛GEO策略中的一个工具。GEO专注于通过清晰结构、引用、数据和权威专业让AI系统更易发现和引用你的内容。LLMs.txt可引导AI系统访问你最优的GEO优化内容。
需要。任何网站都能通过帮助AI系统理解和引用你的内容而受益。博客、本地商家、电商网站和小众社区都能从AI搜索中获得流量。LLMs.txt是提升你在ChatGPT、Claude、Perplexity等AI平台可见性的简单方法。
了解 LLMs.txt 是什么,它是否真的有效,以及你是否应该在你的网站上实施它。对这一新兴 AI SEO 标准的诚实分析。

了解如何在您网站上实施LLMs.txt,以帮助AI系统更好地理解您的内容。为所有平台(包括WordPress、Shopify和静态网站)提供完整的分步指南。...

了解 LLMs.txt 文件是什么、它与 robots.txt 有何不同,以及为什么它对 ChatGPT、Perplexity 和 Google AI Overviews 中 AI 的可见性与引用至关重要。完整实施指南。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.