
NoAI 元标签
了解 NoAI 元标签是什么、它如何防止 AI 抓取、实现方法,以及其在保护您的内容免受未经授权的 AI 训练方面的有效性。
2 分钟阅读

了解如何实现 noai 和 noimageai 元标签,以控制 AI 爬虫对您网站内容的访问。AI 访问控制头信息及实现方法的完整指南。
网页爬虫是自动化程序,系统地浏览互联网,从网站收集信息。过去,这些机器人主要由 Google 等搜索引擎运营,其 Googlebot 会爬取页面、索引内容,并通过搜索结果为网站带来流量,实现互利。然而,AI 爬虫的出现彻底改变了这一格局。与传统搜索引擎机器人用内容换取推荐流量不同,AI 训练爬虫会大量获取网页内容,用于构建大型语言模型的数据集,却往往很少甚至完全不为发布者带来流量。这种转变使得元标签——这些向爬虫传达指令的小型 HTML 指令——对于希望掌控自己作品如何被人工智能系统使用的内容创作者来说日益重要。
noai 和 noimageai 元标签由 DeviantArt 于 2022 年发起,旨在帮助内容创作者防止其作品被用于 AI 图像生成器的训练。这些标签的作用方式类似于早已存在的 noindex 指令,后者用于告知搜索引擎不要索引页面。noai 指令表示页面所有内容都不应被用于 AI 训练,而 noimageai 则专门防止图片被用于 AI 模型训练。您可以如下方式在 HTML 的 head 区域实现这些标签:
<!-- 阻止所有内容被 AI 训练 -->
<meta name="robots" content="noai">
<!-- 仅阻止图片被 AI 训练 -->
<meta name="robots" content="noimageai">
<!-- 同时阻止内容和图片 -->
<meta name="robots" content="noai, noimageai">
以下是不同元标签指令及其用途的对比表:
| 指令 | 作用 | 语法 | 作用范围 |
|---|---|---|---|
| noai | 阻止所有内容用于 AI 训练 | content="noai" | 整个页面内容 |
| noimageai | 阻止图片用于 AI 训练 | content="noimageai" | 仅限图片 |
| noindex | 阻止搜索引擎收录页面 | content="noindex" | 搜索结果 |
| nofollow | 阻止链接被跟踪 | content="nofollow" | 外部链接 |
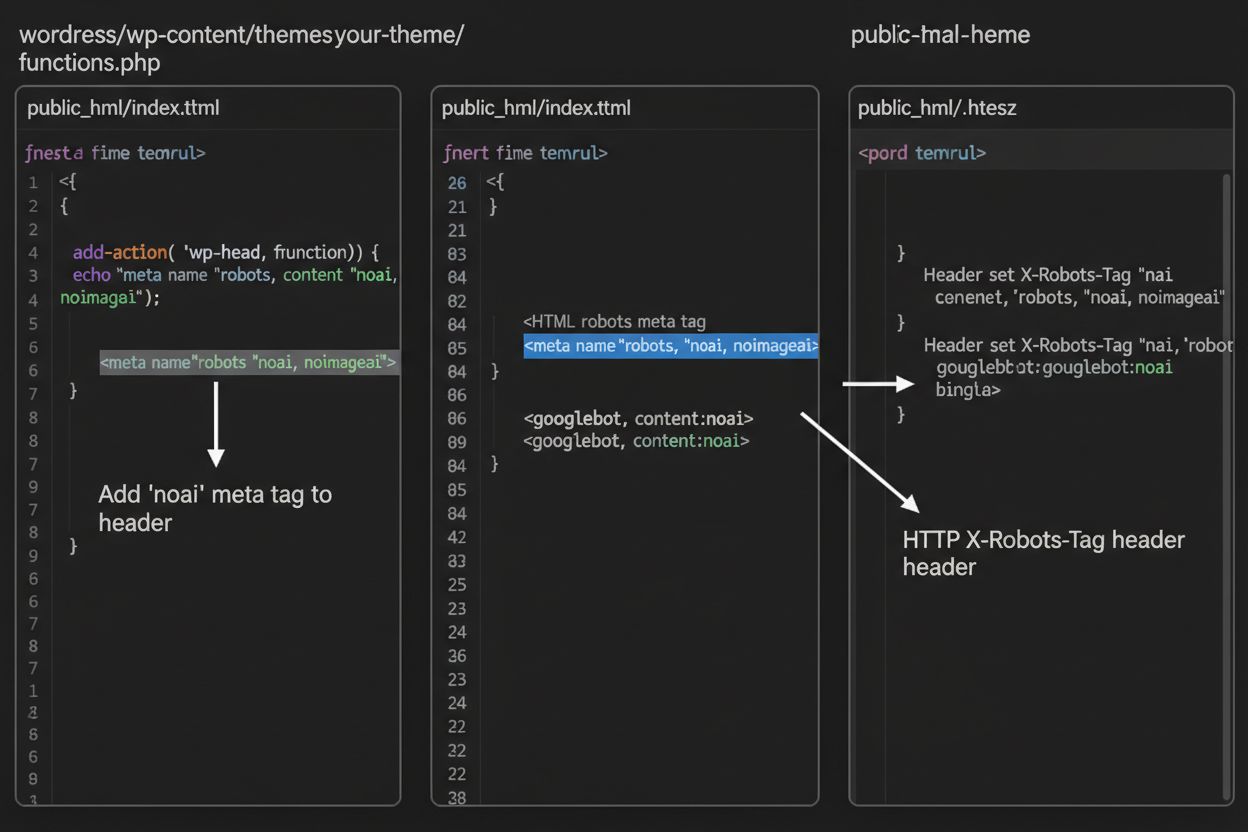
元标签直接嵌入您的 HTML 文件中,而 HTTP 头信息 提供了另一种在服务器层面传达爬虫指令的方法。X-Robots-Tag 头信息可包含与元标签相同的指令,但其工作方式不同——它在页面内容传输之前由 HTTP 响应发送。这种方式尤其适合于控制无法嵌入 HTML 元标签的非 HTML 文件(如 PDF、图片、视频等)的访问权限。
对于 Apache 服务器,您可以在 .htaccess 文件中设置 X-Robots-Tag 头信息:
<IfModule mod_headers.c>
Header set X-Robots-Tag "noai, noimageai"
</IfModule>
对于 NGINX 服务器,在服务器配置中添加:
location / {
add_header X-Robots-Tag "noai, noimageai";
}
头信息可为整个网站或特定目录提供全局防护,非常适合于全面的 AI 访问控制策略。
noai 和 noimageai 标签的有效性完全取决于爬虫是否选择遵守。行为规范的爬虫(主要 AI 公司)通常会遵循这些指令:
然而,行为不规范的机器人和恶意爬虫可能会故意忽略这些指令,因为目前没有强制机制。与搜索引擎已达成行业共识、必须遵守的 robots.txt 不同,noai 不是官方网络标准,爬虫没有义务遵守。因此,安全专家建议采用分层防护,结合多种保护方式,而不要仅依赖元标签。
noai 和 noimageai 标签的实现根据您的网站平台而异。以下是常见平台的实现步骤:
1. WordPress(通过 functions.php) 将如下代码添加到子主题的 functions.php 文件中:
function add_noai_meta_tag() {
echo '<meta name="robots" content="noai, noimageai">' . "\n";
}
add_action('wp_head', 'add_noai_meta_tag');
2. 静态 HTML 站点
直接添加至 HTML 的 <head> 区域:
<head>
<meta name="robots" content="noai, noimageai">
</head>
3. Squarespace 进入“设置 > 高级 > 代码注入”,添加到 Header 区域:
<meta name="robots" content="noai, noimageai">
4. Wix 进入“设置 > 自定义代码”,点击“添加自定义代码”,粘贴元标签,选择“Head”,并应用到所有页面。
不同平台控制程度不一——WordPress 可通过插件实现页面级定制,而 Squarespace 和 Wix 提供全站统一选项。根据您的技术熟练度和具体需求选择最适合的方法。
虽然 noai 和 noimageai 标签是内容创作者保护的重要一步,但也存在显著局限性。首先,它们并非官方网络标准——由 DeviantArt 社区自发提出,没有正式规范或强制机制。其次,遵守完全出于自愿。大公司爬虫会遵守,但行为不规范的机器人和爬虫可以毫无后果地忽略它们。第三,缺乏标准化导致采用率各异。部分小型 AI 公司或研究机构甚至可能不知道这些指令,更谈不上支持。最后,仅靠元标签无法阻止有意的恶意行为者。恶意爬虫可完全忽略您的指令,因此想要全面保护内容,必须增加额外防护层。
最有效的 AI 访问控制策略是多层防护,而不是只依赖单一方法。以下是不同防护方式的对比:
| 方法 | 作用范围 | 有效性(依赖程度) | 难度 |
|---|---|---|---|
| 元标签(noai) | 页面级 | 中(自愿遵守) | 易 |
| robots.txt | 全站级 | 中(建议性) | 易 |
| X-Robots-Tag 头信息 | 服务器级 | 中高(覆盖所有文件类型) | 中 |
| 防火墙规则 | 网络级 | 高(基础设施层面阻断) | 难 |
| IP 白名单 | 网络级 | 很高(仅允许验证来源) | 难 |
一套全面的策略可以包括:(1)所有页面都启用 noai 元标签,(2)在 robots.txt 中加入屏蔽已知 AI 训练爬虫的规则,(3)为非 HTML 文件设置服务器级 X-Robots-Tag 头信息,(4)监控服务器日志,及时识别无视指令的爬虫。这种分层做法大大提高了不良行为者的攻击难度,同时兼容尊重您偏好的行为规范爬虫。
在实现 noai 标签及其他指令后,您还应验证爬虫是否真正遵守了您的规则。最直接的方法是检查服务器访问日志中的爬虫活动。在 Apache 服务器上,您可以查找特定爬虫:
grep "GPTBot\|ClaudeBot\|PerplexityBot" /var/log/apache2/access.log
如果发现被屏蔽爬虫仍有请求,说明它们未遵守您的指令。NGINX 服务器可在 /var/log/nginx/access.log 用同样命令检查。此外,Cloudflare Radar 等工具可帮助您洞察网站 AI 爬虫流量模式,了解最活跃的机器人及其行为变化。建议定期(至少每月)监控日志,发现新爬虫,并确认您的保护措施是否有效。
目前,noai 和 noimageai 仍处于灰色地带:它们已被主要 AI 公司广泛认可并尊重,但仍非官方标准。然而,推进正式标准化的势头正不断增强。W3C(万维网联盟)和多个行业组织正在讨论如何制定 AI 访问控制的官方标准,使这些指令能像 robots.txt 一样具有约束力。如果 noai 成为官方网络标准,遵守将成为行业惯例而非自愿行为,其有效性将显著提升。这一标准化进程反映了科技行业对内容创作者权益和 AI 发展与出版者保护之间平衡的新认识。随着越来越多出版者采用这些标签并要求更强保护,正式标准化的可能性也将提升,有望让 AI 访问控制成为与搜索引擎索引规则同等基础的网络治理要素。
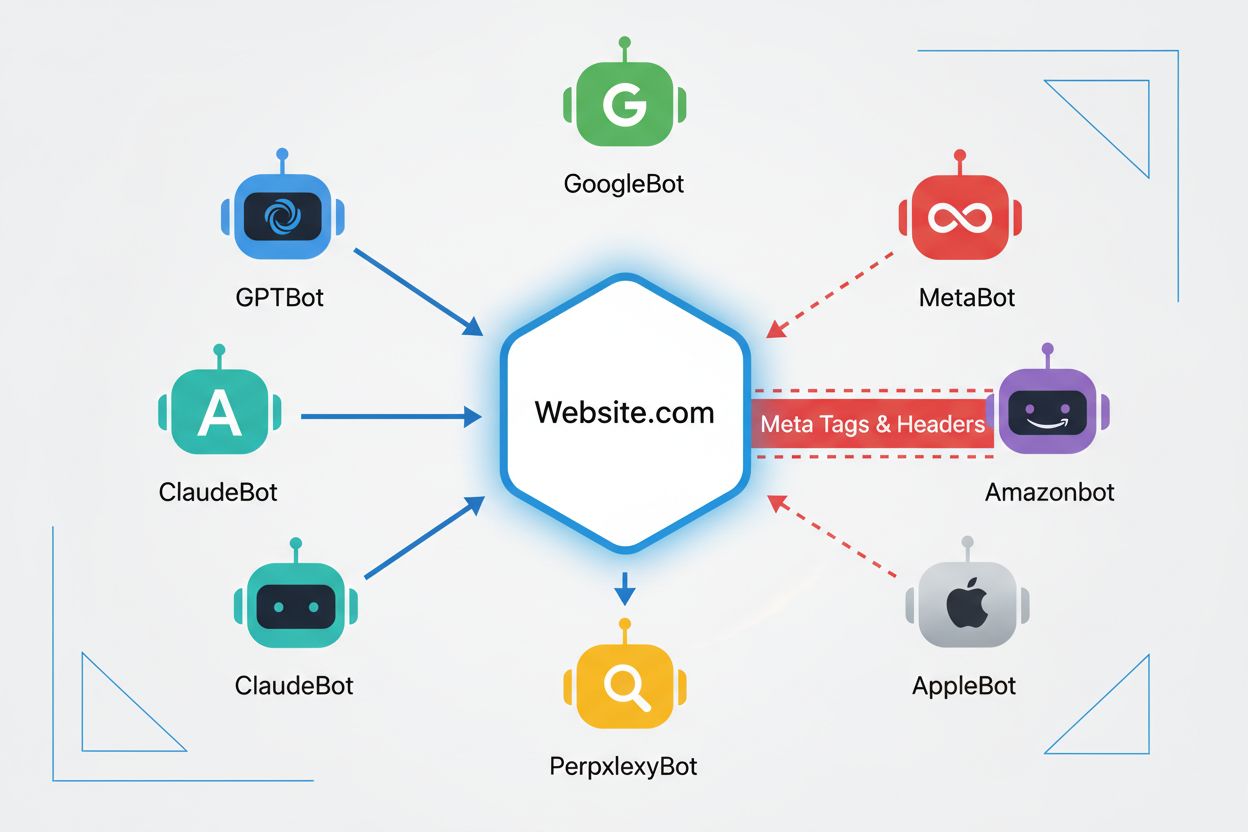
noai 元标签是放置在您网站 HTML head 部分的指令,用于向 AI 爬虫表明您的内容不应被用于训练人工智能模型。它通过向行为规范的 AI 机器人传达您的偏好来工作,尽管它不是官方网络标准,部分爬虫可能会忽略这一指令。
不是,noai 和 noimageai 都不是官方网络标准。它们是 DeviantArt 作为社区倡议创建,用于帮助内容创作者保护其作品不被用于 AI 训练。然而,OpenAI、Anthropic 等主要 AI 公司已开始在其爬虫中尊重这些指令。
主要的 AI 爬虫,包括 GPTBot(OpenAI)、ClaudeBot(Anthropic)、PerplexityBot(Perplexity)、Amazonbot(Amazon)等都会遵守 noai 指令。不过,一些规模较小或行为不规范的爬虫可能会忽略它,因此建议采用分层防护策略。
元标签放置在您的 HTML head 部分,适用于单个页面,而 HTTP 头信息(X-Robots-Tag)是在服务器层面设置的,可以全局或针对特定文件类型生效。头信息也适用于如 PDF、图片等非 HTML 文件,因此在全面防护上更为灵活。
可以。您可以通过多种方式在 WordPress 上实现 noai 标签:将代码加入主题的 functions.php 文件、使用 WPCode 等插件,或者通过 Divi 和 Elementor 等页面构建工具。functions.php 方法最为常见,只需添加一个简单的钩子即可将元标签注入网站头部。
这取决于您的业务目标。屏蔽训练型爬虫可以保护您的内容不被用于 AI 模型开发。但屏蔽如 OAI-SearchBot 等搜索爬虫可能会降低您在 AI 搜索结果和发现平台中的可见性。许多出版者采用有选择性的做法,仅屏蔽训练型爬虫,允许搜索型爬虫访问。
您可以通过如 grep 命令在服务器日志中查找特定爬虫的用户代理活动。Cloudflare Radar 等工具也能帮助您洞察 AI 爬虫流量模式。定期监控日志,查看被屏蔽的爬虫是否仍在访问您的内容,若有则说明它们忽略了您的指令。
如果爬虫忽略了您的元标签,请增加其他防护层,如 robots.txt 规则、X-Robots-Tag HTTP 头信息,以及通过 .htaccess 或防火墙规则进行服务器级屏蔽。为更强的验证,可使用 IP 白名单,仅允许主要 AI 公司公布的经过验证的爬虫 IP 地址访问。
使用 AmICited 跟踪 ChatGPT、Perplexity 和 Google AI Overviews 等 AI 系统如何在不同 AI 平台上引用和参考您的内容。
了解 NoAI 元标签是什么、它如何防止 AI 抓取、实现方法,以及其在保护您的内容免受未经授权的 AI 训练方面的有效性。

了解 noai 元标签、其防止 AI 训练数据采集的工作方式、局限性,以及如何在你的网站上实现它,从而保护你的内容免受生成式 AI 程序的侵用。...
了解元标签如何为AI驱动搜索而演变。学习哪些元标签对AI优化和AI摘要中的可见性最为重要,以及提升搜索排名的实用策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.