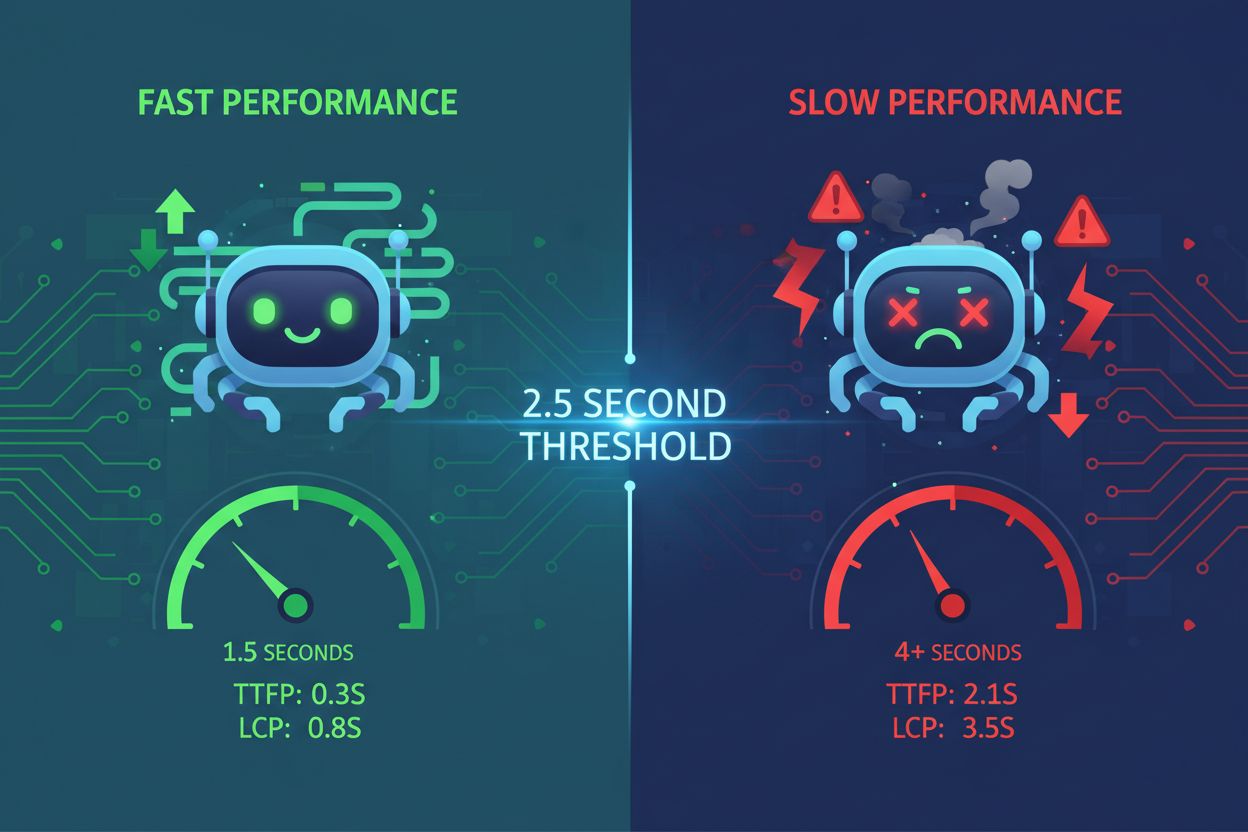
网站速度与AI可见性:性能是否影响被引用率?
了解网站速度如何直接影响ChatGPT、Gemini和Perplexity等AI的可见性和被引用率。掌握2.5秒阈值及AI爬虫优化策略。
1 分钟阅读
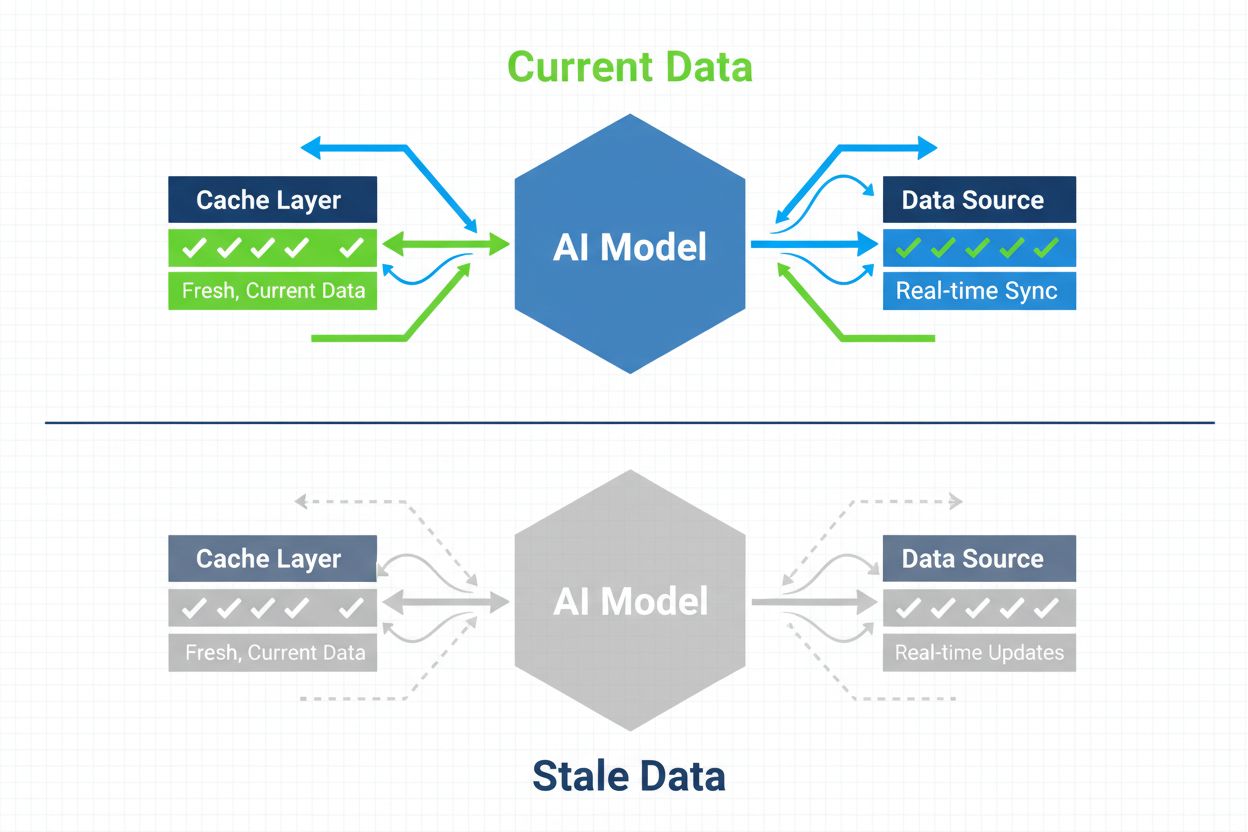
确保AI系统访问当前内容而非过时缓存版本的策略。缓存管理在利用缓存提升性能的同时,权衡提供过时信息的风险,通过失效策略和监控,保持数据新鲜度,同时降低延迟和成本。
确保AI系统访问当前内容而非过时缓存版本的策略。缓存管理在利用缓存提升性能的同时,权衡提供过时信息的风险,通过失效策略和监控,保持数据新鲜度,同时降低延迟和成本。
AI缓存管理是指有系统地存储和检索先前计算结果、模型输出或API响应,以避免冗余处理并降低人工智能系统延迟的方法。核心挑战在于,在利用缓存数据提升性能的同时,避免提供不再反映当前系统状态或用户需求的过时信息。对于推理成本高昂、响应时间直接影响用户体验的大语言模型(LLM)和AI应用,这一问题尤为关键。缓存管理系统必须智能判断何时缓存结果仍然有效,何时需要重新计算,这使得缓存成为生产级AI部署的基础架构考量。
高效缓存管理对AI系统性能的提升是显著且可量化的。在重复查询场景下,缓存策略可将响应延迟降低80-90%,同时API成本可降低50-90%(取决于缓存命中率和系统架构)。除了性能指标外,缓存管理还直接影响准确性一致性和系统可靠性。得当的缓存失效可以确保用户获取到最新信息,而管理不善的缓存则会引入数据陈旧问题。随着AI系统扩展到处理数百万请求,缓存效率的累积效果将直接决定基础设施成本和用户满意度。
| 方面 | 缓存系统 | 非缓存系统 |
|---|---|---|
| 响应时间 | 快80-90% | 基线 |
| API成本 | 降低50-90% | 全部成本 |
| 准确性 | 一致 | 可变 |
| 可扩展性 | 高 | 有限 |
缓存失效策略决定了缓存数据如何、何时被刷新或移除,是缓存架构设计中最关键的决策之一。不同的失效方式在数据新鲜度和系统性能间各有权衡:
选择何种失效策略本质上取决于应用需求:优先数据准确性的系统可通过激进失效接受更高延迟成本,而对性能要求极高的应用则可能容忍轻微数据陈旧,以保持亚毫秒级响应。
在大语言模型中,提示缓存是一种特定的缓存管理应用,存储中间模型状态和Token序列,避免对相同或相似输入的重复处理。LLM主要有两类缓存方式:精确缓存通过逐字符匹配实现完全一致,语义缓存则识别不同措辞但功能等价的提示。OpenAI自动实现提示缓存,对缓存Token可节省50%成本,需提示片段大于1024 Token才触发缓存。Anthropic提供手动提示缓存,节省幅度高达90%,但需要开发者显式管理缓存键和持续时间,且最小缓存要求为1024-2048 Token(取决于模型配置)。LLM系统中的缓存有效期通常从几分钟到数小时不等,旨在平衡重复利用缓存状态带来的计算节省与时效性应用下输出过时的风险。
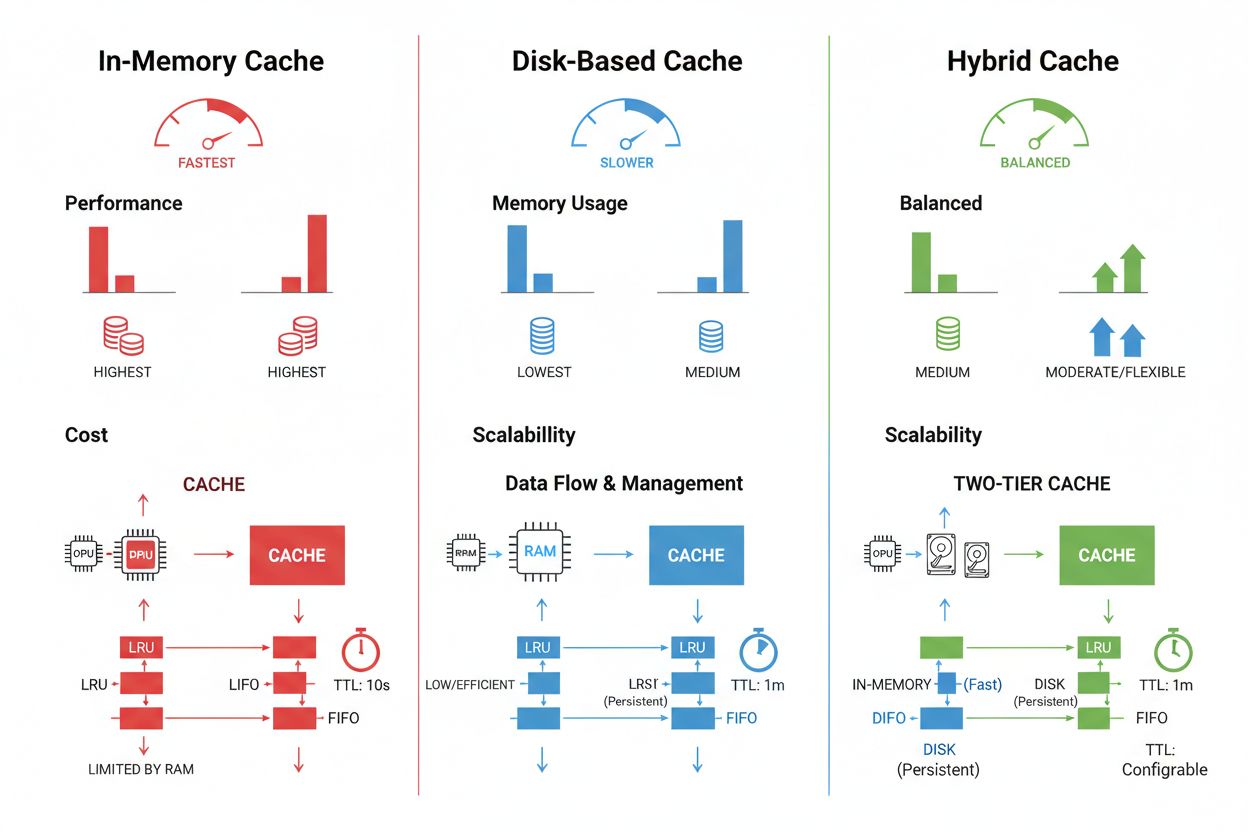
根据性能需求、数据量及基础设施约束,缓存存储与管理技术有显著差异,各有优缺点。内存缓存(如Redis)提供微秒级访问速度,适合高频查询,但消耗大量RAM且需精细内存管理。磁盘缓存可容纳更大数据集,并在系统重启后保持持久,但相比内存缓存延迟为毫秒级。混合方案结合两者,将高频访问数据放入内存,较大数据集保存在磁盘:
| 存储类型 | 最适场景 | 性能 | 内存占用 |
|---|---|---|---|
| 内存(Redis) | 高频查询 | 速度最快 | 高 |
| 磁盘 | 大数据集 | 中等 | 低 |
| 混合 | 混合负载 | 平衡 | 平衡 |
高效缓存管理需根据数据波动性配置合适的TTL设置——快速变化数据用短TTL(分钟级),稳定内容用长TTL(小时/天级)——并持续监控缓存命中率、逐出模式以及内存使用,及时挖掘优化空间。
实际AI应用展现了缓存管理的变革潜力与运维复杂性。客服机器人通过缓存常见问题的答案,降低推理成本60-70%,高效服务数千并发用户。编程助手缓存常见代码模式和文档片段,使开发者即使在高峰期也能获得亚100毫秒的自动补全建议。文档处理系统缓存高频分析文档的嵌入和语义表示,大幅加速相似度检索和分类任务。然而,生产环境下的缓存管理也带来诸多挑战:分布式系统中的失效复杂度呈指数级增长,需在多台服务器间保持缓存一致性;资源受限时,缓存大小与覆盖范围需权衡取舍;缓存敏感数据时若无加密和访问控制将引发安全风险;微服务架构下的缓存更新协调易导致竞态条件和数据不一致。因而,综合监控缓存新鲜度、命中率和失效事件的解决方案对于保障系统可靠性与根据数据模式和用户行为调整缓存策略至关重要。
缓存失效是在发生更改时移除或更新过时数据,能立即保证新鲜度,但需要事件驱动触发。缓存过期则为缓存数据设置一个时限(TTL),实现方式更简单,但如果TTL设置过长,可能会提供过时数据。许多系统会结合两者以实现最佳性能。
高效的缓存管理可根据缓存命中率和系统架构将API成本降低50-90%。OpenAI的提示缓存对缓存Token可减少50%成本,而Anthropic最高可减少90%。实际节省取决于查询模式以及能被有效缓存的数据量。
提示缓存会存储模型中间状态和Token序列,避免大语言模型重复处理相同或相似输入。它支持精确缓存(逐字符匹配)和语义缓存(不同措辞但功能等价的提示)。这可将延迟降低80%,并在重复查询时将成本降低50-90%。
主要策略包括:基于时间的过期(TTL),在设定时长后自动移除;基于事件的失效,在数据变动时立即更新;语义失效,根据含义失效相似查询;以及混合策略,结合多种方式。选择取决于数据波动和新鲜度需求。
内存缓存(如Redis)提供微秒级访问速度,适合频繁查询,但占用大量RAM。磁盘缓存可容纳更大数据集并可重启持久,但延迟为毫秒级。混合方案则将常用数据放入内存,较大数据集存于磁盘。
TTL是一种倒计时定时器,决定缓存数据在过期前的有效时长。短TTL(几分钟)适合变化快的数据,长TTL(数小时/天)适合稳定内容。合理配置TTL可在数据新鲜度与避免无谓刷新和服务器负载间取得平衡。
有效的缓存管理可使AI系统在无需成比例扩展基础设施的情况下处理大量请求。通过缓存减少每次请求的计算负载,系统可更具成本效益地服务数百万用户。缓存命中率直接决定了生产环境中的基础设施成本和用户满意度。
缓存敏感数据若未加密和访问控制,会带来安全漏洞。风险包括:缓存信息被未授权访问,失效期间数据暴露,以及不慎缓存机密内容。全面加密、访问控制和监控是保护敏感缓存数据的关键。
了解网站速度如何直接影响ChatGPT、Gemini和Perplexity等AI的可见性和被引用率。掌握2.5秒阈值及AI爬虫优化策略。
了解如何针对来自GPT、Perplexity和Google AI Overviews的AI流量优化着陆页。通过AmICited发现转化优化和AI引用监测的最佳实践。

了解 AI 系统如何通过新鲜度衰减算法,随时间推移降低内容相关性评分。掌握时间衰减函数、监测策略,以及如何在 AI 驱动的搜索结果中保持可见性。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.