
AI可见性的A/B测试:方法与最佳实践
通过本全面指南掌握AI可见性的A/B测试。学习GEO实验、方法论、最佳实践以及真实案例研究,提升AI监控效果。
1 分钟阅读

在生产部署前,用于验证、评估和调试人工智能模型及应用的隔离沙盒环境。这些受控空间可在不同平台上测试 AI 内容表现、衡量各项指标,并确保可靠性,而不会影响线上系统或暴露敏感数据。
在生产部署前,用于验证、评估和调试人工智能模型及应用的隔离沙盒环境。这些受控空间可在不同平台上测试 AI 内容表现、衡量各项指标,并确保可靠性,而不会影响线上系统或暴露敏感数据。
AI 测试环境是一个受控、隔离的计算空间,用于在模型部署到生产系统前,对人工智能模型及应用进行验证、评估与调试。它是开发者、数据科学家和 QA 团队可安全运行 AI 模型、测试不同配置,并基于预设指标衡量性能的沙盒环境,无需担心影响线上系统或泄露敏感数据。这些环境可模拟生产条件,同时保持完全隔离,使团队能够发现问题、优化模型行为,并确保在各种场景下的可靠性。测试环境作为 AI 开发生命周期中的关键质量闸门,连接着实验原型和企业级部署之间的桥梁。

一个完整的 AI 测试环境由多个相互关联的技术层共同构建,保障全面的测试能力。模型执行层负责实际的推理与计算,支持多种框架(PyTorch、TensorFlow、ONNX)及模型类型(大语言模型、计算机视觉、时序模型)。数据管理层管理测试数据集、测试夹具和合成数据生成,同时确保数据隔离与合规。评估框架包含指标引擎、断言库与评分系统,将模型输出与预期结果进行比对。监控与日志层捕获执行轨迹、性能指标、延迟数据及错误日志,供测试后分析。编排层管理测试流程、并行执行、资源分配及环境配置。下表为不同类型测试环境的关键架构组件对比:
| 组件 | 大模型测试 | 计算机视觉 | 时序模型 | 多模态 |
|---|---|---|---|---|
| 模型运行时 | Transformer 推理 | GPU 加速推理 | 序列处理 | 混合执行 |
| 数据格式 | 文本/Token | 图像/张量 | 数值序列 | 混合媒体 |
| 评估指标 | 语义相似度、幻觉 | 准确率、IoU、F1 分数 | RMSE、MAE、MAPE | 跨模态对齐 |
| 延迟要求 | 典型 100-500ms | 典型 50-200ms | 典型 <100ms | 典型 200-1000ms |
| 隔离方式 | 容器/虚拟机 | 容器/虚拟机 | 容器/虚拟机 | Firecracker 微虚拟机 |
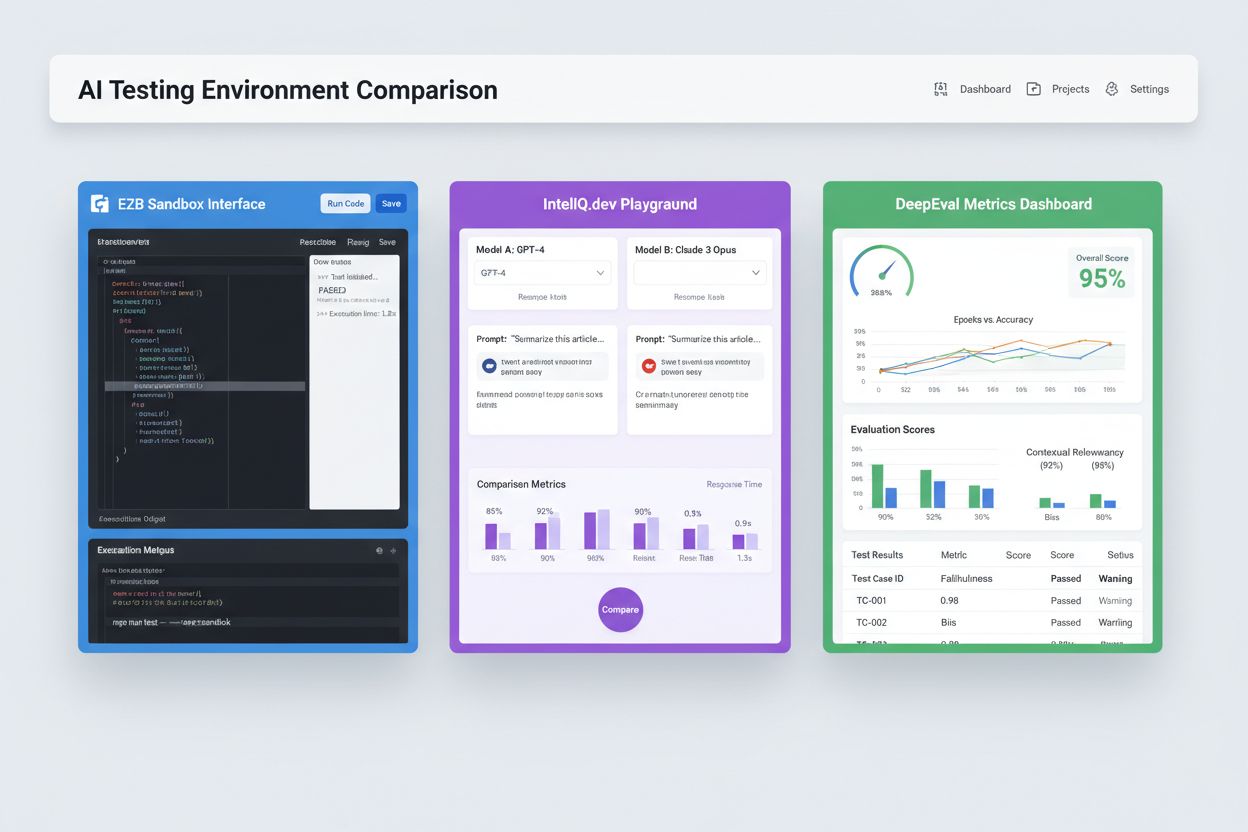
现代 AI 测试环境需支持异构模型生态,便于团队同时在不同大模型服务商、框架及部署目标下评估应用。多平台测试让组织能够在同一测试体系下,比较 OpenAI GPT-4、Anthropic Claude、Mistral 及 Llama 等开源模型的输出,辅助模型选型决策。E2B 等平台提供隔离沙盒,可运行任何大模型生成的代码,支持 Python、JavaScript、Ruby 和 C++,具备完整文件系统访问、终端与包安装能力。IntelIQ.dev 支持多模型并行比对,界面统一,便于在不同服务商间测试带有安全策略的提示词和模板。测试环境需具备:
AI 测试环境满足开发、质量保障与合规等多样化需求。开发团队用于迭代开发阶段,验证模型行为、测试提示词变化、微调参数、调试异常输出,确保集成前模型表现达标。数据科学团队可在留存数据集上评估模型性能,比较不同架构,衡量准确率、精确率、召回率、F1 分数等指标。生产监控则通过持续测试已部署模型与基线指标比对,及时发现性能下降并触发再训练。合规与安全团队利用测试环境验证模型是否符合法规、不产生偏见输出,并妥善处理敏感数据。企业级应用包括:
AI 测试领域包含为不同场景及组织规模量身打造的专用平台。DeepEval 是开源的大语言模型评测框架,内置 50+ 研究支持指标(答案正确性、语义相似度、幻觉检测、毒性评分等),与 Pytest 原生集成,适用于 CI/CD 流程。LangSmith(LangChain 出品)具备完善的可观测性、评估与部署能力,内置追踪、提示词版本管理及数据集管理,专为 LLM 应用设计。E2B 提供基于 Firecracker 微虚拟机的安全隔离沙盒,支持代码执行,启动时间低至 200ms,可持续会话达 24 小时,并集成主流大模型服务商。IntelIQ.dev 注重隐私优先,支持端到端加密、基于角色访问控制,并兼容 GPT-4、Claude 及开源模型。下表为主要能力对比:
| 工具 | 主要方向 | 指标 | CI/CD 集成 | 多模型支持 | 计费方式 |
|---|---|---|---|---|---|
| DeepEval | 大模型评测 | 50+ 指标 | 原生 Pytest | 有限 | 开源 + 云服务 |
| LangSmith | 可观测性与评测 | 自定义指标 | API 集成 | LangChain 生态 | 免费+企业版 |
| E2B | 代码执行 | 性能指标 | GitHub Actions | 全部大模型 | 按用量+企业 |
| IntelIQ.dev | 隐私优先测试 | 自定义指标 | 工作流构建器 | GPT-4、Claude、Mistral | 订阅制 |
企业级 AI 测试环境需实施严格的安全控制,保护敏感数据、满足合规要求、防止未授权访问。数据隔离要求测试数据不得泄露至外部 API 或第三方服务;E2B 等平台采用 Firecracker 微虚拟机,确保完全进程隔离、无内核共享。加密标准应覆盖数据静态与传输全程加密,满足 HIPAA、SOC 2 Type 2、GDPR 等合规需求。访问控制需实施基于角色的权限管理、审计日志、敏感测试场景审批流。最佳实践包括:测试数据集与生产数据分离、对个人信息(PII)进行脱敏、用合成数据实现真实测试而无隐私风险、定期安全审计测试基础设施、完整记录所有测试结果以便合规。建议同时部署偏见检测,识别歧视性模型行为,使用 SHAP、LIME 等可解释性工具理解模型决策,并建立决策日志追踪模型输出形成过程,便于监管溯源。
AI 测试环境需无缝融入现有持续集成与持续部署流程,实现自动质控与快速迭代。原生 CI/CD 集成可在每次代码提交、拉取请求或定时任务时自动触发测试,支持 GitHub Actions、GitLab CI、Jenkins 等平台。DeepEval 的 Pytest 集成支持开发者用标准 Python 测试编写模型测试用例,测试结果与传统单元测试一同报告。自动评测能衡量模型性能指标、输出与基线版本比对,并在质量未达标时阻止上线。工件管理需将测试数据集、模型检查点、评估结果存储于版本控制或制品库,实现复现与审计。常见集成模式包括:
AI 测试环境正在快速演进,以应对模型复杂性、规模及异构性的新挑战。智能体测试日益重要,AI 系统已不再局限于单模型推理,而是多步工作流中,智能体需用工具、做决策、与外部系统交互——这对评估框架提出了任务完成率、安全性与可靠性的新要求。分布式评测通过在云端并行运行成千上万测试实例,实现大规模强化学习及模型训练的必要支撑。实时监控正从批量评估转向生产级持续测试,及时侦测性能下降、数据漂移与新兴偏见。可观测性平台如 AmICited 已成为 AI 监控和可视化的关键工具,集中展示模型性能、使用模式及全局质量指标。未来测试环境将更多融合自动修复机制,不仅检测问题,还能自动触发再训练或模型更新,并实现跨模态评测,支持文本、图像、音频、视频模型在统一框架下同步测试。
AI 测试环境是一个隔离的沙盒,您可以在其中安全地测试模型、提示词和配置,而不会影响线上系统或用户。生产部署则是模型实际为用户提供服务的环境。测试环境可帮助您在上线前发现问题、优化性能、验证变更,从而降低风险并保障质量。
可以,现代 AI 测试环境支持多模型同时测试。E2B、IntelIQ.dev 和 DeepEval 等平台允许您在不同的大模型服务商(如 OpenAI、Anthropic、Mistral 等)间,对同一提示词或输入同时测试,以便直接比较输出和性能指标。
企业级 AI 测试环境实施了多重安全防护,包括数据隔离(容器化或微虚拟机)、端到端加密、基于角色的访问控制、审计日志记录及合规认证(SOC 2、GDPR、HIPAA)。除非明确导出,数据不会离开隔离环境,从而保护敏感信息。
测试环境通过记录所有模型评估的审计轨迹、支持数据脱敏与合成数据生成、强制访问控制,并将测试数据与生产系统完全隔离,助力合规。这些文档和控制措施有助于企业满足如 GDPR、HIPAA 和 SOC 2 等监管要求。
关键指标取决于您的应用场景:对于大语言模型,关注准确率、语义相似度、幻觉率和延迟;RAG 系统关注上下文精确率/召回率及真实性;分类模型关注精确率、召回率和 F1 分数;所有模型都应跟踪性能随时间的变化和偏见指标。
费用因平台而异:DeepEval 为开源免费工具;LangSmith 提供免费层,付费方案起价为 $39/月;E2B 按沙盒运行时长计费;IntelIQ.dev 则为订阅制。许多平台也为企业级部署提供定制价格。
可以,大多数现代测试环境支持 CI/CD 集成。DeepEval 可与 Pytest 原生集成,E2B 支持 GitHub Actions 和 GitLab CI,LangSmith 则提供基于 API 的集成。这些能力支持每次代码提交自动测试并实现部署门控。
端到端测试将整个 AI 应用视为黑盒,对最终输出与预期结果进行比对。组件级测试则单独评估每个环节(如大模型调用、检索器、工具使用),通过追踪和工具化获取更细致的信息。组件级测试更易定位问题根源,端到端测试则验证整体系统行为。
通过本全面指南掌握AI可见性的A/B测试。学习GEO实验、方法论、最佳实践以及真实案例研究,提升AI监控效果。

了解什么是环境型AI助理、它们如何在智能家居中工作、对购买决策的影响,以及智能生活环境的未来。全面指南,解析主动型AI系统。...
了解如何将你的AI可见性与竞争对手进行基准对比。追踪引用、声音份额以及在ChatGPT、Perplexity和Google AI上的竞争定位。发现用于竞争性AI分析的工具和策略。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.