
PerplexityBot:每个网站所有者都需要了解的内容
PerplexityBot爬虫的完整指南——了解其工作方式、管理访问权限、监控引用,并优化以提升Perplexity AI的可见性。了解有关隐秘爬取的担忧和最佳实践。...
1 分钟阅读

亚马逊用于提升包括Alexa、Rufus购物助手和亚马逊AI搜索功能在内的产品和服务的网页爬虫。它遵循Robots Exclusion Protocol,并可通过robots.txt指令进行控制。也可能被用于AI模型训练。
亚马逊用于提升包括Alexa、Rufus购物助手和亚马逊AI搜索功能在内的产品和服务的网页爬虫。它遵循Robots Exclusion Protocol,并可通过robots.txt指令进行控制。也可能被用于AI模型训练。
Amazonbot是亚马逊官方的网页爬虫,旨在通过收集和分析网页内容来提升公司产品与服务。这个先进的爬虫为亚马逊的关键功能提供支持,包括Alexa语音助手、Rufus AI购物助手以及亚马逊的AI驱动搜索体验。Amazonbot使用的user agent字符串为Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36,可用于向Web服务器标识自身。Amazonbot收集的数据可能被用于训练亚马逊的人工智能模型,这使其成为亚马逊AI基础设施与产品开发战略的重要组成部分。
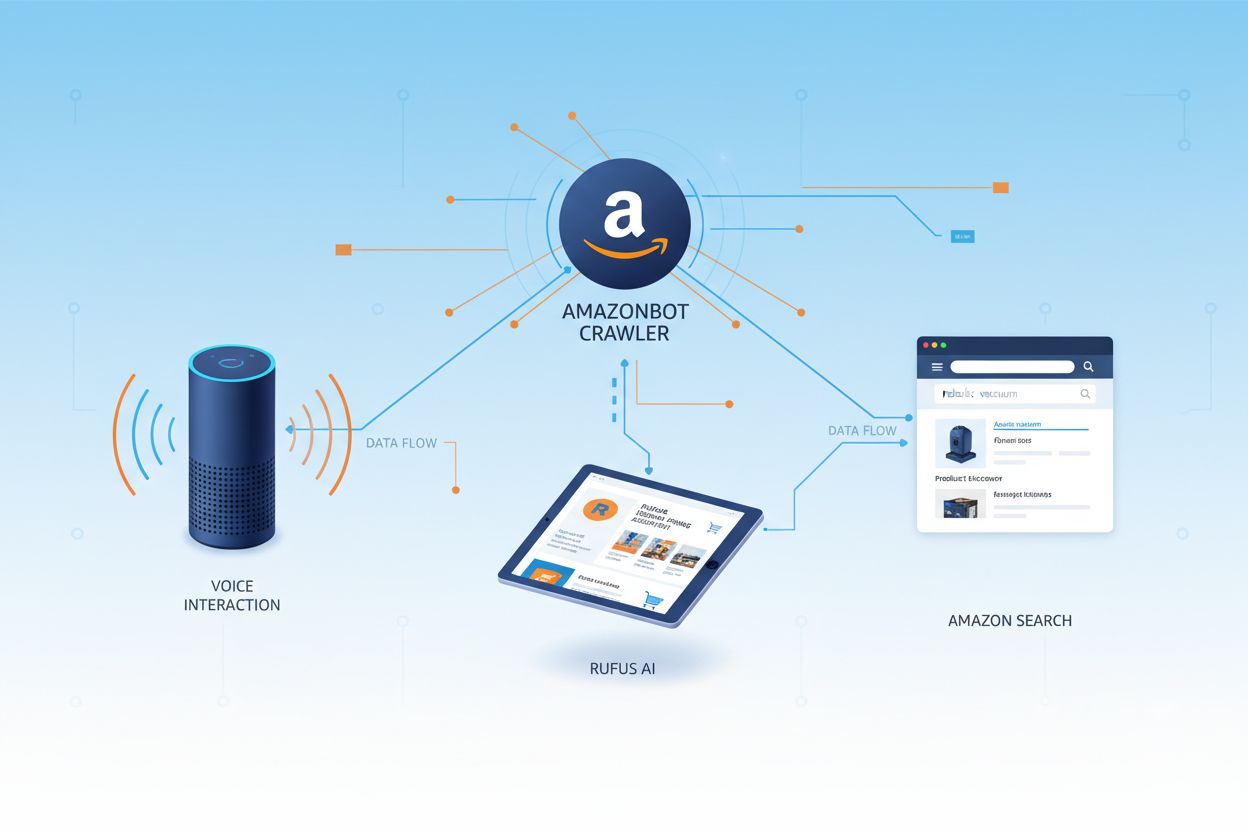
亚马逊运营着三种不同的网页爬虫,每种在其生态系统中有特定用途。Amazonbot是主要爬虫,用于整体产品和服务改进,也可能被用于AI模型训练。Amzn-SearchBot则专为提升Alexa和Rufus等亚马逊产品的搜索体验而设计,且重要的是——它不会抓取内容用于生成式AI模型训练。Amzn-User则支持用户发起的操作,比如当用户向Alexa提问需要最新网页数据时,抓取实时信息,也不会用于AI训练。三种爬虫均遵循Robots Exclusion Protocol并遵守robots.txt指令,网站所有者可据此控制其访问权限。亚马逊在其开发者门户公开每个爬虫的IP地址,便于站长验证真实流量。另外,所有亚马逊爬虫都支持链接级rel=nofollow指令及页面级robots meta标签,包括noarchive(防止用于模型训练)、noindex(防止收录)、none(两者都防止)。
| 爬虫名称 | 主要用途 | AI模型训练 | User Agent | 关键应用场景 |
|---|---|---|---|---|
| Amazonbot | 产品/服务整体提升 | 是 | Amazonbot/0.1 | 亚马逊服务优化、AI训练 |
| Amzn-SearchBot | 搜索体验提升 | 否 | Amzn-SearchBot/0.1 | Alexa搜索、Rufus购物助手索引 |
| Amzn-User | 用户发起的实时数据抓取 | 否 | Amzn-User/0.1 | Alexa实时查询、最新信息请求 |
亚马逊遵循行业标准的Robots Exclusion Protocol(RFC 9309),这意味着网站所有者可以通过robots.txt文件控制Amazonbot的访问。亚马逊会从您域名根目录(如example.com/robots.txt)抓取robots.txt文件,若无法获取则使用最近30天的缓存。robots.txt文件的变更通常约24小时后会反映在亚马逊系统中。该协议支持标准的user-agent和allow/disallow指令,您可精细控制哪些爬虫能访问哪些目录或文件。但需注意,亚马逊爬虫不支持crawl-delay指令,若在robots.txt中写入该参数会被忽略。
以下为Amazonbot访问控制示例:
# 阻止Amazonbot抓取您整个网站
User-agent: Amazonbot
Disallow: /
# 允许Amzn-SearchBot以获得搜索可见性
User-agent: Amzn-SearchBot
Allow: /
# 阻止Amazonbot抓取特定目录
User-agent: Amazonbot
Disallow: /private/
# 允许所有其他爬虫
User-agent: *
Disallow: /admin/
担心爬虫流量的网站所有者应验证自称为Amazonbot的爬虫是否真的来自亚马逊。亚马逊提供了基于DNS查询的验证流程,以确认Amazonbot的真实性。首先,在服务器日志中找到访问IP地址,然后用host命令进行反向DNS查询。得到的域名应为crawl.amazonbot.amazon的子域。接着对该域名做一次正向DNS查询,确认其解析回原始IP。该双向验证流程有助于防止伪造攻击,因为恶意者可能通过伪造反向DNS冒充Amazonbot。亚马逊在开发者门户(developer.amazon.com/amazonbot/ip-addresses/)公开所有爬虫的官方IP地址,也可据此比对。
验证示例:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
如有关于Amazonbot的疑问或需报告可疑行为,请直接联系亚马逊(amazonbot@amazon.com),并在邮件中附上相关域名信息。
亚马逊不同爬虫在AI模型训练方面有关键区别。Amazonbot可能被用于亚马逊人工智能模型训练,这对于关注内容是否被用于AI训练的内容创作者尤为重要。而Amzn-SearchBot和Amzn-User则明确不会抓取内容用于生成式AI模型训练,它们仅用于提升搜索体验和支持用户查询。如果您想阻止自己的内容被用于AI训练,可在网页HTML头部添加robots meta标签noarchive,指示Amazonbot不得将该页面用于模型训练。这一区别对于希望控制自身内容在AI训练管道中用途的内容方、创作者及站长来说尤为重要,同时仍可让内容出现在亚马逊搜索和Rufus推荐中。
Rufus是亚马逊先进的AI购物助手,结合网页抓取和AI技术,为用户提供个性化购物推荐与支持。Amazonbot为亚马逊整体AI基础设施提供支持,而Rufus则专门使用Amzn-SearchBot索引与购物查询相关的产品信息和网页内容。Rufus基于Amazon Bedrock,采用包括Anthropic的Claude Sonnet和Amazon Nova在内的先进大语言模型,并结合自定义模型,训练数据涵盖亚马逊海量产品目录、用户评价、社区问答及网页信息。该购物助手协助用户调研商品、对比选择、追踪价格、发现优惠,甚至能在价格到达目标时自动下单。自推出以来,Rufus极为受欢迎,用户数超过2.5亿,月活跃用户增长149%,互动量同比增加210%。使用Rufus购物的客户,其购买转化率提升超60%,显示出AI购物助手对消费行为的显著影响。
网站所有者应结合自身业务目标和内容政策,制定有针对性的亚马逊爬虫管理策略:
noarchive robots meta标签,或通过robots.txt完全阻止Amazonbot是亚马逊的通用型爬虫,用于提升产品和服务,也可能被用于AI模型训练。Amzn-SearchBot则专为Alexa和Rufus的搜索体验设计,明确不用于AI模型训练。如果您希望阻止AI训练用途,请阻止Amazonbot,但允许Amzn-SearchBot以获得搜索可见性。
在您域名根目录下的robots.txt文件中添加以下内容:User-agent: Amazonbot,接着是Disallow: /。这样可阻止Amazonbot抓取您整个网站。您也可以用Disallow: /specific-path/仅阻止某些目录。
会,Amazonbot可能会被用于训练亚马逊的人工智能模型。如果您想阻止此行为,请在网页的HTML头部使用robots meta标签,这样可指示Amazonbot不将该页面用于模型训练。
对爬虫的IP地址执行反向DNS查询,确认域名为crawl.amazonbot.amazon的子域。然后再做一次正向DNS查询,确保该域名解析回原IP地址。您也可以在developer.amazon.com/amazonbot/ip-addresses/查阅亚马逊公布的IP地址。
使用标准的robots.txt语法:User-agent: Amazonbot来针对该爬虫,后接Disallow: /阻止所有访问,或Disallow: /path/阻止特定目录。您也可以用Allow: /明确允许访问。
亚马逊通常会在约24小时内反映robots.txt的变更。亚马逊会定期抓取您的robots.txt,并最多缓存30天,因此更改可能需要一天才能在其系统中完全生效。
可以,完全没问题。您可以在robots.txt文件中为每个爬虫创建单独的规则。例如,用User-agent: Amzn-SearchBot和Allow: /允许Amzn-SearchBot,同时用User-agent: Amazonbot和Disallow: /阻止Amazonbot。
请直接联系亚马逊,邮箱为amazonbot@amazon.com。邮件中务必包含您的域名及相关细节,亚马逊支持团队会针对您的具体情况提供个性化建议。
PerplexityBot爬虫的完整指南——了解其工作方式、管理访问权限、监控引用,并优化以提升Perplexity AI的可见性。了解有关隐秘爬取的担忧和最佳实践。...

了解 PerplexityBot,这是一款由 Perplexity 开发的网页爬虫,为其 AI 答案引擎索引内容。了解其工作原理、对 robots.txt 的遵循以及如何在你的网站上管理它。...

学习如何让GPTBot、PerplexityBot和ClaudeBot等AI机器人抓取你的网站。配置robots.txt,设置llms.txt,并为AI可见性优化。
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.