
Wikipedia在AI引用中的作用:它如何塑造AI生成的答案
了解Wikipedia如何影响ChatGPT、Perplexity和Google AI等AI平台的引用。发现Wikipedia为何成为AI训练中最受信任的数据源,以及它如何影响您的品牌曝光度。...
1 分钟阅读
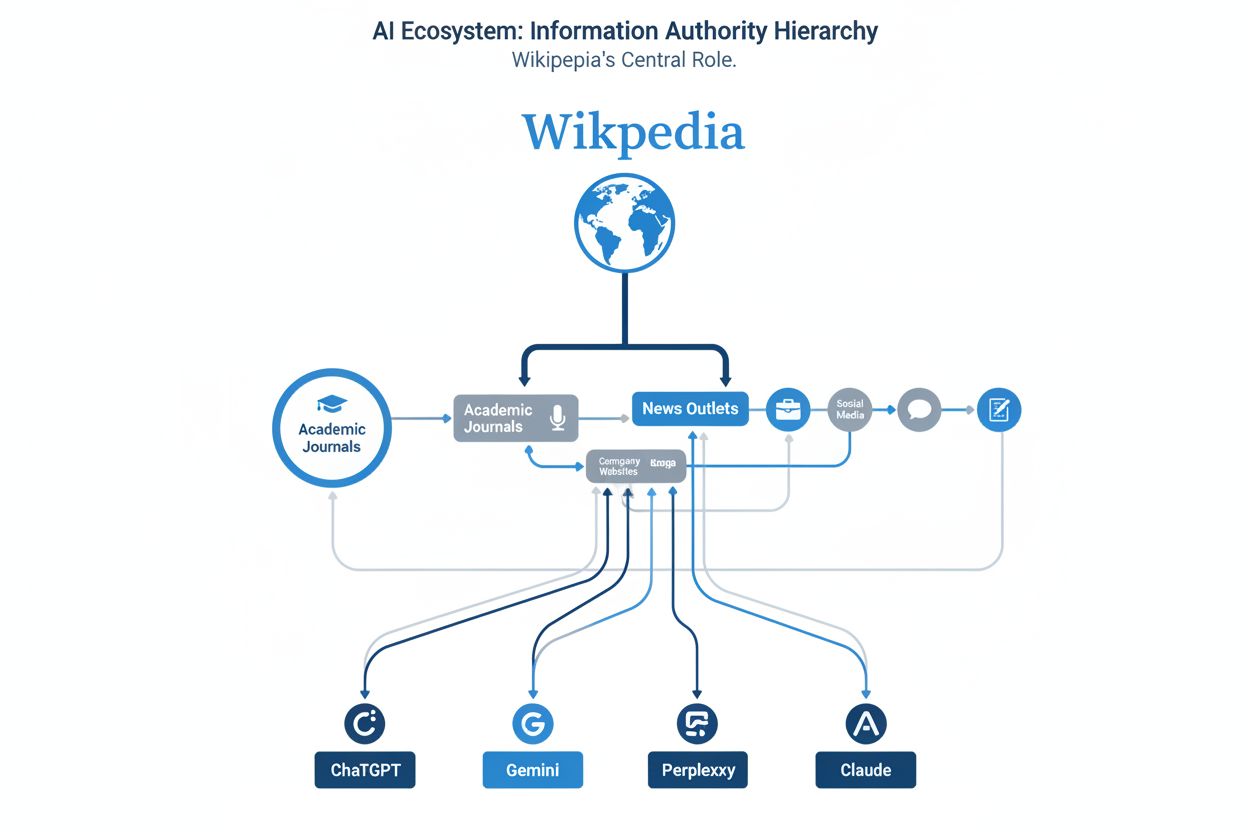
当维基百科引用通过 AI 训练数据传播,并影响品牌在 ChatGPT、Gemini 和 Perplexity 等 AI 平台上的提及方式时所产生的现象。当一个品牌被维基百科引用时,这些信息会在 AI 系统中层层扩散,塑造该品牌在多个 AI 平台上生成答案时的描述方式。
当维基百科引用通过 AI 训练数据传播,并影响品牌在 ChatGPT、Gemini 和 Perplexity 等 AI 平台上的提及方式时所产生的现象。当一个品牌被维基百科引用时,这些信息会在 AI 系统中层层扩散,塑造该品牌在多个 AI 平台上生成答案时的描述方式。
维基百科涟漪效应描述了维基百科的引用和信息如何通过 AI 训练数据传播,并同时影响多个 AI 平台上的品牌提及。当品牌被维基百科提及时,这些信息并不会只停留在单一页面——而是会流入 ChatGPT、Gemini、Perplexity、Claude 及其他大型语言模型的训练数据集,塑造这些系统对品牌的描述和引用。可以把这比作在水面投下一块石头:最初的影响(维基百科引用)形成涟漪,向外扩散,影响整个 AI 生态系统中的信息流动。这一现象从根本上改变了品牌在 AI 驱动时代获得可见度的方式,使维基百科的存在变得与传统网站优化同等重要,甚至更为关键。

现有的每一个主流大型语言模型都经过了维基百科内容的训练,这使其成为 AI 训练数据集中最大且最具影响力的来源之一。当 ChatGPT、Gemini、Claude 和 Perplexity 等 AI 系统获取训练数据时,维基百科条目因其中立性、社区验证和透明的引用结构而被赋予了不成比例的重要权重。数据显示,维基百科引用在主要平台的 AI 回答中出现的频率比直接引用公司官网高出 73%,无论用户询问品牌、产品还是行业信息。这并非偶然——AI 系统特别设计为优先考虑中立且有据可依的信息,而不是推广内容。下表展示了各大 AI 平台引用维基百科和公司官网的显著差异:
| 平台 | 维基百科引用率 | 公司官网引用率 | 维基百科首位出现率 |
|---|---|---|---|
| ChatGPT | 82% | 29% | 91% |
| Claude | 87% | 34% | 88% |
| Perplexity | 83% | 30% | 87% |
| Gemini | 84% | 31% | 89% |
这些数据揭示了一个基本事实:当 AI 系统生成关于您品牌的答案时,更可能引用维基百科而非您的官网,无论您的网站优化得多么出色。
维基百科涟漪效应通过一套复杂的信息传播链条运作,放大维基百科引用在多个系统中的权威。当您的品牌出现在维基百科上时,这些信息会成为 AI 模型训练数据的一部分,但影响远不止于此——像 Google 知识图谱这样的知识图谱会间接地从维基百科抓取信息,将其作为实体信息的主要来源。新闻报道链接至您的维基百科页面,会向 AI 系统强化维基百科作为权威来源的地位,形成研究者所称的**“引用链复合效应”。当多个来源(维基百科、新闻报道、监管披露、新闻稿)都表达相同观点时,AI 系统会对该说法赋予高置信度,并将维基百科的版本视为中立裁判,从而加重其权重。这就形成了“权威倍增器”**——维基百科不仅直接影响 AI 回答,还会放大有关品牌的其他信息的可信度。越多来源印证维基百科的说法,AI 系统就越有信心将其作为事实呈现。这就是为什么一个有据可依的维基百科提及,能在整个 AI 生态中产生指数级影响。
维基百科作为可信度关卡,决定 AI 系统如何评估和加权品牌与组织的信息。公司官网由于自我宣传的天然偏向,无法与维基百科相比,后者在全球数千名志愿编辑的监督下,严格执行中立立场(NPOV)要求。所有维基百科上的说法都必须有可靠来源作为支撑,社区会主动删除无据断言,形成了 AI 模型本能信任的自我纠错系统。当 AI 系统在训练中遇到矛盾信息——比如一个来源称公司为“尚未盈利”,另一个说“已获A轮融资”——维基百科因其中立与验证标准而成为权威裁决。这种可信优势还体现在知识图谱构建上,维基百科是 AI 系统理解实体、关系及属性的主要来源。维基百科透明的引用流程也帮助 AI 评估信息质量:每条引用都包含出版信息、作者、日期,甚至直接链接——算法可通过这些元数据评估来源可靠性并建立信任信号。
维基百科涟漪效应在用户每天接触的 AI 平台上表现为具体且可量化的效果。当有人询问 ChatGPT“[您的公司] 是做什么的?”时,回答通常始于来自或被维基百科印证的信息,即使用户从未访问过维基百科页面。Google 新的 AI 概览功能在生成搜索摘要时经常采用维基百科内容,这意味着维基百科提及可在 Google AI 生成的摘要中出现,而无需链接到您的官网。语音助手如 Google Assistant 和 Alexa 也大量依赖维基百科,提供简明、准确的答案——当有人问“最大的[产品品类]公司是哪家?”时,语音回复常常直接引用维基百科。RAG(检索增强生成)系统会实时从网络抓取信息补充 AI 回答,因结构化和可靠性,始终优先引用维基百科。特色摘要(即 Google 搜索结果顶部的答框)在定义性或事实性查询中大约 70% 来自维基百科。最终结果是,一条维基百科提及能带来多重下游可见度机会:影响 AI 训练、出现在知识面板、被 AI 回答引用,并通过语音搜索传播——这一切都无需用户实际点击维基百科。
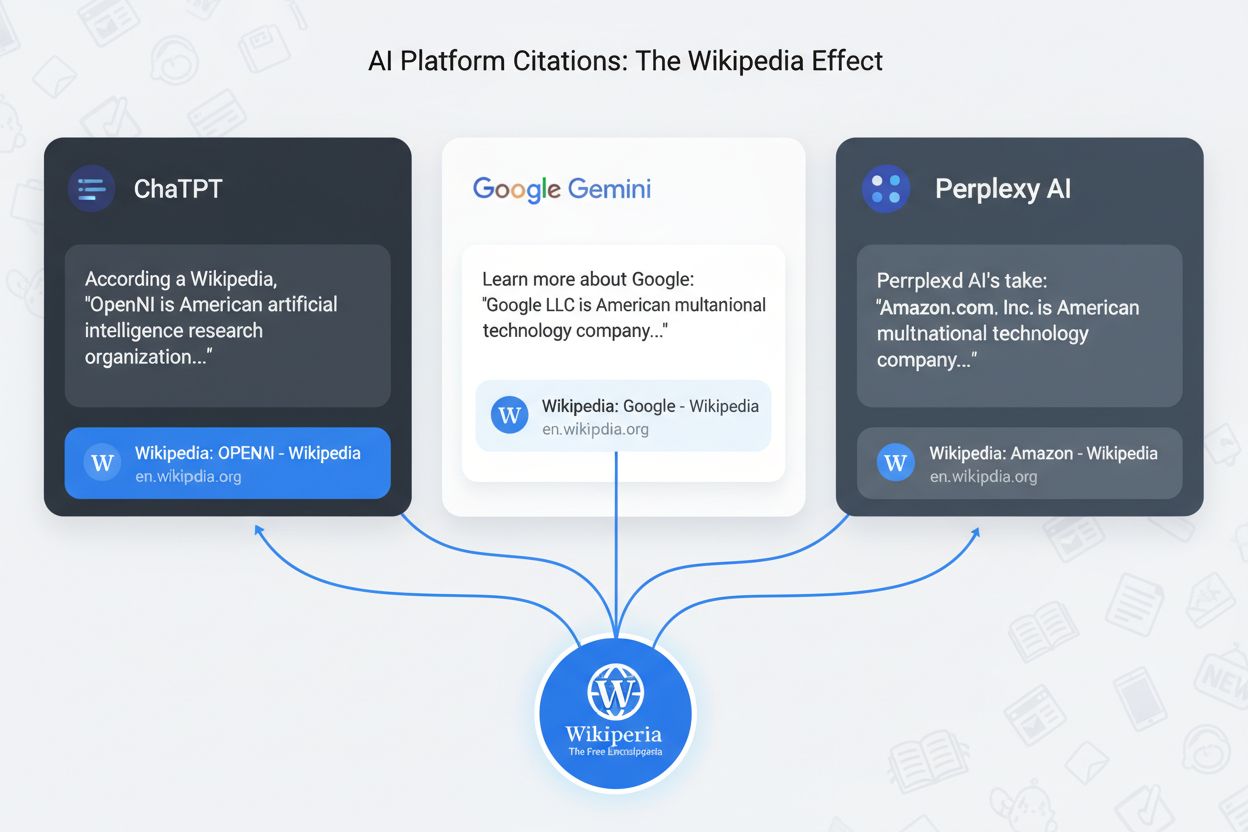
当您追踪单个维基百科提及如何影响不同 AI 平台的回答时,维基百科涟漪效应的真正威力就会显现。每个主流 AI 系统与维基百科的关系各有不同,但都将其视为权威来源:
这些效应的时效性各异:静态数据集训练的 AI 模型反映的是其训练截止日的维基百科内容,而实时 AI 搜索系统如 Perplexity 会在维基百科变动时即时更新。这意味着,一次维基百科更新可在数小时内影响多平台的 AI 回答(针对实时系统),而静态模型则需等到重训后,通常为数月。
理解维基百科涟漪效应只有在能衡量其对品牌 AI 可见度的影响时才有价值。有效的监测需追踪品牌在多平台 AI 回答中的出现频率,并比较来自维基百科与其他来源的提及。像 AmICited.com 这样的工具能让品牌监控其在 ChatGPT、Gemini、Perplexity 及其他 AI 平台上的提及,揭示 AI 系统讨论品牌时最常引用的来源。关键指标包括:AI 回答中维基百科引用和官网引用的频率、品牌提及的突出度与语境(是否被视为领导者、竞争者还是边缘玩家)、以及您在行业内的维基百科存在与竞争对手的对比。对维基百科的竞品情报分析能揭示谁在行业百科覆盖中占据主导地位——维基百科存在强势的公司,始终在 AI 回答中获得更突出和积极的提及。建立监测系统还能实时跟踪变化:当您更新维基百科页面后,可以观察这一变动在 AI 回答中的传播过程。数据驱动的方法,将维基百科从模糊的“锦上添花”转变为 AI 可见度战略的可衡量组成部分。
维基百科涟漪效应代表着品牌在数字可见度资源分配策略上的根本性转变。传统数字营销重在自有媒体——官网、博客、社交渠道——假定只要控制这些阵地就能掌控品牌叙事。涟漪效应打破了这一假设:精心优化的官网对 AI 驱动发现的作用已远不如一页维护良好的维基百科条目。这并不意味着放弃网站优化,而是要认识到百科权威已成为 AI 可见度战略的基石。那些投资于建立真实显著性(如媒体报道、研究、思想领导力、行业认可)并确保这些成就被维基百科妥善记录的品牌,在 AI 回答中赢得了更优质的位置。竞争优势会随时间复利:率先建立维基百科存在者,将受益于多年来不断累积的引用和参考,而后发竞争者则面临更高壁垒。与更广泛的公关和内容战略融合变得至关重要——每一则媒体报道、每个行业奖项、每一项研究出版都应被评估其是否能强化品牌在维基百科上的信息。维基百科优化的投资回报远超直接流量;它决定了数百万用户在日常使用的 AI 系统中如何发现和评价您的品牌。
随着 AI 成为信息获取的主要入口,维基百科涟漪效应只会愈发显著。当前趋势显示,未来 2-3 年内,AI 生成答案将超过传统搜索结果,成为人们了解公司、产品和行业的主要方式。随着这一转变加速,维基百科作为 AI 系统基础来源的作用将愈发关键——缺乏强大维基百科存在的品牌在 AI 驱动发现中将日益“隐形”。新兴 AI 平台持续将维基百科纳入训练集与实时检索系统,确保涟漪效应不断扩展到新工具。维基百科引用的复合效应意味着,今天建立强大存在的品牌,将随着更多 AI 系统的出现和更多用户依赖 AI 获取信息而获得指数级的可见度增长。展望未来,把握 AI 搜索主导权的品牌,将是那些早早认识到维基百科不只是另一个网站——而是告诉 AI 您是谁、为何重要的元数据层。
维基百科涟漪效应描述了维基百科的引用和信息如何通过 AI 训练数据传播,并同时影响多个 AI 平台上的品牌提及。当品牌被维基百科提及时,这些信息会通过 ChatGPT、Gemini、Perplexity、Claude 及其他大型语言模型的训练数据扩散,塑造这些系统如何描述和引用该品牌。
所有主流大型语言模型都经过了维基百科内容的训练,使其成为 AI 训练数据集中最大且最具影响力的来源之一。维基百科引用在 AI 回答中的出现频率比公司官网引用高出 73%,AI 系统优先选择维基百科,是因为它被认为中立、社区验证和引用结构透明。
所有主流 AI 平台都会受到影响,包括 ChatGPT(维基百科引用率 82%)、Claude(87%)、Perplexity(83%)以及 Google Gemini(84%)。此外,知识图谱、特色摘要、语音助手和 AI 概览都大量依赖维基百科作为品牌和组织信息的主要来源。
受严格的利益冲突政策限制,您无法直接控制维基百科内容,但可通过在可靠出版物中获得第三方报道,从而间接影响内容。重点获取媒体报道、行业认可和思想领导地位,自然促成维基百科的提及。
时间线取决于具体 AI 系统。实时 AI 搜索系统如 Perplexity 在维基百科变动时会即时更新。基于静态数据集训练的 AI 模型会反映其训练截止日期的维基百科内容,模型重训后,更新通常在数月内生效。
对于 AI 驱动的发现而言,维基百科正变得比公司官网更为重要。虽然传统网站优化对于直接流量和转化依然有价值,但维基百科的存在已成为 AI 可见度和行业定位的基础,因为 AI 系统更优先考虑百科全书式的信息而非推广内容。
可利用如 AmICited.com 这样的 AI 引用监测工具,追踪品牌在多平台 AI 回答中的出现频率。对比 AI 系统讨论品牌时最常引用的来源,比较维基百科与公司官网的引用量,并分析品牌在竞品中的定位。
投资回报不仅限于维基百科页面本身的直接流量。强大的维基百科存在会影响数百万用户通过日常使用的 AI 系统发现和评价您的品牌。维基百科覆盖良好的企业,在 AI 回答中持续获得更突出、更正面的提及,从而提升品牌认知度和可信度。
了解Wikipedia如何影响ChatGPT、Perplexity和Google AI等AI平台的引用。发现Wikipedia为何成为AI训练中最受信任的数据源,以及它如何影响您的品牌曝光度。...

了解如何以合乎道德的方式让您的品牌在维基百科上被引用,从而实现最大的 AI 可见性。战略指南涵盖政策、可靠来源以及面向 ChatGPT、Perplexity 和 Google AI 的引用策略。...
了解维基百科如何成为关键的AI训练数据集,其对模型准确性的影响、许可协议,以及AI公司为何依赖它训练大型语言模型。...
Cookie 同意
我们使用 cookie 来增强您的浏览体验并分析我们的流量。 See our privacy policy.