
Které AI crawlery povolit? Kompletní průvodce pro rok 2025
Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...
10 min čtení

Zjistěte, jak AI crawlery ovlivňují serverové zdroje, šířku pásma a výkon. Objevte reálné statistiky, strategie zmírnění a infrastrukturní řešení pro efektivní správu zátěže botů.
AI crawlery se staly významnou silou v rámci webového provozu, přičemž hlavní AI společnosti nasazují sofistikované roboty k indexaci obsahu pro účely trénování a vyhledávání. Tyto crawlery operují v obrovském měřítku, generují přibližně 569 milionů požadavků měsíčně napříč webem a spotřebovávají více než 30 TB šířky pásma globálně. Mezi hlavní AI crawlery patří GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity AI), Google-Extended (Google) a Amazonbot (Amazon), z nichž každý má odlišné vzory procházení a nároky na zdroje. Porozumění chování a charakteristikám těchto crawlerů je pro správce webů zásadní pro správné řízení serverových zdrojů a informované rozhodování o přístupových politikách.
| Název crawleru | Společnost | Účel | Vzor požadavků |
|---|---|---|---|
| GPTBot | OpenAI | Tréninková data pro ChatGPT a GPT modely | Agresivní, vysoce frekventované požadavky |
| ClaudeBot | Anthropic | Tréninková data pro modely Claude AI | Střední frekvence, šetrné procházení |
| PerplexityBot | Perplexity AI | Reálné vyhledávání a generování odpovědí | Střední až vysoká frekvence |
| Google-Extended | Rozšířená indexace pro AI funkce | Řízené, dodržuje robots.txt | |
| Amazonbot | Amazon | Indexace produktů a obsahu | Proměnlivé, zaměřené na obchod |
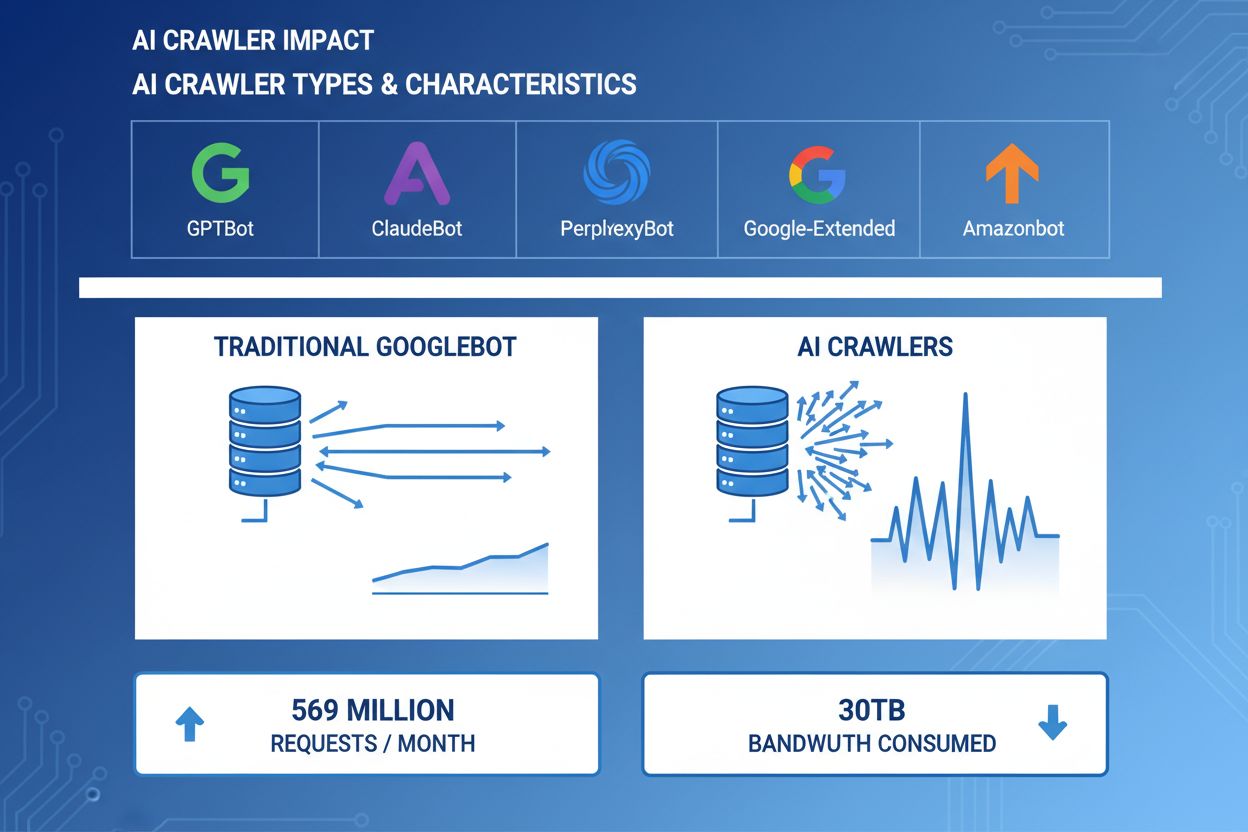
AI crawlery spotřebovávají serverové zdroje v několika rovinách a mají měřitelný dopad na výkon infrastruktury. Využití CPU může při špičkové aktivitě crawlerů vzrůst až o 300 %, protože servery zpracovávají tisíce souběžných požadavků a parsují HTML obsah. Spotřeba šířky pásma patří mezi nejviditelnější náklady – jediný populární web může crawlerům denně poskytnout gigabajty dat. Výrazně stoupá i využití paměti, protože servery udržují pooly spojení a bufferují velké objemy dat ke zpracování. Počet databázových dotazů se násobí, když crawlery žádají stránky generující dynamický obsah, což vytváří další tlak na I/O. Diskové I/O se stává úzkým hrdlem v případech, kdy server musí číst ze storage pro obsluhu crawlerů, zvláště u webů s rozsáhlými knihovnami obsahu.
| Zdroj | Dopad | Reálný příklad |
|---|---|---|
| CPU | Špičky 200–300 % při procházení | Průměrná zátěž serveru stoupne z 2,0 na 8,0 |
| Šířka pásma | 15–40 % celkového měsíčního provozu | 500GB web poskytne crawlerům 150GB/měsíc |
| Paměť | 20–30% nárůst využití RAM | 8GB server potřebuje 10GB při aktivitě crawlerů |
| Databáze | 2–5× vyšší zátěž dotazy | Odezva dotazů vzroste z 50 ms na 250 ms |
| Diskové I/O | Trvale vysoké čtení | Využití disku vyskočí z 30 % na 85 % |
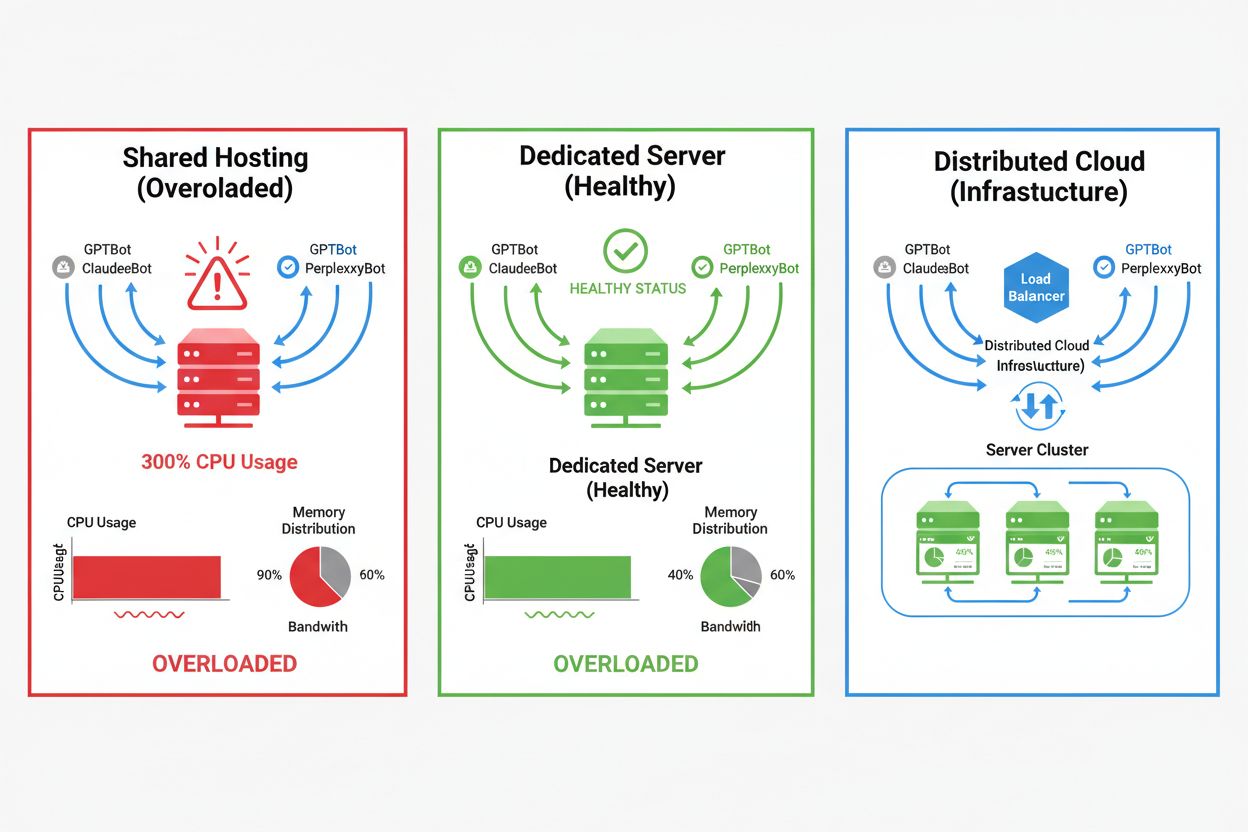
Dopad AI crawlerů se dramaticky liší podle prostředí hostingu, přičemž sdílené hostingy zažívají nejvážnější důsledky. U sdíleného hostingu je zvlášť problematický tzv. „syndrom hlučného souseda“—když jeden web na serveru přitáhne velký provoz crawlerů, spotřebuje zdroje, které by jinak sloužily ostatním stránkám, což zhoršuje výkon pro všechny. Dedikované servery a cloudová infrastruktura poskytují lepší izolaci a záruky zdrojů, což umožňuje absorbovat crawler provoz bez ovlivnění ostatních služeb. I dedikovaná infrastruktura však vyžaduje pečlivé monitorování a škálování, aby zvládla kumulativní zátěž více AI crawlerů současně.
Hlavní rozdíly mezi hostingovými prostředími:
Finanční dopady provozu AI crawlerů přesahují pouhé náklady na šířku pásma a zahrnují přímé i skryté výdaje, které mohou výrazně ovlivnit váš rozpočet. Přímé náklady zahrnují zvýšené účty za šířku pásma od poskytovatele hostingu, které mohou dosáhnout stovek až tisíců dolarů měsíčně v závislosti na objemu provozu a intenzitě crawlerů. Skryté náklady vznikají zvýšenými nároky na infrastrukturu—můžete být nuceni přejít na vyšší hostingové tarify, nasadit další vrstvy cache nebo investovat do CDN služeb čistě kvůli správě crawler provozu. Výpočet návratnosti (ROI) je složitý, protože AI crawlery přinášejí vašemu podnikání jen minimální přímou hodnotu, ale spotřebovávají zdroje, které by mohly sloužit platícím zákazníkům nebo zlepšovat uživatelskou zkušenost. Mnoho vlastníků webů zjišťuje, že náklady na toleranci crawler provozu převyšují jakýkoli možný přínos z AI tréninku či viditelnosti ve výsledcích AI vyhledávání.
Provoz AI crawlerů přímo zhoršuje uživatelskou zkušenost legitimních návštěvníků tím, že spotřebovává serverové zdroje, které by jinak sloužily lidským uživatelům rychleji. Metriky Core Web Vitals se měřitelně zhoršují—Largest Contentful Paint (LCP) se prodlouží o 200–500 ms a Time to First Byte (TTFB) se zhorší o 100–300 ms během období intenzivní aktivity crawlerů. Tyto výkonnostní propady způsobují kaskádové negativní efekty: pomalejší načítání stránek snižuje zapojení uživatelů, zvyšuje míru odchodů a v konečném důsledku snižuje konverzní poměry u e-shopů nebo lead-gen webů. Hodnocení ve vyhledávačích rovněž klesá, protože algoritmus Google bere Core Web Vitals v úvahu jako hodnotící faktor, což vytváří začarovaný kruh, kdy crawler provoz nepřímo poškozuje i vaše SEO. Uživatelé zažívající pomalé načítání mají větší tendenci web opustit a navštívit konkurenci, což přímo ovlivňuje tržby i vnímání značky.
Efektivní řízení provozu AI crawlerů začíná důkladným monitoringem a detekcí, což vám umožní pochopit rozsah problému před zavedením řešení. Většina web serverů zaznamenává user-agent řetězce, které identifikují crawler provádějící každý požadavek, což tvoří základ pro analýzu provozu a rozhodnutí o filtrování. Serverové logy, analytické platformy a specializované monitorovací nástroje dokáží tyto user-agent řetězce parsovat a identifikovat i kvantifikovat vzorce crawler provozu.
Klíčové metody a nástroje detekce:
První linií obrany proti nadměrnému provozu AI crawlerů je dobře nastavený soubor robots.txt, který přímo řídí přístup crawlerů na váš web. Tento jednoduchý textový soubor umístěný v kořenovém adresáři webu vám umožní zakázat konkrétní crawlery, omezit frekvenci procházení a směrovat crawlery na sitemapu obsahující pouze obsah, který chcete indexovat. Rate limiting na aplikační nebo serverové úrovni představuje další ochrannou vrstvu; omezuje počet požadavků z konkrétních IP adres nebo user-agent, aby nedocházelo k vyčerpání zdrojů. Tyto strategie jsou neblokující a vratné, což z nich činí ideální první krok před nasazením razantnějších opatření.
# robots.txt – Blokuje AI crawlery, povoluje legitimní vyhledávače
User-agent: GPTBot
Disallow: /
User-agent: ClaudeBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Amazonbot
Disallow: /
User-agent: CCBot
Disallow: /
# Povol Google a Bing
User-agent: Googlebot
Allow: /
User-agent: Bingbot
Allow: /
# Crawl delay pro ostatní boty
User-agent: *
Crawl-delay: 10
Request-rate: 1/10s
Web Application Firewall (WAF) a Content Delivery Network (CDN) nabízejí sofistikovanou, podnikové úrovně ochranu proti nechtěnému provozu crawlerů pomocí behaviorální analýzy a inteligentního filtrování. Cloudflare a podobní CDN poskytovatelé mají vestavěné bot management funkce, které dokáží identifikovat a blokovat AI crawlery podle vzorců chování, reputace IP a charakteristik požadavků, aniž by bylo třeba ručně nastavovat konfiguraci. Pravidla WAF umožňují vyzvat podezřelé požadavky, omezit rychlost pro specifické user-agenty nebo zcela blokovat provoz z vybraných rozsahů IP crawlerů. Tato řešení fungují na okraji sítě (edge), což znamená, že škodlivý provoz je filtrován dříve, než dorazí k vašemu serveru, a výrazně tak snižuje zátěž infrastruktury. Výhodou WAF a CDN je schopnost adaptovat se na nové crawlery a měnící se vzory útoků bez nutnosti ručních aktualizací konfigurace.
Rozhodnutí, zda AI crawlery blokovat, vyžaduje pečlivé zvážení mezi ochranou serverových zdrojů a zachováním viditelnosti ve výsledcích AI vyhledávání a aplikacích. Blokování všech AI crawlerů znemožní, aby se váš obsah objevil ve výsledcích ChatGPT search, odpovědích Perplexity AI či jiných AI objevovacích mechanismech, a může tak snížit referral traffic i povědomí o značce. Naopak, neomezený přístup crawlerů spotřebuje značné zdroje a může zhoršit uživatelskou zkušenost bez měřitelných přínosů pro vaši firmu. Optimální strategie závisí na konkrétní situaci: vysoce navštěvované weby s dostatkem zdrojů mohou crawlery tolerovat, zatímco weby s omezenými zdroji by měly upřednostnit uživatelský komfort a crawlery blokovat nebo omezit. Strategické rozhodnutí by mělo zohlednit váš obor, cílovou skupinu, typ obsahu i obchodní cíle, namísto univerzálního přístupu.
Weby, které se rozhodnou AI crawler provoz akceptovat, mohou zachovat výkon díky škálování infrastruktury. Vertikální škálování—upgrade serverů s více CPU, RAM a šířkou pásma—je přímé, ale nákladné řešení, které má své fyzické limity. Horizontální škálování—rozdělení provozu mezi více serverů pomocí load balancerů—nabízí lepší dlouhodobou škálovatelnost a odolnost. Cloudové platformy jako AWS, Google Cloud nebo Azure umožňují automatické škálování, které samo přidává zdroje při provozních špičkách a při poklesu provozu je opět snižuje, což minimalizuje náklady. CDN dokáže cachovat statický obsah na edge bodech, čímž snižuje zátěž origin serveru a zlepšuje výkon jak pro lidi, tak pro crawlery. Optimalizace databáze, cache dotazů a vylepšení na úrovni aplikace dále snižují spotřebu zdrojů na jeden požadavek a zvyšují efektivitu bez nutnosti další infrastruktury.
Průběžné monitorování a optimalizace jsou klíčové pro udržení optimálního výkonu při setrvalém provozu AI crawlerů. Specializované nástroje poskytují přehled o aktivitě crawlerů, spotřebě zdrojů a výkonnostních metrikách, což umožňuje rozhodování o strategiích na základě dat. Komplexní monitoring od začátku vám pomůže stanovit výchozí hodnoty, sledovat trendy a vyhodnocovat účinnost zavedených opatření v čase.
Základní nástroje a postupy monitoringu:
Oblast správy AI crawlerů se neustále vyvíjí, přičemž nově vznikající standardy a průmyslové iniciativy formují způsob interakce webů a AI společností. Standard llms.txt představuje nový přístup, jak AI firmám strukturovaně sdělit informace o právech a preferencích využití obsahu, což může nabídnout jemnější alternativu k plošnému blokování nebo povolování. Průmyslové diskuze o modelech kompenzací naznačují, že AI firmy by mohly v budoucnu webům za přístup k trénovacím datům platit, což by zásadně změnilo ekonomiku crawler provozu. Budoucí odolnost infrastruktury vyžaduje sledování nových standardů, průběžné informování o vývoji v oboru a flexibilitu v politice správy crawlerů. Budování vztahů s AI společnostmi, zapojení do diskuzí v oboru a prosazování férových modelů odměn bude stále důležitější, jak se AI stává středobodem webového objevování a konzumace obsahu. Weby, které v tomto měnícím se prostředí uspějí, budou ty, které vyváží inovace s pragmatismem, ochrání své zdroje a zároveň zůstanou otevřené legitimním příležitostem pro zviditelnění a partnerství.
AI crawlery (GPTBot, ClaudeBot) získávají obsah pro trénink LLM bez nutnosti vracet návštěvnost zpět. Vyhledávací crawlery (Googlebot) indexují obsah pro viditelnost ve vyhledávání a obvykle přivádějí referenční návštěvnost. AI crawlery pracují agresivněji s většími dávkami požadavků a často ignorují doporučení na úsporu šířky pásma.
Reálné příklady ukazují přes 30 TB za měsíc od jednoho crawleru. Spotřeba závisí na velikosti webu, objemu obsahu a frekvenci crawleru. Samotný GPTBot od OpenAI vygeneroval 569 milionů požadavků během jednoho měsíce v síti Vercel.
Blokování trénovacích AI crawlerů (GPTBot, ClaudeBot) neovlivní hodnocení ve vyhledávači Google. Blokování AI crawlerů určených pro vyhledávání však může snížit vaši viditelnost ve výsledcích AI vyhledávání jako Perplexity nebo ChatGPT search.
Sledujte nevysvětlitelné špičky CPU (300 % a více), zvýšenou spotřebu šířky pásma bez zvýšeného počtu lidských návštěvníků, pomalejší načítání stránek a neobvyklé user-agent řetězce v serverových logech. Výrazně se mohou zhoršit i metriky Core Web Vitals.
Pro weby s významným provozem crawlerů nabízí dedikovaný hosting lepší izolaci zdrojů, kontrolu a předvídatelnost nákladů. Sdílené hostingové prostředí trpí syndromem hlučného souseda, kdy provoz crawlerů jednoho webu ovlivňuje všechny hostované stránky.
Použijte Google Search Console pro data o Googlebotu, serverové přístupové logy pro detailní analýzu provozu, analytiku CDN (Cloudflare) a specializované platformy jako AmICited.com pro komplexní monitoring a sledování AI crawlerů.
Ano, pomocí direktiv v robots.txt, pravidel WAF a filtrování podle IP adres. Můžete povolit užitečné crawlery typu Googlebot, zatímco náročné trénovací AI crawlery blokovat pomocí pravidel podle user-agent.
Porovnejte serverové metriky před a po zavedení opatření proti crawlerům. Sledujte Core Web Vitals (LCP, TTFB), rychlost načítání stránek, vytížení CPU a metriky uživatelské zkušenosti. Nástroje jako Google PageSpeed Insights a serverové monitorovací platformy poskytují detailní přehled.
Získejte aktuální přehled o tom, jak AI modely přistupují k vašemu obsahu a ovlivňují vaše serverové zdroje pomocí specializované monitorovací platformy AmICited.
Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...

Naučte se, jak strategicky rozhodovat o blokování AI crawlerů. Vyhodnoťte typ obsahu, zdroje návštěvnosti, modely příjmů a konkurenční pozici pomocí našeho komp...

Pochopte, jak fungují AI crawleři jako GPTBot a ClaudeBot, v čem se liší od tradičních crawlerů vyhledávačů a jak optimalizovat svůj web pro viditelnost ve vyhl...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.