Kompletní průvodce blokováním (nebo povolováním) AI crawlerů
Naučte se, jak blokovat nebo povolovat AI crawlery jako GPTBot a ClaudeBot pomocí robots.txt, blokování na úrovni serveru a pokročilých metod ochrany. Kompletní technický průvodce s příklady.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
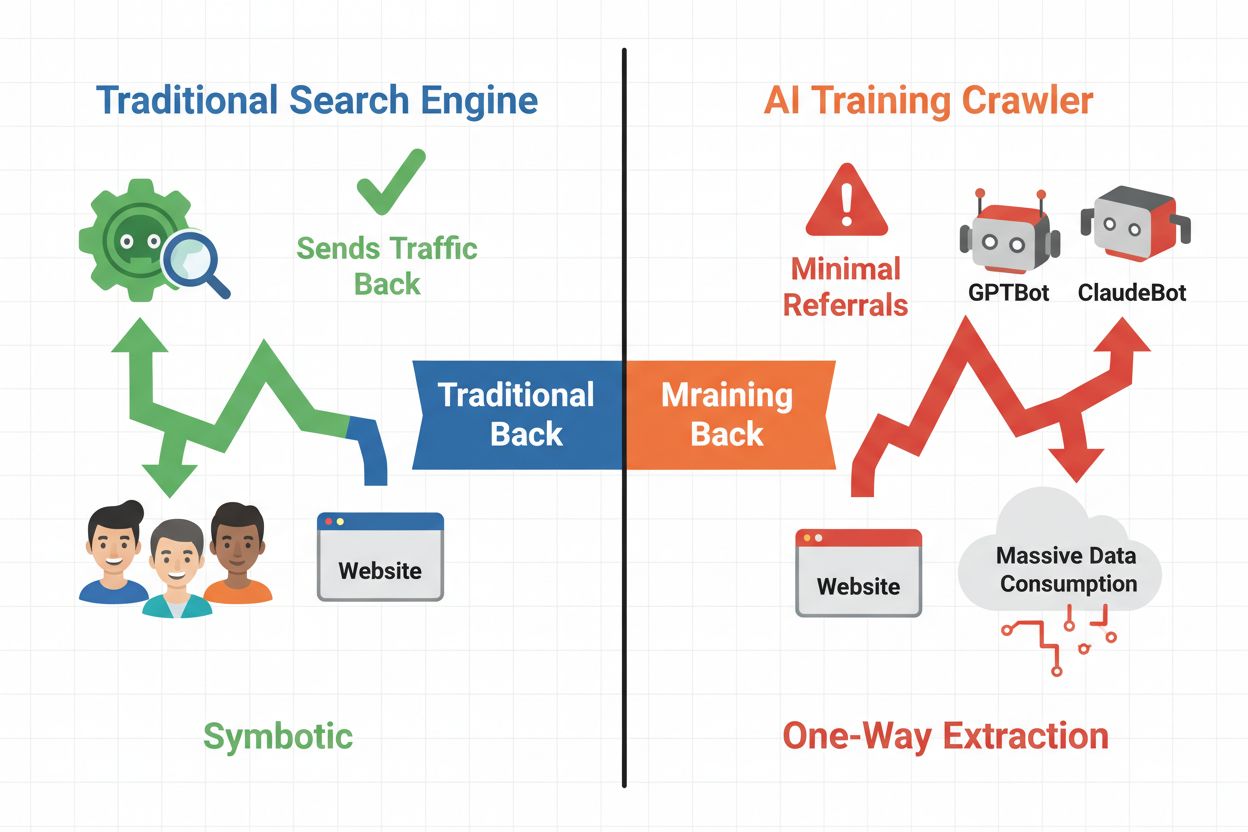
Digitální prostředí se zásadně proměnilo – od tradiční optimalizace pro vyhledávače k řízení zcela nové kategorie automatizovaných návštěvníků: AI crawlerů. Na rozdíl od běžných vyhledávacích botů, kteří přivádějí návštěvníky zpět na váš web přes výsledky vyhledávání, trénovací AI crawlery spotřebovávají váš obsah pro tvorbu velkých jazykových modelů, aniž by vám nutně posílaly referral traffic. Tento rozdíl má zásadní důsledky pro vydavatele, tvůrce obsahu i firmy, které jsou na návštěvnosti webu závislé jako na zdroji příjmů. Hraje se o hodně — kontrola nad tím, jaké AI systémy mají přístup k vašemu obsahu, přímo ovlivňuje vaši konkurenční výhodu, ochranu dat a výsledné hospodaření.
Typy AI crawlerů
AI crawlery lze rozdělit do tří hlavních kategorií, z nichž každá má jiný účel a jiný dopad na návštěvnost. Trénovací crawlery využívají AI společnosti k tvorbě a vylepšování jazykových modelů, typicky pracují ve velkém měřítku a vrací minimální návštěvnost. Vyhledávací a citační crawlery indexují obsah pro vyhledávače poháněné AI a citační systémy, často generují nějaký referral traffic zpět vydavatelům. Crawlery vyvolané uživatelem získávají obsah na vyžádání při interakci uživatelů s AI aplikacemi – tvoří menší, ale rostoucí segment. Porozumění těmto kategoriím vám pomůže rozhodnout, které crawlery podle svého byznys modelu povolit či blokovat.
Ekosystém AI crawlerů zahrnuje crawlery největších technologických společností, každý s vlastním user agentem a účelem. OpenAI má GPTBot (user agent: GPTBot/1.0), který crawlí pro trénování ChatGPT a dalších modelů, zatímco ClaudeBot od Anthropicu (user agent: Claude-Web/1.0) slouží obdobně pro Claude. Googlebot-Extended od Googlu (user agent: Mozilla/5.0 ... Googlebot-Extended) indexuje obsah pro AI Overviews a Bard, zatímco Meta-ExternalFetcher crawlí pro AI iniciativy Meta. Dalšími významnými hráči jsou:
Bytespider (ByteDance) – Jeden z nejagresivnějších crawlerů, využíván pro trénink čínských AI modelů
Amazonbot (Amazon) – Crawlí pro Alexa a AI služby AWS
Applebot-Extended (Apple) – Indexuje obsah pro Siri a Apple Intelligence funkce
Perplexity Bot – Crawlí pro jejich AI vyhledávač (známý tím, že robots.txt často ignoruje)
CCBot (Common Crawl) – Tvoří otevřené datasety využívané mnoha AI společnostmi
Každý crawler operuje v jiném měřítku a různě respektuje blokovací direktivy.
Jak blokovat AI crawlery pomocí robots.txt
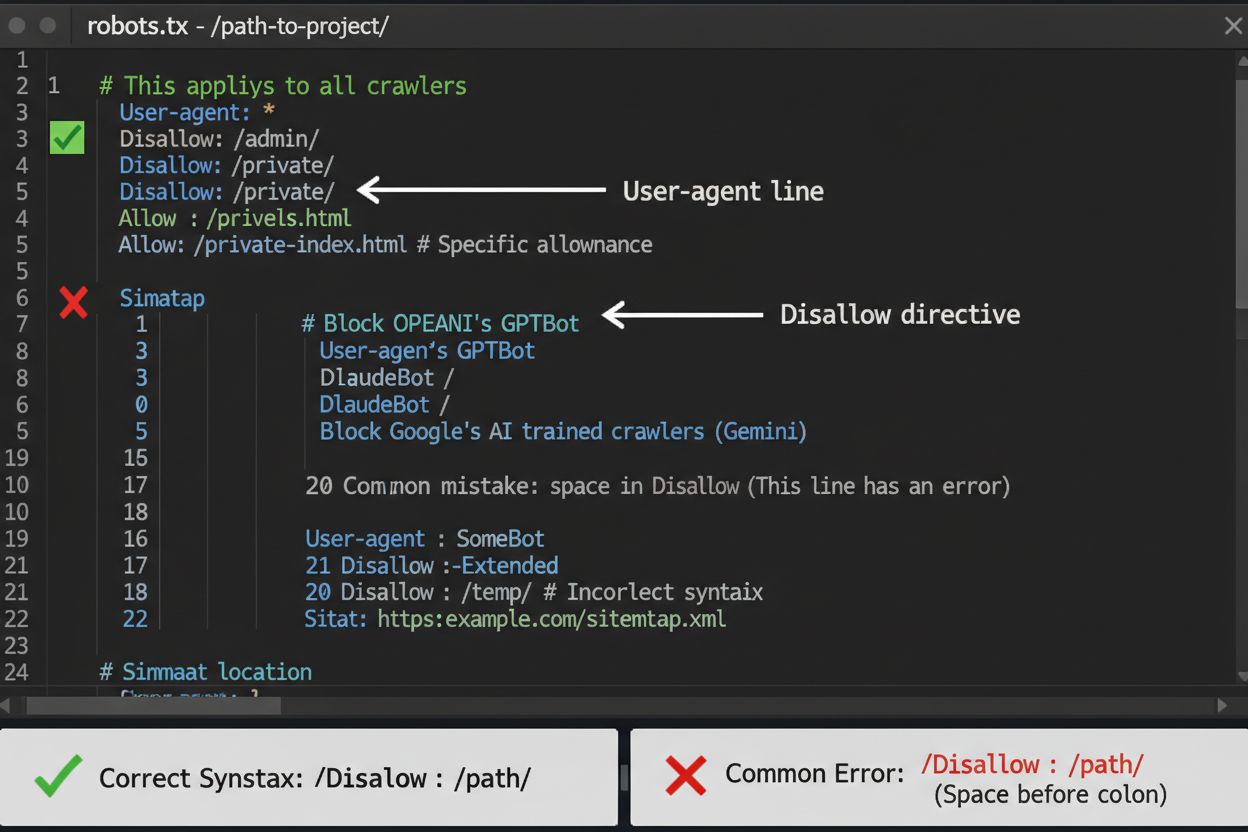
robots.txt je vaší první obrannou linií v kontrole přístupu AI crawlerů, je však důležité vědět, že jde pouze o doporučení, nikoli právně vymahatelné pravidlo. Tento soubor umístěný v kořenovém adresáři vaší domény (např. vasedomena.cz/robots.txt) používá jednoduchou syntaxi pro zadání oblastí, které mají crawlery vynechat. Pro kompletní blokování všech AI crawlerů přidejte následující pravidla:
Častou chybou je použití příliš obecného pravidla jako Disallow: *, což může zmást některé parsery, nebo zapomenutí na individualizaci pravidel při blokování jen konkrétních crawlerů. Velké společnosti jako OpenAI, Anthropic a Google obecně robots.txt respektují, některé crawlery (například Perplexity) však byly zdokumentovány, že pravidla ignorují.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Nad rámec robots.txt – silnější ochranné metody
Pokud robots.txt nestačí, existuje několik silnějších způsobů, jak kontrolovat přístup AI crawlerů. Blokování podle IP adres znamená identifikovat IP rozsahy AI crawlerů a blokovat je na úrovni firewallu nebo serveru — je to vysoce efektivní, ale vyžaduje průběžnou údržbu, protože IP rozsahy se mění. Blokování na úrovni serveru přes soubory .htaccess (Apache) nebo konfiguraci Nginx dává detailnější kontrolu a je obtížněji obejitelné než robots.txt. Pro Apache servery použijte toto pravidlo:
Blokování pomocí meta tagů jako <meta name="robots" content="noindex, noimageindex, nofollowbydefault"> zabrání indexaci, ale nezastaví trénovací crawlery. Ověření request headerů znamená kontrolovat, zda crawlery skutečně pocházejí z deklarovaných zdrojů pomocí reverzního DNS a SSL certifikátů. Pokud potřebujete naprostou jistotu, že crawlery se k obsahu nedostanou, použijte blokování na úrovni serveru a kombinujte více metod pro maximální ochranu.
Strategické rozhodnutí – blokovat nebo povolit
Rozhodnutí, zda AI crawlery zablokovat, závisí na zvážení několika protichůdných zájmů. Blokování trénovacích crawlerů (GPTBot, ClaudeBot, Bytespider) zabrání použití vašeho obsahu pro trénink AI modelů a chrání vaše duševní vlastnictví i konkurenční výhodu. Povolení vyhledávacích crawlerů (Googlebot-Extended, Perplexity) však může přivést referral traffic a zvýšit vaši viditelnost ve výsledcích AI vyhledávání – což je stále významnější kanál objevování obsahu. Komplikací je, že některé AI společnosti mají velmi špatný poměr crawlů k referralům: crawler Anthropicu generuje přibližně 38 000 crawlů na jeden referral, OpenAI asi 400:1. Zátěž serveru a šířka pásma jsou dalším faktorem — AI crawlery spotřebovávají významné zdroje a jejich blokací můžete snížit náklady na infrastrukturu. Rozhodnutí slaďte se svým byznys modelem: zpravodajské weby a vydavatelé mohou profitovat z referral trafficu, SaaS firmy a tvůrci vlastního obsahu často preferují blokování.
Monitoring a ověření
Zavedení blokace crawlerů je jen polovina úspěchu — je třeba ověřit, že crawlery vaše direktivy skutečně respektují. Analýza serverových logů je klíčovým nástrojem: prohlédněte si access logy a hledejte user agent řetězce a IP adresy crawlerů, kteří se po zablokování snaží dostat na váš web. Prohledávejte logy například tímto příkazem:
Tento příkaz spočítá, kolikrát se zmíněné crawlery pokusily přistoupit na váš web. Testovací nástroje jako curl umožní simulovat požadavky crawlerů a ověřit, že blokování funguje správně:
curl -A "GPTBot/1.0" https://vasedomena.cz/robots.txt
První měsíc po zavedení blokování sledujte logy každý týden, poté čtvrtletně. Pokud zjistíte, že crawlery robots.txt ignorují, přejděte na blokování na úrovni serveru nebo kontaktujte abuse tým provozovatele crawleru.
Udržování aktuálního seznamu blokovaných crawlerů
Ekosystém AI crawlerů se rychle vyvíjí – nové firmy spouštějí AI produkty a stávající crawlery mění své user agenty či IP rozsahy. Čtvrtletní kontrola vašeho seznamu blokovaných crawlerů zajistí, že vám neuniknou nové crawlery nebo omylem neblokujete legitimní provoz. Ekosystém je roztříštěný a decentralizovaný, proto nelze vytvořit trvale platný seznam. Sledujte tyto zdroje:
Oficiální dokumentaci OpenAI pro změny GPTBotu
Veřejná prohlášení Anthropicu o chování ClaudeBotu
Fóra komunity a diskuse na Redditu, kde vývojáři sdílejí nově objevené crawlery
Vlastní serverové logy kvůli neznámým user agentům, které mohou být novými AI crawlery
Odborné weby a bezpečnostní blogy, které sledují aktivity nových AI crawlerů
Nastavte si upomínky na kontrolu robots.txt a serverových pravidel každých 90 dní a přihlaste se k odběru bezpečnostních mailing listů, které informují o nových crawlerech.
Jak AmICited pomáhá sledovat AI citace
Blokováním AI crawlerů jim sice zabráníte v přístupu k vašemu obsahu, AmICited ale řeší doplňkovou výzvu: monitoruje, zda a jak AI systémy citují a zmiňují vaši značku a obsah ve svých výstupech. AmICited sleduje zmínky o vaší organizaci v AI generovaných odpovědích, poskytuje přehled o tom, jak váš obsah ovlivňuje výstupy AI modelů a kde se vaše značka objevuje ve výsledcích AI vyhledávání. Tím získáte komplexní AI strategii: přístup crawlerů řídíte přes robots.txt a blokování na serveru, AmICited vám umožní pochopit skutečný dopad vašeho obsahu na AI systémy. Kombinací těchto nástrojů získáte úplný přehled a kontrolu nad vaší přítomností v AI ekosystému — od zabránění nechtěnému využití vašich dat pro trénink až po měření skutečných citací a zmínek vašeho obsahu na AI platformách.
Často kladené otázky
Ovlivňuje blokování AI botů mé SEO pozice?
Ne. Blokování trénovacích AI crawlerů jako GPTBot, ClaudeBot a Bytespider nemá vliv na vaše pozice ve vyhledávačích Google nebo Bing. Tradiční vyhledávače používají jiné crawlery (Googlebot, Bingbot), které fungují nezávisle. Tyto blokujte pouze, pokud se chcete zcela ztratit z výsledků vyhledávání.
Kteří AI boti skutečně respektují robots.txt?
Hlavní crawlery od OpenAI (GPTBot), Anthropic (ClaudeBot), Google (Google-Extended) a Perplexity (PerplexityBot) oficiálně uvádějí, že respektují direktivy robots.txt. Menší nebo méně transparentní boti však mohou vaše nastavení ignorovat, což je důvod, proč existují vícestupňové strategie ochrany.
Mám blokovat všechny AI crawlery, nebo jen trénovací boty?
Záleží na vaší strategii. Blokování pouze trénovacích crawlerů (GPTBot, ClaudeBot, Bytespider) chrání váš obsah před použitím pro trénink modelů a zároveň umožňuje vyhledávacím crawlerům, aby vás zobrazovali ve výsledcích AI vyhledávání. Úplné blokování vás z AI ekosystémů zcela odstraní.
Jak často mám aktualizovat svůj robots.txt kvůli novým AI botům?
Minimálně jednou za čtvrtletí zkontrolujte své nastavení. AI společnosti pravidelně zavádějí nové crawlery. Anthropic například sloučil své boty 'anthropic-ai' a 'Claude-Web' do 'ClaudeBot', což novému botu dočasně umožnilo neomezený přístup na stránky, které neaktualizovaly svá pravidla.
Jaký je rozdíl mezi blokováním a povolováním AI crawlerů?
Blokování zcela zabrání crawlerům v přístupu k vašemu obsahu a chrání jej před sběrem dat pro trénink nebo indexaci. Povolování crawlerům umožňuje přístup, ale může vést k tomu, že váš obsah bude použit pro trénink modelů nebo se objeví ve výsledcích AI vyhledávání s minimálním referral trafficem.
Mohou AI crawlery obejít direktivy robots.txt?
Ano, robots.txt je pouze doporučení a není právně vymahatelné. Dobře se chovající crawlery od velkých společností obvykle robots.txt respektují, ale některé jej ignorují. Pro silnější ochranu použijte blokování na úrovni serveru pomocí .htaccess nebo firewallových pravidel.
Jak zjistím, že můj robots.txt funguje?
Zkontrolujte serverové logy podle user agent řetězců blokovaných crawlerů. Pokud vidíte požadavky od crawlerů, které jste zablokovali, možná vaše robots.txt nerespektují. Použijte testovací nástroje jako robots.txt tester v Google Search Console nebo příkaz curl pro ověření nastavení.
Jaký bude dopad na návštěvnost webu, pokud zablokuji AI crawlery?
Blokování trénovacích crawlerů má obvykle minimální přímý dopad na návštěvnost, protože stejně neposílají téměř žádný referral traffic. Blokování vyhledávacích crawlerů však může snížit vaši viditelnost na AI vyhledávacích platformách. Sledujte své statistiky po dobu 30 dnů po zavedení blokování, abyste změřili skutečný dopad.
Sledujte, jak AI systémy zmiňují vaši značku
I když přístup crawlerů řídíte pomocí robots.txt, AmICited vám pomůže sledovat, jak AI systémy citují a odkazují na váš obsah napříč svými výstupy. Získejte úplný přehled o vaší přítomnosti v AI.
Jak identifikovat AI crawlery v serverových logách: Kompletní průvodce detekcí
Naučte se, jak identifikovat a monitorovat AI crawlery jako GPTBot, PerplexityBot a ClaudeBot ve vašich serverových logách. Objevte user-agent řetězce, metody o...
Které AI crawlery povolit? Kompletní průvodce pro rok 2025
Zjistěte, které AI crawlery povolit nebo blokovat ve vašem robots.txt. Komplexní průvodce zahrnující GPTBot, ClaudeBot, PerplexityBot a 25+ AI crawlerů s ukázka...
Audit přístupu AI crawlerů: Vidí správné boty váš obsah?
Zjistěte, jak provést audit přístupu AI crawlerů na váš web. Zjistěte, které boty vidí váš obsah a opravte blokace, které brání AI viditelnosti v ChatGPT, Perpl...
7 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.