Listikly a AI: Proč jsou číslované seznamy často citovány
Zjistěte, proč AI modely preferují listikly a číslované seznamy. Naučte se, jak optimalizovat obsah založený na seznamech pro citace od ChatGPT, Gemini a Perplexity pomocí ověřených strategií.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
AI modely jsou v jádru stroje na rozpoznávání vzorů, které vynikají v identifikaci a zpracování informací organizovaných v předvídatelných, opakovatelných formátech. Když je obsah strukturován jako listikl, poskytuje přehledný, hierarchický formát, který LLM dokáže analyzovat výrazně efektivněji než narativní text. Strukturovaný obsah snižuje výpočetní složitost, kterou jazykové modely potřebují k extrakci, pochopení a citaci konkrétních informací, protože každá položka seznamu funguje jako samostatná sémantická jednotka. Proces parsování LLM je jednodušší při setkání s číslovanými nebo odrážkovými seznamy, protože model nemusí domýšlet vztahy mezi koncepty—ty jsou jasně určeny strukturou seznamu. Tato efektivita se přímo promítá do vyšších mír citací, protože AI systémy mohou s větší jistotou extrahovat a odkazovat na jednotlivé položky seznamu bez nutnosti rozsáhlého kontextu z okolních odstavců. Předvídatelná povaha formátů listiklů v AI znamená, že modely stráví méně tokenů zpracováním strukturální nejednoznačnosti a více tokenů skutečným pochopením obsahu. V podstatě, když informace prezentujete jako číslovaný seznam, mluvíte „mateřským jazykem“ velkých jazykových modelů.
Jak různé AI platformy citují seznamy
Různé AI platformy vykazují odlišné preference v citacích, které ukazují, jak systémy číslovaných seznamů LLM upřednostňují objevování a ověřování obsahu. ChatGPT vykazuje silnou preferenci pro encyklopedický obsah, kdy 47,9 % jeho citací pochází z Wikipedie—platformy, která silně spoléhá na strukturovanou, na seznamech založenou informační architekturu. Gemini vykazuje vyváženější zdroje, cituje blogy ze 39 % a zpravodajské zdroje z 26 %, což naznačuje preferenci pro listikly AI, které spojují autoritativní strukturu s aktuálními poznatky. Perplexity AI, navržený speciálně pro dotazy orientované na výzkum, cituje blogový obsah ze 38 % a zpravodajství z 23 %, což jasně ukazuje preferenci pro odborné seznamy kombinující hloubku s přístupností. Google AI Overviews preferuje blogové články ze 46 %, zejména ty, které používají přehledné, na seznamech založené formáty, které odpovídají důrazu platformy na rychlé získání informací. Tyto vzorce AI citací ukazují, že platformy důsledně odměňují tvůrce obsahu, kteří strukturovaně prezentují informace ve formátu seznamu pro AI místo hustých narativních odstavců. Porozumění těmto preferencím jednotlivých platforem umožňuje obsahovým stratégům přizpůsobit formát listiklů a maximalizovat viditelnost napříč více AI systémy současně.
AI Platforma
Primární zdroj citací
Procento
Preference obsahu
ChatGPT
Wikipedia
47,9 %
Encyklopedické, strukturované seznamy
Gemini
Blogy
39 %
Vyvážené listikly s poznatky
Perplexity
Blogy
38 %
Odborné seznamy s hloubkou
Google AI Overviews
Blogové články
46 %
Přehledné, na seznamu založené formáty
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Technickým základem, proč si seznamy vedou v AI systémech tak dobře, je sémantické dělení a vektorové embeddingy—matematické reprezentace umožňující jazykovým modelům porozumět významu. Když je obsah organizován jako seznam, každá položka vytváří jasné sémantické hranice, díky nimž může embeddingová vrstva modelu snáze rozlišit jednotlivé koncepty a myšlenky. Číslované sekvence signalizují hierarchii a důležitost AI systémům způsobem, který narativní text nedokáže, což umožňuje modelům pochopit, že položka č. 1 se zásadně liší od položky č. 5 z hlediska pořadí nebo významu. Implementace schéma markup—zejména strukturovaných dat HowTo a FAQ—zesiluje dohledatelnost díky explicitním metadatům, která AI crawlery a indexovací systémy okamžitě rozpoznají a upřednostní. Optimalizace formátu seznamu pro AI zahrnuje také signály aktuálnosti, kdy pravidelně aktualizované listikly vysílají silnější signály čerstvosti algoritmům vyhledávání než statický narativní obsah. Vektorové databáze používané moderními LLM dokážou efektivněji ukládat a vyhledávat obsah založený na seznamu, protože sémantická vzdálenost mezi položkami seznamu je konzistentnější a předvídatelnější než mezi odstavci plynulé prózy. Tato technická výhoda se v čase sčítá, protože AI systémy se učí více vážit zdroje založené na seznamech ve svých trénovacích datech a vyhledávacích procesech.
Listikly vs. narativní obsah – srovnání citací
Výzkumy opakovaně dokazují, že formáty listiklů v AI získávají o 20–30 % více citací od AI systémů v porovnání se stejnými informacemi prezentovanými v narativní podobě. Tato výhoda v citacích vyplývá ze zásadního rozdílu ve způsobu, jakým AI systémy musí zpracovávat a extrahovat informace z každého formátu: narativní obsah vyžaduje, aby model prováděl složité extrakce kontextu a dedukce k identifikaci citovatelných tvrzení, zatímco seznamy prezentují informace jako předpřipravené, samostatné jednotky. Systémy číslovaných seznamů LLM mohou citovat konkrétní položky seznamu bez nutnosti rozsáhlého okolního kontextu, což činí proces citace rychlejším a jistějším pro AI model. Faktor znovupoužitelnosti je klíčový—když AI systém narazí na dobře strukturovaný listikl, může jednotlivé položky extrahovat a citovat samostatně, zatímco narativní obsah často vyžaduje citaci celých odstavců či sekcí kvůli zachování kontextu. Data z několika AI monitorovacích platforem ukazují, že listikly konzistentně překonávají narativní obsah v četnosti citací, pozici v AI odpovědích i pravděpodobnosti být vybrány jako primární zdroj. Tento rozdíl se ještě zvětšuje při srovnání listiklů s dlouhými narativními texty, protože kognitivní náročnost pro AI systémy při analýze a citaci husté prózy roste exponenciálně. Pro tvůrce obsahu zaměřené na viditelnost listiklů v AI je důkaz jasný: struktura vítězí nad narativem vždy.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
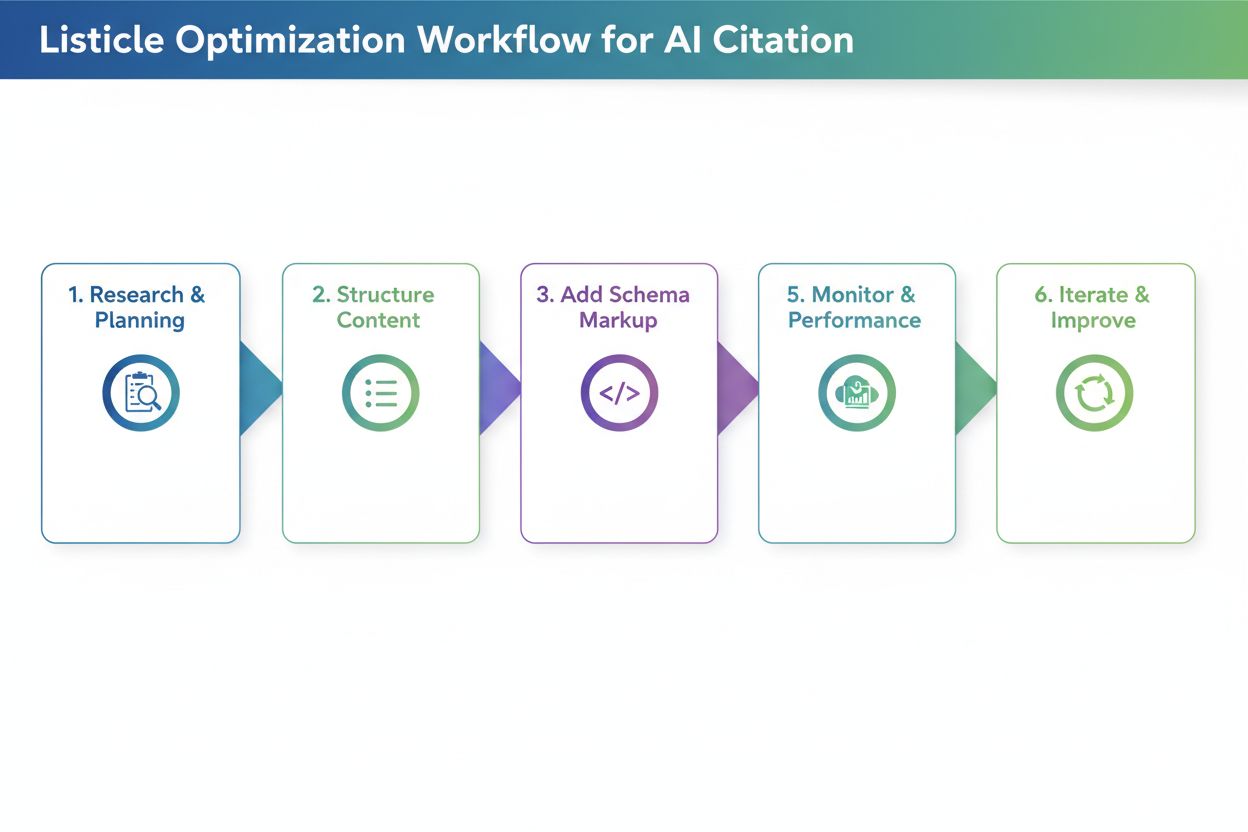
Osvedčené postupy pro AI-optimalizované listikly
Vytváření listiklů maximalizujících AI citace vyžaduje pozornost konkrétním strukturálním a formátovacím prvkům:
Používejte jasnou H2/H3 hierarchii pro vyjádření sémantických vztahů a usnadnění AI orientace v organizaci obsahu
Začněte přímou odpovědí podle principu BLUF (Bottom Line Up Front)—uvedení hlavní myšlenky hned na začátku
Vkládejte srovnávací tabulky v HTML formátu (nikdy jako obrázky), abyste poskytli strukturovaná data, která AI dokáže analyzovat a citovat
Přidejte schéma markup pomocí FAQ a HowTo strukturovaných dat k jasné signalizaci typu a struktury obsahu AI crawlerům
Udržujte vyváženou hloubku položek—vyhněte se situaci, kdy jedna položka má 500 slov a jiné jen 50, protože nekonzistence mate AI při analýze
Používejte číslované seznamy pro sekvenční nebo hodnocený obsah, kde záleží na pořadí (Top 10, návody krok za krokem, žebříčková porovnání)
Používejte odrážky pro seznamy vlastností a neseřazené informace, kde pořadí není podstatné
Aktualizujte čtvrtletně pro čerstvost—AI systémy upřednostňují nedávno aktualizovaný obsah ve formátu seznamu pro AI při citacích
Reálné příklady listiklů citovaných AI
Praktické příklady dokládají sílu správně vytvořených listiklů při získávání AI citací napříč platformami. Listikly typu „Top 5 AML Compliance Tools“ se pravidelně objevují v odpovědích Perplexity AI, přičemž jednotlivé nástroje jsou citovány jako autoritativní doporučení u dotazů týkajících se compliance. Seznamy „Nejlepší alternativy CRM“ dominují odpovědím ChatGPT, zejména když uživatelé žádají srovnání softwaru, přičemž struktura listiklu umožňuje AI s jistotou citovat konkrétní alternativy. Srovnávací produktové listikly se staly dominantním formátem v Google AI Overviews, kde přehledná struktura dokonale ladí s důrazem platformy na rychlé a akční informace. Výzkum a data z MADX a Omnius ukazují, že weby publikující dobře strukturované listikly zaznamenaly nárůst citací o 40–60 % během 90 dnů od zveřejnění. Analýza Tatarek zaměřená na výkon číslovaných seznamů LLM ukázala, že listikly zaměřené na „best of“ kategorie získávají 3,2× více citací než narativní recenze stejných produktů. Tyto reálné příklady potvrzují, že listikly AI nejsou jen teoreticky nadřazené—přinášejí měřitelné, kvantifikovatelné zlepšení AI viditelnosti a četnosti citací.
Jak strukturovat seznamy pro maximální AI viditelnost
Maximalizace viditelnosti v AI vyžaduje promyšlený strukturální přístup, který přesahuje pouhé číslování položek. Začněte sekcí TL;DR v horní části, která shrnuje celý seznam ve 2–3 větách, což AI systémům umožní okamžitě pochopit účel a rozsah obsahu. Zařaďte sekci vysvětlení kritérií, kde jasně uvedete, proč jste vybrali právě tyto položky—tato transparentnost pomáhá AI pochopit vaši metodologii a zvyšuje důvěru v citace. Zajistěte vyvážené pokrytí každé položky seznamu, aby každá položka dostala přiměřenou hloubku a analýzu místo upřednostňování některých položek s přemírou detailů. Kriticky u každé položky uveďte jak silné stránky, tak i omezení, protože AI systémy uznávají a odměňují vyvážené, nuancované analýzy před jednostranně propagačním obsahem. Pokud je to vhodné, přidejte sekci cenového rozpisu, protože tento strukturovaný údaj je velmi snadno citovatelný a často se objevuje v AI odpovědích na srovnání produktů. Implementujte srovnávací tabulku v HTML formátu (ne jako screenshoty nebo obrázky), která AI systémům umožní přímo analyzovat a citovat konkrétní porovnání vlastností. Přidejte sekci FAQ s odpověďmi na časté otázky týkající se položek seznamu, což poskytne další strukturovaná data pro indexaci a citace AI systémů. Nakonec nabídněte jasné další kroky a CTA, které uživatele směřují k akci a signalizují AI systémům, že váš obsah je komplexní a akční.
Role číslovaných seznamů vs. odrážek v AI citacích
Volba mezi číslovanými seznamy a odrážkami má zásadní dopad na to, jak AI systémy zpracovávají a citují váš obsah. Číslované seznamy signalizují pořadí a hodnocení, což je důvod, proč dominují listiklům typu „Top X“ a návodům krok za krokem—AI systémy vnímají číslování jako explicitní hierarchii vyjadřující důležitost nebo pořadí. Odrážky jsou lepší pro neseřazené informace, jako jsou seznamy vlastností nebo srovnání atributů, kde neexistuje žádné inherentní pořadí. Výzkum ukazuje, že AI systémy považují číslované seznamy za autoritativnější a snadněji citovatelné, zejména jako odpověď na dotazy, které výslovně žádají o seřazené nebo sekvenční informace. Když uživatelé ChatGPT nebo Gemini ptají „Jaké jsou top 5 nástrojů pro X?“, AI systém preferenčně cituje zdroje číslovaných seznamů LLM, protože číslování poskytuje explicitní ověření pořadí. Naproti tomu odrážky vynikají u srovnání vlastností, kde AI systémy potřebují extrahovat a citovat konkrétní atributy bez implikace hierarchie. Míchání číslovaných seznamů a odrážek v jednom listiklu vytváří pro AI systémy zmatek při analýze, proto zachovávejte konzistentní formátování obsahu pro maximální optimalizaci formátu seznamu pro AI.
Měření výkonu listiklů v AI vyhledávání
Sledování výkonu listiklů vyžaduje systematické monitorování napříč více AI platformami a nástroji. AtomicAGI, Writesonic a tracking v Perplexity poskytují automatizované sledování, jak často se váš obsah listiklů v AI objevuje v AI generovaných odpovědích. Ruční testování napříč ChatGPT, Gemini a Perplexity zůstává nezbytné, protože automatizované nástroje někdy přehlížejí nuanční vzorce citací nebo chování specifické pro platformu. Stanovte základní metriky sledováním četnosti a pozice citací—nejen zda je váš listikl citován, ale kde se v AI odpovědi objevuje a jak často je vybrán jako hlavní zdroj. Sledujte, které položky seznamu jsou nejčastěji citovány, což odhalí, které konkrétní doporučení nebo postřehy nejvíce rezonují s AI systémy i uživatelskými dotazy. Měřte návštěvnost z AI zdrojů odděleně od tradiční vyhledávací návštěvnosti, protože návštěvy z AI často vykazují jiné konverzní vzorce a uživatelské záměry než organické vyhledávání. Porovnávejte výkon před a po optimalizaci, zavádějte vždy jednu strukturální změnu, abyste zjistili, která konkrétní vylepšení přinášejí nárůst citací. Zaveďte měsíční sledovací cyklus k identifikaci trendů a sezónních vzorců ve výkonu vašeho obsahu číslovaných seznamů LLM napříč různými AI platformami a typy dotazů.
Běžné chyby v listiklech, které škodí AI viditelnosti
I dobře míněné listikly nemusí dosáhnout optimální AI citace, pokud obsahují strukturální nebo obsahové chyby, které matou AI parsovací systémy. Tendenční seznamy upřednostňující váš produkt nebo službu před konkurencí signalizují AI systémům nízkou důvěryhodnost, jež čím dál více penalizují zjevně propagační obsah ve prospěch vyvážených doporučení. Nekonzistentní hloubka položek—když některé položky mají 200 slov analýzy a jiné jen 50—vytváří zmatek při analýze a naznačuje AI systémům neúplný výzkum. Chybějící srovnávací tabulky znamenají významně promarněnou příležitost, protože AI systémy výrazně více váží strukturovaná data a citují raději z tabulek než z popisného textu. Absence schéma markup znamená, že AI systémy musí strukturu obsahu odvozovat místo explicitního určení, což snižuje důvěru v citaci i dohledatelnost. Zastaralé informace jsou pro listikly obzvlášť škodlivé, protože AI systémy rozpoznávají a penalizují zastaralý obsah, zejména v rychle se měnících kategoriích jako jsou softwarové nástroje nebo compliance požadavky. Špatná struktura a hierarchie s nejasnou H2/H3 strukturou ztěžuje AI systémům orientaci v sémantických vztazích mezi položkami. Nakonec přeplnění klíčovými slovy a příliš dlouhé seznamy (50+ položek) snižují autoritu a zaměření listiklu, takže AI systémy jej považují za méně autoritativní než zaměřené, pečlivě vybrané alternativy.
Často kladené otázky
Proč AI modely preferují listikly před narativním obsahem?
AI modely jsou stroje na rozpoznávání vzorů, které zpracovávají strukturované, snadno prohledatelné formáty efektivněji než hustou narativní prózu. Listikly snižují výpočetní složitost tím, že prezentují informace jako oddělené sémantické jednotky, což umožňuje LLM analyzovat, extrahovat a citovat konkrétní položky s větší jistotou a rychlostí.
Jaký je rozdíl mezi číslovanými seznamy a odrážkami pro citování AI?
Číslované seznamy signalizují pořadí a hodnocení, což je činí ideálními pro 'Top X' listikly a návody krok za krokem. Odrážky jsou lepší pro neseřazené informace, jako jsou porovnání vlastností. AI systémy považují číslované seznamy za autoritativnější pro dotazy zaměřené na pořadí, zatímco odrážky vynikají v kontextu srovnání vlastností.
Jak často bych měl aktualizovat své listikly kvůli viditelnosti v AI?
Aktualizujte své listikly minimálně čtvrtletně, abyste udrželi silný signál aktuálnosti. AI systémy upřednostňují nedávno aktualizovaný obsah při citacích. I malé aktualizace—přidání nových údajů, osvěžení statistik nebo rozšíření sekcí—pomáhají udržet nárok na citaci a viditelnost.
Opravdu schéma markup zlepšuje AI citace?
Ano, schéma markup významně zvyšuje dohledatelnost v AI. Strukturovaná data FAQ a HowTo mohou zvýšit pravděpodobnost citace až o 10 %. Schéma markup poskytuje explicitní metadata, která AI crawlery okamžitě rozpoznají a upřednostní, což usnadňuje indexaci a citaci vašeho obsahu.
Mohu používat listikly pro všechny typy obsahu?
Listikly fungují výjimečně dobře pro srovnání, žebříčky, návody a doporučení. Pro narativní vyprávění, hluboké analýzy nebo konceptuální vysvětlení jsou však méně vhodné. Volte formát listiklu, pokud se váš obsah přirozeně rozpadá na jednotlivé, srovnatelné položky.
Jak mohu měřit, zda jsou mé listikly citovány AI?
Použijte nástroje jako AtomicAGI, Writesonic nebo Perplexity tracking pro automatizované monitorování. Ručně testujte relevantní dotazy napříč ChatGPT, Gemini a Perplexity, abyste sledovali frekvenci a pozici citací. Sledujte, které konkrétní položky seznamu jsou nejčastěji citovány a měřte návštěvnost z AI zdrojů odděleně od organického vyhledávání.
Jaká je ideální délka listiklu pro získání AI citací?
Kvalita je důležitější než kvantita. Zaměřte se na 5–10 dobře prozkoumaných položek místo 50+. Každá položka by měla mít vyvářenou, přiměřenou hloubku (150–300 slov). Příliš dlouhé seznamy snižují autoritu a matou AI při analýze, zatímco zaměřené, kurátorsky sestavené listikly mají výrazně lepší výsledky.
Mám do srovnávacích listiklů zařadit i svůj vlastní produkt?
Ano, ale zachovejte transparentnost a vyváženost. Uveďte svůj produkt spolu s konkurenty, poskytněte upřímné silné stránky i omezení a zajistěte stejnou hloubku pokrytí. Tendenční seznamy upřednostňující váš produkt signalizují nízkou důvěryhodnost AI systémům, které čím dál více penalizují zjevně reklamní obsah.
Monitorujte viditelnost své značky v AI
Sledujte, jak často je váš obsah citován ChatGPT, Gemini a Perplexity pomocí AI monitorovací platformy AmICited. Získejte okamžitý přehled o své přítomnosti ve vyhledávání AI.
Preferují AI vyhledávače seznamové články? Kompletní průvodce AI-optimalizovaným obsahem
Zjistěte, zda AI vyhledávače jako ChatGPT a Perplexity preferují seznamové články. Naučte se, jak optimalizovat obsah v podobě seznamů pro AI citace a viditelno...
Zjistěte, co je optimalizace listiklů a jak strukturovat číslované a odrážkové seznamy pro AI extrakci. Objevte osvědčené postupy pro zvýšení viditelnosti ve vý...
Testování formátů obsahu pro AI citace: Návrh experimentu
Zjistěte, jak testovat formáty obsahu pro AI citace pomocí metodologie A/B testování. Objevte, které formáty přinášejí nejvyšší viditelnost a míru citací v Chat...
10 min čtení
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.