Schema Markup pro AI: Které typy jsou nejdůležitější pro viditelnost v LLM
Zjistěte, na kterých typech schémat záleží nejvíce pro viditelnost v AI. Objevte, jak LLM interpretují strukturovaná data a implementujte strategie schema markup, které dostanou vaši značku do AI odpovědí.
Publikováno dne Jan 3, 2026.Naposledy upraveno dne Jan 3, 2026 v 3:24 am
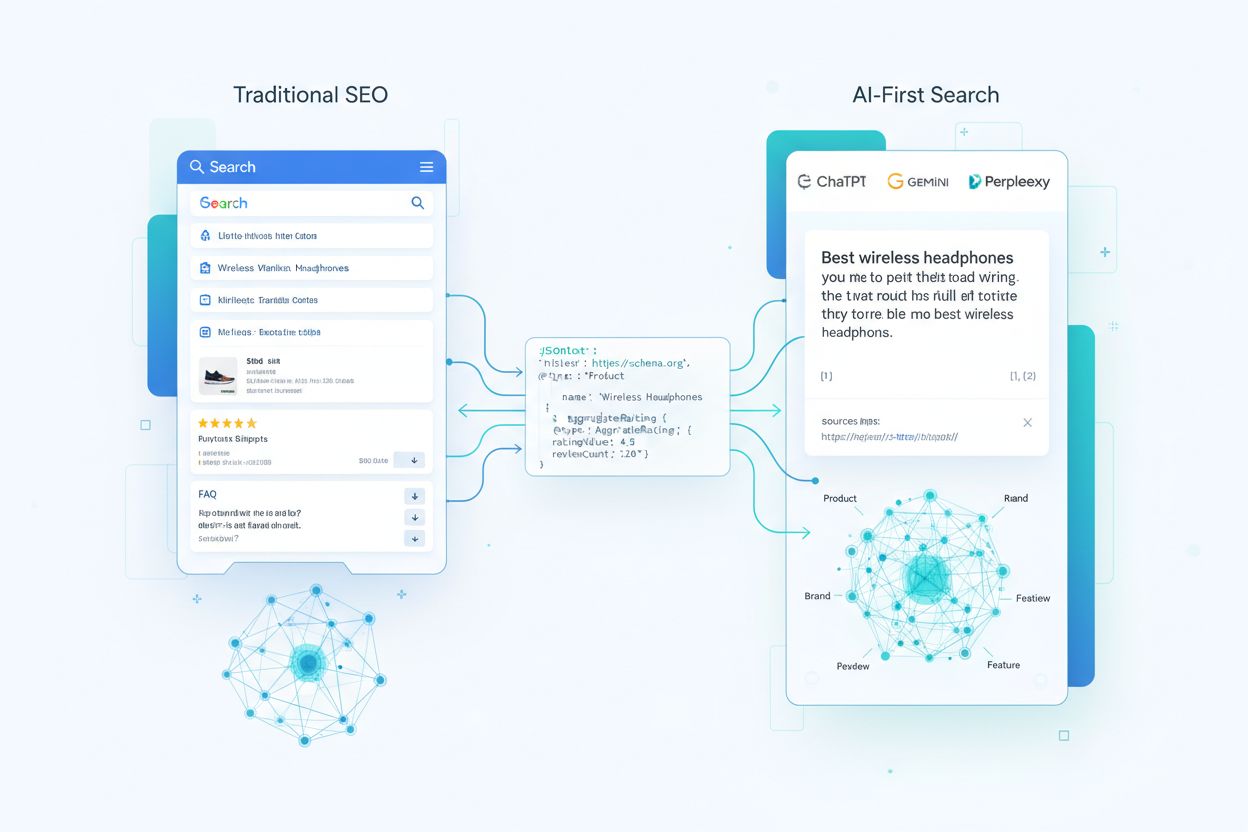
Po léta byl schema markup primárně o získávání bohatých výsledků—těch poutavých hvězdiček, produktových karet a FAQ akordeonů, které se zobrazovaly v tradičních výsledcích vyhledávání. Dnes je tento přístup zastaralý. Velké jazykové modely a AI odpovědní stroje interpretují schema markup zásadně jinak; nepoužívají jej pro kosmetická vylepšení, ale pro budování znalostních grafů a pochopení vztahů mezi entitami v masovém měřítku. Přibližně 45 milionů webů (12,4 % všech registrovaných domén) nyní využívá nějakou formu schema.org markup, takže AI systémy mají bezprecedentní množství strukturovaných dat, ze kterých se mohou učit a na které se mohou spoléhat. Posun je zásadní: schema markup nyní ovlivňuje, zda bude vaše značka citována v AI-generovaných odpovědích, jak přesně budou modely prezentovat vaše produkty a služby a zda se váš obsah stane důvěryhodným zdrojem v AI-prvním vyhledávacím prostředí.
Jak AI systémy skutečně interpretují schema markup
Pochopení toho, jak AI systémy spotřebovávají schema markup, vyžaduje sledovat cestu vašich strukturovaných dat od prvotního procházení až po odpovědi generované LLM. Když crawler narazí na vaši stránku, extrahuje bloky JSON-LD, microdata nebo RDFa a normalizuje je do indexu společně s nestrukturovaným textem a médii. Tato strukturovaná data se stávají součástí znalostního grafu v měřítku webu, kde jsou entity propojené vztahy a dostávají embeddingy pro sémantické vyhledávání. V systémech retrieval-augmented generation (RAG) může být schema přímo zařazeno do chunků, které naplňují vektorové indexy—jeden chunk může obsahovat jak popis produktu, tak jeho JSON-LD markup, což modelům poskytuje narativní kontext i strukturované atributy. Různé architektury LLM schema využívají různě: některé vrstvy modelů staví nad stávajícími indexy vyhledávačů a znalostními grafy, jiné používají multi-zdrojové retrievery, které čerpají jak ze strukturovaného, tak nestrukturovaného obsahu. Klíčové poznání je, že dobře implementované schema funguje jako smlouva s modelem—ve vysoce strukturované podobě stanovuje, které fakta na vaší stránce považujete za kanonická a důvěryhodná.
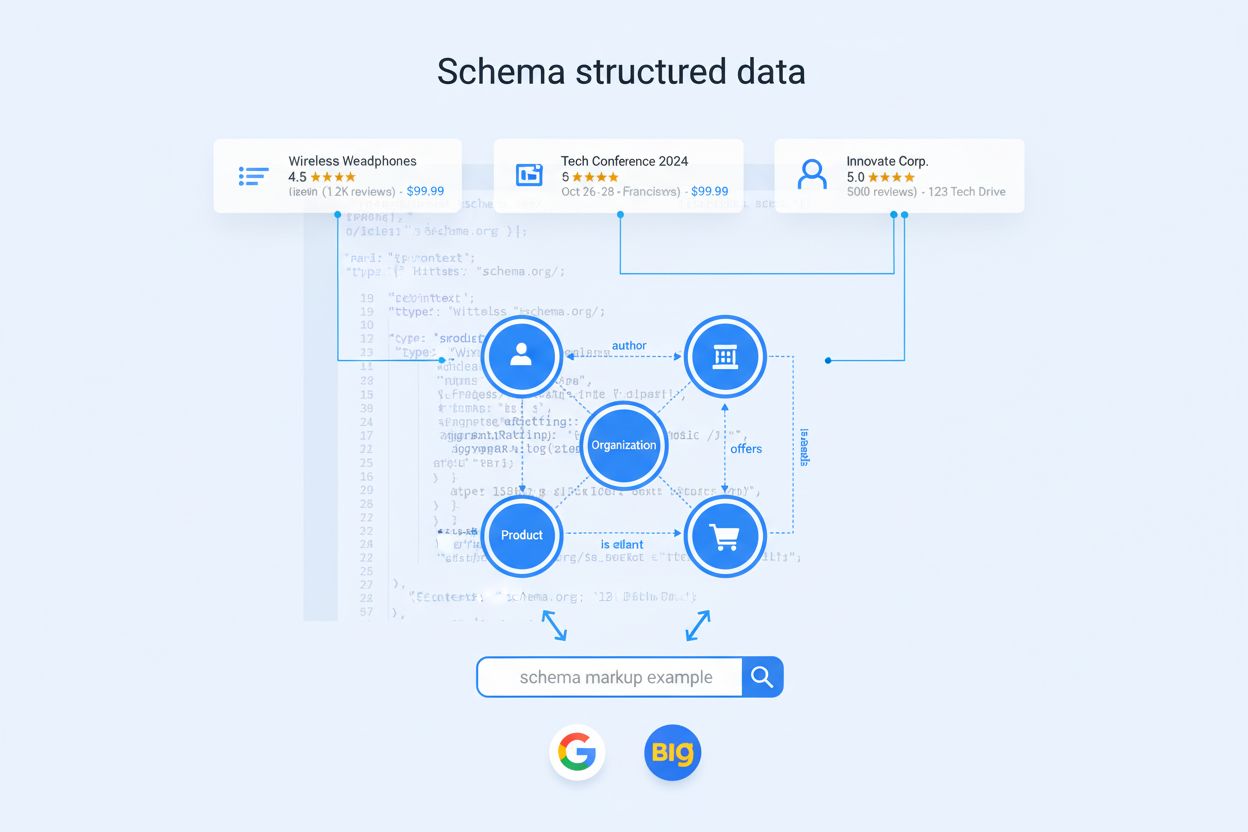
Ne všechny typy schémat mají v AI éře stejnou váhu. Organization markup slouží jako kotva celého vašeho entitního grafu a pomáhá modelům chápat identitu, autoritu a vztahy vaší značky. Product schema je klíčové pro e-commerce a retail, umožňuje AI systémům porovnávat vlastnosti, ceny a hodnocení napříč zdroji. Article a BlogPosting markup pomáhají modelům identifikovat dlouhé texty vhodné pro vysvětlující dotazy a thought leadership. Person schema je zásadní pro vytvoření důvěryhodnosti autora a přisouzení odbornosti v AI-generovaných odpovědích. FAQPage markup se přímo mapuje na konverzační dotazy, na které jsou AI asistenti navrženi odpovídat. Pro SaaS a B2B společnosti jsou stejně důležité typy SoftwareApplication a Service, jež se často objevují v porovnáních “nejlepší nástroje pro X” a hodnocení funkcí. Pro lokální firmy a poskytovatele zdravotní péče typy LocalBusiness a MedicalOrganization poskytují geografickou přesnost a regulační jasnost. Skutečné odlišení však nepřináší samotné přijetí základního typu, ale pokročilé vlastnosti, které navrch přidáte—konzistence napříč stránkami, jasné identifikátory entit a explicitní mapování vztahů.
Pokročilé vlastnosti schémat, které LLM skutečně využívají
Základní vlastnosti schématu jako name, description a URL jsou dnes samozřejmostí; 72,6 % stránek na první stránce Googlu již nějakou podobu schema markup využívá. Vlastnosti, které vytvářejí skutečné odlišení v AI viditelnosti, jsou pojivem, které modelům pomáhá rozlišovat entity, chápat vztahy a disambiguovat význam. Zde jsou pokročilé vlastnosti, na kterých nejvíce záleží:
sameAs: Propojuje vaši entitu s kanonickými profily na Wikipedii, LinkedIn, Crunchbase nebo stránkách výrobce, což výrazně snižuje šanci, že si model vaši značku splete s jmenovcem
about/mentions: Upřesňuje, na které témata a entity je stránka skutečně zaměřena, čímž modelům pomáhá vybrat ten správný “relevantní” zdroj pro složité otázky
@id: Poskytuje stabilní, unikátní identifikátory, které umožňují konzistentní rozlišení entit napříč vaším webem i celým internetem
additionalType: Nabízí specifičtější typové náznaky nad rámec hlavního typu schématu, což modelům pomáhá chápat jemné kategorizace
additionalProperty: Kóduje vlastní atributy a specifikace, které často figurují v porovnáních, recenzích a hodnotících textech
mentions: Výslovně identifikuje entity diskutované na stránce, čímž modelům pomáhá pochopit kontext a vztahy
Tyto vlastnosti proměňují schema z jednoduchého kontejneru dat v sémantickou mapu, v níž se modely mohou s důvěrou orientovat. Pokud pomocí sameAs odkážete svou organizaci na stránku na Wikipedii, nepřidáváte jen metadata—říkáte modelu “toto je autoritativní zdroj informací o nás.” Když využijete additionalProperty pro zakódování specifikací produktu nebo vlastností služby, poskytujete přesně ty atributy, které AI systémy hledají při sestavování porovnání či doporučení.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Strategie implementace schématu: Od základního po LLM-optimalizované
Většina organizací vnímá schema markup jako jednorázový implementační úkol, ale konkurenční výhoda v AI-driven vyhledávání vyžaduje přemýšlet o něm jako o průběžné disciplíně správy dat. Užitečný rámec představuje čtyřúrovňový model zralosti, který týmům pomáhá pochopit, kde se nacházejí a kam se potřebují posunout:
Úroveň 1 – Základní schema pro bohaté výsledky se zaměřuje na minimální markup na vybraných šablonách, primárně za účelem získání hvězdiček, produktových karet či FAQ úryvků. Správa je volná, konzistence nízká a cílem je kosmetické vylepšení, nikoli sémantická jasnost.
Úroveň 2 – Pokrytí zaměřené na entity standardizuje Organization, Product, Article a Person markup napříč klíčovými šablonami, zavádí konzistentní použití hodnot @id a přidává základní sameAs odkazy pro zamezení záměně entit.
Úroveň 3 – Schema integrované do znalostního grafu sladí schema ID s interními datovými modely (CMS, PIM, CRM), rozsáhle využívá vlastnosti about/mentions/additionalType a kóduje vztahy napříč stránkami, aby modely pochopily, jak spolu obsahové uzly souvisí a jak se vztahují k externím entitám.
Úroveň 4 – LLM-optimalizované & RAG-sladěné schema záměrně strukturuje markup pro konverzační dotazy a AI snippet formáty, slaďuje schema s interními RAG pipeline a zahrnuje měření i iteraci jako základní praxi.
Většina značek aktuálně stagnuje na úrovních 1–2, což znamená, že základní implementace je dnes jen hygienickým faktorem, nikoli odlišením. Posun k úrovním 3–4 představuje místo, kde se optimalizace schema pro LLM stává trvalou konkurenční výhodou, protože modely dokážou vaše entity spolehlivě interpretovat napříč mnoha variantami dotazů a výstupních rozhraní.
Vertikálně specifické vzory schémat pro AI odpovědní stroje
Různá odvětví mají různé entity, rizikové profily i záměry uživatelů, takže pokročilé využití schémat nemůže být univerzální. Základní principy—jasnost entit, modelování vztahů a sladění s obsahem na stránce—zůstávají konstantní, ale typy schémat a vlastnosti, které upřednostníte, by měly odrážet způsob, jakým lidé ve vašem oboru skutečně vyhledávají.
Pro e-commerce a retail jsou klíčovými entitami produkty, nabídky, recenze a vaše organizace. Každá produktová stránka s vysokým záměrem by měla obsahovat podrobný Product markup s identifikátory (SKU, GTIN), značkou, modelem, rozměry, materiály a rozlišujícími atributy pomocí additionalProperty. Doplnit je vhodné o Offers s cenou a dostupností a AggregateRating struktury, které modelům usnadní pochopení sociální důkaznosti. Nad rámec základů zvažte, jak zákazníci formulují otázky: “Je to voděodolné?”, “Je v balení záruka?”, “Jaká je politika vrácení?” Zakódování těchto odpovědí jako FAQPage markup na stejné URL a zajištění souladu mezi atributy produktu a FAQ obsahem výrazně usnadní odpovědním strojům citovat správnou stránku.
Pro SaaS a B2B služby jsou entity abstraktnější, ale dobře mapovatelné na SoftwareApplication, Service a Organization schema. Pro každý hlavní produkt či nabídku definujte SoftwareApplication nebo Service entitu s jasnými popisy kategorie, podporovaných platforem, integrací a cenových modelů a využijte additionalProperty pro vyjmenování funkcí, které se často objevují v žebříčcích “nejlepší nástroje pro X”. Propojte je s Organization přes provider nebo offers vztahy a s odbornými členy týmu pomocí Person markup. Na obsahové úrovni pomáhají Article, BlogPosting, FAQPage a HowTo struktury LLM identifikovat vaše nejlepší zdroje pro hodnotící a vzdělávací dotazy.
Pro lokální, zdravotnické a regulované obory typy LocalBusiness, MedicalOrganization a související MedicalEntity umožňují zakódovat adresy, oblasti působnosti, specializace, přijímané pojištění a provozní dobu mnohem méně nejednoznačně než volný text. To je důležité, když se AI asistent ptá “najdi mi dětského kardiologa v okolí, který přijímá moje pojištění” nebo “doporuč urgentní péči, která je právě otevřená.” V těchto sektorech buďte obzvlášť opatrní, aby schema nepřekračovalo nebo neodhalovalo citlivé údaje—označujte pouze fakta, která jste ochotni mít znovu použitá v různých kontextech, a zajistěte, aby právní a compliance týmy zkontrolovaly všechny zdravotnické nebo regulované atributy.
Měření dopadu schématu na AI viditelnost
Chování LLM je ze své podstaty stochastické, takže samotnými změnami schématu nedosáhnete dokonalé atribuce. Můžete ale vybudovat lehký monitorovací systém, který pravidelně vzorkuje AI odpovědi na definované dotazy. Sledujte, které entity jsou zmíněny, které URL jsou citovány, jak je vaše značka popsána a zda jsou klíčové údaje (ceny, schopnosti, compliance) přesné napříč platformami jako ChatGPT, Gemini, Perplexity a Bing Copilot. Pokud se něco pokazí—vymyšlené funkce, chybějící zmínky nebo citace upřednostňující agregátory před vašimi stránkami—začněte kontrolou konfliktních či neúplných signálů. Odporuje si obsah na stránce se schématem? Chybí sameAs odkazy nebo míří na zastaralé profily? Tvrdí více stránek, že jsou kanonickým zdrojem pro stejnou entitu? Strategicky plánujte revizi schématu minimálně čtvrtletně, aby odpovídalo novým nabídkám, obsahovým clusterům a změnám v tom, jak AI odpovědní stroje vaši značku zobrazují.
Běžné chyby ve schématu, které škodí LLM viditelnosti
Několik vzorců opakovaně podkopává efektivitu schématu pro AI systémy. Označování obsahu, který není na stránce viditelný, vytváří deficit důvěry—modely se naučí zdroje, kde se schema a viditelný obsah rozcházejí, ignorovat. Použití příliš obecných typů bez specifikace (např. označovat vše jako “Thing” nebo “CreativeWork”) neposkytuje žádný sémantický signál; modely potřebují přesné typy k pochopení kontextu. Kopírování univerzálního schématu napříč stránkami bez úpravy detailů je asi nejčastější chybou—když každá produktová stránka obsahuje identický Organization markup nebo každý článek uvádí stejného autora, mají modely problém s rozlišením a mohou váš obsah označit jako málo hodnotný. Nekonzistentní identifikátory entit napříč stránkami (různé hodnoty @id pro stejnou organizaci nebo produkt) narušují rozlišení entit a modely pak považují související obsah za samostatné entity. Chybějící sameAs odkazy na autoritativní profily nechávají modely náchylné ke zmatení vaší značky s jmenovci. Nakonec, konfliktní informace mezi schématem a obsahem na stránce signalizují nespolehlivost; pokud schema říká, že produkt je skladem, ale stránka uvádí “není skladem”, modely nebudou věřit ani jednomu zdroji.
Budoucnost schématu a AI vyhledávání
Schema markup se mění z kosmetického SEO triku na základní technologii pro AI-první vyhledávání. Propojené schéma—kde explicitně definujete vztahy mezi entitami pomocí vlastností jako sameAs, about a mentions—buduje znalostní grafy, v nichž se AI systémy mohou sebevědomě orientovat. Konkurenční výhoda již nenáleží těm, kteří se ptají “Jaké minimum schématu potřebujeme pro bohatý výsledek?”, ale těm, kteří řeší “Jaká struktura dat by učinila náš obsah pro stroj jednoznačným, i mimo SERP?” Tento posun tlačí organizace k úplnějším, propojenějším a na entity zaměřeným vzorům schémat. Jak se AI-driven vyhledávání stává hlavním kanálem objevování, optimalizace schema pro LLM přechází z technické zajímavosti na klíčovou SEO disciplínu. Organizace, které projdou úrovněmi zralosti—od základního schématu pro bohaté výsledky k integraci do znalostního grafu a LLM-optimalizovaným vzorcům—si vybudují trvalé konkurenční bariéry v AI-driven objevování, zajistí, že budou citovány jako autority a jejich obsah se objeví jako důvěryhodný zdroj.
Často kladené otázky
Jak se schema markup liší pro AI oproti tradičnímu SEO?
Tradiční schema se zaměřovalo na bohaté výsledky (hvězdičky, úryvky). Pro AI je schema o jasnosti entit, vztazích a znalostních grafech. AI systémy využívají schema k pochopení obsahu na sémantické úrovni, ne pouze pro vizuální vylepšení.
Které typy schémat jsou nejdůležitější pro viditelnost v LLM?
Organization, Product, Article, Person a FAQPage jsou základní. Pro SaaS přidejte SoftwareApplication a Service. Pro lokální/zdravotní segment přidejte LocalBusiness a MedicalOrganization. Důležitost se liší podle odvětví a záměru uživatele.
Musím implementovat všechny typy schémat?
Ne. Začněte s Organization a vašimi nejhodnotnějšími stránkami (produkty, služby, klíčové články). Postupně rozšiřujte pokrytí podle vašeho obchodního modelu a tam, kde by AI odpovědi měly největší přínos.
Jak dlouho trvá, než se projeví výsledky optimalizace schématu?
Změny ve schématu mohou ovlivnit AI citace v řádu týdnů, ale vztah je pravděpodobnostní. Plánujte čtvrtletní revize a průběžné sledování napříč více AI platformami pro sledování dopadu.
Jaký je rozdíl mezi vlastnostmi sameAs a about?
sameAs propojuje vaši entitu s kanonickými profily (Wikipedia, LinkedIn) a zabraňuje záměně se jmenovci. about/mentions upřesňuje, na co se vaše stránka skutečně zaměřuje, což modelům pomáhá pochopit nuance a kontext.
Ne. Schema funguje nejlépe v souladu s kvalitním, dobře strukturovaným obsahem na stránce. Modely potřebují jak strukturovaná data, tak narativní kontext, aby mohly s jistotou citovat vaše stránky.
Jak zjistím, zda změny ve schématu pomáhají s AI viditelností?
Sledujte AI odpovědi napříč platformami (ChatGPT, Gemini, Perplexity, Bing) pro vaše cílové dotazy. Sledujte zmínky o entitách, citace URL, přesnost faktů a popis značky. Sledujte trendy v průběhu týdnů/měsíců.
Mám pro schema markup použít JSON-LD, microdata nebo RDFa?
JSON-LD je doporučený formát pro většinu případů. Je jednodušší na implementaci, údržbu a nezasahuje do HTML. Microdata a RDFa jsou v moderních implementacích méně běžné.
Sledujte svou značku v AI odpovědích
Sledujte, jak AI systémy citují vaši značku napříč ChatGPT, Gemini, Perplexity a Google AI Overviews. Získejte přehled o tom, které typy schémat zvyšují vaši viditelnost.
Jaký schema markup pomáhá u AI vyhledávání? Kompletní průvodce pro rok 2025
Zjistěte, které typy schema markup zvyšují vaši viditelnost ve vyhledávačích s umělou inteligencí jako ChatGPT, Perplexity a Gemini. Naučte se strategie impleme...
Schema markup je standardizovaný kód, který pomáhá vyhledávačům pochopit obsah. Zjistěte, jak strukturovaná data zlepšují SEO, umožňují bohaté výsledky a podpor...
Které typy schema markup skutečně pomáhají s viditelností v AI?
Diskuze komunity o schema markupu pro AI viditelnost. Skutečné zkušenosti vývojářů a SEO odborníků s tím, které typy strukturovaných dat zlepšují citace v AI....
5 min čtení
Discussion
Technical SEO
+1
Souhlas s cookies Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.