
Vyhledávací záměr
Vyhledávací záměr je účel, který stojí za uživatelským dotazem ve vyhledávači. Zjistěte čtyři typy vyhledávacího záměru, jak je identifikovat a jak optimalizova...
11 min čtení
Zjistěte, jak velké jazykové modely interpretují uživatelský záměr nad rámec klíčových slov. Objevte rozšiřování dotazů, sémantické porozumění a jak AI systémy určují, který obsah citovat ve svých odpovědích.
Uživatelský záměr v AI vyhledávání označuje základní cíl nebo účel za dotazem, nikoli jen klíčová slova, která někdo napíše. Když hledáte „nejlepší nástroje na řízení projektů“, můžete chtít rychlé srovnání, informace o ceně nebo možnosti integrací—a velké jazykové modely (LLM) jako ChatGPT, Perplexity a Gemini od Googlu se snaží pochopit, který z těchto cílů skutečně sledujete. Na rozdíl od tradičních vyhledávačů, které párují klíčová slova se stránkami, LLM interpretují sémantický význam vašeho dotazu analýzou kontextu, formulace a souvisejících signálů, aby předpověděly, co skutečně chcete dosáhnout. Tento posun od párování klíčových slov k porozumění záměru je zásadní pro fungování moderních AI vyhledávačů a přímo určuje, které zdroje budou citovány v AI generovaných odpovědích. Porozumění uživatelskému záměru je dnes klíčové pro značky usilující o viditelnost ve výsledcích AI vyhledávání, protože nástroje jako AmICited již sledují, jak AI systémy odkazují na váš obsah podle sladění záměru.
Když zadáte jeden dotaz do AI vyhledávače, v zákulisí se děje něco pozoruhodného: model neodpovídá jen přímo na vaši otázku. Místo toho rozšiřuje váš dotaz na desítky souvisejících mikrootázek, což výzkumníci nazývají „query fan-out“. Například jednoduché hledání „Notion vs Trello“ může spustit poddotazy jako „Který je lepší pro týmovou spolupráci?“, „Jaké jsou rozdíly v cenách?“, „Který se lépe integruje se Slackem?“ a „Který je jednodušší pro začátečníky?“ Toto rozšíření umožňuje LLM prozkoumat různé úhly vašeho záměru a získat komplexnější informace před vytvořením odpovědi. Systém pak hodnotí pasáže z různých zdrojů na úrovni detailních úseků, místo aby řadil celé stránky—může být vybrán jediný odstavec z vašeho obsahu, zatímco zbytek stránky je ignorován. Tato analýza na úrovni pasáží je důvod, proč jasnost a konkrétnost v každé sekci mají větší význam než kdy dříve—dobře strukturovaná odpověď na konkrétní podzáměr může být důvodem, proč se váš obsah objeví v AI generované odpovědi.
| Původní dotaz | Podzáměr 1 | Podzáměr 2 | Podzáměr 3 | Podzáměr 4 |
|---|---|---|---|---|
| “Nejlepší nástroje na řízení projektů” | “Který je nejlepší pro vzdálené týmy?” | “Jaká je cena?” | “Který se integruje se Slackem?” | “Který je nejjednodušší pro začátečníky?” |
| “Jak zvýšit produktivitu” | “Jaké nástroje pomáhají s time managementem?” | “Jaké jsou osvědčené metody produktivity?” | “Jak omezit rozptýlení?” | “Jaké návyky zvyšují soustředění?” |
| “AI vyhledávače vysvětleny” | “Jak se liší od Googlu?” | “Který AI vyhledávač je nejpřesnější?” | “Jak řeší soukromí?” | “Jaká je budoucnost AI vyhledávání?” |
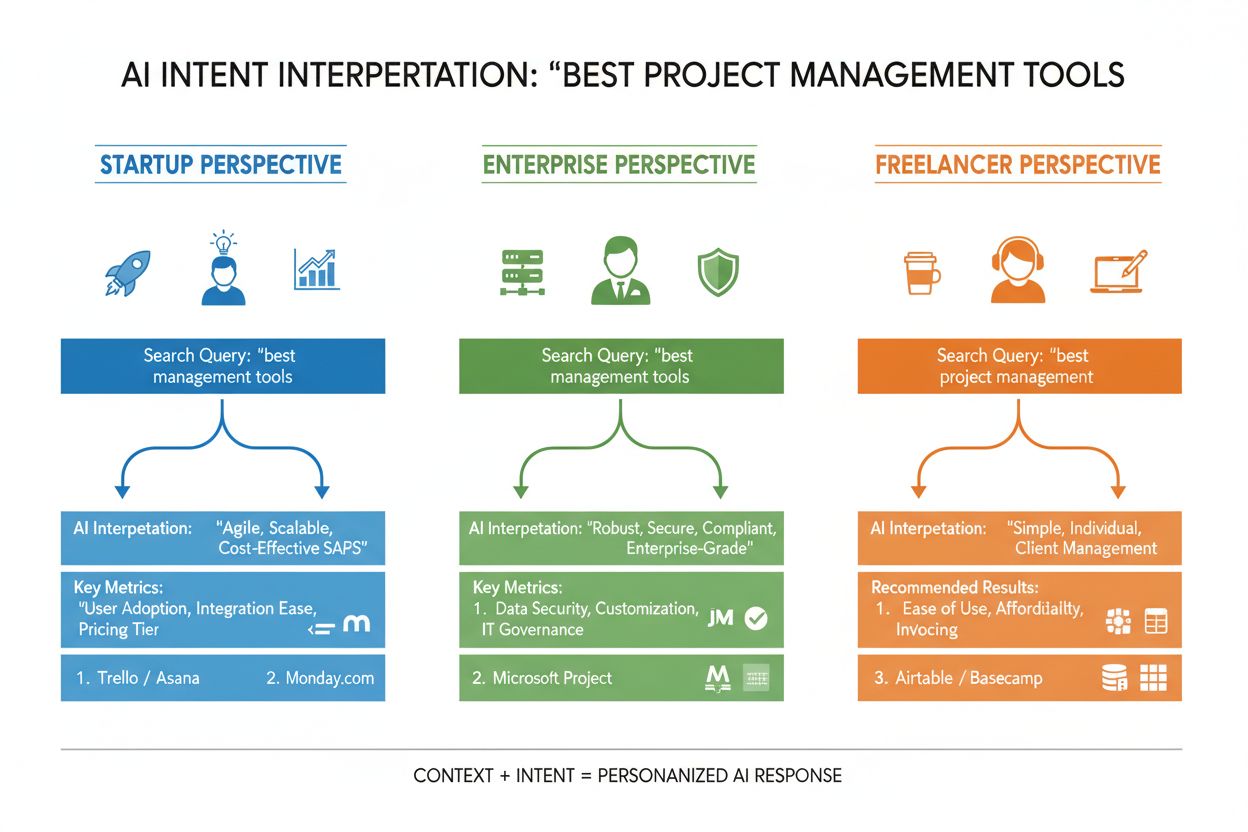
LLM neposuzují váš dotaz izolovaně—budují to, co výzkumníci nazývají „embedding uživatele“, vektorový profil, který zachycuje váš měnící se záměr na základě historie vyhledávání, polohy, typu zařízení, denní doby a dokonce i předchozích konverzací. Toto kontextové porozumění umožňuje systému dramaticky personalizovat výsledky: dva uživatelé hledající „nejlepší CRM nástroje“ mohou dostat zcela odlišná doporučení, pokud je jeden zakladatel startupu a druhý manažer ve velké firmě. Re-rankování v reálném čase dále zpřesňuje výsledky podle vašich interakcí—pokud klikáte na určité výsledky, strávíte čas čtením konkrétních sekcí nebo pokládáte doplňující otázky, systém upravuje pochopení vašeho záměru a podle toho aktualizuje další doporučení. Tento behaviorální zpětnovazební okruh znamená, že AI systémy se neustále učí, co uživatelé skutečně chtějí, ne jen to, co původně zadali. Pro tvůrce obsahu a marketéry to zdůrazňuje důležitost vytváření obsahu, který naplňuje záměr napříč různými uživatelskými kontexty a fázemi rozhodovacího procesu.
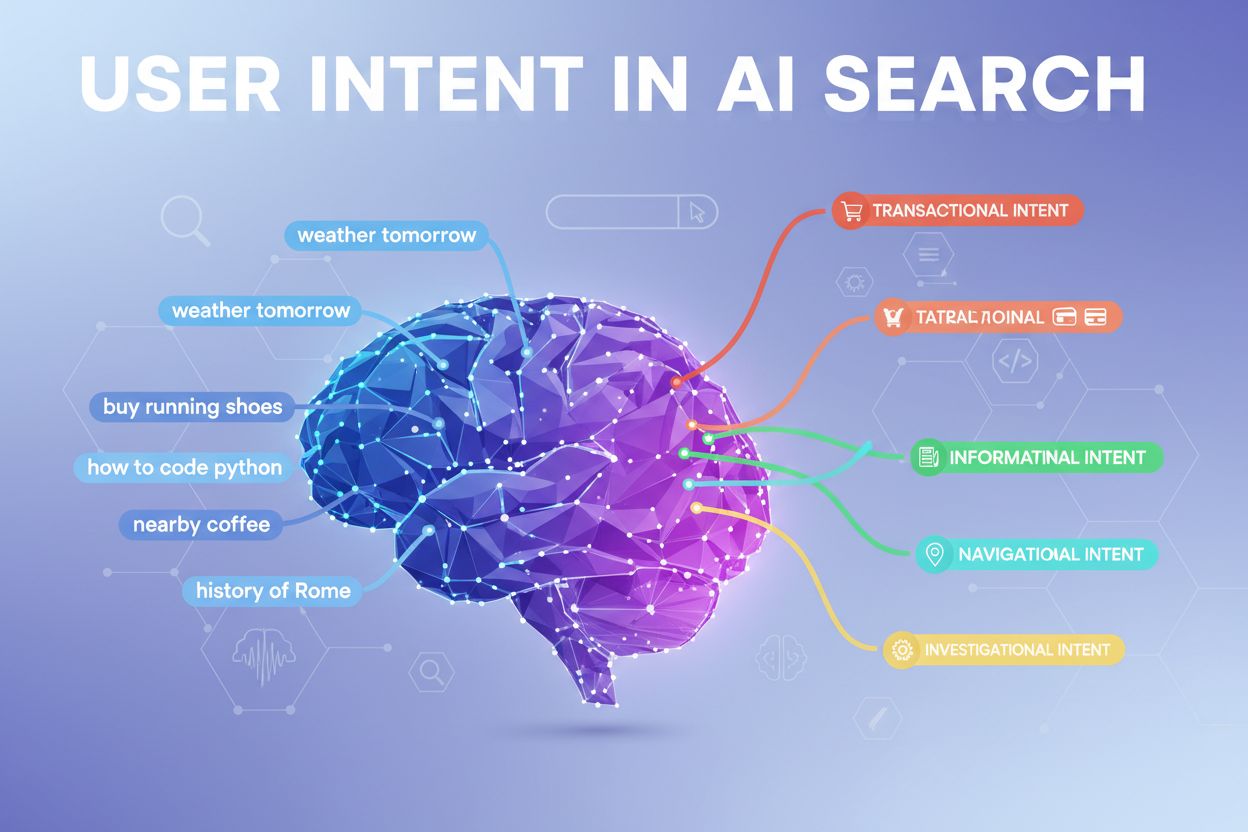
Moderní AI systémy klasifikují uživatelský záměr do několika odlišných kategorií, z nichž každá vyžaduje jiný typ obsahu a odpovědi:
LLM automaticky klasifikují tyto záměry analýzou struktury dotazu, klíčových slov a kontextových signálů a pak vybírají obsah, který nejlépe odpovídá zjištěnému typu záměru. Porozumění těmto kategoriím pomáhá tvůrcům obsahu strukturovat stránky tak, aby oslovily konkrétní záměr, se kterým uživatel přichází do vyhledávání.
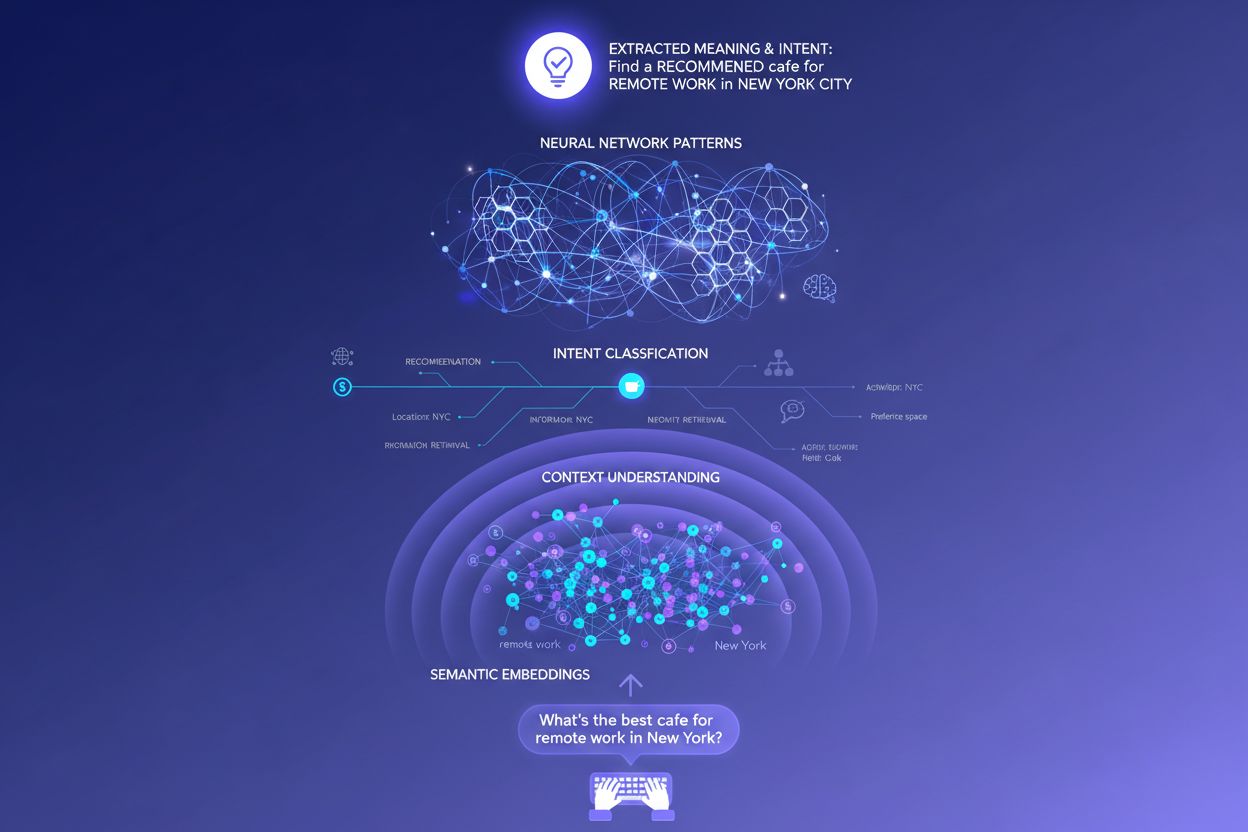
Tradiční vyhledávače založené na klíčových slovech fungují na jednoduchém párování řetězců—pokud vaše stránka obsahuje přesně ta slova, která někdo hledá, může se zobrazit ve výsledcích. Tento přístup ale selhává u synonym, parafrází a kontextu. Pokud někdo hledá „dostupný software na řízení projektů“ a vaše stránka používá frázi „cenově příznivá platforma pro koordinaci úkolů“, tradiční vyhledávač spojení vůbec nemusí najít. Sémantické embeddingy tento problém řeší tím, že převádějí slova a fráze do matematických vektorů, které zachycují význam místo povrchového textu. Tyto vektory existují ve vícerozměrném prostoru, kde se sémanticky podobné pojmy shlukují dohromady, takže LLM rozpoznají, že „dostupný“, „cenově příznivý“, „levný“ a „nízkonákladový“ vyjadřují stejný záměr. Tento sémantický přístup také mnohem lépe zvládá dlouhé a konverzační dotazy než párování klíčových slov—dotaz jako „Jsem freelancer a potřebuji něco jednoduchého, ale výkonného“ lze spárovat s relevantním obsahem, i když neobsahuje klasická klíčová slova. Praktickým výsledkem je, že AI systémy dokáží zobrazit relevantní odpovědi i na vágní, složité nebo neobvyklé dotazy, což je činí mnohem užitečnějšími než jejich předchůdci založení na klíčových slovech.
Technickým jádrem interpretace záměru je transformerová architektura, neuronová síť, která zpracovává jazyk analýzou vztahů mezi slovy pomocí mechanismu zvaného „attention“. Místo sekvenčního čtení textu jako člověk hodnotí transformer, jak se každé slovo vztahuje ke všem ostatním ve větě, což umožňuje zachytit jemné významy a kontext. Sémantické embeddingy jsou číselné reprezentace, které z tohoto procesu vznikají—každé slovo, fráze či pojem je převeden do vektoru čísel nesoucích jeho význam. Modely jako BERT (Bidirectional Encoder Representations from Transformers) a RankBrain používají tyto embeddingy k rozpoznání, že „nejlepší CRM pro startupy“ a „špičková platforma pro řízení vztahů se zákazníky pro nové firmy“ vyjadřují podobný záměr, i když používají zcela odlišná slova. Attention mechanismus je obzvlášť silný, protože umožňuje modelu zaměřit se na nejrelevantnější části dotazu—ve frázi „nejlepší nástroje na řízení projektů pro vzdálené týmy s omezeným rozpočtem“ se systém naučí přisuzovat vyšší váhu výrazům „vzdálené týmy“ a „omezený rozpočet“ jako klíčovým signálům záměru. Tato technická vyspělost je důvodem, proč AI vyhledávání působí mnohem inteligentněji než tradiční systémy založené na klíčových slovech.
Pochopení toho, jak LLM interpretují záměr, zásadně mění obsahovou strategii. Místo psaní jednoho rozsáhlého průvodce, který má zacílit na jediné klíčové slovo, úspěšný obsah dnes řeší více podzáměrů v modulárních sekcích, které mohou stát samostatně. Pokud píšete o nástrojích na řízení projektů, místo jedné obrovské srovnávací stránky vytvořte samostatné sekce odpovídající na „Který je nejlepší pro vzdálené týmy?“, „Který je nejdostupnější?“, „Který se integruje se Slackem?“—každá sekce se stává potenciální kartou odpovědi, kterou LLM mohou vytáhnout a citovat. Formátování připravené na citace je mimořádně důležité: používejte fakta místo vágních tvrzení, uvádějte konkrétní čísla a data a strukturovaně informace, aby je AI systémy mohly snadno citovat nebo shrnout. Odrážky, jasné nadpisy a krátké odstavce pomáhají LLM lépe zpracovat váš obsah než hutný text. Nástroje jako AmICited nyní umožňují marketérům sledovat, jak AI systémy odkazují na jejich obsah v ChatGPT, Perplexity a Google AI, takže lze zjistit, která sladění záměru fungují a kde jsou obsahové mezery. Tento daty řízený přístup k obsahové strategii—optimalizace pro to, jak AI systémy skutečně interpretují a citují vaši práci—představuje zásadní posun oproti tradičnímu SEO.
Představte si příklad z e-commerce: když někdo hledá „voděodolná bunda do 5 000 Kč“, současně vyjadřuje několik záměrů—chce informace o odolnosti, potvrzení ceny a produktová doporučení. AI systém může tento dotaz rozšířit na poddotazy týkající se voděodolné technologie, porovnání cen, recenzí značek a záruk. Značka, která všechny tyto úhly pokrývá modulárním, dobře strukturovaným obsahem, má mnohem větší šanci být citována v AI generované odpovědi než konkurence s generickou produktovou stránkou. V oblasti SaaS se stejný dotaz „Jak pozvu svůj tým do tohoto workspace?“ může objevit stovkykrát v podpůrných záznamech, což signalizuje zásadní obsahovou mezeru. AI asistent vyškolený na vaší dokumentaci může mít s jasnou odpovědí problém, což vede ke špatné uživatelské zkušenosti a nižší viditelnosti v AI generovaných odpovědích podpory. V oblasti zpravodajství a informací bude dotaz „Co se děje s regulací AI?“ interpretován různě podle uživatelského kontextu—politik potřebuje legislativní detaily, byznys lídr konkurenční dopady a technolog potřebuje informace o technických standardech. Úspěšný obsah tyto různé kontexty explicitně zohledňuje.
Navzdory své vyspělosti čelí LLM skutečným výzvám v interpretaci záměru. Nejednoznačné dotazy jako „Java“ mohou znamenat programovací jazyk, ostrov nebo kávu—a i s kontextem může dojít k chybné klasifikaci. Smíšené nebo vrstvené záměry vše komplikují: „Je tento CRM lepší než Salesforce a kde si ho můžu vyzkoušet zdarma?“ kombinuje srovnávací, hodnotící a transakční záměr v jednom dotazu. Omezení kontextového okna znamenají, že LLM zvládnou zohlednit jen omezenou část historie konverzace, takže v dlouhých multi-turn rozhovorech mohou být dřívější signály záměru zapomenuty. Halucinace a faktické chyby zůstávají problémem, zvláště v oblastech vyžadujících vysokou přesnost, jako je zdravotnictví, finance nebo právní poradenství. Zásady soukromí také hrají roli—jak systémy shromažďují více behaviorálních dat pro zlepšení personalizace, musí vyvážit přesnost rozpoznání záměru s ochranou soukromí uživatelů. Pochopení těchto omezení pomáhá tvůrcům obsahu a marketérům nastavit realistická očekávání ohledně viditelnosti v AI vyhledávání a uvědomit si, že ne každý dotaz bude interpretován perfektně.
Vyhledávání podle záměru se rychle vyvíjí směrem k sofistikovanějšímu porozumění a interakci. Konverzační AI bude stále přirozenější, systémy udrží kontext v delších, složitějších multi-turn dialozích, kde se může záměr měnit a vyvíjet. Multimodální rozpoznání záměru spojí text, obrázky, hlas i video pro komplexnější pochopení uživatelských cílů—představte si, že AI asistentovi řeknete „najdi mi něco jako tohle“ a ukážete fotku. Zero-query vyhledávání představuje nový směr, kdy AI systémy předvídají potřeby uživatelů dřív, než jsou explicitně vysloveny, na základě behaviorálních signálů a kontextu proaktivně zobrazují relevantní informace. Lepší personalizace bude znamenat stále individualizovanější výsledky podle profilu, fáze rozhodování i situace uživatele. Propojení s doporučovacími systémy rozmaže hranici mezi vyhledáváním a objevováním, protože AI budou uživatelům navrhovat relevantní obsah, který by jinak nehledali. Jak tyto schopnosti dozrávají, konkurenční výhodu budou mít značky a tvůrci, kteří záměru skutečně rozumí a strukturuji svůj obsah tak, aby jej komplexně naplnili napříč různými kontexty a typy uživatelů.
Uživatelský záměr označuje základní cíl nebo účel dotazu, nikoli jen použitá klíčová slova. LLM interpretují sémantický význam analýzou kontextu, formulace a souvisejících signálů, aby předpověděly, co uživatel skutečně chce dosáhnout. Proto stejný dotaz může přinést různé výsledky v závislosti na kontextu uživatele a fázi rozhodovacího procesu.
LLM využívají proces zvaný 'query fan-out', kdy rozkládají jediný dotaz na desítky souvisejících mikro-otázek. Například 'Notion vs Trello' se může rozšířit do poddotazů o týmové spolupráci, cenách, integracích a jednoduchosti použití. Díky tomu mohou AI systémy prozkoumat různé úhly záměru a získat komplexní informace.
Pochopení záměru pomáhá tvůrcům obsahu optimalizovat, jak AI systémy skutečně interpretují a citují jejich práci. Obsah, který řeší více podzáměrů v modulárních sekcích, má větší pravděpodobnost výběru LLM. To přímo ovlivňuje viditelnost v AI generovaných odpovědích napříč ChatGPT, Perplexity a Google AI.
Sémantické embeddingy převádějí slova a fráze do matematických vektorů, které zachycují význam, ne jen povrchový text. Díky tomu LLM poznají, že 'dostupný', 'cenově příznivý' a 'levný' vyjadřují stejný záměr, i když používají různá slova. Tento sémantický přístup lépe zvládá synonyma, parafráze i kontext než tradiční párování klíčových slov.
Ano, LLM čelí výzvám s nejednoznačnými dotazy, smíšenými záměry a omezením kontextu. Dotazy jako 'Java' mohou znamenat programovací jazyk, geografii nebo kávu. Dlouhé konverzace mohou překročit kontextové okno, což znamená, že dřívější signály záměru se zapomenou. Pochopení těchto omezení pomáhá nastavit realistická očekávání ohledně viditelnosti v AI vyhledávání.
Značky by měly tvořit modulární obsah, který řeší více podzáměrů v samostatných sekcích. Používejte formátování připravené na citace s fakty, konkrétními čísly a jasnou strukturou. Sledujte, jak AI systémy odkazují na váš obsah pomocí nástrojů jako AmICited, abyste odhalili mezery ve sladění záměru a optimalizovali podle toho.
Záměr je zaměřený na úkol—co chce uživatel právě teď uskutečnit. Zájem je širší obecná zvědavost. AI systémy upřednostňují záměr, protože přímo určuje, který obsah bude vybrán do odpovědi. Uživatel může mít zájem o produktivní nástroje obecně, ale jeho záměrem může být najít něco konkrétního pro vzdálenou týmovou spolupráci.
AI systémy citují zdroje, které nejlépe odpovídají detekovanému záměru. Pokud váš obsah jasně řeší konkrétní podzáměr dobře strukturovanými, faktickými informacemi, je větší šance na jeho výběr. Nástroje jako AmICited sledují tyto vzorce citací a ukazují, které sladění záměru zvyšuje viditelnost v AI generovaných odpovědích.
Pochopte, jak LLM odkazují na váš obsah v ChatGPT, Perplexity a Google AI. Sledujte sladění záměru a optimalizujte viditelnost v AI pomocí AmICited.
Vyhledávací záměr je účel, který stojí za uživatelským dotazem ve vyhledávači. Zjistěte čtyři typy vyhledávacího záměru, jak je identifikovat a jak optimalizova...

Prozkoumejte kategorie záměrů vyhledávání v AI a jak generativní systémy jako ChatGPT, Perplexity a Google AI interpretují cíle uživatelů. Poznejte 4 základní t...
Zjistěte, co znamená informační vyhledávací záměr pro AI systémy, jak AI tyto dotazy rozpoznává a proč je pochopení tohoto záměru důležité pro viditelnost obsah...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.