
Existuje AI vyhledávací index? Jak AI vyhledávače indexují obsah
Zjistěte, jak fungují AI vyhledávací indexy, jaké jsou rozdíly mezi metodami indexace ChatGPT, Perplexity a SearchGPT, a jak optimalizovat svůj obsah pro vidite...
7 min čtení

Zjistěte, jak fungují AI vyhledávače jako ChatGPT, Perplexity a Google AI Overviews. Objevte LLM, RAG, sémantické vyhledávání a mechanismy pro vyhledávání v reálném čase.
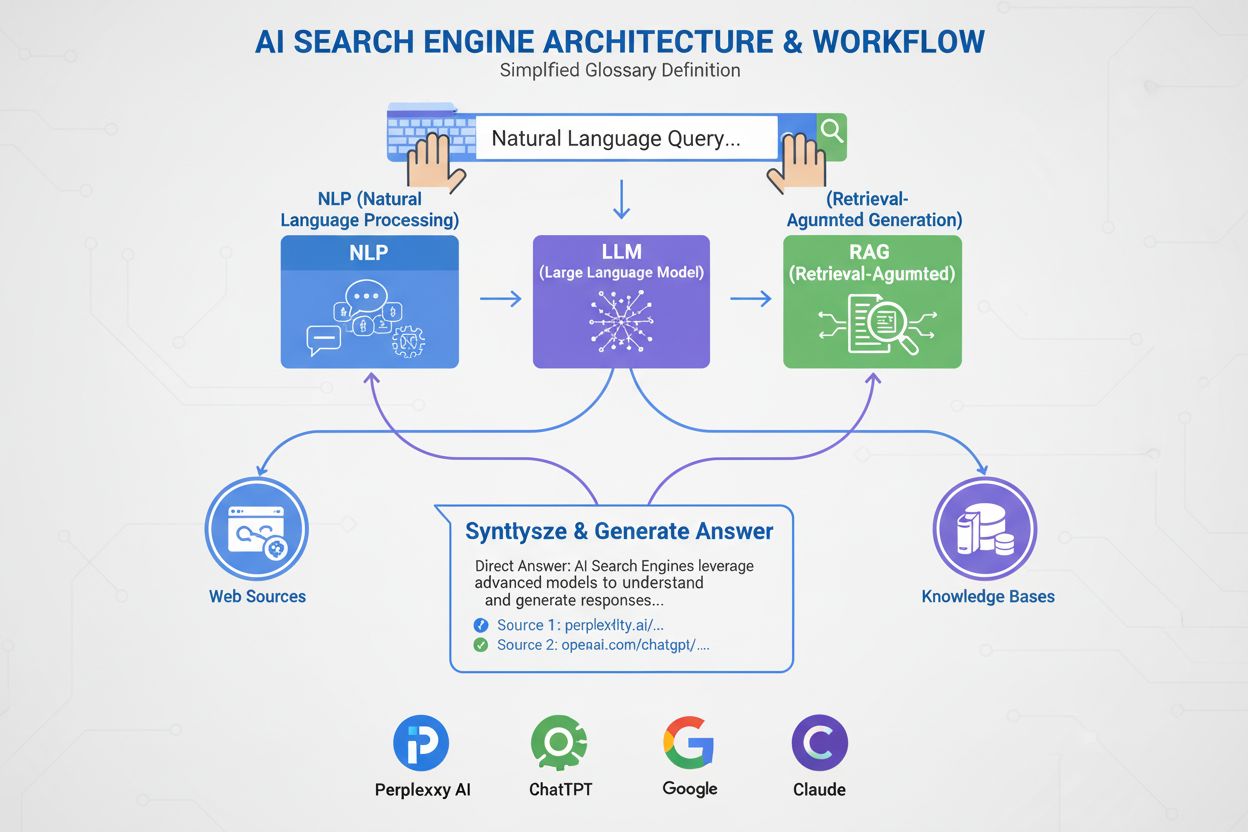
AI vyhledávače využívají velké jazykové modely (LLM) v kombinaci s generováním doplněným vyhledáváním (RAG), aby porozuměly záměru uživatele a v reálném čase vyhledávaly relevantní informace z webu. Zpracovávají dotazy pomocí sémantického porozumění, vektorových embeddingů a znalostních grafů, aby poskytly konverzační odpovědi s citacemi zdrojů, na rozdíl od tradičních vyhledávačů, které vracejí seřazené seznamy webových stránek.
AI vyhledávače představují zásadní posun od tradičního vyhledávání založeného na klíčových slovech k konverzačnímu, záměrově řízenému vyhledávání informací. Na rozdíl od tradičního vyhledávače Google, který prochází web, indexuje stránky a řadí je pro návrat seznamu odkazů, AI vyhledávače jako ChatGPT, Perplexity, Google AI Overviews a Claude generují originální odpovědi kombinací několika technologií. Tyto platformy rozumí tomu, co uživatelé skutečně hledají, získávají relevantní informace z autoritativních zdrojů a syntetizují je do ucelených, citovaných odpovědí. Technologie, která tato řešení pohání, mění způsob, jakým lidé objevují informace online; ChatGPT zpracovává 2 miliardy dotazů denně a AI Overviews se objevují v 18 % globálních vyhledávání na Googlu. Porozumění tomu, jak tyto systémy fungují, je zásadní pro tvůrce obsahu, marketéry i firmy, které chtějí být v tomto novém vyhledávacím prostředí vidět.
AI vyhledávače fungují prostřednictvím tří propojených systémů, které spolupracují na poskytování přesných odpovědí se zdroji. První komponentou je velký jazykový model (LLM), který je trénován na obrovském množství textových dat, aby pochopil jazykové vzory, strukturu a nuance. Modely jako GPT-4 od OpenAI, Gemini od Googlu a Claude od Anthropicu jsou trénovány neřízeným učením na miliardách dokumentů, což jim umožňuje předpovídat, která slova by měla následovat podle statistických vzorců naučených během tréninku. Druhou komponentou je embeddingový model, který převádí slova a fráze do číselných reprezentací zvaných vektory. Tyto vektory zachycují sémantický význam a vztahy mezi pojmy, takže systém rozpozná, že „herní notebook“ a „výkonný počítač“ jsou sémanticky příbuzné, i když nemají stejná klíčová slova. Třetí klíčovou komponentou je generování doplněné vyhledáváním (RAG), které doplňuje tréninková data LLM tím, že v reálném čase získává aktuální informace z externích znalostních bází. To je zásadní, protože LLM mají datum tréninkového omezení a bez RAG nemohou přistupovat k živým informacím. Tyto tři komponenty společně umožňují AI vyhledávačům poskytovat aktuální, přesné a citované odpovědi namísto halucinací nebo zastaralých informací.
Generování doplněné vyhledáváním je proces, který umožňuje AI vyhledávačům opírat své odpovědi o autoritativní zdroje, místo aby se spoléhaly pouze na tréninková data. Když zadáte dotaz do AI vyhledávače, systém nejprve převede vaši otázku na vektorovou reprezentaci pomocí embeddingového modelu. Tento vektor je následně porovnán s databází indexovaného webového obsahu, také převedeného na vektory, pomocí technik jako kosinová podobnost k identifikaci nejrelevantnějších dokumentů. Systém RAG tyto dokumenty získá a předá je LLM spolu s původním dotazem. LLM pak použije jak získané informace, tak svá tréninková data k vygenerování odpovědi, která přímo odkazuje na konzultované zdroje. Tento přístup řeší několik zásadních problémů: zajišťuje aktuálnost a faktickou správnost odpovědí, umožňuje uživatelům ověřit informace podle citací zdrojů a dává tvůrcům obsahu možnost být citováni v AI odpovědích. Azure AI Search a AWS Bedrock jsou podniková řešení RAG, která ukazují, jak mohou organizace stavět vlastní AI vyhledávací systémy. Kvalita RAG závisí do značné míry na tom, jak dobře dokáže vyhledávací systém identifikovat relevantní dokumenty, proto se sémantické řazení a hybridní vyhledávání (kombinace klíčových slov a vektorového vyhledávání) staly klíčovými technikami pro zvýšení přesnosti.
Sémantické vyhledávání je technologie, která umožňuje AI vyhledávačům chápat význam, nejen porovnávat klíčová slova. Tradiční vyhledávače hledají přesné shody klíčových slov, zatímco sémantické vyhledávání analyzuje záměr a kontextuální význam dotazu. Když například hledáte „dostupné smartphony s dobrým fotoaparátem“, sémantický vyhledávač pochopí, že chcete levné telefony s vynikajícími fotoaparáty, i když výsledky neobsahují přesně tato slova. To je umožněno díky vektorovým embeddingům, které převádějí text do vícerozměrných číselných polí. Pokročilé modely jako BERT (Bidirectional Encoder Representations from Transformers) a OpenAI text-embedding-3-small převádějí slova, fráze a celé dokumenty do vektorů, kde je sémanticky podobný obsah umístěn blízko sebe ve vektorovém prostoru. Systém pak počítá vektorovou podobnost pomocí matematických technik, jako je kosinová podobnost, aby našel dokumenty nejvíce odpovídající záměru dotazu. Tento přístup je výrazně efektivnější než porovnávání klíčových slov, protože zachycuje vztahy mezi pojmy. Například systém chápe, že „herní notebook“ a „výkonný počítač s GPU“ spolu souvisejí, i když nemají společná klíčová slova. Znalostní grafy přidávají další vrstvu tím, že vytvářejí strukturované sítě sémantických vztahů, spojují pojmy jako „notebook“ s „procesorem“, „RAM“ a „GPU“ a zvyšují porozumění. Tento víceúrovňový přístup k sémantickému porozumění umožňuje AI vyhledávačům poskytovat relevantní výsledky na složité, konverzační dotazy, se kterými mají tradiční vyhledávače potíže.
| Vyhledávací technologie | Jak funguje | Silné stránky | Omezení |
|---|---|---|---|
| Vyhledávání podle klíčových slov | Hledá přesná slova nebo fráze v dotazu a indexovaném obsahu | Rychlé, jednoduché, předvídatelné | Selhává u synonym, překlepů a složitých záměrů |
| Sémantické vyhledávání | Rozumí významu a záměru pomocí NLP a embeddingů | Zvládá synonyma, kontext a složité dotazy | Vyžaduje více výpočetních zdrojů |
| Vektorové vyhledávání | Převádí text na číselné vektory a počítá podobnost | Přesné porovnání podobnosti, škálovatelné | Zaměřuje se na matematickou vzdálenost, ne na kontext |
| Hybridní vyhledávání | Kombinuje přístup podle klíčových slov a vektorového vyhledávání | Nejlepší kombinace přesnosti a pokrytí | Složitější implementace a ladění |
| Vyhledávání podle znalostních grafů | Využívá strukturované vztahy mezi pojmy | Přidává úsudek a kontext do výsledků | Vyžaduje ruční správu a údržbu |
Jednou z největších výhod AI vyhledávačů oproti tradičním LLM je jejich schopnost získávat aktuální informace z webu v reálném čase. Když se například zeptáte ChatGPT na aktuální události, využívá bot ChatGPT-User ke skutečnému procházení webových stránek v reálném čase a získání čerstvých informací. Perplexity obdobně vyhledává na internetu v reálném čase a sbírá poznatky z předních zdrojů, proto dokáže odpovídat i na otázky týkající se událostí po datu uzávěrky svého tréninku. Google AI Overviews využívá stávající index a infrastrukturu Google, aby získal aktuální informace. Tato schopnost vyhledávání v reálném čase je zásadní pro udržení přesnosti a relevance. Proces vyhledávání zahrnuje několik kroků: nejprve systém rozloží váš dotaz na více souvisejících poddotazů procesem zvaným query fan-out, což napomáhá získání komplexnějších informací. Poté systém prohledává indexovaný webový obsah pomocí porovnávání klíčových slov i sémantiky, aby identifikoval relevantní stránky. Získané dokumenty jsou seřazeny podle relevance pomocí sémantických algoritmů řazení, které přehodnocují výsledky na základě významu, nikoliv pouze četnosti klíčových slov. Nakonec systém extrahuje nejrelevantnější pasáže z těchto dokumentů a předává je LLM pro generování odpovědi. To vše probíhá během několika sekund, proto uživatelé očekávají odpovědi AI během 3–5 sekund. Rychlost a přesnost tohoto vyhledávacího procesu přímo ovlivňuje kvalitu finální odpovědi, a efektivní vyhledávání je tedy klíčovou součástí architektury AI vyhledávačů.
Jakmile systém RAG získá relevantní informace, velký jazykový model je použije k vygenerování odpovědi. LLM nerozumí jazyku v lidském smyslu; místo toho používají statistické modely k předpovědi, která slova by měla následovat na základě vzorců naučených během tréninku. Když zadáte dotaz, LLM jej převede na vektorovou reprezentaci a zpracuje ji v neuronové síti obsahující miliony propojených uzlů. Tyto uzly si během tréninku osvojily sílu spojení zvanou váhy, které určují, jak moc se jednotlivá spojení navzájem ovlivňují. LLM nevrací jedinou předpověď pro další slovo; místo toho vrací seřazený seznam pravděpodobností. Například může předpovědět 4,5% šanci, že dalším slovem bude „učit se“, a 3,5% šanci, že to bude „předpovědět“. Systém nevybírá vždy slovo s nejvyšší pravděpodobností; někdy záměrně volí slova s nižší pravděpodobností, aby odpovědi působily přirozeněji a kreativněji. Tato náhodnost je řízena parametrem teplota (temperature), který se pohybuje od 0 (deterministické) do 1 (velmi kreativní). Po vygenerování prvního slova systém stejný proces opakuje pro slovo další, a tak dále, dokud není odpověď kompletní. Tento postup generování po jednotlivých „tokenech“ je důvodem, proč AI odpovědi někdy znějí konverzačně a přirozeně—model v podstatě předpovídá nejpravděpodobnější pokračování konverzace. Kvalita generované odpovědi závisí jak na kvalitě získaných informací, tak na vyspělosti tréninku LLM.
Různé AI vyhledávací platformy implementují tyto základní technologie různými způsoby a s odlišnými optimalizacemi. ChatGPT, vyvinutý OpenAI, drží 81 % podílu na trhu AI chatbotů a zpracovává 2 miliardy dotazů denně. ChatGPT využívá GPT modely od OpenAI v kombinaci s přístupem na web v reálném čase přes ChatGPT-User pro získání aktuálních informací. Vyniká zejména ve zpracování složitých, vícestupňových dotazů a udržení kontextu konverzace. Perplexity se odlišuje transparentními citacemi zdrojů, kdy uživatelé přesně vidí, ze kterých webů byly informace převzaty. Mezi jeho hlavní zdroje citací patří Reddit (6,6 %), YouTube (2 %) a Gartner (1 %), což odráží důraz na hledání autoritativních a různorodých zdrojů. Google AI Overviews jsou integrovány přímo do výsledků vyhledávání Google a objevují se na vrcholu stránky u mnoha dotazů. Tyto přehledy se objevují v 18 % globálních vyhledávání na Googlu a jsou poháněny modelem Gemini. Google AI Overviews jsou zvláště efektivní u informačních dotazů, přičemž 88 % dotazů, které je spouštějí, je informačního charakteru. Google’s AI Mode, samostatný vyhledávací režim spuštěný v květnu 2024, restrukturalizuje celou výsledkovou stránku kolem AI odpovědí a dosáhl 100 milionů aktivních uživatelů měsíčně v USA a Indii. Claude od Anthropicu klade důraz na bezpečnost a přesnost; uživatelé oceňují jeho schopnost poskytovat nuancované, dobře zdůvodněné odpovědi. Každá platforma dělá jiné kompromisy mezi rychlostí, přesností, transparentností zdrojů a uživatelským zážitkem, ale všechny spoléhají na základní architekturu LLM, embeddingů a RAG.
Když zadáte dotaz do AI vyhledávače, prochází sofistikovanou vícestupňovou zpracovatelskou pipeline. První fází je analýza dotazu, kdy systém rozebere vaši otázku na základní komponenty včetně klíčových slov, entit a frází. Techniky zpracování přirozeného jazyka jako tokenizace, značkování slovních druhů a rozpoznávání pojmenovaných entit identifikují, na co se ptáte. Například v dotazu „nejlepší notebooky na hraní“ systém rozpozná „notebooky“ jako hlavní entitu a „hraní“ jako hybatele záměru a odvodí, že potřebujete vysokou paměť, výkon a GPU. Druhou fází je rozšíření dotazu a fan-out, kdy systém vygeneruje více souvisejících dotazů pro získání komplexnějších informací. Místo hledání pouze „nejlepší herní notebooky“ systém zároveň hledá „specifikace herních notebooků“, „výkonné notebooky“ a „požadavky na GPU u notebooků“. Tyto paralelní vyhledávání probíhají současně a výrazně zlepšují úplnost získaných informací. Třetí fází je vyhledávání a řazení, kdy systém prohledává indexovaný obsah pomocí srovnání klíčových slov i sémantiky, a poté řadí výsledky podle relevance. Čtvrtou fází je extrakce pasáží, kdy systém identifikuje nejrelevantnější úryvky z dokumentů místo předání celých dokumentů LLM. To je zásadní, protože LLM mají omezení na počet tokenů—GPT-4 zvládne přibližně 128 000 tokenů, ale můžete mít 10 000 stránek dokumentace. Extrakcí pouze relevantních pasáží systém maximalizuje kvalitu informací předaných LLM a zároveň se vejde do omezení tokenů. Poslední fází je generování odpovědi a citace, kdy LLM vygeneruje odpověď a přidá citace použitých zdrojů. Celá pipeline musí být dokončena během několika sekund, aby splnila očekávání uživatelů na rychlost odpovědi.
Zásadní rozdíl mezi AI vyhledávači a tradičními vyhledávači, jako je Google, spočívá v jejich hlavních cílech a metodikách. Tradiční vyhledávače jsou navrženy tak, aby pomohly uživatelům najít existující informace procházením webu, indexací stránek a jejich řazením podle signálů relevance, jako jsou odkazy, klíčová slova a uživatelská interakce. Postup Googlu zahrnuje tři hlavní kroky: procházení (objevování stránek), indexace (analýza a uložení informací o stránce) a řazení (určení, které stránky jsou k dotazu nejrelevantnější). Cílem je vrátit seznam webových stránek, nikoli vytvářet nový obsah. AI vyhledávače naproti tomu generují originální, syntetické odpovědi na základě vzorců naučených z tréninkových dat a aktuálních informací získaných z webu. Přestože tradiční vyhledávače používají AI algoritmy jako RankBrain a BERT ke zlepšení řazení, nesnaží se vytvářet nový obsah. AI vyhledávače v zásadě generují nový text předpovídáním sledu slov. Tento rozdíl má zásadní dopad na viditelnost. U tradičního vyhledávání musíte být v top 10, abyste získali prokliky. U AI vyhledávání je 40 % zdrojů citovaných v AI Overviews zařazeno hůře než na 10. pozici ve výsledcích tradičního Googlu a pouze 14 % URL citovaných Google AI Mode je v tradičním vyhledávání Googlu v top 10 pro stejné dotazy. To znamená, že váš obsah může být citován v AI odpovědích, i když v tradičním vyhledávání nepatří mezi přední výsledky. Navíc zmínky o značce na webu mají korelaci 0,664 s výskytem v Google AI Overviews, což je mnohem víc než u zpětných odkazů (0,218), což naznačuje, že viditelnost a reputace značky jsou v AI vyhledávání důležitější než tradiční SEO metriky.
Oblast AI vyhledávání se rychle vyvíjí a má zásadní dopady na to, jak lidé objevují informace a jak si firmy udržují viditelnost. Předpokládá se, že návštěvnost AI vyhledávání překoná tradiční vyhledávače do roku 2028 a aktuální data ukazují, že AI platformy vygenerovaly v červnu 2025 1,13 miliardy návštěv z odkazů, což představuje nárůst o 357 % oproti červnu 2024. Důležité je, že konverzní poměr návštěv z AI vyhledávání je 14,2 %, zatímco u Googlu jen 2,8 %, což činí tento provoz mnohem hodnotnějším, i když aktuálně tvoří pouze 1 % celosvětového provozu. Trh se konsoliduje kolem několika dominantních platforem: ChatGPT má 81 % podílu na trhu AI chatbotů, Gemini od Googlu má 400 milionů aktivních uživatelů měsíčně a Perplexity má přes 22 milionů aktivních uživatelů měsíčně. Nové funkce rozšiřují schopnosti AI vyhledávání—Agent Mode ChatGPT umožňuje uživatelům delegovat složité úkoly jako rezervace letenek přímo v platformě, zatímco Instant Checkout umožňuje nákupy přímo z chatu. ChatGPT Atlas, spuštěný v říjnu 2025, přináší ChatGPT napříč webem pro okamžité odpovědi a návrhy. Tyto trendy ukazují, že AI vyhledávání se stává nejen alternativou k tradičnímu vyhledávání, ale komplexní platformou pro objevování informací, rozhodování i obchod. Pro tvůrce obsahu a marketéry tato změna znamená zásadní úpravu strategie. Místo optimalizace na klíčová slova je pro úspěch v AI vyhledávání nutné vytvářet relevantní vzory v tréninkových materiálech, budovat autoritu značky skrze zmínky a citace a zajistit, aby byl obsah aktuální, komplexní a dobře strukturovaný. Nástroje jako AmICited umožňují firmám sledovat, kde se jejich obsah objevuje napříč AI platformami, sledovat vzorce citací a měřit viditelnost v AI vyhledávání—což jsou nezbytné dovednosti pro orientaci v tomto novém prostředí.
Sledujte, kde se váš obsah objevuje v ChatGPT, Perplexity, Google AI Overviews a Claude. Získejte upozornění v reálném čase, když je vaše doména citována v AI generovaných odpovědích.
Zjistěte, jak fungují AI vyhledávací indexy, jaké jsou rozdíly mezi metodami indexace ChatGPT, Perplexity a SearchGPT, a jak optimalizovat svůj obsah pro vidite...
Zjistěte, co jsou AI vyhledávače, jak se liší od tradičního vyhledávání a jak ovlivňují viditelnost značek. Prozkoumejte platformy jako Perplexity, ChatGPT, Goo...
Zjistěte základní první kroky pro optimalizaci vašeho obsahu pro AI vyhledávače jako ChatGPT, Perplexity a Google AI Overviews. Objevte, jak strukturovat obsah,...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.