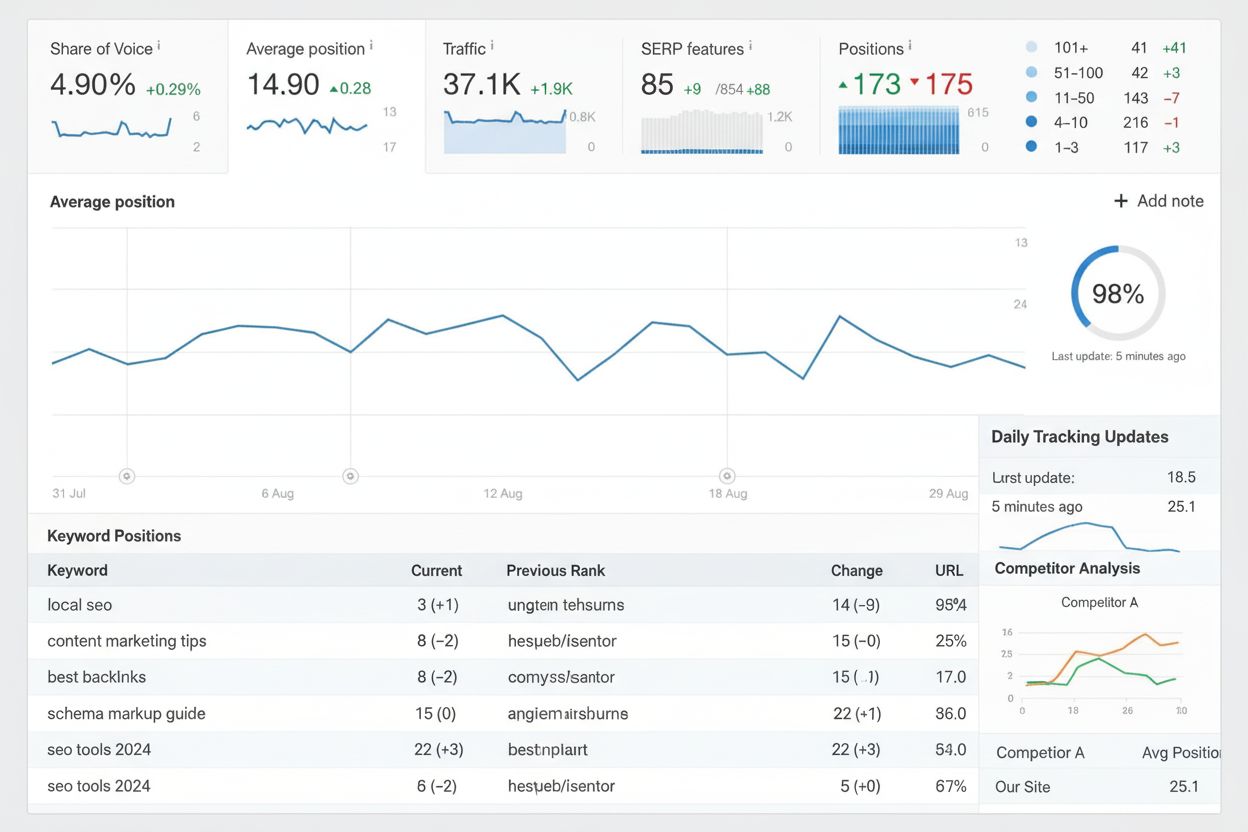
Sledování pozic
Sledování pozic monitoruje umístění klíčových slov ve výsledcích vyhledávání v čase. Zjistěte, jak funguje, proč je důležité pro SEO a jak efektivně používat ná...
9 min čtení
Mechanismus pozornosti je komponenta neuronové sítě, která dynamicky váží důležitost jednotlivých vstupních prvků a umožňuje modelům zaměřit se na nejrelevantnější části dat při provádění predikcí. Vypočítává váhy pozornosti pomocí naučených transformací dotazů, klíčů a hodnot, což umožňuje modelům hlubokého učení zachytit dlouhodobé závislosti a vztahy v sekvenčních datech s ohledem na kontext.
Mechanismus pozornosti je komponenta neuronové sítě, která dynamicky váží důležitost jednotlivých vstupních prvků a umožňuje modelům zaměřit se na nejrelevantnější části dat při provádění predikcí. Vypočítává váhy pozornosti pomocí naučených transformací dotazů, klíčů a hodnot, což umožňuje modelům hlubokého učení zachytit dlouhodobé závislosti a vztahy v sekvenčních datech s ohledem na kontext.
Mechanismus pozornosti je technika strojového učení, která navádí modely hlubokého učení, aby při predikcích upřednostnily (nebo „věnovaly pozornost“) nejrelevantnějším částem vstupních dat. Místo aby se ke všem vstupním prvkům přistupovalo stejně, mechanismy pozornosti počítají váhy pozornosti, které odrážejí relativní důležitost každého prvku pro aktuální úlohu, a tyto váhy pak dynamicky zvýrazňují či potlačují konkrétní vstupy. Tato zásadní inovace se stala základním kamenem moderních transformer architektur a velkých jazykových modelů (LLM) jako ChatGPT, Claude a Perplexity, které jim umožňují zpracovávat sekvenční data s bezprecedentní efektivitou a přesností. Mechanismus je inspirován lidskou kognitivní pozorností—schopností selektivně se zaměřit na důležité detaily a filtrovat nepodstatné informace—a tuto biologickou zásadu převádí do matematicky přesné a naučitelné komponenty neuronové sítě.
Koncept mechanismů pozornosti byl poprvé představen Bahdanauem a kolegy v roce 2014 k řešení zásadních omezení rekurentních neuronových sítí (RNN) používaných pro strojový překlad. Před zavedením pozornosti se Seq2Seq modely spoléhali na jediný kontextový vektor pro zakódování celých zdrojových vět, což vytvářelo informační úzké hrdlo a výrazně omezovalo výkon u delších sekvencí. Původní mechanismus pozornosti umožnil dekodéru přistupovat ke všem skrytým stavům enkodéru, nejen k poslednímu, a dynamicky vybírat nejrelevantnější části vstupu při každém kroku dekódování. Tento průlom dramaticky zlepšil kvalitu překladu, zejména u delších vět. V roce 2015 představili Luong a kolegové dot-product attention, která nahradila výpočetně náročnou aditivní pozornost efektivním maticovým násobením. Zlomový okamžik nastal v roce 2017 s publikací “Attention is All You Need”, která představila transformer architekturu zcela bez rekurence ve prospěch čistě mechanismů pozornosti. Tento článek způsobil revoluci v hlubokém učení a umožnil vznik modelů jako BERT, GPT a celého moderního generativního AI ekosystému. Dnes jsou mechanismy pozornosti všudypřítomné v oblasti zpracování přirozeného jazyka, počítačového vidění i multimodálních AI systémů a více než 85 % špičkových modelů využívá nějakou formu architektury založené na pozornosti.
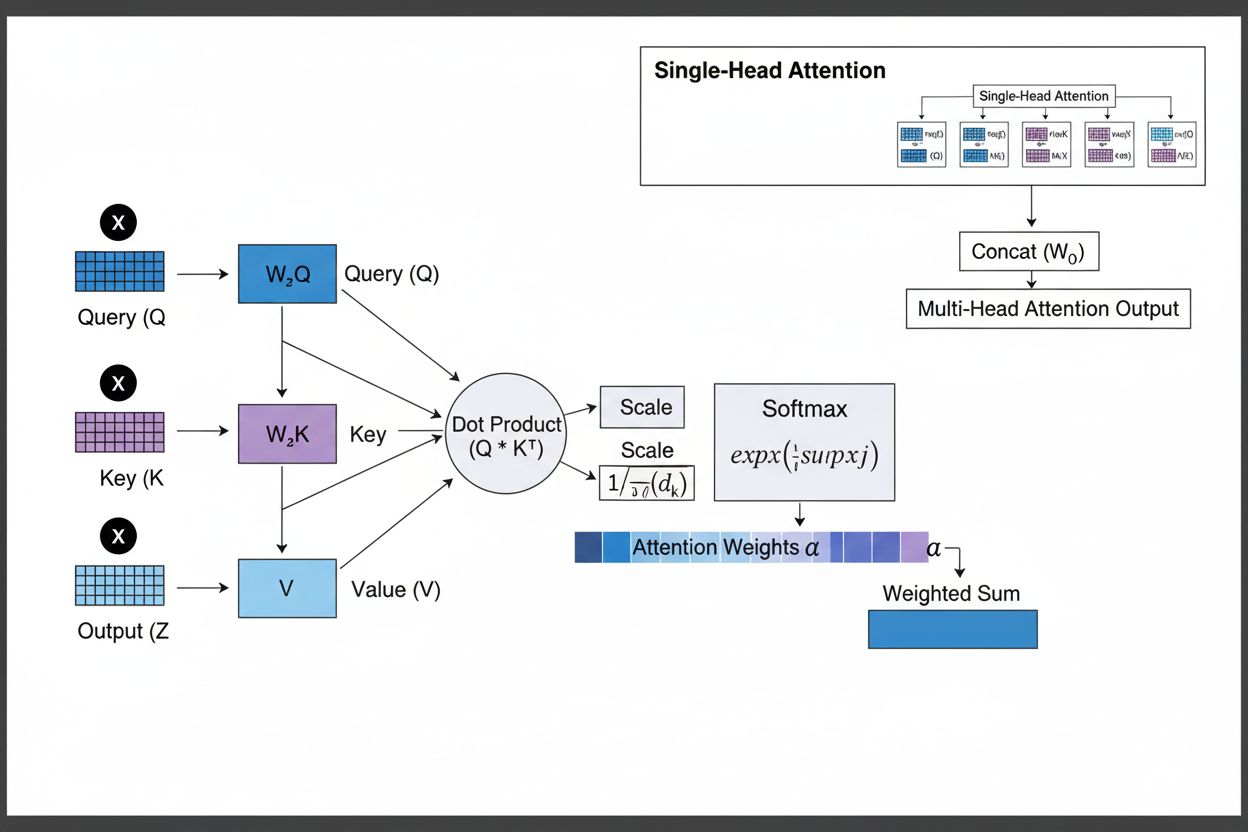
Mechanismus pozornosti funguje díky sofistikované souhře tří základních matematických komponent: dotazů (Q), klíčů (K) a hodnot (V). Každý vstupní prvek je pomocí naučených lineárních projekcí transformován do těchto tří reprezentací, čímž vzniká struktura podobná relační databázi, kde klíče slouží jako identifikátory a hodnoty obsahují samotné informace. Mechanismus počítá skóre zarovnání měřením podobnosti mezi dotazem a všemi klíči, nejčastěji pomocí škálované dot-product attention, kde se skóre vypočítává jako QK^T/√d_k. Tato surová skóre jsou pak normalizována pomocí softmax funkce, která je převádí na pravděpodobnostní rozdělení, kde součet všech vah je 1, což zajišťuje, že každý prvek dostane váhu mezi 0 a 1. Posledním krokem je výpočet váženého součtu vektorů hodnot podle těchto vah, čímž vzniká kontextový vektor, který reprezentuje nejrelevantnější informace z celé vstupní sekvence. Tento kontextový vektor je pak zkombinován s původním vstupem pomocí reziduálních spojení a prochází dopřednými vrstvami, což modelu umožňuje iterativně zpřesňovat své pochopení vstupu. Matematická elegance tohoto návrhu—kombinace naučitelných transformací, výpočtů podobnosti a pravděpodobnostního vážení—umožňuje mechanismům pozornosti zachytit komplexní závislosti a zároveň zůstat plně diferencovatelné pro optimalizaci pomocí gradientů.
| Typ pozornosti | Způsob výpočtu | Výpočetní složitost | Nejlepší použití | Klíčová výhoda |
|---|---|---|---|---|
| Aditivní pozornost | Feed-forward síť + tanh aktivace | O(n·d) na dotaz | Kratší sekvence, proměnlivé dimenze | Zvládá různé dimenze dotazu/klíče |
| Dot-Product Attention | Jednoduché maticové násobení | O(n·d) na dotaz | Standardní sekvence | Výpočetně efektivní |
| Škálovaná dot-product | QK^T/√d_k + softmax | O(n·d) na dotaz | Moderní transformery | Zabraňuje vymizení gradientu |
| Multi-Head Attention | Více paralelních hlav pozornosti | O(h·n·d), kde h=hlavy | Složité vztahy | Zachycuje rozmanité sémantické aspekty |
| Self-Attention | Dotazy, klíče, hodnoty ze stejné sekvence | O(n²·d) | Vztahy v rámci sekvence | Umožňuje paralelní zpracování |
| Cross-Attention | Dotazy z jedné sekvence, klíče/hodnoty z jiné | O(n·m·d) | Encoder-decoder, multimodální | Sladění různých modalit |
| Grouped Query Attention | Sdílí klíče/hodnoty napříč hlavami dotazů | O(n·d) | Efektivní inference | Snižuje paměť a výpočty |
| Sparse Attention | Omezená pozornost na lokální/poskočné pozice | O(n·√n·d) | Velmi dlouhé sekvence | Zvládá extrémně dlouhé sekvence |
Mechanismus pozornosti pracuje v přesně řízené posloupnosti matematických transformací, které neuronovým sítím umožňují dynamicky se zaměřovat na relevantní informace. Při zpracování vstupní sekvence je každý prvek nejprve zobrazen do vektorového prostoru s vysokou dimenzionalitou, který zachycuje sémantické a syntaktické informace. Tyto embeddingy jsou pak promítnuty do tří oddělených prostorů pomocí naučených vah: do dotazového prostoru (co model hledá), klíčového prostoru (jakou informaci každý prvek obsahuje) a prostorů hodnot (skutečná data k agregaci). Pro každou pozici dotazu mechanismus vypočítá skóre podobnosti se všemi klíči pomocí jejich skalárního součinu, čímž vznikne vektor surových zarovnávacích skóre. Tato skóre jsou škálována dělením odmocninou z dimenze klíče (√d_k), což je zásadní pro zabránění příliš vysokých hodnot dot produktů při velkých dimenzích, které by vedly k vymizení gradientu při zpětném šíření. Škálovaná skóre jsou následně prohnána softmax funkcí, která je exponencuje a normalizuje tak, aby jejich součet byl 1, což vytváří pravděpodobnostní rozdělení přes všechny vstupní pozice. Tyto váhy pozornosti se pak použijí pro výpočet váženého průměru vektorů hodnot, kdy pozice s vyššími vahami pozornosti více přispívají do výsledného kontextového vektoru. Tento kontextový vektor je následně kombinován s původním vstupem přes reziduální spojení a zpracován dopřednými vrstvami, což modelu umožňuje iterativně zpřesňovat reprezentace. Celý proces je diferencovatelný a model se může učit optimální vzory pozornosti pomocí gradientního sestupu během tréninku.
Mechanismy pozornosti tvoří základní stavební kámen transformer architektur, které se staly dominantním paradigmatem v hlubokém učení. Na rozdíl od RNN, které zpracovávají sekvence sekvenčně, a CNN, které operují na pevných lokálních oknech, využívají transformery self-attention, která umožňuje každé pozici přímo věnovat pozornost všem ostatním pozicím současně, což umožňuje masivní paralelizaci na GPU a TPU. Transformer architektura se skládá ze střídajících se vrstev multi-head self-attention a dopředných sítí, přičemž každá vrstva pozornosti umožňuje modelu upřesnit své porozumění vstupu selektivním zaměřením na různé aspekty. Multi-head attention spouští více mechanismů pozornosti paralelně, přičemž každá hlava se učí zaměřovat na jiný typ vztahů—jedna hlava může specializovat na gramatické závislosti, jiná na sémantické souvislosti a třetí například na dlouhodobé koreference. Výstupy všech hlav jsou spojeny a projektovány, což umožňuje modelu současně sledovat více jazykových jevů. Tato architektura se ukázala jako mimořádně účinná pro velké jazykové modely jako GPT-4, Claude 3 a Gemini, které využívají pouze dekodérové transformer architektury, kde každý token může věnovat pozornost pouze předchozím tokenům (tzv. kauzální maskování), aby byla zachována autoregresivní vlastnost generování. Schopnost mechanismu pozornosti zachytit dlouhodobé závislosti bez problémů vymizení gradientu, které trápily RNN, byla klíčová pro to, že tyto modely mohou zpracovávat kontextová okna o velikosti i 100 000+ tokenů a zachovat soudržnost a konzistenci v rozsáhlých textech. Výzkumy ukazují, že přibližně 92 % špičkových NLP modelů nyní spoléhá na transformer architektury poháněné mechanismy pozornosti, což dokládá jejich zásadní význam pro moderní AI systémy.
V kontextu AI vyhledávacích platforem jako ChatGPT, Perplexity, Claude a Google AI Overviews hrají mechanismy pozornosti klíčovou roli při určování, které části získaných dokumentů a znalostních bází jsou nejrelevantnější pro uživatelský dotaz. Při generování odpovědí tyto systémy dynamicky váží různé zdroje a pasáže na základě relevance, což jim umožňuje syntetizovat koherentní odpovědi z více zdrojů a zároveň zachovávat faktickou správnost. Váhy pozornosti vypočtené během generování lze analyzovat pro pochopení toho, jaké informace model upřednostnil, což poskytuje vhled do toho, jak AI systémy interpretují a reagují na dotazy. Pro monitoring značek a GEO (Generative Engine Optimization) je porozumění mechanismům pozornosti zásadní, protože právě ony určují, který obsah a zdroje dostanou v AI-generovaných odpovědích důraz. Obsah strukturovaný v souladu se způsobem, jakým mechanismy pozornosti váží informace—jasné definice entit, autoritativní zdroje a kontextová relevance—má větší šanci být citován a zobrazen na předních místech v AI odpovědích. AmICited využívá poznatky o mechanismech pozornosti ke sledování výskytu značek a domén napříč AI platformami, přičemž rozpoznává, že citace vážené pozorností jsou nejvlivnější zmínky v AI-generovaném obsahu. Jak podniky stále více monitorují svou přítomnost v AI odpovědích, porozumění tomu, že mechanismy pozornosti určují vzory citací, se stává klíčovým pro optimalizaci obsahové strategie a zajištění viditelnosti značky v generativní AI éře.
Oblast mechanismů pozornosti se rychle vyvíjí a výzkumníci vyvíjejí stále sofistikovanější varianty ke zmírnění výpočetních omezení a zvýšení výkonu. Sparse attention omezuje pozornost na lokální sousedství nebo poskočné pozice, čímž snižuje složitost z O(n²) na O(n·√n) při zachování výkonu u velmi dlouhých sekvencí. Efektivní mechanismy pozornosti jako FlashAttention optimalizují přístup k paměti během výpočtu pozornosti a dosahují 2-4x zrychlení díky lepšímu využití GPU. Grouped query attention a multi-query attention snižují počet hlav klíčů a hodnot při zachování výkonu, což významně snižuje paměťové nároky při inferenci—zásadní pro nasazení velkých modelů v produkci. Architektury Mixture of Experts kombinují pozornost s řídkým směrováním, což umožňuje modelům škálovat až na biliony parametrů a přitom zůstat efektivní. Nový výzkum zkoumá naučené vzory pozornosti, které se dynamicky přizpůsobují charakteru vstupu, a hierarchickou pozornost fungující na více úrovních abstrakce. Integrace mechanismů pozornosti s retrieval-augmented generation (RAG) umožňuje modelům dynamicky věnovat pozornost relevantním externím znalostem, zvyšuje faktickou správnost a snižuje halucinace. Jak jsou AI systémy nasazovány v kritických aplikacích, mechanismy pozornosti jsou doplňovány prvky vysvětlitelnosti, které poskytují lepší vhled do rozhodování modelu. Budoucnost pravděpodobně přinese hybridní architektury kombinující pozornost s alternativními mechanismy jako state-space modely (například Mamba), které nabízejí lineární složitost při zachování konkurenceschopného výkonu. Porozumění těmto vyvíjejícím se mechanismům pozornosti je zásadní pro odborníky budující AI nové generace i pro organizace sledující svůj výskyt v AI-generovaném obsahu, protože mechanismy určující vzory citací a zvýraznění obsahu se neustále zdokonalují.
Pro organizace využívající AmICited ke sledování viditelnosti značky v AI odpovědích poskytuje pochopení mechanismů pozornosti klíčový kontext pro interpretaci vzorů citací. Když ChatGPT, Claude nebo Perplexity citují vaši doménu ve svých odpovědích, váhy pozornosti vypočítané během generování určily, že váš obsah je pro dotaz uživatele nejrelevantnější. Kvalitní, dobře strukturovaný obsah, který jasně definuje entity a poskytuje autoritativní informace, přirozeně dostává vyšší váhy pozornosti a je tak pravděpodobněji vybrán k citaci. Vizualizace pozornosti v některých AI platformách ukazují, které zdroje získaly při generování odpovědi největší pozornost, a tedy které citace byly nejvlivnější. Tento vhled umožňuje organizacím optimalizovat svou obsahovou strategii s vědomím, že mechanismy pozornosti upřednostňují jasnost, relevanci a autoritativní zdroje. Jak AI vyhledávání roste—a více než 60 % podniků nyní investuje do generativních AI iniciativ—je schopnost porozumět a optimalizovat pro mechanismy pozornosti stále cennější pro udržení viditelnosti značky a zajištění přesné reprezentace v AI-generovaném obsahu. Průnik mechanismů pozornosti a monitoringu značky představuje novou oblast GEO, kde pochopení matematických základů toho, jak AI systémy váží a citují informace, přímo vede ke zvýšené viditelnosti a vlivu v generativním AI ekosystému.
Tradiční RNN zpracovávají sekvence sériově, což ztěžuje zachycení dlouhodobých závislostí, zatímco CNN mají pevná lokální zorná pole, která omezují jejich schopnost modelovat vzdálené vztahy. Mechanismy pozornosti tyto limity překonávají tím, že počítají vztahy mezi všemi vstupními pozicemi současně, což umožňuje paralelní zpracování a zachycení závislostí bez ohledu na vzdálenost. Tato flexibilita v čase i prostoru činí mechanismy pozornosti výrazně efektivnějšími a účinnějšími pro komplexní sekvenční a prostorová data.
Dotazy představují, jakou informaci model aktuálně hledá, klíče reprezentují obsah informací, které každý vstupní prvek obsahuje, a hodnoty uchovávají skutečná data, která se mají agregovat. Model vypočítává skóre podobnosti mezi dotazy a klíči, aby určil, které hodnoty by měly být nejvýše váženy. Tato terminologie inspirovaná databázemi, kterou popularizoval článek 'Attention is All You Need', poskytuje intuitivní rámec pro pochopení toho, jak mechanismy pozornosti selektivně vyhledávají a kombinují relevantní informace ze vstupních sekvencí.
Self-attention počítá vztahy v rámci jedné vstupní sekvence, kde dotazy, klíče a hodnoty pocházejí ze stejného zdroje, což umožňuje modelu pochopit, jak jsou různé prvky mezi sebou propojeny. Naproti tomu cross-attention používá dotazy z jedné sekvence a klíče/hodnoty z jiné sekvence, což modelu umožňuje sladit a kombinovat informace z více zdrojů. Cross-attention je zásadní v architekturách typu encoder-decoder, například při strojovém překladu, a v multimodálních modelech jako Stable Diffusion, které kombinují textové a obrazové informace.
Škálovaná dot-product pozornost používá pro výpočet zarovnávacích skóre násobení místo sčítání, což je výpočetně efektivnější díky maticovým operacím využívajícím paralelizaci na GPU. Škálovací faktor 1/√dk zabraňuje tomu, aby dot produkty byly při vysoké dimenzi klíčů příliš velké, což by způsobovalo vymizení gradientů při zpětném šíření. Ačkoliv aditivní pozornost někdy překonává dot-product pozornost u velmi vysokých dimenzí, škálovaná dot-product pozornost je díky své výpočetní efektivitě a praktickému výkonu standardní volbou v moderních transformerech.
Multi-head attention spouští více mechanismů pozornosti paralelně, přičemž každá hlava se učí soustředit na různé aspekty vstupu, například gramatické vztahy, sémantický význam nebo dlouhodobé závislosti. Každá hlava pracuje s různými lineárními projekcemi vstupu, což modelu umožňuje současně zachytit rozmanité typy vztahů. Výstupy všech hlav jsou spojeny a dále projektovány, což modelu umožňuje udržet komplexní povědomí o více jazykových a kontextových rysech zároveň a výrazně vylepšit kvalitu reprezentace i výkon v navazujících úlohách.
Softmax normalizuje surová zarovnávací skóre vypočítaná mezi dotazy a klíči do pravděpodobnostního rozdělení, kde součet všech vah je 1. Tato normalizace zajišťuje, že váhy pozornosti lze interpretovat jako skóre důležitosti, přičemž vyšší hodnoty znamenají větší relevanci. Funkce softmax je diferencovatelná, což umožňuje učení mechanismu pozornosti pomocí gradientů během tréninku, a její exponenciální povaha zvýrazňuje rozdíly mezi skóre, což činí zaměření modelu selektivnější a lépe interpretovatelné.
Mechanismy pozornosti umožňují těmto modelům dynamicky vážit různé části vstupního promptu na základě relevance k aktuálnímu kroku generování. Při generování odpovědi model využívá pozornost k určení, které předchozí tokeny a vstupní prvky by měly nejvíce ovlivnit predikci dalšího tokenu. Toto vážení s ohledem na kontext modelům umožňuje zachovat koherenci, sledovat entity v dlouhých textech, řešit nejednoznačnost a generovat odpovědi, které správně odkazují na specifické části vstupu, což zvyšuje přesnost a kontextovou vhodnost jejich výstupů.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Sledování pozic monitoruje umístění klíčových slov ve výsledcích vyhledávání v čase. Zjistěte, jak funguje, proč je důležité pro SEO a jak efektivně používat ná...
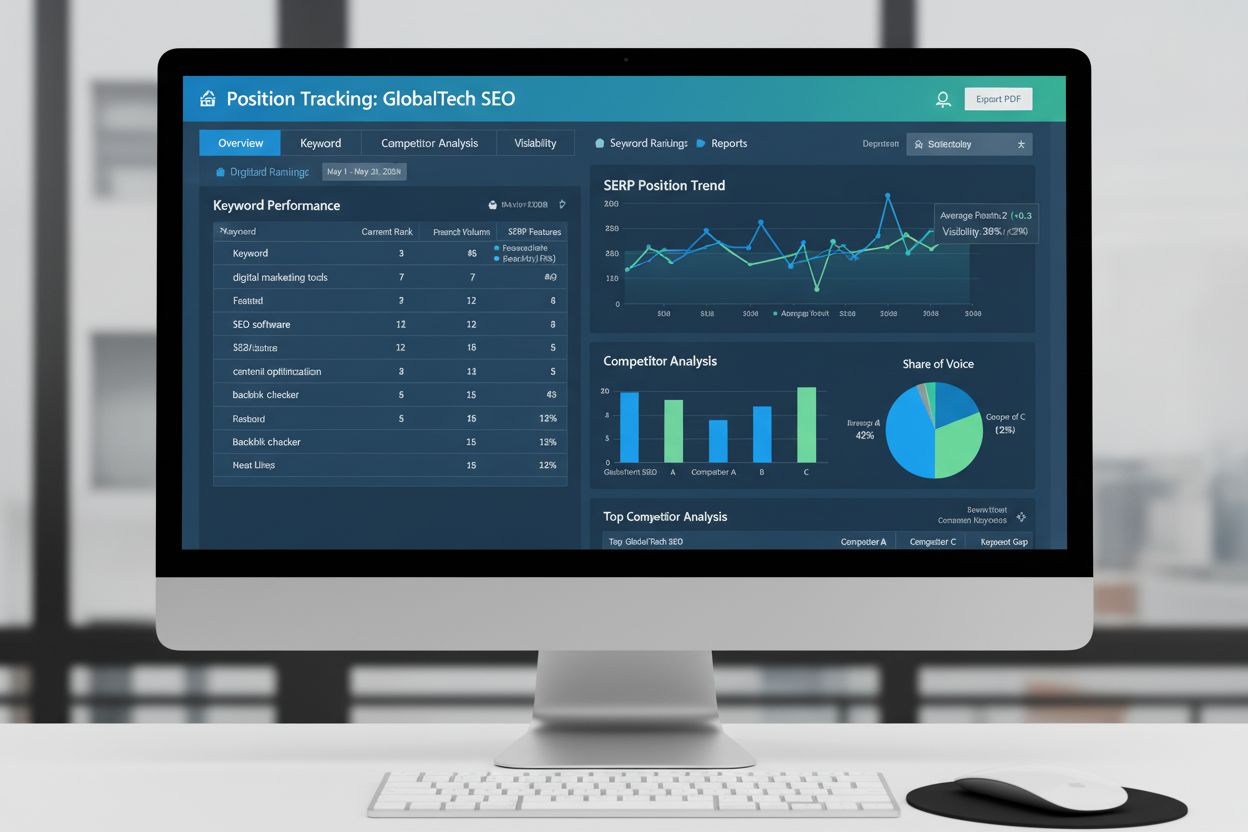
Sledování pozic monitoruje pořadí klíčových slov napříč SERP k měření výkonu SEO. Zjistěte, jak sledovat pozice, klíčové metriky a proč je to důležité pro vidit...

Zjistěte, jak sledování přesunu podílu viditelnosti v AI monitoruje okamžiky, kdy se viditelnost vaší značky v AI odpovědích přesouvá mezi konkurenty. Objevte m...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.