Definice kanonické URL
Kanonická URL je primární, preferovaná nebo autoritativní verze webové stránky, kterou určujete pro vyhledávače k procházení, indexaci a hodnocení v případech, kdy více URL obsahuje identický či velmi podobný obsah. Termín „kanonická“ vychází z konceptu stanovení jediného autoritativního zdroje mezi více variantami. V kontextu optimalizace pro vyhledávače a webové architektury slouží kanonická URL jako hlavní kopie, která konsoliduje signály pro hodnocení, hodnotu odkazů i indexační autoritu ze všech duplicitních nebo téměř duplicitních verzí téhož obsahu. Toto rozlišení je klíčové, protože vyhledávače jako Google, Bing a stále častěji také AI vyhledávače typu ChatGPT, Perplexity a Claude považují každou unikátní URL za samostatnou stránku, i když je obsah totožný. Tím, že explicitně určíte kanonickou URL pomocí HTML tagu rel="canonical" nebo jiných metod kanonizace, sdělujete vyhledávačům svou preferenci a zajišťujete, že správná verze získá prioritu v indexaci i hodnocení.
Kontext a pozadí
Koncept kanonických URL vznikl s vývojem webových technologií a narůstající složitostí webů. V počátcích internetu měly většinu webů jednoduché struktury URL s minimem duplikací. S rozmachem redakčních systémů (CMS), e-commerce platforem a dynamických webových aplikací však problém neúmyslného duplicitního obsahu výrazně narostl. Podle výzkumů předních SEO platforem více než 30 % webových stránek obsahuje významné problémy s duplicitním obsahem, často bez vědomí webmastera. K této duplicitě dochází různými mechanismy: parametry v URL sloužícími ke sledování a filtrování, více verzemi protokolu (HTTP vs HTTPS), doménovými variantami (www vs bez www), mobilními URL, session ID nebo stránkovacími parametry. John Mueller z Googlu zdůrazňuje, že kanonické tagy jsou nezbytné pro sdělení struktury webu vyhledávačům, zejména když web generuje více URL pro stejný obsah. Specifikace rel="canonical" byla formálně představena Googlem, Yahoo a Microsoftem v roce 2009 jako standardizovaná metoda pro webmastery k určení preferovaných URL. Od té doby se kanonické URL staly základním prvkem technického SEO a více než 78 % podnikových webů implementuje kanonické tagy v rámci své SEO strategie. Význam kanonických URL dále roste s nástupem AI vyhledávačů a generativních AI systémů, které pro správné přiřazení obsahu a vyhnutí se indexaci duplicitních verzí spoléhají na správnou kanonizaci.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Jak fungují kanonické URL: Technický proces
Proces kanonizace probíhá prostřednictvím systematického postupu, který vyhledávače následují při nalezení více URL s totožným nebo podobným obsahem. Jakmile crawler navštíví váš web, identifikuje stránky, které obsahují stejný nebo téměř stejný obsah napříč různými URL. Poté hledá signály kanonizace, aby určil, která verze má být považována za hlavní stránku. Mezi tyto signály patří HTML tag rel="canonical" umístěný v sekci <head>, HTTP hlavičky s informací o kanonické URL, 301 redirecty, vzorce interního prolinkování, záznamy v XML sitemapě a preference HTTPS. Nejvýraznějším a nejsilnějším signálem je prvek rel="canonical", který v HTML vypadá například takto: <link rel="canonical" href="https://www.example.com/preferred-url" />. Pokud vyhledávače tento tag najdou, rozumí tomu, že URL uvedená v atributu href je kanonická verze. Crawler poté konsoliduje všechny signály pro hodnocení – včetně zpětných odkazů, interních odkazů, metrik zapojení uživatelů i autority obsahu – do kanonické URL. Tato konsolidace je klíčová, protože zabraňuje rozmělnění síly hodnocení mezi více duplicitními URL. Například pokud je vaše produktová stránka dostupná přes pět různých URL díky sledovacím parametrům a doménovým variantám a každá URL získá nezávisle zpětné odkazy, tyto odkazy by si navzájem konkurovaly. Správnou kanonizací proudí veškerá síla odkazů do jedné kanonické URL, čímž výrazně posilujete její potenciál v žebříčku vyhledávačů. Výzkumy ukazují, že správná kanonizace může zlepšit viditelnost ve vyhledávání o 15–30 % u webů s výraznými problémy s duplicitním obsahem.
Kanonická URL vs příbuzné pojmy: Srovnávací tabulka
| Aspekt | Kanonická URL (rel=“canonical”) | 301 Redirect | Zařazení do sitemap | Blokování v robots.txt |
|---|
| Účel | Označuje preferovanou verzi při zachování přístupu k duplicitám | Trvale přesouvá jednu URL na druhou | Navrhuje kanonické URL vyhledávačům | Zabraňuje procházení duplicitních stránek |
| Uživatelská zkušenost | Uživatelé mají přístup jak ke kanonické, tak k duplicitním URL | Uživatelé jsou automaticky přesměrováni na novou URL | Bez přímého vlivu na uživatele | Uživatelé nemohou přistupovat k blokovaným URL |
| Síla signálu pro vyhledávače | Silný signál; konsoliduje sílu hodnocení | Nejsilnější signál; úplná konsolidace URL | Slabý signál; Google sám určuje duplicity | Nedoporučuje se pro kanonizaci |
| Složitost implementace | Střední; úprava HTML nebo nastavení CMS | Střední; serverová konfigurace | Snadné; přidání URL do sitemap | Snadné; pravidla v robots.txt |
| Ideální použití | Duplicitní obsah, který musí zůstat dostupný | Vyřazení starých URL nebo migrace webu | Velké weby s mnoha kanonickými URL | Blokace testovacích/provozních prostředí |
| Konsolidace síly odkazů | Ano; signály proudí do kanonické URL | Ano; úplný převod na novou URL | Částečná; záleží na posouzení Googlu | Ne; zcela blokuje procházení |
| Reverzibilita | Ano; lze změnit nebo odebrat | Obtížné; vyžaduje nové přesměrování | Ano; lze aktualizovat v sitemapě | Ano; lze odebrat z robots.txt |
| Dopad na crawl budget | Střední; snižuje zbytečné procházení duplicit | Vysoký; eliminuje procházení starých URL | Nízký; stále prochází všechny URL v sitemapě | Vysoký; zabrání procházení duplicit |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technická implementace kanonických URL
Implementace kanonických URL vyžaduje pochopení dostupných metod a volbu postupu, který nejlépe odpovídá architektuře vašeho webu a použitému redakčnímu systému. Prvek rel="canonical" je nejběžnější metodou, umístěnou přímo v sekci <head> HTML duplicitních stránek. Tento tag by měl odkazovat na absolutní URL (včetně protokolu a domény) kanonické verze. Například na produktové stránce dostupné přes více URL přidáte: <link rel="canonical" href="https://www.example.com/products/blue-shoes" /> ke všem duplicitním verzím. Kanonická URL by měla být čistá a přístupná adresa bez sledovacích parametrů, session ID nebo zbytečných query stringů. Self-referenční kanonické tagy – kdy stránka odkazuje sama na sebe – jsou stále častěji doporučovány jako nejlepší praxe. Tím posilujete pro vyhledávače informaci o správné URL i u unikátních stránek a předcházíte náhodným problémům s kanonizací. Pro ne-HTML obsah, jako jsou PDF, Word dokumenty nebo jiné typy souborů, je vhodnější metoda kanonické HTTP hlavičky. Ta spočívá v nastavení serveru na odeslání Link hlavičky v HTTP odpovědi: Link: <https://www.example.com/document.pdf>; rel="canonical". Tato metoda je zvláště užitečná pro weby, které publikují obsah ve více formátech na různých URL. 301 redirecty jsou dalším silným signálem kanonizace, zejména když chcete plně konsolidovat URL a odstranit starou verzi z výsledků vyhledávání. Pokud je stránka A přesměrována s kódem 301 na stránku B, vyhledávače chápou stránku B jako kanonickou a převedou na ni všechny signály pro hodnocení. XML sitemapy poskytují slabší, avšak stále užitečný signál tím, že uvádějí pouze kanonické URL, které chcete indexovat. Dále je preference HTTPS automatickým signálem, kdy Google upřednostňuje HTTPS před HTTP, proto se ujistěte, že vaše kanonické URL používají HTTPS.
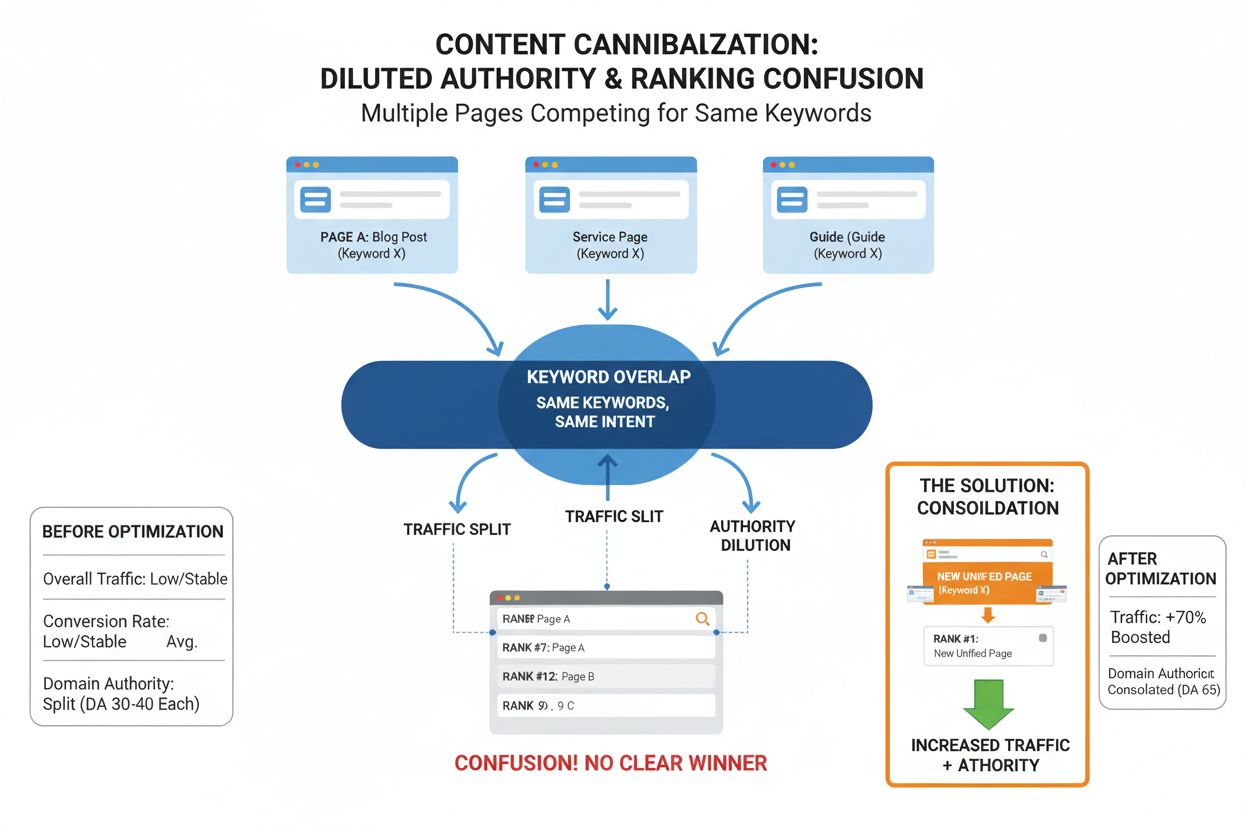
Kanonické URL a prevence duplicitního obsahu
Duplicitní obsah představuje jednu z největších výzev v současné správě webu a podle průzkumů zasahuje přibližně 29 % všech indexovaných stránek. Duplicitní obsah vzniká mnoha způsoby: e-shopy generují jedinečné URL pro stejný produkt díky filtrům a řazení, blogy mají archivní a kategoriální stránky se stejnými články, při syndikaci obsahu na více doménách, existencí mobilních i desktopových URL nebo náhodnými duplikáty z testovacích prostředí. Bez správné kanonizace musí vyhledávače samy rozhodnout, kterou verzi indexovat, což často neodpovídá vašim obchodním cílům. Může dojít ke kanibalizaci klíčových slov, kdy si různé verze stejného obsahu navzájem konkurují pro stejná klíčová slova, což rozděluje sílu hodnocení a snižuje celkovou viditelnost. Kanonické URL tento problém řeší tím, že jasně sdělují vaši preferenci vyhledávačům. Pokud určíte kanonickou URL, vyhledávače všechny duplicitní verze považují za varianty jednoho obsahu a konsolidují signály hodnocení do této kanonické verze. To je zvláště důležité pro distribuci síly odkazů. Pokud vaše webová stránka získává zpětné odkazy na různé varianty stejného obsahu, tyto odkazy by se běžně počítaly odděleně a rozdělovaly sílu hodnocení. S kanonickými tagy proudí veškerá síla odkazů do jedné kanonické URL, což vytváří silnější signál pro vyhledávače. Například pokud je vaše homepage dostupná jako https://www.example.com, https://example.com, http://www.example.com a http://example.com a každá verze získává nezávisle zpětné odkazy, kanonické tagy zajistí, že se veškerá autorita konsoliduje do preferované verze. Tato konsolidace může znamenat zlepšení pozic ve vyhledávání o 15–30 % u stránek s výraznými duplicitními problémy.
Kanonické URL v e-commerce a dynamickém obsahu
E-shopy čelí obzvlášť složitým výzvám v kanonizaci kvůli povaze produktových stránek a systémů filtrování. Jeden produkt může být dostupný přes více URL: přímá produktová URL, URL s filtry barvy nebo velikosti, adresy s parametry řazení, URL s marketingovými sledovacími kódy i mobilní verze. Bez správné kanonizace mohou vyhledávače indexovat desítky variant téže produktové stránky, což vede ke ztrátě crawl budgetu i rozmělnění síly hodnocení. E-shopy po implementaci správné kanonizace hlásí 20–40% nárůst organické návštěvnosti díky konsolidaci signálů. Kanonická URL produktu by měla být čistá produktová adresa bez parametrů: https://www.example.com/products/blue-running-shoes. Všechny varianty s filtry, tříděním či sledováním by měly obsahovat kanonický tag odkazující na tuto čistou URL. Redakční systémy jako Magento, Shopify nebo WooCommerce často poskytují vestavěné funkce pro automatické generování kanonických tagů, někdy je však nutné jejich správné fungování nastavit. Shopify přidává kanonické tagy automaticky na produktové a kolekční stránky, ale vlastní implementace může vyžadovat manuální konfiguraci. Magento poskytuje možnost povolit kanonické tagy pro produkty i kategorie, ale u kategorií je třeba postupovat opatrně, aby nedošlo k nechtěné konsolidaci. WordPress s pluginy typu Yoast SEO nebo Rank Math generuje kanonické tagy automaticky s možností jejich individuální úpravy. Klíčovou zásadou pro e-commerce je zajistit, aby veškeré produktové varianty – ať už přes filtry, řazení či sledovací parametry – odkazovaly na jedinou kanonickou produktovou URL, což umožňuje správnou indexaci a konsolidaci signálů.
Kanonické URL a optimalizace pro AI vyhledávače
Nástup AI vyhledávačů a generativních AI systémů přinesl nové rozměry významu kanonických URL. Platformy jako ChatGPT, Perplexity, Claude a Google AI Overviews spoléhají při generování odpovědí na procházení webu a indexaci obsahu. Když tyto AI systémy narazí na více URL s totožným obsahem, správná kanonizace jim pomáhá určit autoritativní zdroj, který budou citovat ve svých odpovědích. Více než 60 % podniků se dnes zajímá o to, jak je jejich obsah prezentován v AI-generovaných odpovědích, což činí správu kanonických URL stále důležitější pro viditelnost a připsání značky. Pokud AI systém narazí na více URL se stejným obsahem, musí rozhodnout, kterou verzi bude citovat jako zdroj. Bez kanonických tagů může AI citovat nekanonickou verzi, což uživatele přesměruje na méně vhodnou stránku nebo nezajistí správné připsání značky. Správnou kanonizací zajistíte, že AI systémy budou citovat vaši preferovanou URL, čímž zlepšíte uživatelskou zkušenost i konzistentnost značky. To je obzvlášť důležité pro sledování a monitoring AI citací, kde platformy jako AmICited pomáhají organizacím sledovat, jak se jejich obsah objevuje v AI odpovědích. Správnou implementací kanonických tagů zvyšujete šanci, že se vaše preferovaná URL objeví v AI citacích a zvýšíte viditelnost v prostředí AI vyhledávání. Kanonické URL také pomáhají AI systémům pochopit strukturu vašeho webu a hierarchii obsahu, což umožňuje přesnější a relevantnější citace. S tím, jak AI vyhledávání roste – Perplexity uvádí přes 500 milionů aktivních uživatelů měsíčně a ChatGPT rozšiřuje své vyhledávací funkce – je správná kanonizace zásadní pro udržení viditelnosti a připsání v AI obsahu.
Osvědčené postupy implementace kanonických URL
Efektivní implementace kanonických URL vyžaduje dodržování osvědčených postupů, které zajistí, že vyhledávače i AI systémy správně rozpoznají a respektují vaše signály kanonizace. Používejte absolutní URL místo relativních v kanonických tagách, vždy včetně protokolu a domény: <link rel="canonical" href="https://www.example.com/page" /> místo <link rel="canonical" href="/page" />. Relativní URL mohou způsobovat problémy, například pokud je omylem procházeno testovací prostředí nebo se změní struktura URL. Zajistěte konzistenci napříč všemi signály kanonizace – vaše kanonické tagy, interní odkazy, položky v XML sitemapě i 301 redirecty by měly vždy odkazovat na stejnou URL. Konfliktní signály matou vyhledávače a snižují efektivitu kanonizace. Vyvarujte se kanonických řetězců, kdy stránka A ukazuje na B a B ukazuje na C – vyhledávače nemusí tyto řetězce správně sledovat. Nikdy neodkazujte kanonickými tagy na přesměrované URL nebo stránky blokované robots.txt či označené noindexem, protože tím vytváříte konfliktní signály, které vyhledávače těžko interpretují. Implementujte self-referenční kanonické tagy na všechny stránky, včetně těch, které jsou samy kanonické. Tím posilujete správný výklad kanonizace vyhledávači a předcházíte náhodným problémům. Používejte HTTPS v kanonických URL, pokud váš web podporuje HTTPS, protože vyhledávače preferují zabezpečené verze. Dbejte na konzistentní formátování URL z hlediska závěrečného lomítka, www prefixů a velikosti písmen. Například zvolte, zda vaše kanonické URL budou obsahovat závěrečné lomítko (https://example.com/page/) nebo ne (https://example.com/page) a postupujte tak jednotně na celém webu. Pravidelně auditujte své kanonické tagy pomocí nástrojů jako Google Search Console, Moz Pro Site Crawl nebo Semrush Site Audit, abyste odhalili chybějící, nefunkční nebo konfliktní kanonické tagy. Testujte implementaci pomocí vývojářských nástrojů v prohlížeči nebo SEO nástrojů a ověřte, že kanonické tagy jsou správně umístěny v HTML head a odkazují na správné URL.
Běžné chyby u kanonických URL a jak se jim vyhnout
Přestože jsou kanonické URL nesmírně důležité, mnoho webů je implementuje nesprávně, což snižuje jejich účinnost nebo dokonce poškozuje SEO. Jednou z nejčastějších chyb je odkazování kanonických tagů na neexistující nebo nefunkční URL. Tím vzniká situace, kdy vyhledávače dostávají konfliktní signály – kanonický tag ukazuje na URL, která vrací chybu 404 nebo je blokována pro indexaci. Vždy ověřte, že vaše kanonické URL jsou dostupné, vracejí kód 200 a nejsou blokovány robots.txt nebo noindexem. Další častou chybou je používání kanonických tagů pro ne-duplikátní obsah. Kanonické tagy mají být používány pouze pro duplicitní nebo téměř totožný obsah. Někteří SEO specialisté se mylně snaží konsolidovat sílu hodnocení z odlišných stránek, například přesměrováním autority ze stránek nedostupných produktů na kategorie. Google tento postup nedoporučuje a pravděpodobně takové kanonické tagy ignoruje. Kanonické řetězce jsou dalším závažným problémem – kdy stránka A ukazuje na B, B na C atd. Vyhledávače nemusí tyto řetězce správně sledovat, což vede ke špatné kanonizaci. Vždy zajistěte, aby kanonické tagy ukazovaly přímo na finální kanonickou URL. Konfliktní signály kanonizace vznikají, když různé metody ukazují na různé URL – například kanonický tag ukazuje na jednu URL, ale 301 redirect na jinou. Vyhledávače pak mohou ignorovat oba signály. Zajistěte, aby všechny metody – kanonické tagy, redirecty, sitemapy i interní odkazy – ukazovaly na stejnou URL. Umístění kanonických tagů mimo HTML head zabrání vyhledávačům v jejich nalezení. Kanonické tagy musí být v sekci <head>. Používání relativních URL místo absolutních může způsobit problémy zvláště při změnách struktury webu nebo procházení testovacích prostředí. Vždy používejte úplnou adresu včetně protokolu a domény. Opomenutí self-referenčních kanonických tagů na samotných kanonických stránkách může způsobit náhodné problémy s kanonizací. Každá stránka, i ta kanonická, by měla mít tag ukazující sama na sebe. Nevhodné kombinování kanonických a hreflang tagů na vícejazyčných webech může vést ke zmatkům – každá jazyková verze má mít svůj vlastní kanonický tag ukazující na sebe a hreflang tagy s odkazy na všechny jazykové varianty.
Kanonické URL a optimalizace crawl budgetu
Crawl budget – počet stránek, které vyhledávače během určité doby na vašem webu projdou – je omezený zdroj, zvláště u rozsáhlých webů. Weby s výrazným duplicitním obsahem mohou promarnit 20–40 % svého crawl budgetu na stránky, které vůbec není nutné indexovat. Kanonické URL pomáhají optimalizovat crawl budget tím, že vyhledávačům signalizují, které stránky mají smysl procházet a indexovat. Správně implementované kanonické tagy napovídají vyhledávačům, že duplicitní stránky není třeba procházet tak důkladně, což umožňuje věnovat více crawl budgetu unikátním a hodnotným stránkám. To je zvlášť důležité pro velké e-shopy s tisíci produktových variant, zpravodajské weby s více formáty článků a obsahové platformy s rozsáhlými archivy tagů a kategorií. Konsolidací duplicitních URL pomocí kanonizace zajistíte, že vyhledávače věnují crawl budget stránkám, které jsou pro váš byznys nejdůležitější. Výsledkem může být rychlejší indexace nového obsahu, častější procházení důležitých stránek a zlepšená celková viditelnost ve vyhledávání. Navíc správná kanonizace snižuje počet URL v Google Search Console a usnadňuje správu a monitoring výkonu webu ve vyhledávání. Pro weby s omezeným crawl budgetem – zejména menší weby nebo ty v konkurenčních odvětvích – může optimalizace prostřednictvím kanonizace mít měřitelný dopad na pozice a viditelnost.
Budoucnost kanonických URL v AI vyhledávání
Jak se vyhledávací prostředí vyvíjí s nástupem AI vyhledávačů a generativních AI systémů, role kanonických URL stále roste. Trh s AI vyhledáváním má vzrůst z 5,2 miliardy dolarů v roce 2024 na více než 15 miliard dolarů do roku 2030, přičemž platformy jako Perplexity, ChatGPT a Claude získávají významný podíl. Tyto AI systémy spoléhají na webové crawling a indexaci obsahu podobně jako tradiční vyhledávače, což činí kanonické URL nezbytnými pro správné připsání a viditelnost obsahu. Budoucnost kanonických URL pravděpodobně přinese užší integraci se systémy pro sledování a monitoring citací v AI. Platformy jako AmICited již dnes umožňují sledovat, jak je obsah prezentován v AI odpovědích, a kanonické URL v tom budou hrát klíčovou roli. S rostoucí sofistikovaností AI systémů lze očekávat lepší metody pro rozpoznání kanonických URL a konsolidaci informací z různých zdrojů. Nástup federovaného vyhledávání a multi-source AI systémů, které kombinují výsledky z více vyhledávačů a datových zdrojů, dále zvýší důležitost kanonických URL pro konzistentní prezentaci obsahu napříč platformami. Organizace, které správně implementují kanonické URL již dnes, budou lépe připraveny udržet viditelnost a připsání v prostředí AI vyhledávání budoucnosti. Se zpřísňujícími se pravidly ochrany soukromí a požadavky na připsání obsahu mohou být kanonické URL brzy standardním požadavkem v licenčních a syndikačních smlouvách. Integrace kanonických URL se strukturovanými daty a sémantickými webovými technologiemi umožní ještě