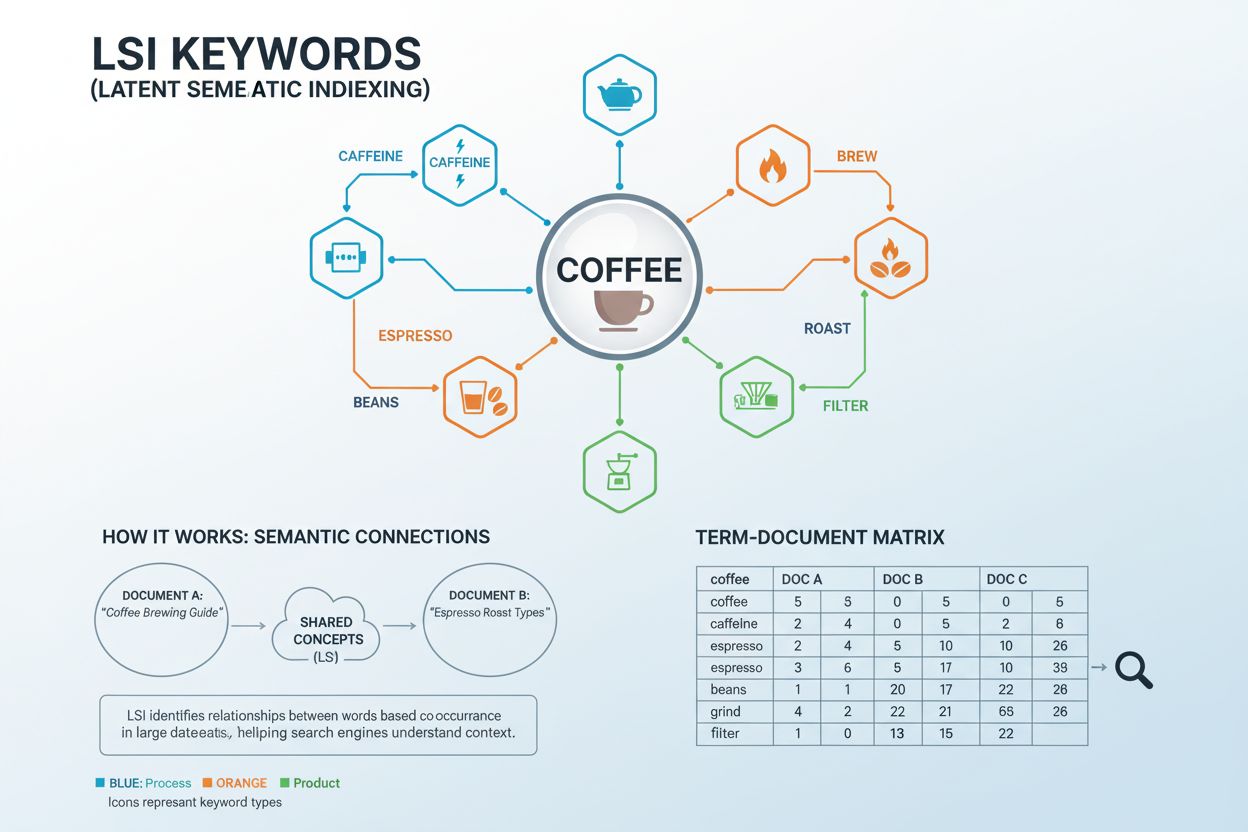
Definice LSI klíčových slov
LSI klíčová slova (Latent Semantic Indexing Keywords) jsou slova a fráze, které jsou koncepčně spojeny s vaším cílovým klíčovým slovem a často se vyskytují společně v podobných kontextech. Termín pochází z matematické techniky vyvinuté v 80. letech, která analyzuje skryté sémantické vztahy mezi slovy ve velkých kolekcích dokumentů. V praxi SEO jsou LSI klíčová slova vyhledávací výrazy, které pomáhají vyhledávačům a AI systémům pochopit širší kontext a téma vašeho obsahu nad rámec pouhého shody přesných klíčových slov. Například pokud je vaším hlavním klíčovým slovem “káva”, příbuzná LSI klíčová slova mohou zahrnovat “kofein”, “vaření”, “espresso”, “zrna”, “pražení” a “mletí”. Tyto výrazy společně signalizují vyhledávačům, že váš obsah komplexně pokrývá téma kávy, nikoliv jen opakovaně zmiňuje slovo.
Historický kontext a vývoj LSI klíčových slov
Latentní sémantické indexování bylo představeno v zásadním výzkumném článku z roku 1988 jako “nový přístup k řešení problémů slovní zásoby v interakci člověka s počítačem”. Technologie byla navržena k řešení zásadního problému: vyhledávače byly příliš závislé na přesné shodě klíčových slov, což často vedlo k neschopnosti najít relevantní dokumenty, když uživatelé používali odlišnou terminologii nebo synonyma. V roce 2004 Google implementoval koncepty LSI do svého algoritmu vyhledávání, což znamenalo zásadní změnu v tom, jak vyhledávače rozumí obsahu. Tato aktualizace umožnila Googlu posunout se za prostou analýzu frekvence slov a začít chápat kontext, význam a koncepční vztahy mezi výrazy. Podle vlastního výzkumu Googlu je nyní více než 15 % denních vyhledávání zcela nových, nikdy dříve nehledaných termínů, což činí kontextové porozumění skrze příbuzné výrazy stále důležitějším. Vývoj od LSI k moderní sémantické analýze představuje jeden z nejvýznamnějších posunů v technologii vyhledávačů a zásadně mění přístup tvůrců obsahu k optimalizaci.
LSI klíčová slova vs. příbuzná terminologie: Srovnávací tabulka
| Termín | Definice | Zaměření | Vztah k hlavnímu klíčovému slovu | Dopad na moderní SEO |
|---|
| LSI klíčová slova | Slova vyskytující se společně s hlavním klíčovým slovem na základě matematické analýzy | Vzorce frekvence slov a společný výskyt | Přímý kontextový vztah | Omezený (Google nepoužívá LSI algoritmus) |
| Sémantická klíčová slova | Koncepčně příbuzné výrazy pokrývající záměr uživatele a hloubku tématu | Význam a záměr uživatele | Širší tematický vztah | Vysoký (jádro moderního SEO) |
| Synonyma | Slova se stejným nebo velmi podobným významem | Přímá záměna slov | Stejný význam, jiné slovo | Střední (užitečné, ale ne hlavní zaměření) |
| Long-tail klíčová slova | Delší, konkrétnější fráze klíčových slov | Objem vyhledávání a specifičnost | Konkrétnější verze hlavního klíčového slova | Vysoký (nižší konkurence, vyšší záměr) |
| Příbuzná klíčová slova | Výrazy často vyhledávané spolu s hlavním klíčovým slovem | Vzorce chování při vyhledávání | Vzorce vyhledávání uživatelů | Vysoký (naznačuje záměr uživatele) |
| Entitní klíčová slova | Pojmenované entity a koncepty související s tématem | Vztahy entit a znalostní grafy | Koncepční a kategoriální vztah | Velmi vysoký (AI systémy upřednostňují entity) |
Matematický základ: Jak fungují LSI klíčová slova
Latentní sémantické indexování funguje na základě sofistikovaného matematického procesu zvaného Singular Value Decomposition (SVD), který analyzuje vztahy mezi slovy v rámci velkých kolekcí dokumentů. Systém začíná vytvořením Term Document Matrix (TDM)—dvojrozměrného pole, které sleduje, jak často se jednotlivá slova vyskytují v různých dokumentech. Zastávková slova (běžná slova jako “a”, “je”, “to”) jsou odstraněna, aby zůstaly jen významová slova. Algoritmus pak aplikuje váhovací funkce k identifikaci vzorců společného výskytu—situací, kdy se konkrétní slova vyskytují spolu se stejnou frekvencí napříč více dokumenty. Když se slova trvale vyskytují společně v podobných kontextech, systém je rozpozná jako sémanticky příbuzná. Například slova “káva”, “vaření”, “espresso” a “kofein” se často vyskytují v dokumentech o nápojích, což signalizuje jejich sémantický vztah. Tento matematický přístup umožňuje počítačům pochopit, že “espresso” a “káva” jsou příbuzné koncepty, aniž by musely být naprogramovány s explicitními pravidly. SVD vektory vytvořené touto analýzou předpovídají význam přesněji než analýza jednotlivých slov izolovaně a umožňují vyhledávačům chápat obsah na hlubší koncepční úrovni, než dovoluje pouhé párování klíčových slov.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Proč Google nepoužívá LSI (ale stále oceňuje sémantické porozumění)
Navzdory teoretické eleganci latentního sémantického indexování Google výslovně uvedl, že LSI ve svém hodnotícím algoritmu nepoužívá. John Mueller, zástupce Googlu, v roce 2019 potvrdil: “Neexistuje nic jako LSI klíčová slova—kdokoli tvrdí opak, se mýlí, promiňte.” Existuje několik důvodů, proč Google LSI opustil ve prospěch modernějších přístupů. Za prvé, LSI byl navržen pro menší, statické kolekce dokumentů, nikoliv pro dynamický, neustále se rozšiřující web. Původní patent na LSI, udělený Bell Communications Research v roce 1989, vypršel v roce 2008, ale Google už tehdy technologii překonal. Důležitější je, že Google vyvinul mnohem pokročilejší systémy jako RankBrain (představený v roce 2015), který využívá strojové učení k převodu textu do matematických vektorů, kterým počítače rozumí. Později Google představil BERT (Bidirectional Encoder Representations from Transformers) v roce 2019, který analyzuje slova obousměrně—zohledňuje všechna slova před i po konkrétním výrazu pro pochopení kontextu. Na rozdíl od LSI, které zastávková slova odstraňuje, BERT rozpoznává, že drobná slova jako “najít” ve větě “Kde mohu najít místního zubaře?” jsou zásadní pro pochopení záměru hledání. Dnes Google používá MUM (Multitask Unified Model) a AI Overviews pro generování kontextových souhrnů přímo ve výsledcích vyhledávání, což znamená pokrok daleko přesahující možnosti LSI.
Sémantické SEO: Moderní vývoj konceptů LSI
Ačkoli jsou LSI klíčová slova jako konkrétní technologie zastaralá, základní princip—že vyhledávače by měly rozumět kontextu a významu obsahu—zůstává klíčový pro moderní SEO. Sémantické SEO představuje vývoj tohoto konceptu a zaměřuje se na záměr uživatele, tematickou autoritu a komplexní pokrytí obsahu namísto vzorců frekvence klíčových slov. Podle dat z roku 2025 je přibližně 74 % všech vyhledávání nyní tvořeno long-tail frázemi, což činí sémantické porozumění zásadním pro oslovení různorodého publika. Sémantické SEO klade důraz na tvorbu obsahu, který důkladně pokrývá téma z více úhlů, přirozeně začleňuje příbuzné koncepty a odpovídá na související otázky. Tento přístup odpovídá způsobu, jakým moderní AI systémy jako ChatGPT, Perplexity, Google AI Overviews a Claude hodnotí zdroje. Tyto systémy upřednostňují obsah, který prokazuje odbornost, komplexnost a jasnou tematickou autoritu—vlastnosti, které přirozeně vznikají při začlenění sémanticky příbuzných výrazů a konceptů. Posun od LSI k sémantickému SEO znamená vyspění vyhledávacích technologií, přechod od matematického rozpoznávání vzorců k opravdovému kontextovému porozumění poháněnému neuronovými sítěmi a strojovým učením.
Praktická implementace: Kde a jak používat příbuzná klíčová slova
Začleňování LSI klíčových slov a sémanticky příbuzných výrazů do obsahu vyžaduje strategické umístění a přirozenou integraci. Nejefektivnější místa pro tyto výrazy zahrnují title tagy a H1 nadpisy, které mají v hodnocení vyhledávačů významnou váhu. H2 a H3 podnadpisy poskytují skvělé příležitosti pro přirozené zavedení příbuzných konceptů při logickém členění obsahu. Alt text obrázků je další cennou možností, jak posílit tematickou relevantnost a zároveň zlepšit přístupnost. V těle obsahu by měly být příbuzné výrazy přirozeně začleněny do vět a odstavců, aby podpořily hlavní myšlenku, aniž by ji narušily. Meta popisky mohou zahrnovat příbuzná klíčová slova pro zvýšení míry prokliků z výsledků vyhledávání. Interní odkazy a jejich anchor texty poskytují další příležitosti pro posílení sémantických vztahů mezi příbuznými stránkami na vašem webu. Klíčovým principem je přirozená integrace—pokud se příbuzný výraz do obsahu nehodí přirozeně, neměl by být násilně vkládán. Výzkumy ukazují, že obsah s jedním LSI klíčovým slovem na každých 200–300 slov udržuje optimální rovnováhu mezi sémantickou bohatostí a čitelností. Toto pravidlo není závazné, ale slouží jako užitečný návod pro zajištění dostatečného tematického pokrytí bez přeoptimalizace.
LSI klíčová slova a viditelnost ve vyhledávání s AI
Pro značky a tvůrce obsahu zaměřené na viditelnost ve vyhledávání s AI a citace napříč platformami, které monitoruje například AmICited, se stává porozumění LSI klíčovým slovům a sémantickým vztahům stále důležitější. AI systémy, které generují odpovědi pro ChatGPT, Perplexity, Google AI Overviews a Claude, hodnotí zdrojový materiál na základě komplexnosti tématu a signálů odbornosti. Když váš obsah obsahuje sémanticky příbuzné výrazy a koncepty, signalizuje těmto AI systémům, že jste téma důkladně pokryli. Tato komplexnost zvyšuje pravděpodobnost, že váš obsah bude vybrán jako zdroj pro AI-generované odpovědi. Navíc sémantická klíčová slova pomáhají vytvářet vztahy mezi entitami—spojení mezi koncepty, která AI systémy využívají k pochopení znalostních domén. Například obsah o “kávě”, který zahrnuje příbuzné entity jako “kofein”, “kávovary”, “kávová zrna” a “metody vaření”, prokazuje větší odbornost než obsah zmiňující pouze hlavní klíčové slovo. Takový obsah bohatý na entity je s větší pravděpodobností citován AI systémy generujícími komplexní odpovědi. Jak se vyhledávání s AI dále vyvíjí, schopnost prokázat tematickou autoritu prostřednictvím sémantické bohatosti se stává klíčovou konkurenční výhodou pro viditelnost a citace.
Klíčové aspekty LSI klíčových slov a sémantické optimalizace
- Kontextové vztahy: Příbuzné výrazy, které se často vyskytují společně v podobných kontextech a pomáhají vyhledávačům pochopit význam obsahu nad rámec přesné shody klíčových slov
- Vzorce společného výskytu: Slova, která se opakovaně vyskytují spolu napříč více dokumenty, signalizující sémantické vztahy vyhledávacím algoritmům
- Tematická autorita: Komplexní pokrytí tématu prostřednictvím příbuzných konceptů, budování odbornosti a důvěryhodnosti jak u vyhledávačů, tak AI systémů
- Přirozená integrace: Plynulé začlenění příbuzných výrazů do obsahu, který je čitelný pro člověka a zároveň signalizuje relevanci vyhledávačům
- Slučitelnost se záměrem vyhledávání: Používání sémanticky příbuzných výrazů, které odpovídají skutečným dotazům uživatelů, zvyšuje relevanci obsahu a míru prokliků
- Rozpoznávání entit: Identifikace a začlenění pojmenovaných entit a konceptů souvisejících s hlavním tématem, zásadní pro hodnocení AI systémů
- Sémantická bohatost: Hloubka a šířka koncepčně příbuzného obsahu, naznačující komplexní pokrytí tématu
- Long-tail varianty klíčových slov: Delší, specifičtější fráze, které zachycují příbuzný záměr vyhledávání a snižují konkurenci
- Komplexnost obsahu: Zahrnutí více úhlů pohledu a podtémat souvisejících s hlavním klíčovým slovem, zvyšuje celkovou kvalitu obsahu
- Potenciál AI citace: Prokázání odbornosti skrze sémantické pokrytí zvyšuje šanci, že vás AI systémy jako ChatGPT a Perplexity ocení jako zdroj
Budoucnost sémantického porozumění ve vyhledávání
Směr vývoje vyhledávacích technologií jasně směřuje k stále sofistikovanějšímu sémantickému porozumění poháněnému umělou inteligencí a strojovým učením. LSI klíčová slova jako konkrétní technologie představují raný pokus o řešení problému sémantického porozumění, ale moderní přístupy tyto možnosti dávno překonaly. Budoucí vyhledávací systémy budou pravděpodobně ještě více spoléhat na neurální sítě, transformer modely a velké jazykové modely, aby pochopily nejen to, co obsah říká, ale i co znamená v širším kontextu. Vznik disciplíny Generative Engine Optimization (GEO) tento posun odráží—marketéři nyní musí optimalizovat nejen pro tradiční vyhledávače, ale i pro AI systémy generující odpovědi. Tyto AI systémy hodnotí zdrojový materiál na základě komplexnosti, odbornosti a tematické autority—vlastnosti, které přirozeně vznikají při sémantické optimalizaci. Jak AI Overviews získávají větší podíl ve výsledcích vyhledávání, schopnost prokázat tematickou odbornost prostřednictvím sémanticky bohatého obsahu se stává stále cennější. Budoucnost pravděpodobně přinese ještě těsnější propojení tradičního SEO a AI optimalizace, přičemž sémantické porozumění bude mostem mezi těmito disciplínami. Tvůrci obsahu, kteří pochopí a implementují principy sémantické optimalizace, si udrží výhodu ve viditelnosti s tím, jak se technologie vyhledávání nadále vyvíjí.
Závěr: Od LSI klíčových slov k sémantické autoritě
Ačkoli LSI klíčová slova jako konkrétní algoritmický přístup Google již nepoužívá, základní princip—že vyhledávače mají rozumět kontextu a významu obsahu—je aktuálnější než kdy dřív. Vývoj od LSI k sémantickému SEO a dále k moderní AI optimalizaci představuje přirozený vývoj v tom, jak vyhledávací technologie rozumí a hodnotí obsah. Pro tvůrce obsahu a značky zaměřené na viditelnost ve vyhledávačích i AI platformách je praktický závěr jasný: tvořte komplexní, tematicky bohatý obsah, který přirozeně začleňuje příbuzné koncepty a prokazuje odbornost. Tento přístup splňuje požadavky jak tradičních vyhledávačů, tak hodnoticích kritérií AI systémů jako ChatGPT, Perplexity, Google AI Overviews a Claude. Pochopením vztahů mezi vaším hlavním klíčovým slovem a sémanticky příbuznými výrazy vytvoříte obsah, který se dobře umisťuje ve výsledcích vyhledávání i je citován jako autoritativní zdroj AI systémy. Budoucnost viditelnosti ve vyhledávání patří těm, kdo ovládnou sémantickou optimalizaci—ne skrze přeoptimalizování či umělé vkládání výrazů, ale prostřednictvím skutečné odbornosti a komplexního pokrytí tématu, které přirozeně začleňuje příbuzné koncepty a prokazuje hluboké porozumění dané problematice.