
Sémantické párování dotazů
Zjistěte, jak sémantické párování dotazů umožňuje AI systémům rozumět záměru uživatele a poskytovat relevantní výsledky nad rámec párování klíčových slov. Prozk...
5 min čtení
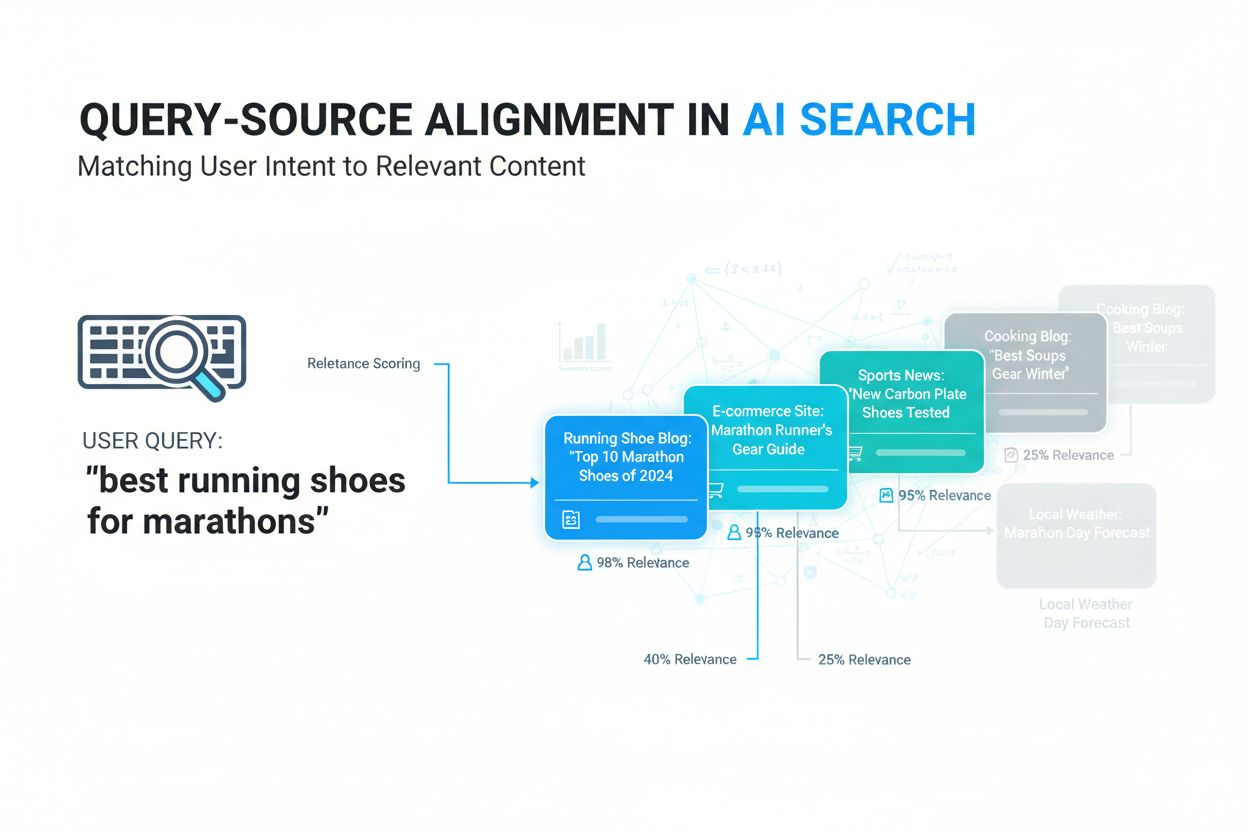
Zarovnání dotazu a zdroje je proces přiřazování uživatelských vyhledávacích dotazů k nejrelevantnějším informačním zdrojům na základě sémantického významu a kontextové relevance. Využívá AI a strojové učení k pochopení záměru za dotazy a propojuje je se zdroji, které skutečně odpovídají na informační potřeby uživatelů, místo aby se spoléhalo pouze na jednoduché shodování klíčových slov. Tato technologie je základem moderních AI vyhledávacích systémů, jako jsou Google AI Overviews, ChatGPT a Perplexity. Efektivní zarovnání zajišťuje, že AI systémy vracejí přesné a relevantní výsledky, které zvyšují spokojenost uživatelů a viditelnost obsahu.
Zarovnání dotazu a zdroje je proces přiřazování uživatelských vyhledávacích dotazů k nejrelevantnějším informačním zdrojům na základě sémantického významu a kontextové relevance. Využívá AI a strojové učení k pochopení záměru za dotazy a propojuje je se zdroji, které skutečně odpovídají na informační potřeby uživatelů, místo aby se spoléhalo pouze na jednoduché shodování klíčových slov. Tato technologie je základem moderních AI vyhledávacích systémů, jako jsou Google AI Overviews, ChatGPT a Perplexity. Efektivní zarovnání zajišťuje, že AI systémy vracejí přesné a relevantní výsledky, které zvyšují spokojenost uživatelů a viditelnost obsahu.
Zarovnání dotazu a zdroje označuje proces přiřazování uživatelských vyhledávacích dotazů k nejrelevantnějším informačním zdrojům na základě sémantického významu a kontextové relevance, nikoliv pouze prostého překrytí klíčových slov. V jádru tento koncept řeší zásadní výzvu v oblasti vyhledávání informací: zajistit, aby výsledky, které uživatelé při hledání získají, nebyly jen technicky spojené s jejich dotazy, ale skutečně odpovídaly jejich skutečným informačním potřebám.
Tradičně se vyhledávací systémy spoléhaly na párování klíčových slov – hledání dokumentů, které obsahují přesná slova či fráze zadané uživatelem. Tento přístup je sice přímočarý, ale často vedl k irelevantním výsledkům, protože ignoroval kontext, záměr a hlubší význam dotazů. Zarovnání dotazu a zdroje tento problém řeší pomocí sémantických párovacích technik, které rozumí koncepčním vztahům mezi tím, na co se uživatelé ptají, a co se nachází ve zdrojích. To znamená, že vyhledávání „údržba vozidla“ může účinně najít články o „péči o auto“ nebo „servisu automobilu“, i když nedojde k přesné shodě klíčových slov.
V kontextu moderních AI vyhledávacích systémů se zarovnání dotazu a zdroje stává stále důležitějším, protože umělá inteligence umožňuje sofistikovanější pochopení jazykových nuancí a uživatelského záměru. Místo aby systémy považovaly dotazy jen za sbírku slov, AI poháněná zarovnávací řešení analyzují sémantický obsah jak uživatelských otázek, tak dostupných zdrojů a vytvářejí smysluplná propojení na základě relevance, nikoliv povrchové podobnosti.
Toto rozlišení je zásadní, protože přímo ovlivňuje kvalitu vyhledávání a spokojenost uživatele. Efektivní zarovnání dotazu a zdroje zajišťuje, že vyhledávací systémy vracejí výsledky, které skutečně odpovídají uživatelským otázkám, snižují irelevantní šum ve výsledcích a pomáhají uživatelům objevit informace, které by pomocí tradičních metod párování slov nemuseli najít. Jak se AI vyhledávací technologie dál vyvíjí, zarovnání dotazu a zdroje zůstává základním principem pro stavbu systémů, které skutečně rozumí a reagují na informační potřeby uživatelů.
Technický proces zarovnání dotazu a zdroje zahrnuje několik sofistikovaných kroků, které převádějí uživatelské dotazy na smysluplná propojení s relevantními zdroji:
Zpracování dotazu a tokenizace – Když uživatel zadá vyhledávací dotaz, systém jej nejprve rozdělí na jednotlivé tokeny (slova a fráze) a analyzuje gramatickou strukturu. Algoritmy zpracování přirozeného jazyka identifikují klíčové pojmy, entity a záměr dotazu, odstraní stop slova a určí nejvýznamnější složky, které budou řídit zarovnávací proces.
Generování embeddingu dotazu – Zpracovaný dotaz je převeden na sémantický vektor – matematickou reprezentaci, která zachycuje význam a kontext dotazu v mnohorozměrném prostoru. Tento embedding je vytvořen pomocí neuronových jazykových modelů trénovaných na velkém množství textových dat, což systému umožňuje zachytit sémantickou podstatu dotazu, nikoliv jen jeho doslovná slova.
Vektorizace zdrojových dokumentů – Současně jsou všechny dostupné zdrojové dokumenty v systému převedeny na sémantické vektory pomocí stejného embedding modelu. Díky tomu jsou dotazy i zdroje reprezentovány ve stejném sémantickém prostoru, což umožňuje jejich přímé porovnání. Vektor každého dokumentu zachycuje jeho celkový význam, témata a signály relevance.
Výpočty vektorové podobnosti – Systém spočítá podobnost mezi vektorem dotazu a každým vektorem zdrojového dokumentu pomocí matematických metrik vzdálenosti, nejčastěji kosinové podobnosti. Tento výpočet určuje, jak blízko je sémantický význam každého zdroje významu dotazu, a vytváří skóre podobnosti mezi 0 a 1.
Bodování relevance a řazení – Nad rámec sémantické podobnosti systém využívá další faktory hodnocení, včetně autority domény, aktuálnosti obsahu, metrik zapojení uživatelů a tematické relevance. Tyto faktory jsou kombinovány se sémantickým skóre pro vytvoření komplexního skóre relevance, které určuje pozici zdroje ve výsledcích.
Ověření shody obsahu – Systém ověřuje, že vybrané zdroje skutečně obsahují relevantní informace, analýzou konkrétních částí obsahu. Zajišťuje tím, že zdroje nejsou řazeny vysoko jen proto, že obsahují relevantní klíčová slova, ale protože skutečně řeší informační potřebu uživatele kvalitním a přesným obsahem.
Konečný výběr a řazení zdrojů – Nejvýše hodnocené zdroje jsou vybrány k prezentaci uživateli nebo k citaci v AI-generovaných odpovědích. Konečné pořadí odráží kombinované hodnocení sémantického zarovnání, autority, relevance a kvality obsahu, což zajišťuje, že uživatelé obdrží ty nejvhodnější zdroje pro svůj konkrétní dotaz.
| Metoda/přístup | Jak funguje | Výhody | Nevýhody | Nejvhodnější pro |
|---|---|---|---|---|
| Párování klíčových slov (tradiční) | Hledá přesná slova nebo fráze v dokumentech; řadí podle četnosti a pozice | Snadná implementace; rychlé zpracování; transparentní logika párování | Ignoruje kontext a záměr; přináší nerelevantní výsledky; neřeší synonyma | Jednoduché, faktické dotazy; starší systémy |
| Sémantická podobnost (vektorová) | Převádí dotazy a dokumenty na sémantické vektory; počítá podobnost matematickými metrikami vzdálenosti | Chápe význam za slovy; zvládá synonyma i kontext; vysoká přesnost | Výpočetně náročné; vyžaduje velké trénovací datasety; méně transparentní | Složité dotazy; vyhledávání dle záměru; moderní AI systémy |
| Rozpoznávání entit | Identifikuje a klasifikuje klíčové entity (osoby, místa, organizace, produkty) v dotazech i obsahu | Zlepšuje porozumění konkrétním tématům; rozlišuje pojmy; umožňuje integraci znalostních grafů | Vyžaduje rozsáhlé databáze entit; potíže s novými či úzce zaměřenými entitami | Dotazy na konkrétní entity; znalostní vyhledávání |
| Porozumění kontextu | Analyzuje okolní kontext, historii uživatele a vzorce dotazů pro odhad významu | Zachycuje nuance záměru; personalizuje výsledky; zvyšuje přesnost u nejednoznačných dotazů | Otázky soukromí; potřeba historických dat; složitá implementace | Konverzační vyhledávání; personalizovaná doporučení |
| Hybridní přístup | Kombinuje více metod (sémantická podobnost, rozpoznávání entit, porozumění kontextu) | Využívá silné stránky více metod; robustní a přesné; zvládá rozmanité typy dotazů | Složitá implementace i údržba; vyšší výpočetní náročnost; hůře laditelné | Podniková vyhledávání; AI vyhledávací platformy |
| Znalostní grafy | Využívá propojené entity a vztahy k pochopení dotazů a párování relevantních zdrojů | Zachycuje reálné vztahy; umožňuje sofistikované úvahy; podporuje složité dotazy | Vyžaduje rozsáhlou tvorbu znalostních grafů; náročná údržba; doménová specifika | Složité výzkumné dotazy; sémantické webové aplikace |
Zarovnání dotazu a zdroje je základním principem fungování moderních AI vyhledávacích systémů a výběru zdrojů pro jejich odpovědi:
Google AI Overviews – Využívá zarovnání dotazu a zdroje k výběru nejrelevantnějších zdrojů pro AI-generované souhrny vyhledávání. Systém analyzuje sémantické zarovnání mezi uživatelským dotazem a dostupnými webovými stránkami, upřednostňuje zdroje se silnou sémantickou relevancí a vysokou autoritou. Výzkumy ukazují, že přibližně 70 % zdrojů v AI Overviews pochází z top 10 organických výsledků, což znamená, že tradiční řazení a sémantické zarovnání jdou ruku v ruce.
ChatGPT s prohlížením – Při aktivované funkci prohlížení používá ChatGPT zarovnání dotazu a zdroje k identifikaci a načtení nejrelevantnějších webových stránek pro odpovědi na uživatelské otázky. Systém upřednostňuje autoritativní zdroje se silným sémantickým zarovnáním k dotazu, aby odpovědi byly založené na spolehlivých a relevantních informacích z webu.
Perplexity AI – Zavádí zarovnání dotazu a zdroje pro výběr zdrojů ke svým konverzačním odpovědím. Platforma zobrazuje citované zdroje vedle svých odpovědí, což dělá proces zarovnání transparentní pro uživatele. Silné sémantické zarovnání mezi dotazy a zdroji zajišťuje, že odpovědi Perplexity jsou dobře podložené a ověřitelné.
Bing AI Chat – Využívá zarovnání dotazu a zdroje k propojení vyhledávacích výsledků s konverzačními odpověďmi. Systém páruje uživatelské dotazy s relevantními výsledky Bingu pomocí sémantického porozumění a následně syntetizuje informace z více zarovnaných zdrojů do ucelených odpovědí.
Koncept jádrových zdrojů – AI systémy identifikují tzv. „jádrové zdroje“ – URL, které se konzistentně vyskytují napříč odpověďmi na příbuzné dotazy. Tyto zdroje mají mimořádně silné sémantické zarovnání s tématy dotazu a jsou považovány za vysoce autoritativní. Stát se jádrovým zdrojem ve svém oboru je klíčem k viditelnosti obsahu v AI vyhledávání.
Skórování sémantické relevance – AI platformy přidělují skóre relevance podle toho, jak dobře obsah zdroje sémanticky odpovídá záměru dotazu. Zdroje s vyšším skóre sémantického zarovnání mají větší pravděpodobnost, že budou vybrány, citovány a zvýrazněny v AI-generovaných odpovědích.
Zarovnání více dotazů – Když AI systémy generují odpovědi, často rozkládají uživatelské dotazy na více dílčích (fan-out) dotazů. Zarovnání dotazu a zdroje se uplatňuje na každý dílčí dotaz a zdroje, které se dobře zarovnají s více příbuznými dotazy, jsou upřednostněny, což umožňuje komplexnější a lépe podložené odpovědi.
Sledování v AmICited – AmICited sleduje zarovnání dotazu a zdroje tím, že monitoruje, které vaše stránky jsou vybrány jako zdroje pro konkrétní dotazy napříč AI platformami. Platforma zobrazuje skóre vašeho sémantického zarovnání, sleduje stav jádrových zdrojů a identifikuje příležitosti ke zlepšení zarovnání s hodnotnými dotazy ve vašem oboru.
Rovnováha autority a sémantiky – I když autorita domény zůstává důležitá, výzkumy ukazují, že sémantické zarovnání je stále klíčovější. Zdroje se silným sémantickým zarovnáním, ale střední autoritou, mohou předčit vysoce autoritativní zdroje se slabým sémantickým zarovnáním, což dokazuje, že význam je stejně důležitý jako reputace.
Sledování zarovnání v reálném čase – Moderní AI monitorovací platformy sledují, jak se zarovnání dotazu a zdroje v čase mění s aktualizací obsahu a nástupem nových zdrojů. To umožňuje marketérům pochopit, které úpravy obsahu zlepšují zarovnání a které dotazy nabízejí nejlepší příležitosti pro zvýšení viditelnosti.
Pochopení a optimalizace zarovnání dotazu a zdroje se v době AI vyhledávání stala nezbytností pro tvůrce obsahu, marketéry i značky:
Sledování citací značky – Zarovnání dotazu a zdroje přímo určuje, zda je vaše značka a obsah citována v AI-generovaných odpovědích. Platformy jako AmICited toto zarovnání monitorují a ukazují, na které dotazy se váš obsah v AI odpovědích objevuje a jak často je vaše značka zmiňována napříč AI vyhledávacími platformami.
Sémantická relevance a objevitelnost – Silné sémantické zarovnání s uživatelskými dotazy zvyšuje pravděpodobnost, že váš obsah bude AI systémy objeven a citován. To je zvláště důležité u long-tail dotazů a úzce zaměřených témat, kde je tradiční SEO konkurence nižší, ale sémantická relevance klíčová.
Konkurenční výhoda v AI vyhledávání – Jak se AI vyhledávání rozšiřuje, značky se silným zarovnáním dotazu a zdroje pro hodnotné dotazy získávají významnou konkurenční výhodu. Včasná optimalizace pro sémantické zarovnání umožňuje vašemu obsahu získat viditelnost dříve, než konkurence přizpůsobí své strategie.
Sledování zdrojů a atribuce – Pochopení zarovnání dotazu a zdroje vám pomáhá sledovat, které vaše stránky jsou vybírány jako zdroje pro konkrétní dotazy. Tato data o atribuci odhalují, který obsah si vede nejlépe v AI odpovědích a která témata jsou příležitostí ke zlepšení.
Optimalizace pro AI odpovědi – Místo optimalizace pouze na tradiční pořadí ve vyhledávání je nyní třeba do obsahové strategie zapojit i zarovnání dotazu a zdroje. Obsah, který se dobře umísťuje v tradičním vyhledávání, ale má slabé sémantické zarovnání, nemusí být AI systémy vybrán a může tak přijít o viditelnost.
Snížení rizik a kontrola značky – Sledování zarovnání dotazu a zdroje vám umožňuje pochopit, jak je vaše značka prezentována v AI odpovědích. Pokud má obsah konkurence silnější zarovnání pro klíčové dotazy, můžete identifikovat mezery a vytvářet obsah, který lépe odpovídá uživatelskému záměru.
Zpřesnění obsahové strategie – Metodiky zarovnání dotazu a zdroje ukazují, která témata, klíčová slova a obsahové formáty nejvíce rezonují s AI systémy. Tato data řídí vaši strategii a pomáhají zaměřit se na témata, kde je sémantické zarovnání dosažitelné a hodnotné.
Konkurenční přehled – Analýzou zarovnání dotazu a zdroje v rámci svého oboru můžete zjistit, který konkurenční obsah je nejčastěji citován v AI odpovědích. Tato konkurenční inteligence odhaluje mezery ve vaší obsahové strategii a příležitosti k získání viditelnosti.
Plánování dlouhodobé viditelnosti – Zarovnání dotazu a zdroje je stabilnější než tradiční pořadí ve vyhledávání, protože je založeno na sémantickém významu, nikoliv na algoritmických faktorech, které se často mění. Silné sémantické zarovnání přináší trvalejší viditelnost v AI vyhledávání v čase.
Měřitelná návratnost investic do obsahu – Sledování zarovnání dotazu a zdroje a výsledné viditelnosti v AI odpovědích poskytuje jasná měřítka pro vyhodnocení návratnosti investic do obsahu. Můžete přímo vidět, jak investice do obsahu vedou k citacím značky a návštěvnosti z AI vyhledávacích platforem.
Optimalizace pro zarovnání dotazu a zdroje vyžaduje strategický přístup, který jde nad rámec tradičního SEO. Cílem je zajistit, aby váš obsah měl silné sémantické zarovnání s dotazy vašeho cílového publika a byl tak častěji vybrán AI systémy jako relevantní zdroj.
Pochopení sémantické optimalizace – Sémantická optimalizace se zaměřuje na to, aby váš obsah důkladně odpovídal na konkrétní uživatelské záměry a otázky, nikoliv pouze na klíčová slova. Zahrnuje pochopení sémantických vztahů mezi pojmy, používání konzistentní terminologie a strukturování obsahu tak, aby jasně sděloval význam jak lidem, tak AI systémům.
Osvědčené postupy pro zarovnání dotazu a zdroje:
Provádějte sémantický výzkum klíčových slov – Jděte za hranice tradičního výzkumu klíčových slov a identifikujte sémantické shluky příbuzných termínů a pojmů. Využijte nástroje jako SEMrush nebo Ahrefs nejen pro hledání frekventovaných klíčových slov, ale i sémantických variant a příbuzných dotazů, které řeší stejný uživatelský záměr. Vytvořte z nich obsah, který pokrývá všechny tyto variace.
Používejte sémantické HTML5 značky – Využívejte sémantické HTML5 prvky jako <article>, <section>, <header>, <nav> a <main> pro jasné strukturování obsahu. Tyto prvky pomáhají AI systémům pochopit organizaci a hierarchii obsahu a zlepšují sémantickou interpretaci. Nadpisové značky (<h1>, <h2>, atd.) používejte hierarchicky pro vyjádření vztahů mezi tématy.
Tvořte obsah bohatý na entity – Identifikujte klíčové entity (osoby, organizace, produkty, pojmy) relevantní pro vaše téma a zmiňujte je explicitně v obsahu. Používejte konzistentní terminologii a poskytujte kontext, který AI systémům pomáhá pochopit, o jakých entitách píšete. Například při zmínce o „Apple“ upřesněte podle kontextu, zda jde o technologickou firmu nebo ovoce.
Implementujte strukturovaná data (JSON-LD) – Používejte schema.org značky ve formátu JSON-LD pro explicitní sémantickou informaci o obsahu. Implementujte vhodné typy schémat jako Article, NewsArticle, HowTo, FAQPage nebo Product podle typu obsahu. AI systémům tak jasně sdělíte, o čem obsah je a jak souvisí s uživatelskými dotazy.
Optimalizujte pro různé varianty záměru uživatele – Identifikujte různé způsoby, jak uživatelé vyjadřují stejnou informační potřebu, a tvořte obsah, který odpovídá všem těmto variantám. Například uživatelé mohou hledat „jak opravit kapající kohoutek“, „návod na opravu kohoutku“ nebo „řešení pro kapající baterii“. Vytvořte komplexní obsah zahrnující všechny tyto varianty záměru se stejným sémantickým významem.
Rozvíjejte komplexní pokrytí témat – Místo tvorby více povrchních článků na podobná témata tvořte ucelené průvodce, které téma důkladně pokrývají. AI systémy preferují hluboký obsah, který poskytuje úplné odpovědi na uživatelské otázky. Používejte tematické shlukování, abyste pokryli všechny aspekty tématu se silnými sémantickými vazbami mezi sekcemi.
Udržujte konzistentní terminologii – Používejte stejnou terminologii napříč obsahem i celým webem. Pokud zavádíte nějaký pojem, držte se stejného výrazu místo nahrazování synonymy. Tato konzistence pomáhá AI systémům rozpoznat, že se v celém obsahu jedná stále o stejný koncept.
Vytvářejte jasné hierarchie obsahu – Strukturu obsahu tvořte s jasnou hierarchií, která ukazuje, jak spolu pojmy souvisejí. Používejte nadpisy, odrážky a číslované seznamy k vyjádření vztahů mezi myšlenkami. Tato struktura pomáhá AI systémům pochopit sémantickou organizaci obsahu a propojenost různých pojmů.
Optimalizujte meta popisy a titulky – Pište meta popisy a titulky stránek tak, aby jasně vystihovaly sémantický obsah stránky. Tyto prvky AI systémy často využívají k pochopení obsahu, proto se ujistěte, že přesně odrážejí hlavní téma a klíčové pojmy stránky. V titulcích a popisech zmiňujte relevantní entity a pojmy.
Sledujte skóre sémantického zarovnání – Využívejte AI monitorovací platformy jako AmICited k měření skóre sémantického zarovnání pro důležité dotazy. Sledujte, jak se vaše zarovnání mění při aktualizaci obsahu a identifikujte, které úpravy zarovnání zlepšují. Zaměřte se na rozvoj obsahu v oblastech s nejsilnějším zarovnáním.
Příklady z praxe v různých odvětvích:
Tradiční párování klíčových slov pouze hledá přesná slova nebo fráze v dokumentech, zatímco zarovnání dotazu a zdroje využívá sémantické porozumění k párování významu a záměru za dotazy. To znamená, že vyhledávání 'údržba vozidla' může najít články o 'péči o auto', i když nedochází k přesné shodě klíčových slov. Zarovnání dotazu a zdroje přináší relevantnější výsledky, protože chápe kontext a záměr uživatele, nikoliv jen povrchní podobnost slov.
AI vyhledávací platformy používají zarovnání dotazu a zdroje k výběru nejrelevantnějších zdrojů, které citují ve svých generovaných odpovědích. Systém analyzuje jak sémantický význam uživatelského dotazu, tak obsah dostupných zdrojů a poté řadí zdroje podle relevance, autority a sémantického zarovnání. To zajišťuje, že AI-generované odpovědi jsou založené na kvalitních, relevantních zdrojích, které skutečně odpovídají na uživatelskou informační potřebu.
Zarovnání dotazu a zdroje přímo ovlivňuje, zda je váš obsah vybrán jako zdroj v AI-generovaných odpovědích. Pokud má váš obsah silné sémantické zarovnání s běžnými dotazy ve vašem oboru, je pravděpodobnější, že bude citován AI systémy. Tato viditelnost v AI odpovědích přináší návštěvnost a buduje autoritu značky. Pochopení a optimalizace pro zarovnání dotazu a zdroje je nezbytná pro udržení viditelnosti v době AI vyhledávání.
Pro optimalizaci zarovnání dotazu a zdroje se zaměřte na tvorbu obsahu, který důkladně řeší konkrétní uživatelské záměry a otázky. Používejte sémantické HTML značky, implementujte strukturovaná data (JSON-LD), zajistěte jasné rozpoznávání entit a udržujte konzistentní terminologii. Pište komplexní, řešení zaměřený obsah, který důkladně odpovídá na otázky. Sledujte své skóre sémantického zarovnání a monitorujte výkon obsahu v AI odpovědích pomocí nástrojů jako AmICited.
Sémantická podobnost je jádrem zarovnání dotazu a zdroje. Měří, jak blízko je význam dotazu významu obsahu ve zdrojích. To se vypočítává pomocí vektorových embeddingů—matematických reprezentací textu, které zachycují sémantický význam. Zdroje s vyšším skóre sémantické podobnosti k dotazu jsou řazeny výše a mají větší šanci být vybrány AI systémy jako relevantní zdroje pro odpovědi na uživatelské otázky.
AmICited je AI monitorovací platforma, která sleduje, jak je vaše značka a obsah citována napříč AI vyhledávacími platformami. Sleduje zarovnání dotazu a zdroje tím, že ukazuje, které vaše stránky jsou vybírány jako zdroje pro konkrétní dotazy, jak často je vaše značka zmiňována v AI odpovědích a jak vaše sémantické zarovnání obstojí ve srovnání s konkurencí. Tato data vám pomáhají pochopit a optimalizovat obsahovou strategii pro lepší viditelnost v AI vyhledávání.
Jádrové zdroje jsou URL adresy, které se konzistentně objevují v několika AI-generovaných odpovědích na stejné nebo příbuzné dotazy. Tyto zdroje mají silné sémantické zarovnání s tématy dotazu a AI systémy je považují za vysoce relevantní. Jádrové zdroje obvykle dosahují vyššího hodnocení v tradičních výsledcích vyhledávání a mají lepší sémantické zarovnání se záměrem dotazu. Stát se jádrovým zdrojem pro vaše klíčové dotazy je klíčovým cílem pro viditelnost obsahu v AI vyhledávání.
Rozpoznávání entit pomáhá AI systémům identifikovat a chápat klíčové pojmy, osoby, organizace a témata jak v dotazech, tak v obsahu zdrojů. Díky rozpoznávání entit mohou AI systémy lépe porozumět, na co se dotaz skutečně ptá, a spárovat jej se zdroji, které řeší stejné entity v relevantních kontextech. Například rozpoznání, že 'Apple' označuje technologickou společnost, nikoli ovoce, pomáhá zarovnat dotazy na Apple produkty s relevantními technologickými zdroji.
Sledujte, jak je váš obsah citován napříč AI vyhledávacími platformami a optimalizujte lepší zarovnání dotazu a zdroje s AI monitorovací platformou AmICited.
Zjistěte, jak sémantické párování dotazů umožňuje AI systémům rozumět záměru uživatele a poskytovat relevantní výsledky nad rámec párování klíčových slov. Prozk...

Upřesnění dotazu je iterativní proces optimalizace vyhledávacích dotazů pro lepší výsledky v AI vyhledávačích. Zjistěte, jak funguje v ChatGPT, Perplexity, Goog...
Vyhledávání na základě otázek jsou dotazy v přirozeném jazyce formulované jako otázky. Zjistěte, jak tento posun ovlivňuje monitoring AI, viditelnost značky a m...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.