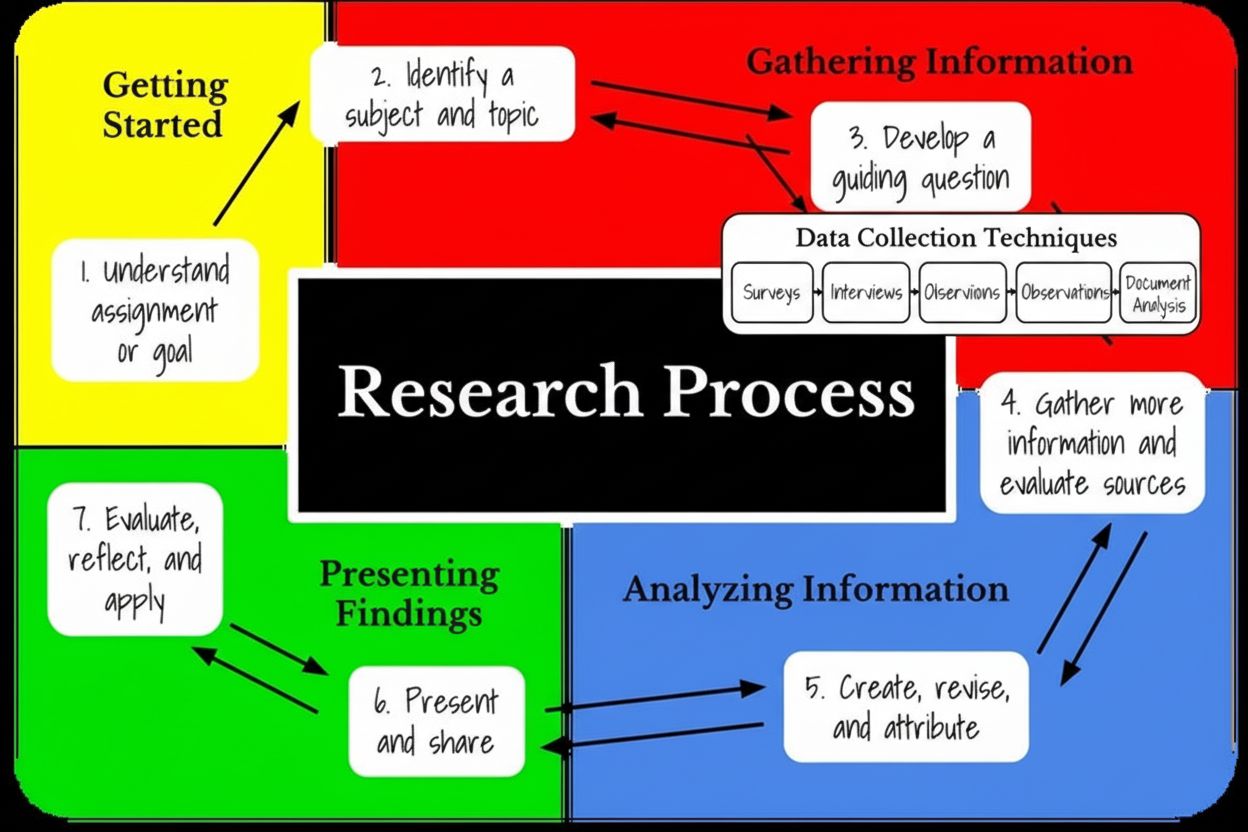
Fáze výzkumu – fáze shromažďování informací
Zjistěte, co je fáze shromažďování informací ve výzkumu, jaký má význam v metodologii výzkumu, jaké existují techniky sběru dat a jak ovlivňuje AI monitoring a ...
8 min čtení

Sekundární výzkum je analýza a interpretace již existujících dat, která byla dříve shromážděna jinými výzkumníky nebo organizacemi pro odlišné účely. Zahrnuje syntézu publikovaných datových souborů, zpráv, odborných časopisů a dalších zdrojů k zodpovězení nových výzkumných otázek nebo ověření hypotéz bez provádění vlastního sběru dat.
Sekundární výzkum je analýza a interpretace již existujících dat, která byla dříve shromážděna jinými výzkumníky nebo organizacemi pro odlišné účely. Zahrnuje syntézu publikovaných datových souborů, zpráv, odborných časopisů a dalších zdrojů k zodpovězení nových výzkumných otázek nebo ověření hypotéz bez provádění vlastního sběru dat.
Sekundární výzkum, známý také jako desk research, je systematická výzkumná metodologie, která zahrnuje analýzu, syntézu a interpretaci již existujících dat, která byla dříve shromážděna jinými výzkumníky, organizacemi či institucemi pro jiné účely. Místo získávání původních dat prostřednictvím dotazníků, rozhovorů nebo experimentů využívá sekundární výzkum publikované datové sady, zprávy, odborné časopisy, vládní statistiky a další shromážděné informační zdroje k zodpovězení nových výzkumných otázek či ověření hypotéz. Tento přístup znamená zásadní posun od sběru dat k jejich analýze a interpretaci, což umožňuje organizacím získat využitelné poznatky z informací, které již existují ve veřejném prostoru nebo v organizačních archívech. Termín „sekundární“ odkazuje na skutečnost, že výzkumníci pracují s daty, která jsou sekundární vůči původnímu účelu sběru – data původně shromážděná za jedním účelem jsou znovu analyzována s cílem zodpovědět jiné výzkumné otázky či obchodní výzvy.
Praxe sekundárního výzkumu se za poslední století výrazně vyvinula – od knihovních rešerší až po sofistikovanou digitální analýzu dat. Historicky se výzkumníci spoléhali na fyzické knihovny, archivy a publikované materiály při provádění sekundární analýzy, což byl časově náročný proces omezující rozsah a dostupnost výzkumu. Digitální revoluce zásadně změnila sekundární výzkum tím, že zpřístupnila rozsáhlé datové sady okamžitě prostřednictvím online databází, státních portálů a akademických repozitářů. V současnosti generuje globální průmysl tržního výzkumu 140 miliard dolarů ročně (stav v roce 2024), přičemž sekundární výzkum tvoří významnou část tohoto trhu. Růst je pozoruhodný – odvětví se rozrostlo ze 102 miliard v roce 2021 na 140 miliard v roce 2024, což představuje nárůst o 37,25 % za pouhé tři roky. Tento růst odráží rostoucí důraz organizací na rozhodování založené na datech a uznání, že sekundární výzkum poskytuje cenově efektivní cestu k tržním poznatkům. Vznik nástrojů pro analýzu dat poháněných AI dále revolucionalizoval sekundární výzkum – umožňuje výzkumníkům zpracovávat obrovské datové sady, identifikovat vzorce a získávat poznatky bezprecedentní rychlostí. Podle nedávných výzkumů 69 % odborníků na tržní výzkum začlenilo syntetická data a AI analýzu do svých sekundárních výzkumných aktivit, což dokládá rychlý technologický vývoj v tomto oboru.
Data pro sekundární výzkum pocházejí ze dvou hlavních kategorií: interní zdroje a externí zdroje. Interní sekundární data zahrnují informace již shromážděné a uložené v rámci organizace, například databáze prodeje, historii zákaznických transakcí, předchozí výzkumné projekty, metriky výkonu kampaní a webovou analytiku. Tato interní data poskytují konkurenční výhodu, protože zůstávají exkluzivní pro organizaci a odrážejí skutečný obchodní výkon. Externí sekundární data zahrnují veřejně dostupné nebo placené informace od státních agentur, akademických institucí, agentur pro tržní výzkum, oborových asociací a mediálních zdrojů. Vládní zdroje poskytují sčítací data, ekonomické statistiky a regulatorní informace; akademické zdroje nabízejí recenzovaný výzkum a longitudinální studie; agentury pro tržní výzkum publikují odvětvové zprávy a konkurenční analýzy; oborové asociace sestavují odvětvová data a trendy. Různorodost sekundárních zdrojů umožňuje výzkumníkům triangulovat zjištění z více perspektiv a ověřovat závěry napříč zdroji.
| Aspekt | Sekundární výzkum | Primární výzkum |
|---|---|---|
| Sběr dat | Analyzuje existující data shromážděná jinými | Shromažďuje původní data přímo ze zdrojů |
| Časový rámec | Dny až týdny | Týdny až měsíce |
| Náklady | Nízké až minimální (často zdarma) | Vysoké (nábor účastníků, administrativa) |
| Kontrola nad daty | Žádná kontrola nad metodikou či kvalitou | Plná kontrola nad návrhem a realizací výzkumu |
| Specifičnost | Nemusí řešit konkrétní výzkumné otázky | Přizpůsobeno přesným výzkumným cílům |
| Zkreslení výzkumníkem | Neznámé zkreslení od původních sběratelů | Potenciální zkreslení od současných výzkumníků |
| Exkluzivita dat | Neexkluzivní (konkurence má přístup ke stejným datům) | Exkluzivní vlastnictví závěrů |
| Velikost vzorku | Často rozsáhlé datové sady | Liší se dle rozpočtu a rozsahu |
| Relevance | Může vyžadovat přizpůsobení aktuálním potřebám | Přímo relevantní pro současné výzkumné cíle |
| Rychlost poznatků | Okamžitý přístup ke shromážděným informacím | Vyžaduje čas na sběr a analýzu dat |
Metodika sekundárního výzkumu se řídí strukturovaným pětikrokovým procesem, který zajišťuje důkladnou analýzu a validní závěry. Prvním krokem je jasné vymezení výzkumného tématu a identifikace konkrétních otázek, které by sekundární data mohla zodpovědět. Výzkumníci musí přesně formulovat, čeho chtějí dosáhnout – zda jde o explorativní (zjištění příčin jevu), nebo konfirmativní (ověření hypotéz) cíle. Druhý krok zahrnuje identifikaci a vyhledání vhodných zdrojů sekundárních dat s ohledem na relevanci dat, důvěryhodnost zdroje, datum publikace a geografický rozsah. Třetím krokem je systematické shromažďování a organizace dat, často vyžadující přístup do více databází, ověření autenticity zdrojů a konsolidaci informací do analyzovatelných formátů. V této fázi musí výzkumníci hodnotit kvalitu dat, transparentnost metodiky a zjistit, zda časový rámec sběru dat odpovídá potřebám výzkumu. Čtvrtý krok se zaměřuje na kombinaci a porovnání datových sad, identifikaci vzorců napříč různými zdroji a rozpoznání trendů nebo anomálií, které vyplývají z komparativní analýzy. Výzkumníci mohou potřebovat vyfiltrovat nepoužitelná data, sladit rozpory a uspořádat zjištění do smysluplných narativů. Poslední krok zahrnuje komplexní analýzu a interpretaci, při níž výzkumníci posuzují, zda sekundární data dostatečně odpovídají původním výzkumným otázkám, identifikují informační mezery a rozhodují, zda je nutný doplňkový primární výzkum. Tento strukturovaný přístup zajišťuje, že sekundární výzkum přináší důvěryhodné a využitelné poznatky, nikoli pouze povrchní závěry.
Jednou z nejpřesvědčivějších výhod sekundárního výzkumu je jeho výrazná nákladová efektivita oproti primárním výzkumným metodám. Analýza sekundárních dat je téměř vždy levnější než provádění primárního výzkumu, přičemž organizace obvykle ušetří 50–70 % rozpočtu na výzkum využitím již existujících datových sad. Jelikož sběr dat představuje nejdražší složku primárního výzkumu – včetně náboru účastníků, pobídek, správy dotazníků a terénních operací – sekundární výzkum tyto náklady zcela eliminuje. Většina sekundárních zdrojů je dostupná zdarma prostřednictvím státních institucí, veřejných knihoven a akademických repozitářů, nebo za minimální poplatek přes předplacené služby. Úspora času je rovněž významná: sekundární výzkum lze dokončit během dnů až týdnů, zatímco primární výzkum obvykle vyžaduje týdny až měsíce. Výzkumníci mají okamžitý přístup ke shromážděným datovým sadám prostřednictvím online platforem, což umožňuje rychlé rozhodování v časově kritických situacích. Sekundární data jsou navíc většinou předčištěná a organizovaná v elektronické podobě, což eliminuje časově náročnou přípravu dat, která v primárním výzkumu spotřebuje značné zdroje. Pro organizace s omezeným rozpočtem nebo krátkými termíny představuje sekundární výzkum dostupnou cestu k tržním poznatkům, konkurenčním informacím a analýze trendů. Růst globálního trhu tržního výzkumu na 140 miliard dolarů odráží rostoucí investice organizací do výzkumu, přičemž sekundární výzkum tvoří cenově efektivní složku komplexních výzkumných strategií.
V kontextu AI monitoringu a optimalizace generativních enginů hraje sekundární výzkum klíčovou roli při stanovování východisek a pochopení, jak AI systémy citují zdroje. Platformy jako AmICited využívají principy sekundárního výzkumu ke sledování zmínek o značce napříč AI systémy včetně ChatGPT, Perplexity, Google AI Overviews a Claude. Analýzou existujících dat o citacích konkurence, trendech v odvětví a historické výkonnosti značky v AI odpovědích mohou organizace identifikovat vzorce v tom, jak AI systémy vybírají a citují zdroje. Sekundární výzkum pomáhá stanovit měřítka pro viditelnost v AI, což značkám umožňuje pochopit svou aktuální pozici ve srovnání s konkurenty a standardy odvětví. Organizace mohou analyzovat sekundární data o výkonu obsahu, vzorcích citací a preferencích AI systémů a optimalizovat tak svou obsahovou strategii pro vyšší četnost citací v AI. Tato integrace sekundárního výzkumu s AI monitoringem vytváří komplexní porozumění tomu, jak se značky objevují ve výsledcích generativního vyhledávání a odpovědích poháněných AI. Analýza existujících dat o citacích, strategiích konkurence a trendech v odvětví poskytuje kontext pro interpretaci dat z AI monitoringu v reálném čase a umožňuje sofistikovanější optimalizační strategie. Vzhledem k tomu, že 47 % výzkumníků po celém světě pravidelně využívá AI v tržním výzkumu, spojení metodologie sekundárního výzkumu s AI analytickými nástroji zásadně mění způsob, jakým organizace chápou svou pozici na trhu a viditelnost v AI.
Zajištění kvality dat v sekundárním výzkumu vyžaduje důsledné ověřovací procesy a kritické posouzení důvěryhodnosti zdrojů. Výzkumníci musí zkoumat původní metodologii výzkumu, včetně velikosti vzorku, charakteristik populace, postupů sběru dat a možných zkreslení, která mohla ovlivnit výsledky. Recenzované odborné časopisy udržují vyšší standardy důvěryhodnosti než blogy nebo názorové články, protože procházejí odborným posouzením před publikací. Vládní agentury a renomované výzkumné instituce obvykle uplatňují přísné kontroly kvality, takže jejich data jsou spolehlivější než data z vlastních publikací. Křížové ověřování závěrů z více nezávislých zdrojů pomáhá validovat závěry a odhalit nesrovnalosti, které mohou naznačovat problémy s kvalitou dat. Výzkumníci by měli posoudit, zda časový rámec původní studie odpovídá současným potřebám, protože data získaná před pěti lety nemusí odrážet aktuální situaci na trhu nebo chování spotřebitelů. Datum publikace je zásadní – sekundární data se s postupem času stávají méně relevantními, zejména v rychle se měnících odvětvích. Výzkumníci by také měli zvážit, zda původní metodika odpovídá jejich vlastním požadavkům, jelikož různé metodiky mohou vést k neporovnatelným výsledkům. Kontaktování původních výzkumníků nebo organizací může poskytnout další kontext k procesu sběru dat, míře odpovědí a známým omezením. Tento komplexní validační přístup zajišťuje, že závěry sekundárního výzkumu stojí na důvěryhodných a kvalitních datech, nikoli na potenciálně chybných či zastaralých informacích.
Sekundární výzkum nabízí řadu strategických výhod, které z něj činí nezbytnou součást komplexních výzkumných programů. Snadno dostupná data jsou k dispozici prostřednictvím online databází, knihoven a státních portálů a jejich nalezení a přístup vyžaduje minimální technické znalosti. Rychlejší doba výzkumu umožňuje organizacím zodpovědět výzkumné otázky během dnů namísto měsíců, což podporuje rychlé rozhodování a konkurenceschopnost. Nízké finanční náklady činí sekundární výzkum dostupným i pro organizace s omezeným rozpočtem, a tím demokratizují přístup k tržním poznatkům. Sekundární výzkum může podnítit další výzkumné kroky tím, že odhalí mezery ve znalostech vyžadující primární výzkum, a slouží jako základ pro cílenější studie. Možnost rychle škálovat výsledky pomocí rozsáhlých datových sad, jako jsou sčítací data, umožňuje vyvozovat závěry o širokých populacích bez potřeby drahých průzkumů. Sekundární výzkum poskytuje předběžné poznatky, které organizacím pomáhají rozhodnout, zda má smysl pokračovat ve výzkumu, a tím šetří zdroje, když už odpovědi existují v publikované literatuře. Šíře a hloubka dostupných dat umožňuje zkoumat trendy napříč roky, identifikovat vzorce a pochopit historický kontext důležitý pro současné rozhodování. Organizace mohou využít konkurenční výhody díky přístupu k interním sekundárním datům, která konkurence nemá, a získat tak unikátní poznatky o vlastním výkonu a pozici na trhu.
Přes své výhody přináší sekundární výzkum i významná omezení, která musí výzkumníci pečlivě zvážit. Zastaralá data jsou hlavním rizikem, protože sekundární zdroje nemusí odrážet aktuální situaci na trhu, preference spotřebitelů nebo technologické změny. V rychle se měnících odvětvích mohou být sekundární data zastaralá během několika měsíců, proto je nutné ověřit jejich aktuálnost. Nedostatek kontroly nad metodikou znamená, že výzkumníci nemohou ověřit způsob původního sběru dat, zda byla dodržena kvalitativní kritéria, nebo zda výsledky neovlivnilo neznámé zkreslení. Nemožnost přizpůsobit data konkrétním výzkumným otázkám často nutí výzkumníky přizpůsobit své cíle dostupným informacím místo toho, aby nacházeli data přesně odpovídající svým potřebám. Neexkluzivní přístup k datům znamená, že ke stejným sekundárním zdrojům má přístup i konkurence, čímž odpadá konkurenční výhoda, kterou může přinést primární výzkum. Neznámé zkreslení výzkumníkem ze strany původních sběratelů dat mohlo ovlivnit výsledky způsobem, který současní výzkumníci nemohou odhalit ani napravit. Mezery v relevanci dat mohou vyžadovat doplnění sekundárních zjištění primárním výzkumem k zodpovězení konkrétních otázek. Složitost integrace dat při kombinaci více sekundárních zdrojů s různými metodikami, časovými rámci a populacemi může přinášet analytické výzvy. Výzkumníci musí věnovat značné úsilí ověřování a validaci dat, aby měli jistotu, že sekundární zdroje splňují kvalitativní požadavky a poskytují spolehlivé poznatky.
Budoucnost sekundárního výzkumu je zásadně formována umělou inteligencí, strojovým učením a pokročilými analytickými technologiemi. AI nástroje nyní umožňují výzkumníkům zpracovávat rozsáhlé datové sady, identifikovat složité vzorce a získávat poznatky, které by manuální analýzou nebylo možné zjistit. 83 % odborníků na tržní výzkum plánuje v roce 2025 investovat do AI pro své výzkumné aktivity, což potvrzuje široké uznání transformačního potenciálu AI. Integrace syntetických dat do sekundárního výzkumu zrychluje, více než 70 % výzkumníků očekává, že syntetická data budou tvořit přes 50 % sběru dat během tří let. Tento posun odráží rostoucí význam poznatků generovaných AI a nutnost doplnit tradiční sekundární zdroje algoritmicky generovanými daty. Automatizovaná analýza obsahu využívající zpracování přirozeného jazyka umožňuje výzkumníkům analyzovat kvalitativní sekundární zdroje ve velkém rozsahu, identifikovat témata, sentiment a sémantické vztahy v tisících dokumentů. Propojení sekundárního výzkumu se strategiemi generative engine optimization (GEO) vytváří nové příležitosti pro organizace, jak zjistit, jak AI systémy citují a odkazují na zdroje. Jak se systémy jako ChatGPT, Perplexity a Claude stávají hlavními informačními zdroji pro spotřebitele, sekundární výzkumné metodologie se vyvíjejí tak, aby analyzovaly, jak tyto systémy vybírají, citují a prezentují informace. Organizace stále častěji využívají sekundární výzkum ke stanovení východisek pro AI viditelnost a zjišťují, jak se jejich značky objevují v AI odpovědích ve srovnání s konkurencí. Budoucnost sekundárního výzkumu bude pravděpodobně sofistikovanější, v reálném čase a integrovaná s AI monitorovacími platformami, které sledují zmínky o značce napříč více AI systémy současně. Tento vývoj znamená zásadní posun od tradičního sekundárního výzkumu směrem k dynamické, AI obohacené analýze přinášející kontinuální poznatky o tržní pozici, konkurenčním prostředí a AI viditelnosti.
Organizace, které chtějí maximalizovat efektivitu sekundárního výzkumu, by měly zavést strukturované osvědčené postupy zajišťující důkladnou analýzu a využitelné poznatky. Vymezte jasné výzkumné cíle před zahájením sekundárního výzkumu, přesně specifikujte otázky, které mohou být sekundárními daty zodpovězeny, a určete kritéria úspěchu projektu. Upřednostňujte důvěryhodnost zdrojů výběrem recenzovaných akademických zdrojů, státních agentur a renomovaných výzkumných institucí před vlastními publikacemi či zaujatými zdroji. Zaveďte ověřovací protokoly, které vyžadují křížové ověření závěrů z několika nezávislých zdrojů před vyvozením závěrů. Dokumentujte metodiku zaznamenáváním, které zdroje byly konzultovány, jak byla data analyzována a jaká omezení či zkreslení mohla výsledky ovlivnit. Posuzujte aktuálnost dat ověřením, že sekundární data odrážejí současné podmínky a nejsou zastaralá kvůli rychlým změnám v odvětví. Kombinujte s primárním výzkumem v případech, kdy sekundární data neodpovídají konkrétním výzkumným otázkám nebo je nutné sekundární zjištění ověřit. Využívejte interní data důkladným auditem organizačních databází a předchozích výzkumných projektů před hledáním externích sekundárních zdrojů. Využívejte AI analytické nástroje pro efektivní zpracování velkých sekundárních datových sad a identifikaci vzorců, které by manuální analýza přehlédla. Sledujte AI viditelnost kombinací poznatků ze sekundárního výzkumu s AI monitorovacími platformami jako AmICited, abyste pochopili, jak se značka objevuje v AI odpovědích. Stanovte aktualizační harmonogramy pro sekundární výzkumné projekty, protože tržní podmínky se mění a pravidelná re-analýza může být nutná pro zachování přesnosti poznatků.
Sekundární výzkum zůstává zásadní metodologií pro organizace hledající cenově efektivní a rychlé poznatky o tržních podmínkách, konkurenčním prostředí a spotřebitelských trendech. S pokračující expanzí globálního trhu tržního výzkumu – z 102 miliard v roce 2021 na 140 miliard v roce 2024 – představuje sekundární výzkum stále důležitější součást komplexních výzkumných strategií. Integrace umělé inteligence a technologií strojového učení proměňuje sekundární výzkum z manu
Primární výzkum zahrnuje sběr původních dat přímo ze zdrojů prostřednictvím dotazníků, rozhovorů nebo pozorování, zatímco sekundární výzkum analyzuje existující data dříve shromážděná jinými osobami. Primární výzkum je časově náročnější a dražší, ale poskytuje cílené poznatky, zatímco sekundární výzkum je rychlejší a cenově výhodnější, avšak nemusí přesně odpovídat konkrétním výzkumným otázkám. Obě metody jsou často kombinovány pro komplexní výzkumné strategie.
Zdroje sekundárního výzkumu zahrnují vládní statistiky a sčítací data, odborné časopisy a recenzované publikace, tržní výzkumné zprávy od profesionálních agentur, firemní zprávy a white papery, data oborových asociací, zpravodajské archivy a mediální publikace a interní databáze organizací. Tyto zdroje mohou být interní (z vaší organizace) nebo externí (veřejně dostupné či zakoupené od třetích stran). Volba zdroje závisí na cílech výzkumu, relevanci dat a požadavcích na důvěryhodnost.
Sekundární výzkum eliminuje náklady na sběr dat, protože informace již byly shromážděny a zpracovány jinými. Výzkumníci se vyhnou nákladům spojeným s náborem účastníků, vedením dotazníků či rozhovorů a správou terénních operací. Navíc jsou sekundární data často dostupná zdarma nebo za minimální poplatek prostřednictvím veřejných databází, knihoven a státních agentur. Organizace mohou ušetřit 50–70 % rozpočtu na výzkum využitím existujících datových sad, což je ideální pro týmy s omezenými zdroji.
Data ze sekundárního výzkumu mohou být zastaralá a nemusí zachycovat nedávné změny trhu nebo trendy. Původní metodika sběru dat nemusí být známá, což vyvolává otázky ohledně kvality a validity dat. Výzkumníci nemají kontrolu nad způsobem sběru dat, což může přinášet neznámé zkreslení. Sekundární datové sady nemusí přesně odpovídat konkrétním výzkumným otázkám, což od výzkumníků vyžaduje přizpůsobení jejich cílů. Sekundární data navíc nejsou exkluzivní, což znamená, že ke stejným informacím mají přístup i konkurenti.
Organizace by měly před použitím sekundárních dat prověřit původní metodiku výzkumu, datum publikace a pověst zdroje. Recenzované odborné časopisy a státní agentury zpravidla udržují vyšší standardy důvěryhodnosti než blogy nebo názorové články. Křížové ověřování dat z více nezávislých zdrojů pomáhá potvrdit zjištění a odhalit nesrovnalosti. Výzkumníci by měli posoudit, zda velikost vzorku, populace a design původní studie odpovídají jejich potřebám. Kontaktování původních výzkumníků nebo organizací může poskytnout další informace o procesech sběru dat.
Sekundární výzkum poskytuje historický kontext a výchozí data pro AI monitorovací platformy, jako je AmICited, které sledují zmínky o značce v AI systémech jako ChatGPT, Perplexity a Claude. Analýzou existujících dat o zmínkách konkurence, trendech v odvětví a historické výkonnosti značky mohou organizace stanovit měřítka pro viditelnost v AI. Sekundární výzkum pomáhá identifikovat vzorce v tom, jak AI systémy citují zdroje, což značkám umožňuje optimalizovat obsahovou strategii pro lepší citace a viditelnost ve výsledcích generativního vyhledávání.
AI nástroje nyní automatizují analýzu sekundárních dat, což výzkumníkům umožňuje rychleji zpracovávat velké datové sady a identifikovat vzorce, které by bylo obtížné zjistit ručně. Přibližně 47 % výzkumníků po celém světě pravidelně využívá AI ve svých aktivitách tržního výzkumu, přičemž v Asii a Pacifiku dosahuje adopce 58 %. Nástroje pro analýzu obsahu poháněné AI dokážou rozpoznat témata, sémantické souvislosti a vztahy v rámci sekundárních zdrojů. Ovšem 73 % výzkumníků vyjadřuje důvěru v aplikaci AI na sekundární výzkum, zatímco některé týmy stále mají obavy z nedostatku dovedností.
Sekundární výzkum lze dokončit během dnů až týdnů, protože data jsou již shromážděna a uspořádána, zatímco primární výzkum obvykle vyžaduje týdny až měsíce plánování, sběru dat a analýzy. Organizace mají okamžitý přístup k sekundárním datům přes online databáze a knihovny, což umožňuje rychlé rozhodování. Tato rychlost činí sekundární výzkum ideálním pro časově citlivá obchodní rozhodnutí, konkurenční analýzy i přípravné fáze výzkumu. Nevýhodou však je, že sekundární data nemusí poskytovat specifické a aktuální poznatky jako primární výzkum.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Zjistěte, co je fáze shromažďování informací ve výzkumu, jaký má význam v metodologii výzkumu, jaké existují techniky sběru dat a jak ovlivňuje AI monitoring a ...

Původní výzkum a prvotní data jsou proprietární studie a zákaznické informace shromažďované přímo značkami. Zjistěte, jak budují autoritu, zvyšují citovanost v ...
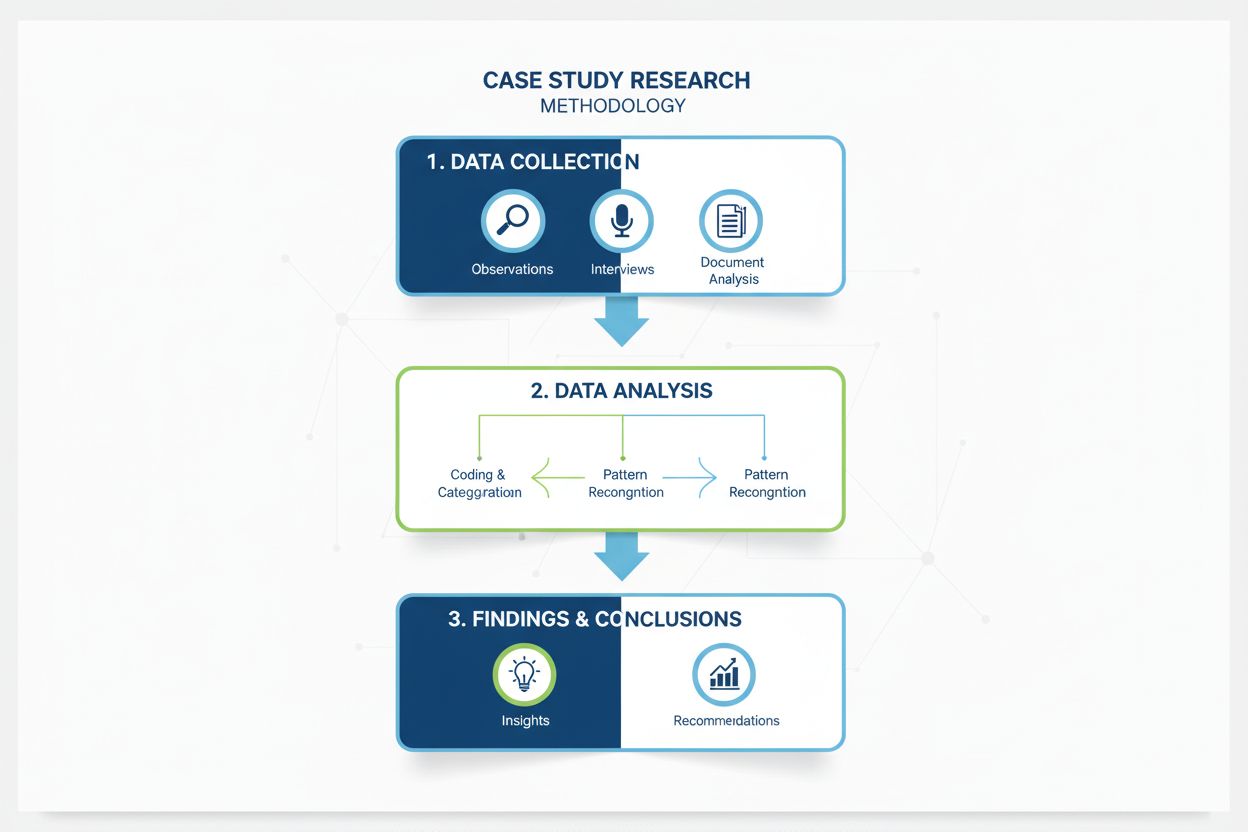
Komplexní definice metodologie výzkumu případových studií. Zjistěte, jak případové studie poskytují hlubokou analýzu konkrétních příkladů, metody sběru dat a up...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.