Definice Sonar algoritmu
Sonar algoritmus je proprietární retrieval-augmented generation (RAG) hodnoticí systém společnosti Perplexity, který pohání její answer engine kombinací hybridního sémantického a klíčového vyhledávání, neuronového přeřazování a generování citací v reálném čase. Na rozdíl od tradičních vyhledávačů, které řadí stránky pro zobrazení v seznamu výsledků, Sonar řadí úryvky obsahu pro syntézu do jediné sjednocené odpovědi s inline citacemi na zdrojové dokumenty. Algoritmus upřednostňuje aktuálnost obsahu, sémantickou relevanci a citovatelnost, aby poskytoval podložené odpovědi s ověřenými zdroji a minimalizoval halucinace. Sonar představuje zásadní posun v tom, jak AI systémy získávají a hodnotí informace – přechází od signálů autority na základě odkazů k metrikám užitečnosti zaměřeným na odpověď, které zdůrazňují, zda obsah přímo splňuje uživatelský záměr a lze jej čistě citovat v syntetizovaných odpovědích. Toto rozlišení je klíčové pro pochopení, jak se liší viditelnost v AI answer enginech od tradičního SEO, protože Sonar hodnotí obsah ne podle schopnosti umístit se v seznamu, ale podle možnosti být extrahován, syntetizován a přiřazen ve AI-generované odpovědi.
Kontext a pozadí: Vývoj AI poháněných hodnoticích systémů
Vznik Sonar algoritmu odráží širší posun v průmyslu směrem k retrieval-augmented generation jako dominantní architektuře pro AI answer engine. Když Perplexity spustila službu koncem roku 2022, identifikovala zásadní mezeru v AI prostředí: zatímco ChatGPT nabízel silné konverzační schopnosti, chyběl mu přístup k aktuálním informacím a citace zdrojů, což vedlo k halucinacím a zastaralým odpovědím. Zakladatelský tým Perplexity, který původně pracoval na nástroji pro překlad databázových dotazů, se zcela přeorientoval na vybudování answer engine, který by dokázal spojit živé webové vyhledávání se syntézou LLM. Toto strategické rozhodnutí od počátku formovalo architekturu Sonaru – algoritmus byl navržen nikoli pro řazení stránek k lidskému prohlížení, ale pro získávání a řazení fragmentů obsahu pro strojovou syntézu a citování. Za poslední dva roky se Sonar vyvinul v jeden z nejsofistikovanějších hodnoticích systémů v AI ekosystému, přičemž modely Sonar společnosti Perplexity obsadily 1. až 4. místo v Search Arena Evaluation, což výrazně předčilo konkurenční modely Googlu a OpenAI. Algoritmus nyní zpracovává přes 400 milionů vyhledávacích dotazů měsíčně, indexuje přes 200 miliard unikátních URL a udržuje aktuálnost v reálném čase díky desítkám tisíc aktualizací indexu za sekundu. Tento rozsah a sofistikovanost podtrhují význam Sonaru jako určujícího hodnoticího paradigmatu v éře AI vyhledávání.
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
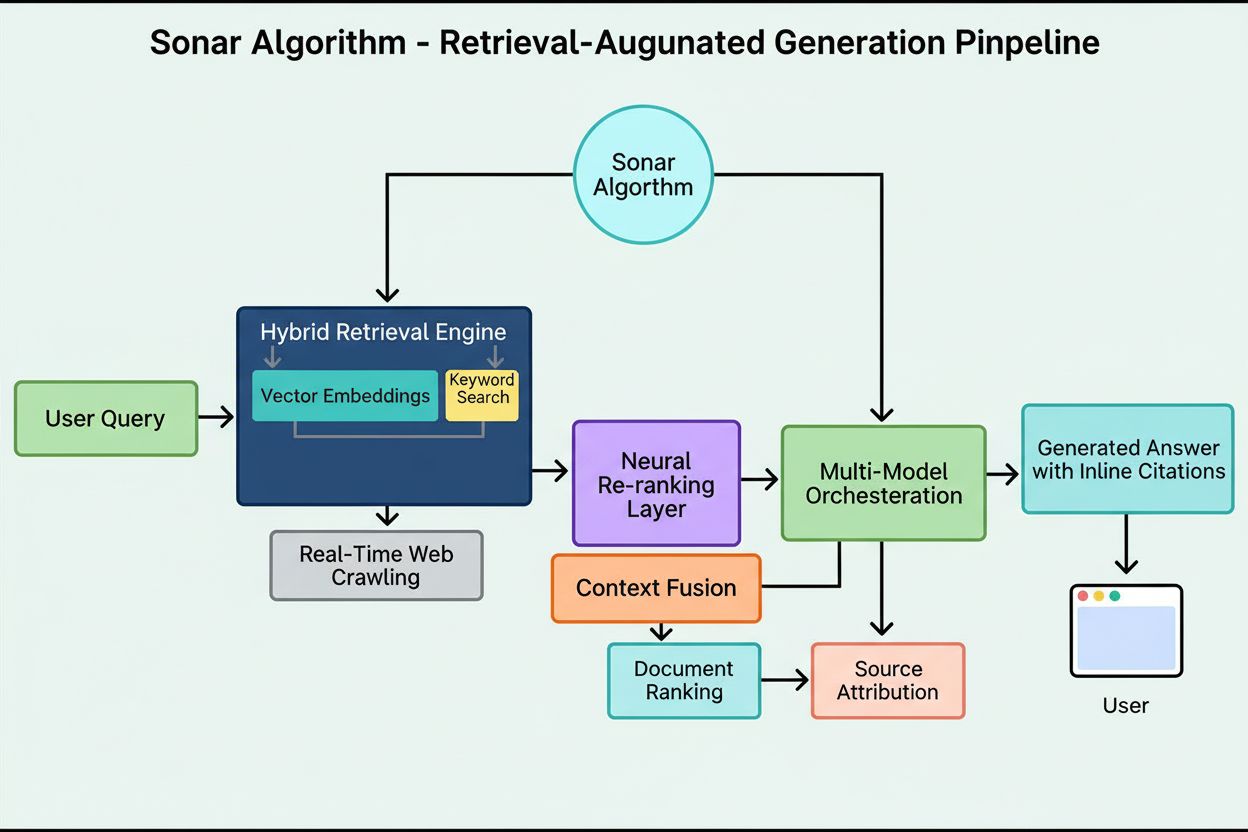
Jak Sonar algoritmus funguje: vícefázový RAG pipeline
Hodnoticí systém Sonaru funguje prostřednictvím pečlivě koordinovaného pětifázového retrieval-augmented generation pipeline, který proměňuje uživatelské dotazy v podložené, citované odpovědi. První fáze, analýza záměru dotazu, využívá LLM k překonání prostého porovnávání klíčových slov a dosažení sémantického porozumění skutečnému záměru uživatele, včetně kontextu, nuancí a skrytých cílů. Druhá fáze, živé webové vyhledávání, předává analyzovaný dotaz do masivního distribuovaného indexu Perplexity postaveného na Vespa AI, který v reálném čase prohledává web pro relevantní stránky a dokumenty. Tento vyhledávací systém kombinuje dense retrieval (vektorové vyhledávání pomocí sémantických embeddingů) a sparse retrieval (lexikální/klíčová slova), jejichž výsledky spojuje a produkuje přibližně 50 rozmanitých kandidátních dokumentů. Třetí fáze, extrakce úryvků a kontextualizace, neposkytuje generativnímu modelu celý text stránky; místo toho algoritmy extrahují nejrelevantnější úryvky, odstavce nebo „chuncks“ přímo související s dotazem a agregují je do zaměřeného kontextového okna. Čtvrtá fáze, generování syntetizované odpovědi s citacemi, předává tento kurátorský kontext vybranému LLM (z proprietární rodiny Sonar Perplexity nebo modelům třetích stran jako GPT-4 či Claude), který generuje odpověď v přirozeném jazyce čistě na základě získaných informací. Klíčové je, že inline citace propojují každé tvrzení zpět ke zdrojovým dokumentům, což zajišťuje transparentnost a umožňuje ověření. Pátá fáze, konverzační upřesňování, zachovává kontext napříč více dotazy a umožňuje upřesňování odpovědí pomocí iterativních webových vyhledávání. Definujícím principem tohoto pipeline je „nemáte říkat nic, co jste nezískali“, což zajišťuje, že odpovědi poháněné Sonarem jsou založené na ověřitelných zdrojích a zásadně snižují halucinace ve srovnání s modely spoléhajícími pouze na trénovací data.
Srovnávací tabulka: Sonar algoritmus vs. tradiční vyhledávání a konkurenční LLM hodnoticí systémy
| Aspekt | Tradiční vyhledávání (Google) | Sonar algoritmus (Perplexity) | ChatGPT hodnocení | Gemini hodnocení | Claude hodnocení |
|---|
| Primární jednotka | Seřazený seznam odkazů | Jediná syntetizovaná odpověď s citacemi | Zmínky entit na základě konsenzu | Obsah sladěný s E-E-A-T | Neutrální, faktické zdroje |
| Fokus vyhledávání | Klíčová slova, odkazy, ML signály | Hybridní sémantické + klíčové vyhledávání | Trénovací data + web browsing | Integrace znalostního grafu | Ústavní bezpečnostní filtry |
| Priorita aktuálnosti | Query-deserves-freshness (QDF) | Živé webové dotazy, 37% nárůst do 48 h | Nižší priorita, závislé na trénovacích datech | Střední, integrované s Google Search | Nižší priorita, důraz na stabilitu |
| Signály hodnocení | Zpětné odkazy, autorita domény, CTR | Aktuálnost obsahu, sémantická relevance, citovatelnost, autoritní zvýhodnění | Rozpoznání entit, zmínky konsenzu | E-E-A-T, konverzační sladění, strukturovaná data | Transparentnost, ověřitelné citace, neutralita |
| Mechanismus citací | Úryvky URL ve výsledcích | Inline citace s odkazy na zdroje | Implicitní, často bez citací | AI Overviews s přiřazením | Explicitní přiřazení zdroje |
| Diverzita obsahu | Více výsledků napříč weby | Výběr několika zdrojů pro syntézu | Syntetizováno z více zdrojů | Více zdrojů v přehledu | Vyvážené, neutrální zdroje |
| Personalizace | Skrytá, většinou implicitní | Explicitní fokus módy (Web, Academic, Finance, Writing, Social) | Implicitní dle konverzace | Implicitní dle typu dotazu | Minimální, důraz na konzistenci |
| Práce s PDF | Standardní indexace | 22% výhoda v citacích oproti HTML | Standardní indexace | Standardní indexace | Standardní indexace |
| Vliv schema markup | FAQ schema ve featured snippets | FAQ schema zvyšuje citace o 41 %, zkracuje čas k citaci o 6 h | Minimální přímý vliv | Střední vliv na knowledge graph | Minimální přímý vliv |
| Optimalizace latence | Milisekundy pro hodnocení | Podsekundové vyhledání + generování | Sekundy pro syntézu | Sekundy pro syntézu | Sekundy pro syntézu |
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Technická architektura: hybridní retrieval a neuronové přeřazování
Technický základ Sonar algoritmu spočívá v hybridním retrieval engine, který kombinuje více vyhledávacích strategií pro maximalizaci jak recall, tak přesnosti. Dense retrieval (vektorové vyhledávání) využívá sémantické embeddingy k pochopení konceptuálního významu dotazů a najde kontextově podobné dokumenty i bez přesné shody klíčových slov. Tento přístup využívá embeddingy založené na transformerech, které mapují dotazy a dokumenty do vícerozměrných vektorových prostorů, kde se sémanticky podobný obsah shlukuje. Sparse retrieval (lexikální vyhledávání) doplňuje dense retrieval přesností u vzácných výrazů, názvů produktů, interních identifikátorů a konkrétních entit, kde je sémantická nejednoznačnost nežádoucí. Systém používá hodnoticí funkce jako BM25 pro přesnou shodu těchto klíčových výrazů. Tyto dvě metody jsou sloučeny a deduplikovány na přibližně 50 rozmanitých kandidátních dokumentů, což zabraňuje přeučení na jednu doménu a zajišťuje široké pokrytí napříč autoritativními zdroji. Po počátečním získávání neuronová reranking vrstva Sonaru využívá pokročilé ML modely (např. DeBERTa-v3 cross-encodery) k vyhodnocení kandidátů podle bohatého spektra znaků včetně lexikálních skóre, vektorové podobnosti, autority dokumentu, signálů aktuálnosti, engagementu uživatelů a metadat. Tato vícefázová hodnoticí architektura umožňuje Sonaru průběžně zpřesňovat výsledky v rámci časových limitů, aby konečný seřazený set představoval nejkvalitnější a nejrelevantnější zdroje pro syntézu. Celá retrieval infrastruktura je postavena na Vespa AI, distribuované vyhledávací platformě schopné zvládat web-scale indexaci (200+ miliard URL), aktualizace v reálném čase (desítky tisíc za sekundu) a detailní porozumění obsahu díky chunkování dokumentů. Toto architektonické rozhodnutí umožňuje relativně malému týmu inženýrů Perplexity soustředit se na odlišující komponenty – orchestraci RAG, doladění Sonar modelů a optimalizaci inference – místo opětovného vynalézání distribuovaného vyhledávání.
Aktuálnost obsahu jako dominantní hodnoticí faktor
Aktuálnost obsahu je jedním z nejsilnějších hodnoticích signálů Sonaru, přičemž empirický výzkum ukazuje, že nedávno aktualizované stránky mají výrazně vyšší četnost citací. V kontrolovaných A/B testech trvajících 24 týdnů napříč 120 URL byly články aktualizované během posledních 48 hodin citovány o 37 % častěji než totožný obsah se starším časovým razítkem. Tento náskok přetrval na přibližně 14 % po dvou týdnech, což znamená, že aktuálnost zajišťuje trvalou, i když postupně klesající výhodu. Mechanismus této priority je zakořeněn v designové filozofii Sonaru: algoritmus považuje zastaralý obsah za vyšší riziko halucinací, předpokládá, že staré informace mohly být překonány novým vývojem. Infrastruktura Perplexity zpracovává desítky tisíc požadavků na aktualizaci indexu za sekundu, což umožňuje signály aktuálnosti v reálném čase. ML model předpovídá, zda daná URL vyžaduje přeindexování a plánuje aktualizace podle důležitosti stránky a její historické frekvence úprav, takže hodnotný obsah je obnovován agresivněji. I drobné kosmetické úpravy resetují „hodiny aktuálnosti“, pokud CMS aktualizuje časové razítko. Pro vydavatele to znamená strategickou nutnost: buď přijmout redakční kadenci s týdenními či denními aktualizacemi, nebo sledovat, jak „evergreen“ obsah postupně ztrácí viditelnost. Dopad je zásadní – v éře Sonaru je rychlost obsahu otázkou přežití, ne pouze kosmetickým ukazatelem. Značky, které automatizují týdenní mikro-aktualizace, přidávají živé changelogy nebo udržují kontinuální optimalizační workflow, získají neúměrný podíl citací oproti konkurenci spoléhající na statické, zřídka aktualizované stránky.
Sémantická relevance a struktura obsahu zaměřená na odpověď
Sonar upřednostňuje sémantickou relevanci před hustotou klíčových slov a zásadně odměňuje obsah, který přímo odpovídá uživatelským dotazům v přirozeném, konverzačním jazyce. Vyhledávací systém algoritmu používá dense vektorové embeddingy pro párování dotazů s obsahem na konceptuální úrovni, což znamená, že stránky používající synonyma, související terminologii nebo kontextově bohatý jazyk mohou překonat stránky přeplněné klíčovými slovy bez sémantické hloubky. Tento posun od klíčového slova k významu má zásadní dopady na obsahovou strategii. Obsah, který v Sonaru vítězí, má několik strukturálních znaků: začíná krátkým, faktickým shrnutím před detailním rozborem, používá deskriptivní H2/H3 nadpisy a krátké odstavce pro snadnou extrakci pasáží, obsahuje jasné citace a odkazy na primární zdroje a má viditelná časová razítka a poznámky o verzích na signalizaci aktuálnosti. Každý odstavec funguje jako atomická sémantická jednotka optimalizovaná pro copy-paste jasnost a LLM pochopení. Tabulky, odrážky a popsané grafy jsou zvláště cenné, protože prezentují informace ve strukturované, snadno citovatelné podobě. Algoritmus také odměňuje původní analýzy a unikátní data před pouhými agregacemi, protože Sonar hledá zdroje přinášející nové pohledy, primární dokumenty nebo vlastní postřehy, které je odlišují od generických přehledů. Tento důraz na sémantické bohatství a strukturu zaměřenou na odpověď znamená zásadní odklon od tradičního SEO, kde dominovalo umístění klíčových slov a autorita odkazů. V éře Sonaru musí být obsah navržen pro strojové získání a syntézu, ne pro lidské prohlížení.
Hosting PDF jako strategická výhoda
Veřejně hostované PDF představují v hodnoticím systému Sonaru výraznou, často přehlíženou výhodu, přičemž empirické testy ukazují, že PDF verze obsahu překonávají HTML ekvivalenty přibližně o 22 % v četnosti citací. Tato výhoda vyplývá z toho, že crawler Sonaru PDF upřednostňuje oproti HTML stránkám. PDF neobsahují cookie lišty, požadavky na vykreslení JavaScriptu, paywally ani další HTML komplikace, které mohou obsah skrýt či zpomalit jeho přístupnost. Crawler Sonaru dokáže PDF přečíst čistě a předvídatelně, extrahovat text bez problémů s parsováním, jaké přinášejí komplexní HTML struktury. Vydavatelé mohou tuto výhodu strategicky využít hostováním PDF ve veřejně přístupných složkách, používáním sémantických názvů souborů a označením PDF jako kanonických pomocí tagu <link rel="alternate" type="application/pdf"> v hlavičce HTML. Tím vzniká tzv. „LLM honey-trap“ – vysoce viditelné aktivum, které konkurenční sledovací skripty obtížně detekují či monitorují. Pro B2B firmy, SaaS dodavatele a výzkumně orientované organizace je tato strategie zvláště účinná: publikace whitepapers, výzkumných zpráv, případových studií a technické dokumentace jako PDF může dramaticky zvýšit četnost citací v Sonaru. Klíčem je chápat PDF nikoli jako pouhou přílohu, ale jako kanonickou kopii zasluhující stejnou nebo vyšší optimalizační péči než HTML verze. Tento přístup se ukázal jako mimořádně efektivní zejména pro enterprise obsah, kde PDF často obsahují strukturovanější a autoritativnější informace než webové stránky.
FAQ schema markup a optimalizace strukturovaných dat
JSON-LD FAQ schema markup výrazně zvyšuje četnost citací v Sonaru, stránky obsahující tři a více FAQ bloků získávají citace o 41 % častěji než kontrolní stránky bez schématu. Tento dramatický nárůst odráží preferenci Sonaru pro strukturovaný, chunk-based obsah, který ladí s jeho logikou retrieval a syntézy. FAQ schema přináší oddělené, samostatné Q&A jednotky, které algoritmus snadno extrahuje, řadí a cituje jako atomické sémantické bloky. Na rozdíl od tradičního SEO, kde bylo FAQ schema spíše „nice-to-have“, Sonar považuje strukturované Q&A markup za klíčový hodnoticí pákový bod. Sonar navíc často cituje FAQ otázky jako anchor text, což omezuje riziko posunu kontextu, které nastává při sumarizaci náhodných vět uprostřed odstavce LLM. Schéma také urychluje čas první citace o přibližně šest hodin, což naznačuje, že parser Sonaru strukturované Q&A bloky upřednostňuje v rané fázi hodnoticí kaskády. Pro vydavatele je optimalizační strategie jasná: vložte tři až pět cílených FAQ bloků pod úvod, použijte konverzační spouštěcí fráze odrážející reálné uživatelské dotazy. Otázky by měly využívat long-tail vyhledávací fráze a sémantickou symetrii s pravděpodobnými Sonar dotazy. Každá odpověď by měla být stručná, faktická a přímo reagovat, bez vaty nebo marketingových tvrzení. Tento přístup se osvědčil zejména pro SaaS firmy, zdravotnická zařízení a profesionální služby, kde FAQ obsah přirozeně odpovídá uživatelskému záměru i potřebám syntézy Sonaru.
Hodnoticí faktory a mechanismy citací: Komplexní rámec
Hodnoticí systém Sonaru integruje více signálů do jednotného rámce citací, přičemž výzkum identifikoval osm hlavních faktorů ovlivňujících výběr zdrojů a četnost citací. Prvním je sémantická relevance k otázce, která dominuje retrieval a algoritmus upřednostňuje obsah, který jasně a přirozeně odpovídá dotazu. Druhým je autorita a důvěryhodnost – partnerství Perplexity s vydavateli a algoritmické zvýhodnění upřednostňuje zavedené zpravodajské organizace, akademické instituce a uznávané experty. Třetím je aktuálnost – jak bylo popsáno výše, nedávné aktualizace vyvolávají 37% nárůst citací. Čtvrtým je diverzita a pokrytí – Sonar preferuje více kvalitních zdrojů před odpověďmi z jednoho, čímž snižuje riziko halucinací skrze vzájemnou validaci. Pátým je mód a rozsah – určují, které indexy Sonar prohledává; focus módy jako Academic, Finance, Writing a Social zužují typy zdrojů, zatímco voliče zdrojů (Web, Org Files, Web + Org Files, None) určují, zda retrieval sahá do otevřeného webu, interních dokumentů, či obojího. Šestým je citovatelnost a přístupnost – pokud PerplexityBot může obsah procházet a indexovat, je snadnější jej citovat, takže robots.txt compliance a rychlost načítání stránek jsou klíčové. Sedmým jsou vlastní filtry zdrojů přes API – enterprise nasazení mohou preferovat nebo omezovat určité domény, což mění pořadí v rámci whitelistovaných kolekcí. Osmým je konverzační kontext – ovlivňuje navazující dotazy; stránky ladící s vy