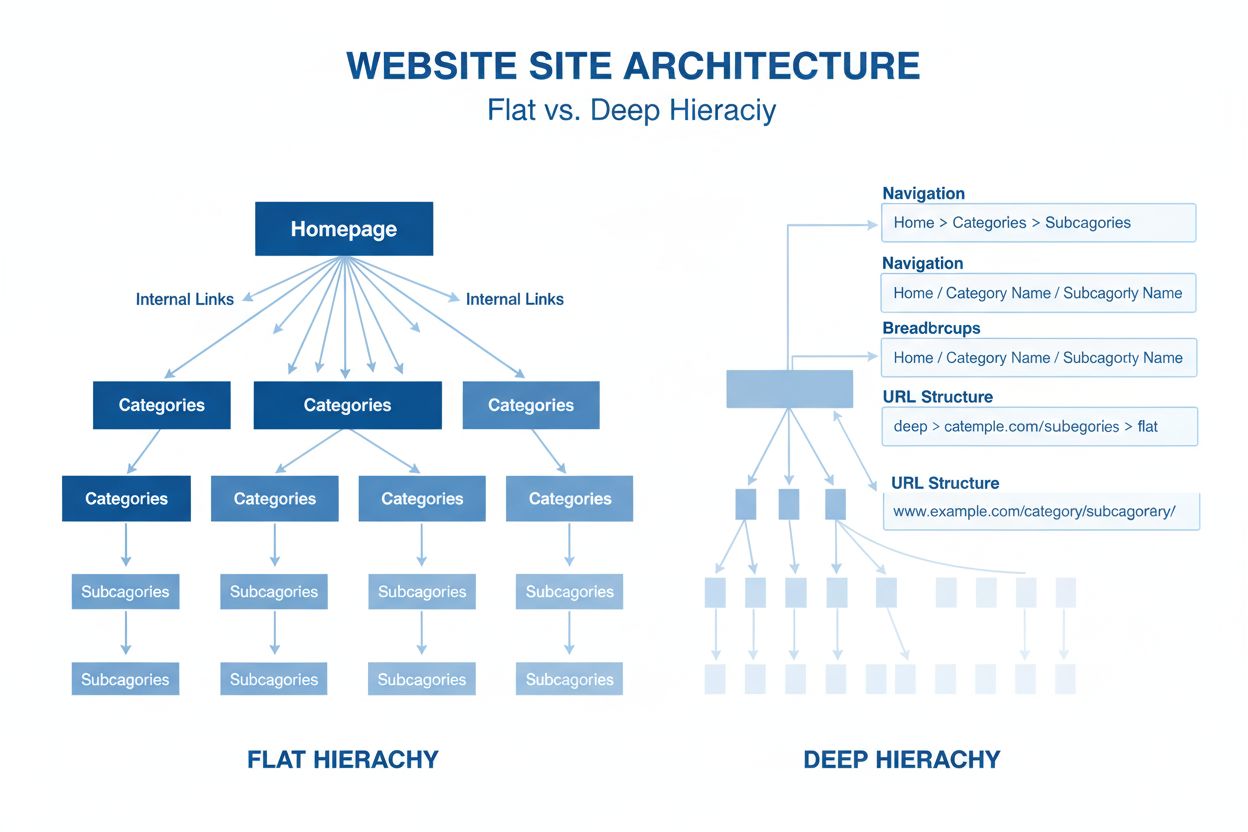
Architektura webu
Architektura webu je hierarchické uspořádání stránek a obsahu webových stránek. Zjistěte, jak správná struktura webu zlepšuje SEO, uživatelskou zkušenost a vidi...
8 min čtení

Neuronová síťová architektura založená na mechanismu vícehlavé self-attention, která zpracovává sekvenční data paralelně a umožnila vznik moderních velkých jazykových modelů, jako jsou ChatGPT, Claude a Perplexity. Transformátory, představené ve studii z roku 2017 ‘Attention is All You Need’, se staly základní technologií téměř všech nejmodernějších AI systémů.
Neuronová síťová architektura založená na mechanismu vícehlavé self-attention, která zpracovává sekvenční data paralelně a umožnila vznik moderních velkých jazykových modelů, jako jsou ChatGPT, Claude a Perplexity. Transformátory, představené ve studii z roku 2017 'Attention is All You Need', se staly základní technologií téměř všech nejmodernějších AI systémů.
Transformátorová architektura je revoluční návrh neuronové sítě, představený ve studii „Attention is All You Need“ z roku 2017 výzkumníky z Googlu. Je založena především na mechanismech vícehlavé self-attention, které umožňují modelům zpracovávat celé sekvence dat paralelně, nikoli sekvenčně. Architektura se skládá ze zásobníku enkodérových a dekodérových vrstev, z nichž každá obsahuje subvrstvy self-attention a dopředné neuronové sítě, propojené reziduálními spoji a normalizací vrstev. Transformátorová architektura se stala základní technologií téměř všech moderních velkých jazykových modelů (LLM), včetně ChatGPT, Claude, Perplexity a Google AI Overviews, a je proto pravděpodobně nejdůležitější inovací neuronových sítí posledního desetiletí.
Význam transformátorové architektury přesahuje její technickou eleganci. Studie „Attention is All You Need“ z roku 2017 byla citována více než 208 000krát a je jedním z nejvlivnějších výzkumných článků v oblasti strojového učení vůbec. Tato architektura zásadně změnila způsob, jakým AI systémy zpracovávají a chápou jazyk, a umožnila vývoj modelů s miliardami parametrů, které zvládají sofistikované uvažování, kreativní psaní i složité řešení problémů. Trh podnikových LLM, téměř výhradně postavený na transformátorové technologii, byl v roce 2024 oceněn na 6,7 miliardy dolarů a očekává se, že poroste složenou roční mírou růstu 26,1 % až do roku 2034, což dokládá klíčovou roli architektury v moderní AI infrastruktuře.
Vývoj transformátorové architektury představuje zásadní zlom v historii deep learningu a navazuje na desetiletí výzkumu neuronových sítí pro zpracování sekvenčních dat. Před nástupem transformátorů dominovaly úlohám zpracování přirozeného jazyka rekurentní neuronové sítě (RNN) a jejich varianty, zejména long short-term memory (LSTM) sítě. Tyto architektury však měly zásadní omezení: sekvence zpracovávaly sekvenčně, prvek po prvku, což bylo pomalé a ztěžovalo zachycení vztahů mezi vzdálenými prvky v dlouhých sekvencích. Problém mizejícího gradientu dále omezoval schopnost RNN učit se dlouhodobé vztahy, protože gradienty při zpětném průchodu mnoha vrstvami exponenciálně slábly.
Zavedení mechanismů pozornosti v roce 2014 od Bahdanaua a kolegů přineslo průlom, protože modely mohly zaměřit pozornost na relevantní části vstupní sekvence bez ohledu na vzdálenost. Zpočátku však byla pozornost pouze rozšířením RNN, nikoli jejich náhradou. Transformátor z roku 2017 posunul tento koncept dále a navrhl, že pozornost je vše, co potřebujete – tedy že celou neuronovou síť lze postavit pouze s mechanismy pozornosti a dopřednými vrstvami, zcela bez rekurence. Tento postřeh byl zásadní. Odstraněním sekvenčního zpracování umožnily transformátory masivní paralelizaci, což výzkumníkům dovolilo trénovat na dosud nevídaných objemech dat pomocí GPU a TPU. Největší model v původní studii byl trénován na 8 GPU po dobu 3,5 dne a ukázal, že škálování a paralelizace mohou dramaticky zlepšit výkon.
Po původní studii se architektura rychle vyvíjela. BERT (Bidirectional Encoder Representations from Transformers), uvedený Googlem v roce 2019, ukázal, že enkodéry transformátorů lze předtrénovat na masivních korpusech textu a následně doladit pro různé úlohy. Největší model BERT měl 345 milionů parametrů a byl trénován na 64 specializovaných TPU čtyři dny s odhadovanými náklady 7 000 USD, přesto dosáhl špičkových výsledků v mnoha jazykových benchmarcích. Současně OpenAI série GPT zvolila jinou cestu, když využila pouze dekodérové transformátory trénované na úloze modelování jazyka. GPT-2 s 1,5 miliardou parametrů překvapil komunitu tím, že modelování jazyka samotné může vést ke vzniku velmi schopných systémů. GPT-3 se 175 miliardami parametrů ukázal emergentní schopnosti – dovednosti, které se objevily až při velkém měřítku, včetně few-shot učení a komplexního uvažování – a zásadně změnil očekávání od AI systémů.
Transformátorová architektura se skládá z několika propojených technických komponent, které společně umožňují efektivní paralelní zpracování a sofistikované porozumění kontextu. Vstupní embedding vrstva převádí diskrétní tokeny (slova nebo podslova) na spojité vektorové reprezentace, obvykle rozměru 512 nebo vyšší. Tyto embeddingy jsou rozšířeny o poziční zakódování, které přidává informaci o pozici každého tokenu v sekvenci pomocí sinusových a kosinových funkcí na různých frekvencích. Tato poziční informace je klíčová, protože na rozdíl od RNN, které uchovávají pořadí sekvence svou rekurentní strukturou, transformátory zpracovávají všechny tokeny současně a potřebují explicitní signály pro pořadí a vzdálenosti slov.
Mechanismus self-attention je architektonickou inovací, která odlišuje transformátory od všech předchozích návrhů neuronových sítí. Pro každý token ve vstupní sekvenci model počítá tři vektory: Query vektor (co token hledá), Key vektory (co každý token obsahuje) a Value vektory (jaká informace má být předána). Mechanismus pozornosti vypočítá podobnost mezi Query jednoho tokenu a Key všech tokenů pomocí skalárního součinu, tyto skóre normalizuje softmaxem a vytvoří tak váhy pozornosti mezi 0 a 1. Následně použije tyto váhy na Value vektory a vytvoří vážený součet. Tento proces umožňuje každému tokenu selektivně se zaměřit na jiné relevantní tokeny a chápat kontext i vztahy.
Vícehlavá pozornost rozšiřuje tento koncept spuštěním více paralelních mechanismů pozornosti, obvykle 8, 12 či 16 hlav. Každá hlava pracuje s jinými lineárními projekcemi Query, Key a Value vektorů, což modelu umožňuje sledovat různé typy vztahů a vzorců v různých podprostorech reprezentace. Například jedna hlava může sledovat syntaktické vztahy mezi slovy, zatímco jiná se zaměřuje na sémantiku či dlouhodobé závislosti. Výstupy všech hlav jsou spojeny a lineárně transformovány, takže model získává bohaté a mnohovrstevné kontextové informace. Tento přístup se ukázal jako velmi účinný a výzkumy potvrzují, že různé hlavy se specializují na různé jazykové jevy.
Enkodér-dekodér struktura organizuje tyto mechanismy pozornosti do hierarchického zpracovatelského řetězce. Enkodér se skládá z více vrstev (typicky 6 a více), z nichž každá obsahuje subvrstvu vícehlavé self-attention a dopřednou neuronovou síť pro každou pozici. Reziduální spoje kolem každé subvrstvy zajišťují, že gradienty mohou protékat přímo skrz síť během tréninku, což zlepšuje stabilitu a umožňuje hlubší architektury. Normalizace vrstev po každé subvrstvě udržuje aktivace ve stabilních měřítcích. Dekodér má podobnou strukturu, ale navíc obsahuje enkodér-dekodér attention vrstvu, která umožňuje dekodéru zaměřit se na výstup enkodéru, což je klíčové při generování každého výstupního tokenu. V čistě dekodérových architekturách, jako je GPT, dekodér generuje tokeny autoregresivně, přičemž každý nový token závisí na předchozích vygenerovaných tokenech.
| Aspekt | Transformátorová architektura | RNN/LSTM | Konvoluční neuronové sítě (CNN) |
|---|---|---|---|
| Způsob zpracování | Paralelní zpracování celých sekvencí pomocí pozornosti | Sekvenční zpracování, prvek po prvku | Lokální konvoluce na fixních oknech |
| Dlouhodobé závislosti | Výborné; pozornost přímo spojuje vzdálené tokeny | Slabé; omezeno mizejícími gradienty a sekvenčním úzkým hrdlem | Omezené; lokální pole vyžaduje mnoho vrstev |
| Rychlost tréninku | Velmi rychlá; masivní paralelizace na GPU/TPU | Pomalá; sekvenční zpracování brání paralelizaci | Rychlá pro fixní vstupy; méně vhodná pro proměnlivé sekvence |
| Paměťové nároky | Vysoké; kvadratické k délce sekvence kvůli pozornosti | Nižší; lineární k délce sekvence | Střední; závisí na velikosti kernelu a hloubce |
| Škálovatelnost | Výborná; škáluje se na miliardy parametrů | Omezená; obtížné trénovat velmi velké modely | Dobrá pro obrazy; méně vhodná pro sekvence |
| Typické použití | Modelování jazyka, strojový překlad, generování textu | Časové řady, sekvenční predikce (dnes méně běžné) | Klasifikace obrazů, detekce objektů, počítačové vidění |
| Propagace gradientu | Stabilní; reziduální spoje umožňují hluboké sítě | Problematičtí; mizející/explodující gradienty | Obvykle stabilní; lokální propojení pomáhá toku gradientu |
| Informace o pozici | Explicitní poziční zakódování | Implicitní díky sekvenčnímu zpracování | Implicitní díky prostorové struktuře |
| Moderní LLM | GPT, Claude, Llama, Granite, Perplexity | V moderních LLM zřídka | Nepoužívají se pro modelování jazyka |
Vztah mezi transformátorovou architekturou a moderními velkými jazykovými modely je zásadní a neoddělitelný. Každý významný LLM vydaný v posledních pěti letech – včetně OpenAI GPT-4, Anthropic Claude, Meta Llama, Google Gemini, IBM Granite a modely Perplexity AI – je postaven na transformátorové architektuře. Schopnost architektury efektivně škálovat jak velikostí modelu, tak trénovacích dat, je zásadní pro dosažení schopností, které definují moderní AI systémy. Když výzkumníci zvětšovali modely z milionů na miliardy či stovky miliard parametrů, paralelizace a mechanismy pozornosti transformátorů umožnily toto škálování bez úměrného prodlužování doby tréninku.
Autoregresivní dekódování používané většinou moderních LLM je přímou aplikací dekodérové transformátorové architektury. Při generování textu tyto modely zpracují vstupní prompt přes enkodér (nebo v dekodérových modelech přes celý dekodér) a následně generují výstupní tokeny jeden po druhém. Každý nový token je generován určením rozdělení pravděpodobnosti nad celým slovníkem pomocí softmaxu, přičemž model volí nejpravděpodobnější token (nebo vzorkuje podle nastavení teploty). Tento proces, opakovaný stovky či tisíce krát, vede k souvislému, kontextově vhodnému textu. Mechanismus self-attention umožňuje modelu udržet kontext napříč celou generovanou sekvencí, vytvářet dlouhé, souvislé pasáže a zachovat konzistenci témat, postav i logiky.
Emergentní schopnosti pozorované u velkých transformátorových modelů – dovednosti, které se objevují až při určitém měřítku, například few-shot učení, chain-of-thought reasoning či učení v kontextu – jsou přímým důsledkem návrhu transformátorové architektury. Schopnost vícehlavé pozornosti zachytit rozmanité vztahy a obrovské množství parametrů v kombinaci s tréninkem na různorodých datech umožňuje těmto systémům zvládat úlohy, na které nebyly explicitně trénovány. Například GPT-3 umělo počítat, psát kód i odpovídat na triviální otázky, ačkoliv bylo trénováno pouze na modelování jazyka. Tyto emergentní vlastnosti činí z transformátorových LLM základ moderní AI revoluce, od konverzační AI a generování obsahu po syntézu kódu a asistenci při vědeckém výzkumu.
Mechanismus self-attention je architektonickou inovací, která zásadně odlišuje transformátory a vysvětluje jejich lepší výkon oproti předchozím přístupům. Pro pochopení self-attention si představte výzvu interpretace nejednoznačných zájmen v jazyce. Ve větě „Pohár se nevejde do kufru, protože je příliš velký“ může zájmeno „je“ odkazovat na pohár nebo na kufr, ale kontext jasně říká, že jde o pohár. Ve větě „Pohár se nevejde do kufru, protože je příliš malý“ zájmeno tentokrát odkazuje na kufr. Transformátorový model se musí naučit řešit takové nejednoznačnosti pochopením vztahů mezi slovy.
Self-attention to zvládá matematicky elegantně. Pro každý token ve vstupní sekvenci model počítá Query vektor vynásobením embeddingu tokenu váhovou maticí WQ. Podobně vypočítá Key vektory (pomocí WK) a Value vektory (pomocí WV) pro všechny tokeny. Skóre pozornosti mezi Query jednoho tokenu a Key jiného tokenu je skalární součin těchto vektorů, normalizovaný druhou odmocninou rozměru (typicky √64 ≈ 8). Tato surová skóre jsou pak převedena pomocí softmaxu na normalizované váhy pozornosti, které dávají dohromady 1. Nakonec je výstup pro každý token váženým součtem všech Value vektorů, kde váhy odpovídají skóre pozornosti. Tento proces umožňuje každému tokenu selektivně agregovat informace od ostatních tokenů, přičemž váhy se učí v průběhu tréninku k zachycení významuplných vztahů.
Matematická elegance self-attention umožňuje efektivní výpočty. Celý proces lze zapsat maticovými operacemi: Attention(Q, K, V) = softmax(QK^T / √d_k)V, kde Q, K a V jsou matice obsahující všechny query, key a value vektory. Tato maticová formulace umožňuje akceleraci na GPU, takže transformátory zpracují celé sekvence paralelně místo sekvenčně. Sekvence o 512 tokenech lze zpracovat téměř stejně rychle jako jediný token v RNN, což činí trénování transformátorů řádově rychlejší. Tato výpočetní efektivita v kombinaci se schopností zachytit dlouhodobé závislosti vysvětluje, proč se transformátory staly dominantní architekturou pro modelování jazyka.
Vícehlavá pozornost rozšiřuje self-attention spuštěním několika paralelních mechanismů pozornosti, z nichž každý se učí jiné aspekty vztahů mezi tokeny. V typickém transformátoru s 8 hlavami jsou vstupní embeddingy lineárně promítány do 8 různých podprostorů reprezentace, z nichž každý má vlastní váhové matice pro Query, Key a Value. Každá hlava samostatně počítá váhy pozornosti a vytváří výstupní vektory. Tyto výstupy jsou poté spojeny a lineárně transformovány přes finální váhovou matici, čímž vznikne výsledná vícehlavá pozornost. Tato architektura umožňuje modelu současně sledovat informace z různých podprostorů reprezentace na různých pozicích.
Výzkum analýzy naučených transformátorových modelů ukázal, že různé hlavy se specializují na různé jazykové jevy. Některé hlavy se zaměřují na syntaktické vztahy, například sledování gramatických vazeb mezi slovesy a jejich podměty či předměty. Jiné sledují sémantické vztahy a navazují na slova s podobným významem. Další zachycují dlouhodobé závislosti a zaměřují se na slova, která jsou v sekvenci vzdálená, ale významově propojená. Některé hlavy dokonce sledují především aktuální token, čímž působí jako identity operace. Tato specializace vzniká přirozeně během tréninku bez explicitního dozoru a dokládá sílu vícehlavé architektury učit se různorodé, vzájemně se doplňující reprezentace.
Počet hlav je důležitým architektonickým hyperparametrem. Větší modely typicky používají více hlav (16, 32 nebo i více), což umožňuje zachytit větší rozmanitost vztahů. Celková dimenze pozornosti je však obvykle konstantní, takže více hlav znamená nižší rozměr na hlavu. Toto řešení vyvažuje přínosy více podprostorů reprezentace s výpočetní efektivitou. Vícehlavý mechanismus se natolik osvědčil, že se stal standardem ve všech moderních transformátorech – od BERT a GPT až po specializované architektury pro zpracování obrazu, audia či multimodálních dat.
Původní návrh transformátoru, jak je popsán ve studii „Attention is All You Need“, používá enkodér-dekodér strukturu optimalizovanou pro úlohy typu sekvence-na-sekvenci, jako je strojový překlad. Enkodér zpracovává vstupní sekvenci a vytváří sekvenci kontextových reprezentací. Každá vrstva enkodéru obsahuje dvě základní komponenty: vícehlavou self-attention subvrstvu, která umožňuje tokenům věnovat pozornost ostatním tokenům ve vstupu, a dopřednou neuronovou síť, která aplikuje nelineární transformaci na každý token samostatně. Tyto subvrstvy jsou propojeny reziduálními spoji (skip connections), které přičítají vstup k výstupu každé subvrstvy. Toto řešení, inspirované reziduálními sítěmi v počítačovém vidění, umožňuje trénovat velmi hluboké sítě tím, že gradienty mohou protékat přímo.
Dekodér generuje výstupní sekvenci po jednom tokenu s využitím informací z enkodéru i předchozích vygenerovaných tokenů. Každá vrstva dekodéru obsahuje tři hlavní komponenty: maskovanou self-attention subvrstvu, která umožňuje každému tokenu věnovat pozornost pouze předchozím tokenům (čímž se zabrání „podvádění“ při tréninku), enkodér-dekodér attention subvrstvu, která umožňuje dekodéru zaměřit se na výstupy enkodéru, a dopřednou neuronovou síť. Maskování v self-attention subvrstvě je klíčové: zabraňuje toku informací z budoucích pozic do minulých, takže predikce pro pozici i závisí jen na známých výstupech na pozicích menších než i. Tato autoregresivní struktura je zásadní pro generování sekvencí po jednom tokenu.
Enkodér-dekodér architektura se ukázala jako velmi účinná pro úlohy, kde se struktura či délka vstupu a výstupu liší, například při strojovém překladu, sumarizaci nebo odpovídání na otázky. Moderní LLM jako GPT však využívají pouze dekodérové architektury, kde jediný zásobník dekodérových vrstev zpracovává vstupní prompt i generuje výstup. Toto zjednodušení snižuje složitost modelu a ukázalo se, že je pro jazykové modelování stejně či více efektivní, protože model se naučí self-attention použít jak pro zpracování vstupu, tak generování výstupu v jednom celku.
Zásadní výzvou transformátorové architektury je reprezentace pořadí tokenů v sekvenci. Na rozdíl od RNN, které uchovávají pořadí sekvence díky své rekurentní struktuře, transformátory zpracovávají všechny tokeny paralelně a nemají žádné vestavěné vnímání pozice. Bez explicitní informace o pozici by transformátor nerozlišoval mezi „Kočka seděla na podložce“ a „podložce na seděla Kočka“, což by bylo pro porozumění jazyku katastrofální. Řešením je poziční zakódování, které před zpracováním přičítá k embeddingům tokenů vektory závislé na pozici.
Původní práce o transformátoru používá sinusoidální poziční zakódování, kde vektor pro pozici pos a dimenzi i je:
Tyto sinusoidální funkce vytvářejí jedinečný vzor pro každou pozici s různými frekvencemi pro různé dimenze. Nižší frekvence (menší i) se s pozicí mění pomalu, čímž zachycují dlouhodobé poziční informace, zatímco vyšší frekvence se mění rychle a zachycují detailní pozici. Tento návrh má několik výhod: přirozeně zobecňuje na delší sekvence, než byly při tréninku, poskytuje plynulé přechody mezi pozicemi a umožňuje modelu naučit se vztahy relativních pozic. Vektory pozičního zakódování jsou jednoduše přičteny k embeddingům před první vrstvou pozornosti a model se během tréninku naučí tuto informaci využívat.
Byly navrženy a zkoumány alternativní metody pozičního zakódování, například relativní poziční reprezentace (kódující vzdálenosti mezi tokeny místo absolutních pozic) a rotary position embeddings (RoPE) (otáčející embeddingy podle pozice). Tyto alternativy v některých případech zlepšily výkon, zejména u velmi dlouhých sekvencí nebo při doladění na delší sekvence, než na jaké byl model trénován. Volba pozičního zakódování může zásadně ovlivnit výkon modelu a zůstává aktivní oblastí výzkumu v optimalizaci transformátorů.
Transformátorová architektura zpracovává celé sekvence paralelně pomocí self-attention, zatímco RNN a LSTM zpracovávají sekvence sekvenčně, po jednom prvku. Tato paralelizace činí transformátory výrazně rychlejšími pro trénink a schopnějšími zachytit dlouhodobé závislosti mezi vzdálenými slovy či tokeny. Transformátory se také vyhýbají problému mizejícího gradientu, který trápil RNN, a umožňují efektivní učení i z velmi dlouhých sekvencí.
Self-attention počítá tři vektory (Query, Key a Value) pro každý token v sekvenci vstupu. Query vektor jednoho tokenu je porovnáván se všemi Key vektory ostatních tokenů, aby se určily skóre relevance, která jsou normalizována pomocí softmaxu. Tyto váhy pozornosti jsou pak aplikovány na Value vektory pro vytvoření kontextově citlivých reprezentací. Tento mechanismus umožňuje každému tokenu 'věnovat pozornost' nebo se zaměřit na ostatní relevantní tokeny v sekvenci, což modelu umožňuje chápat kontext a vztahy.
Hlavními komponentami jsou: (1) vstupní embeddingy a poziční zakódování pro reprezentaci tokenů a jejich pozic, (2) vrstvy vícehlavé self-attention, které počítají pozornost napříč více podprostory reprezentací, (3) dopředné neuronové sítě aplikované nezávisle na každé pozici, (4) zásobník enkodéru pro zpracování vstupních sekvencí, (5) zásobník dekodéru pro generování výstupních sekvencí a (6) reziduální spojení a normalizace vrstev pro stabilitu tréninku. Tyto komponenty spolupracují pro efektivní paralelní zpracování a porozumění kontextu.
Transformátorová architektura je pro LLM vynikající, protože umožňuje paralelní zpracování celých sekvencí, což dramaticky zkracuje dobu tréninku oproti sekvenčním RNN. Díky self-attention efektivně zachycuje dlouhodobé závislosti, takže modely chápou kontext napříč celými dokumenty. Architektura se také efektivně škáluje s většími datasety a vyšším počtem parametrů, což je zásadní pro modely s miliardami parametrů, které vykazují emergentní schopnosti.
Vícehlavá pozornost spouští více paralelních mechanismů pozornosti (typicky 8 nebo 16 hlav) současně, každá v jiném podprostoru reprezentace. Každá hlava se učí zaměřovat na různé typy vztahů a vzorců v datech. Výstupy všech hlav jsou spojeny a lineárně transformovány, což umožňuje modelu zachytit rozmanité kontextové informace. Tento přístup výrazně zlepšuje schopnost modelu chápat složité vztahy a celkově zvyšuje jeho výkon.
Poziční zakódování přidává informace o pozici tokenu k embeddingům pomocí sinusových a kosinových funkcí na různých frekvencích. Protože transformátory zpracovávají všechny tokeny paralelně (na rozdíl od sekvenčních RNN), potřebují explicitní informace o pozici pro pochopení pořadí slov. Vektory pozičního zakódování jsou přičteny k embeddingům tokenů před zpracováním, což modelu umožňuje naučit se, jak pozice ovlivňuje význam, a umožňuje mu zobecňovat na delší sekvence než při tréninku.
Enkodér zpracovává vstupní sekvenci a vytváří bohaté kontextové reprezentace přes několik vrstev self-attention a dopředných sítí. Dekodér generuje výstupní sekvenci po jednom tokenu pomocí enkodér-dekodér pozornosti, která se zaměřuje na relevantní části vstupu. Tato struktura je zvláště užitečná pro úlohy typu sekvence-na-sekvenci, jako je strojový překlad, ale moderní LLM často využívají pouze dekodérové architektury pro generování textu.
Transformátorová architektura pohání AI systémy, které generují odpovědi na platformách jako ChatGPT, Claude, Perplexity a Google AI Overviews. Porozumění tomu, jak transformátory zpracovávají a generují text, je zásadní pro AI monitoringové platformy jako AmICited, které sledují, kde se značky a domény objevují v odpovědích generovaných AI. Schopnost architektury chápat kontext a generovat souvislý text přímo ovlivňuje to, jak jsou značky zmiňovány a prezentovány ve výstupech AI.
Začněte sledovat, jak AI chatboti zmiňují vaši značku na ChatGPT, Perplexity a dalších platformách. Získejte užitečné informace pro zlepšení vaší AI prezence.
Architektura webu je hierarchické uspořádání stránek a obsahu webových stránek. Zjistěte, jak správná struktura webu zlepšuje SEO, uživatelskou zkušenost a vidi...
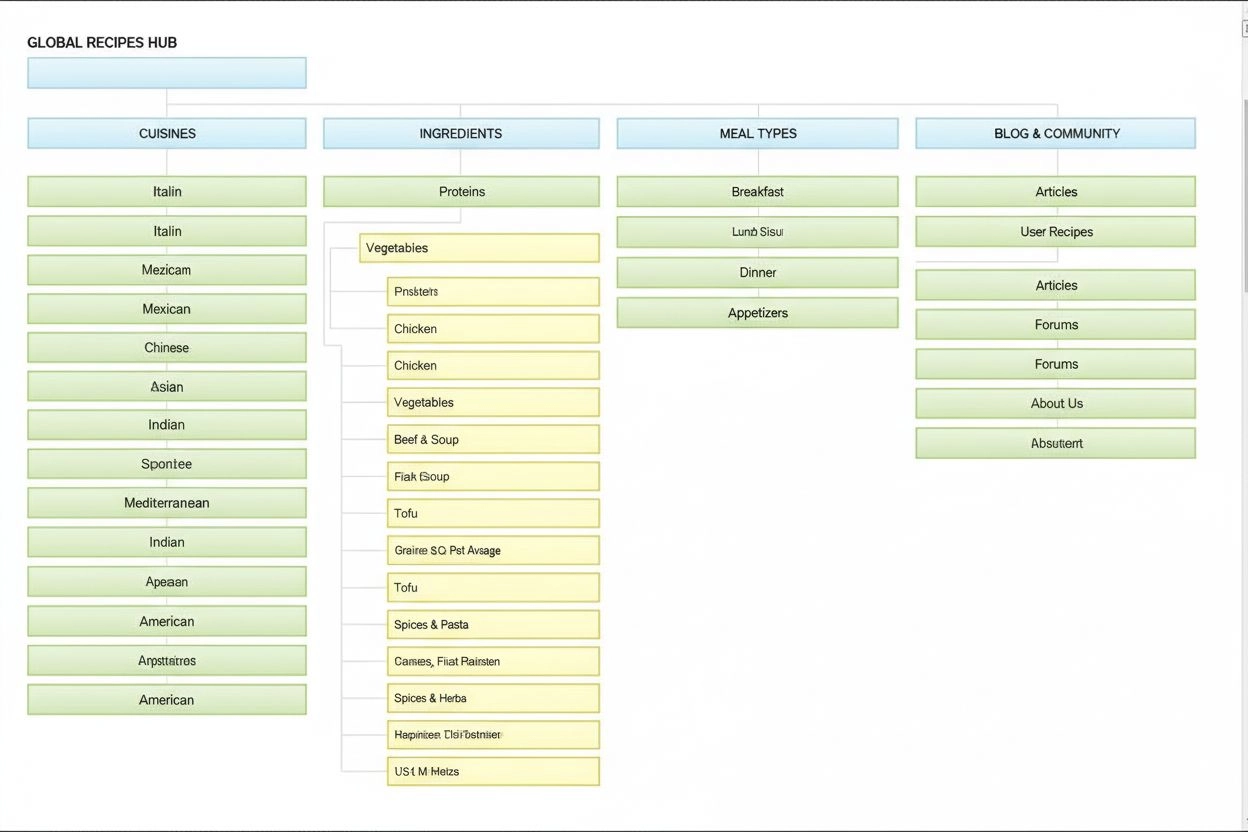
Informační architektura je praxe organizace a strukturování obsahu pro optimální použitelnost. Zjistěte, jak IA zlepšuje dohledatelnost, uživatelskou zkušenost ...
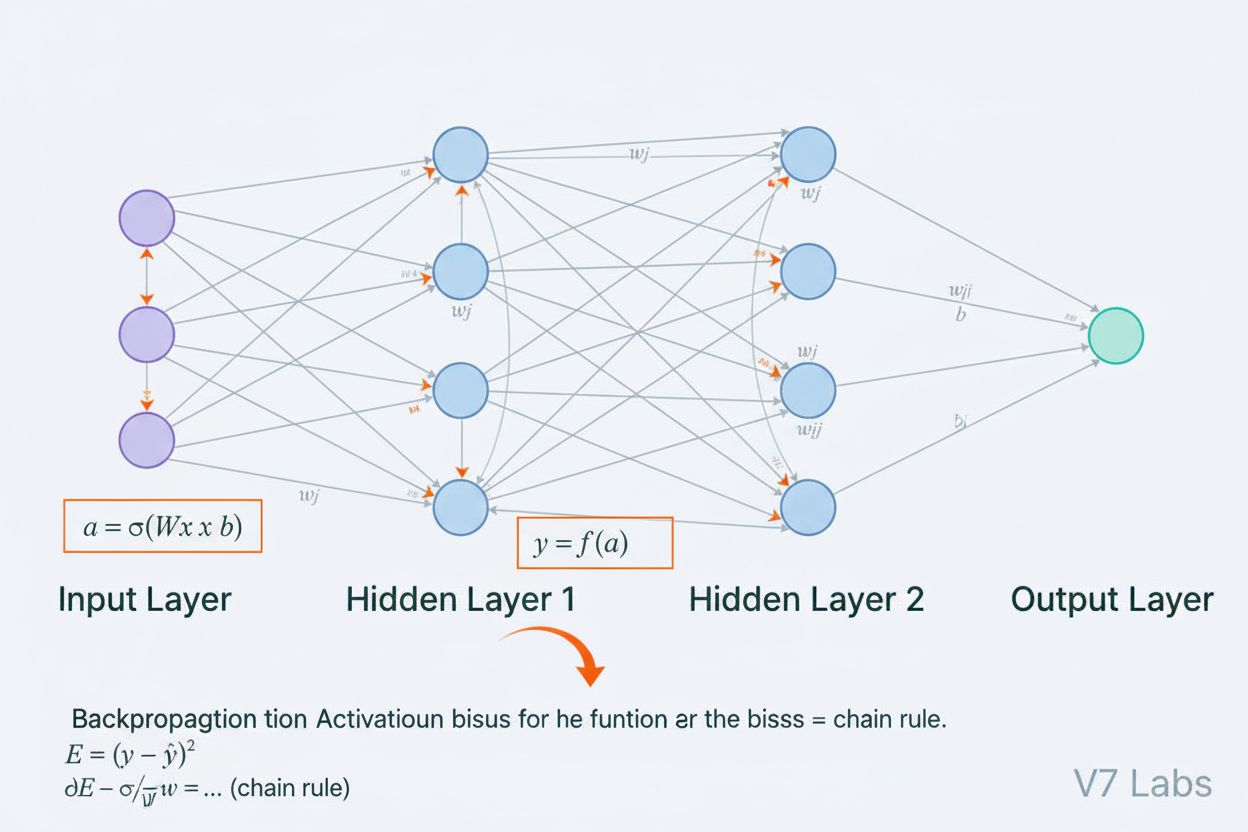
Komplexní definice neuronových sítí jako výpočetních systémů inspirovaných biologickým mozkem. Zjistěte, jak umělé neurony, vrstvy a zpětná propagace umožňují A...
Souhlas s cookies
Používáme cookies ke zlepšení vašeho prohlížení a analýze naší návštěvnosti. See our privacy policy.