
Hvilke AI-crawlere bør jeg give adgang? Komplet guide til 2025
Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
10 min læsning

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit site for synlighed i AI-søgning.
AI-crawlere er automatiserede programmer designet til systematisk at gennemtrawle internettet og indsamle data fra websites, specifikt for at træne og forbedre kunstige intelligensmodeller. I modsætning til traditionelle søgemaskinecrawlere som Googlebot, der indekserer indhold til søgeresultater, samler AI-crawlere rå webdata til brug i store sprogmodeller (LLMs) som ChatGPT, Claude og andre AI-systemer. Disse bots arbejder løbende på tværs af millioner af websites, downloader sider, analyserer indhold og udtrækker information, der hjælper AI-platforme med at forstå sprogmønstre, faktuel information og forskellige skrivestile. De største aktører på området inkluderer GPTBot fra OpenAI, ClaudeBot fra Anthropic, Meta-ExternalAgent fra Meta, Amazonbot fra Amazon og PerplexityBot fra Perplexity.ai, som hver især understøtter deres respektive AI-platformes trænings- og driftsbehov. At forstå, hvordan disse crawlere arbejder, er blevet essentielt for website-ejere og indholdsskabere, da AI-synlighed nu direkte påvirker, hvordan dit brand dukker op i AI-drevne søgeresultater og anbefalinger.
Webcrawl-landskabet har gennemgået en dramatisk forvandling det seneste år, hvor AI-crawlere har oplevet eksplosiv vækst, mens traditionelle søgemaskinecrawlere har fastholdt stabile mønstre. Mellem maj 2024 og maj 2025 voksede den samlede crawlertrafik med 18%, men fordelingen ændrede sig markant—GPTBot steg 305% i rå forespørgsler, mens andre crawlere som ClaudeBot faldt med 46% og Bytespider faldt 85%. Denne omrokering afspejler den intensiverede konkurrence blandt AI-virksomheder om at sikre træningsdata og forbedre deres modeller. Her er en detaljeret oversigt over de vigtigste crawlere og deres nuværende markedsposition:
| Crawler-navn | Virksomhed | Månedlige forespørgsler | Årlig vækst | Primært formål |
|---|---|---|---|---|
| Googlebot | 4,5 milliarder | 96% | Søgeindeksering & AI Overviews | |
| GPTBot | OpenAI | 569 millioner | 305% | ChatGPT-modeltræning & søgning |
| Claude | Anthropic | 370 millioner | -46% | Claude-modeltræning & søgning |
| Bingbot | Microsoft | ~450 millioner | 2% | Søgeindeksering |
| PerplexityBot | Perplexity.ai | 24,4 millioner | 157.490% | AI-søgeindeksering |
| Meta-ExternalAgent | Meta | ~380 millioner | Ny aktør | Meta AI-træning |
| Amazonbot | Amazon | ~210 millioner | -35% | Søgning & AI-applikationer |
Tallene viser, at selvom Googlebot fastholder dominansen med 4,5 milliarder månedlige forespørgsler, repræsenterer AI-crawlere samlet set cirka 28% af Googlebots volumen, hvilket gør dem til en betydelig kraft i webtrafikken. Den eksplosive vækst for PerplexityBot (157.490% stigning) demonstrerer, hvor hurtigt nye AI-platforme opskalerer deres crawling, mens faldet for nogle etablerede AI-crawlere indikerer en markedsmæssig konsolidering omkring de mest succesfulde AI-platforme.
GPTBot er OpenAIs webcrawler, specifikt designet til at indsamle data til træning og forbedring af ChatGPT og andre OpenAI-modeller. GPTBot blev lanceret som en mindre aktør med kun 5% markedsandel i maj 2024, men er nu blevet den dominerende AI-crawler med 30% af al AI-crawlertrafik i maj 2025—en bemærkelsesværdig stigning på 305% i rå forespørgsler. Denne eksplosive vækst afspejler OpenAIs aggressive strategi for at sikre, at ChatGPT har adgang til frisk, mangfoldigt webindhold til både modeltræning og realtidssøgning via ChatGPT Search. GPTBot har et særligt crawl-mønster, hvor HTML-indhold prioriteres (57,70% af hentningerne), men hvor der også downloades JavaScript-filer og billeder, selvom den ikke udfører JavaScript til at renderere dynamisk indhold. Crawleren støder ofte på 404-fejl (34,82% af forespørgslerne), hvilket antyder, at den kan følge forældede links eller forsøge at tilgå ressourcer, der ikke længere eksisterer. For website-ejere betyder GPTBots dominans, at det er blevet kritisk for synlighed i ChatGPTs søgefunktioner og fremtidig modeltræning, at dit indhold er tilgængeligt for denne crawler.
ClaudeBot, udviklet af Anthropic, fungerer som den primære crawler til træning og opdatering af Claude AI-assistenten samt til at understøtte Claudes søge- og forankringsfunktioner. Som tidligere næststørste AI-crawler med 27% markedsandel i maj 2024 har ClaudeBot oplevet et markant fald til 21% i maj 2025, med et fald på 46% i rå forespørgsler år-for-år. Dette fald er ikke nødvendigvis et problem med Anthropics strategi, men afspejler snarere det bredere markedsskifte mod OpenAIs dominans og fremkomsten af nye konkurrenter som Meta-ExternalAgent. ClaudeBot udviser lignende adfærd som GPTBot og prioriterer HTML-indhold, men bruger en højere andel af forespørgsler på billeder (35,17% af hentningerne), hvilket antyder, at Anthropic muligvis træner Claude til bedre at forstå visuelt indhold sammen med tekst. Ligesom andre AI-crawlere rendererer ClaudeBot ikke JavaScript, hvilket betyder, at den kun ser den rå HTML på siderne uden dynamisk indlæst indhold. For indholdsskabere er det fortsat vigtigt at opretholde synlighed med ClaudeBot, hvis man vil sikre, at Claude kan tilgå og citere ens indhold, især når Anthropic fortsat udvikler Claudes søge- og ræsonnementsevner.
Udover GPTBot og ClaudeBot er flere andre betydningsfulde AI-crawlere aktive med at indsamle webdata til deres respektive platforme:
Meta-ExternalAgent (Meta): Metas crawler gjorde et dramatisk indtog i topplaceringerne med 19% markedsandel i maj 2025 som ny aktør. Denne bot samler data til Metas AI-initiativer, herunder mulig træning til Meta AI og integration med Instagrams og Facebooks AI-funktioner. Metas hurtige vækst antyder, at virksomheden satser seriøst på AI-drevet søgning og anbefalinger.
PerplexityBot (Perplexity.ai): På trods af kun 0,2% markedsandel oplevede PerplexityBot den mest eksplosive vækstrate på 157.490% år-for-år. Det afspejler Perplexitys hurtige opskalering som AI-svarmotor, der er afhængig af realtidssøgning for at forankre sine svar. For websites repræsenterer besøg fra PerplexityBot direkte muligheder for at blive citeret i Perplexitys AI-genererede svar.
Amazonbot (Amazon): Amazons crawler faldt fra 21% til 11% markedsandel med et fald på 35% i rå forespørgsler år-for-år. Amazonbot samler data til Amazons søgefunktioner og AI-applikationer, men den faldende andel antyder, at Amazon måske ændrer AI-strategi eller konsoliderer crawling.
Applebot (Apple): Apples crawler oplevede et fald på 26% i forespørgsler, fra 1,9% til 1,2% markedsandel. Applebot betjener primært Siri og Spotlight-søgning, men kan også understøtte Apples fremspirende AI-tiltag. I modsætning til de fleste andre AI-crawlere kan Applebot renderere JavaScript og har dermed evner svarende til Googlebot.
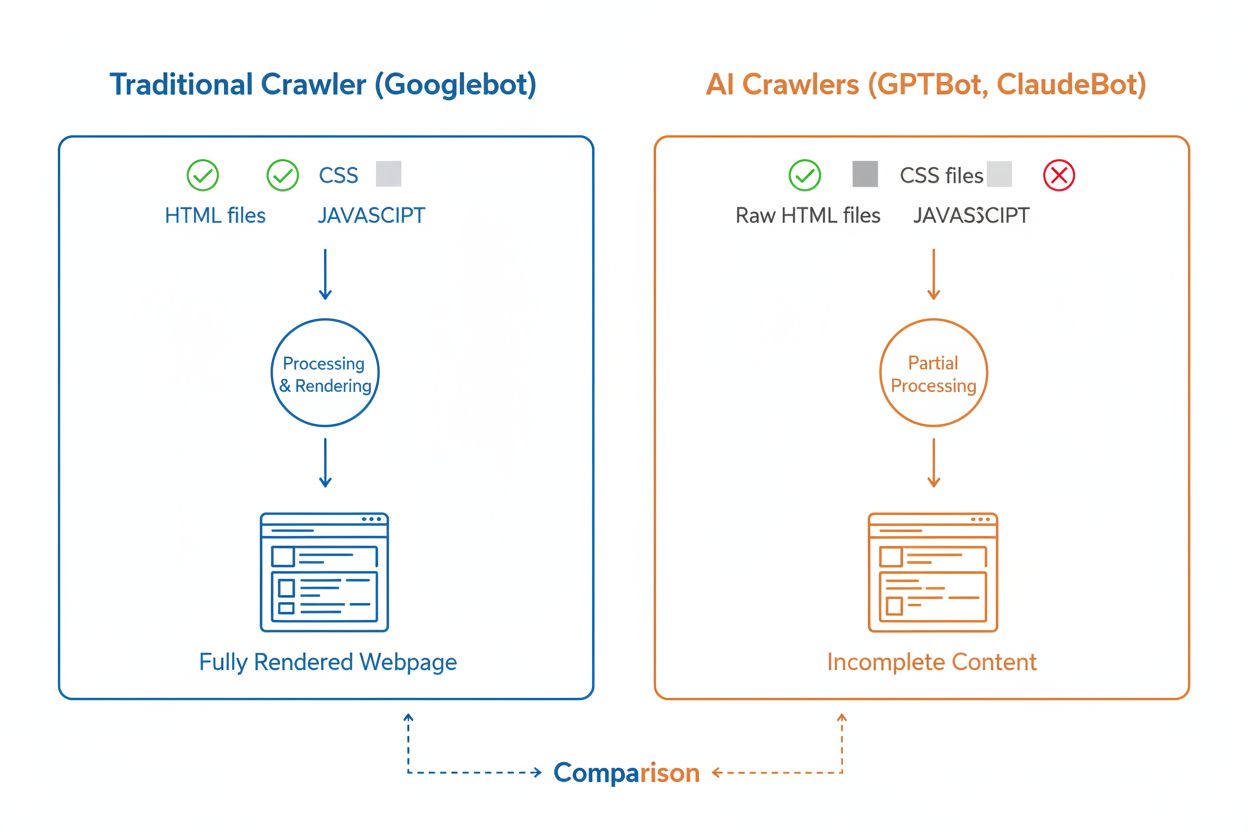
Selvom AI-crawlere og traditionelle søgemaskinecrawlere som Googlebot begge systematisk gennemtrawler nettet, adskiller deres tekniske evner og adfærd sig væsentligt på måder, der direkte påvirker, hvordan dit indhold opdages og forstås. Den væsentligste forskel er JavaScript-rendering: Googlebot kan udføre JavaScript efter download af en side og kan dermed se dynamisk indlæst indhold, mens de fleste AI-crawlere (GPTBot, ClaudeBot, Meta-ExternalAgent, Bytespider) kun læser den rå HTML og ignorerer alt indhold, der kræver JavaScript. Det betyder, at hvis dit website er afhængigt af client-side rendering for at vise vigtig information, vil AI-crawlere kun se en ufuldstændig version af dine sider. Derudover udviser AI-crawlere mindre forudsigelige crawl-mønstre sammenlignet med Googlebots systematiske tilgang—de bruger 34,82% af forespørgslerne på 404-sider og 14,36% på at følge redirects, mod Googlebots mere effektive 8,22% på 404’er og 1,49% på redirects. Crawl-frekvensen adskiller sig også: Hvor Googlebot besøger sider ud fra et sofistikeret crawlbudget-system, crawler AI-crawlere tilsyneladende hyppigere, men mindre systematisk, og nogle studier viser, at AI-crawlere kan besøge sider over 100 gange oftere end Google i visse tilfælde. Disse forskelle betyder, at traditionelle SEO-optimeringsstrategier ikke nødvendigvis dækker AI-crawlbarhed, og at der kræves en særskilt tilgang med fokus på server-side rendering og rene URL-strukturer.
En af de største tekniske udfordringer for AI-crawlere er deres manglende evne til at renderere JavaScript, hvilket skyldes de store beregningsmæssige omkostninger ved at udføre JavaScript i den massive skala, der kræves til træning af store sprogmodeller. Når en crawler downloader din webside, modtager den kun det indledende HTML-svar, men alt indhold, der indlæses eller ændres af JavaScript—såsom produktdetaljer, prisoplysninger, brugeranmeldelser eller dynamiske navigations-elementer—er usynligt for AI-crawlere. Det skaber et kritisk problem for moderne websites, der er stærkt afhængige af client-side rendering-frameworks som React, Vue eller Angular uden server-side rendering (SSR) eller statisk sitegenerering (SSG). For eksempel vil en e-commerce-side, hvor produktinformation indlæses via JavaScript, fremstå som en tom side uden produktinformation for AI-crawlere, hvilket gør det umuligt for AI-systemer at forstå eller citere indholdet. Løsningen er at sikre, at alt kritisk indhold serveres i det indledende HTML-svar via server-side rendering, som genererer den komplette HTML på serveren, inden den sendes til browseren. Denne tilgang sikrer, at både menneskelige besøgende og AI-crawlere får den samme indholdsrige oplevelse. Websites, der bruger moderne frameworks som Next.js med SSR, statiske site generators som Hugo eller Gatsby eller traditionelle server-renderede platforme som WordPress, er naturligt AI-crawler-venlige, mens sites, der udelukkende bruger client-side rendering, står over for betydelige synlighedsudfordringer i AI-søgning.
AI-crawlere udviser særlige crawl-frekvens-mønstre, der adskiller sig markant fra Googlebots adfærd, med vigtige konsekvenser for, hvor hurtigt dit indhold opfanges af AI-systemer. Forskning viser, at AI-crawlere som ChatGPT og Perplexity ofte besøger sider hyppigere end Google i den korte periode efter publicering—i nogle tilfælde besøger de sider 8 gange oftere end Googlebot inden for de første par dage. Denne hurtige indledende crawling antyder, at AI-platforme prioriterer hurtig opdagelse og indeksering af nyt indhold, sandsynligvis for at sikre, at deres modeller og søgefunktioner har adgang til den nyeste information. Men denne aggressive indledende crawling efterfølges af et mønster, hvor AI-crawlere måske ikke vender tilbage, hvis indholdet ikke opfylder kvalitetskrav, hvilket gør førstehåndsindtrykket ekstra vigtigt. I modsætning til Googlebot, der har et sofistikeret crawlbudget og vender tilbage til sider regelmæssigt afhængigt af opdateringshyppighed og vigtighed, ser AI-crawlere ud til at træffe en hurtig vurdering af, om indholdet er værd at vende tilbage til. Det betyder, at hvis en AI-crawler besøger din side og finder tyndt indhold, tekniske fejl eller dårlige brugeroplevelsessignaler, kan der gå væsentligt længere tid, før den vender tilbage—hvis den gør det overhovedet. Konsekvensen for indholdsskabere er klar: Du kan ikke regne med en ny chance for at optimere indholdet for AI-crawlere, som du måske kan med traditionelle søgemaskiner, så kvalitetssikring før publicering er afgørende.
Website-ejere kan bruge robots.txt-filen til at kommunikere deres præferencer angående adgang for AI-crawlere, men effektiviteten og håndhævelsen af disse regler varierer betydeligt mellem forskellige crawlere. Ifølge nyere data har cirka 14% af de 10.000 største websites implementeret specifikke tilladelses- eller blokeringregler rettet mod AI-bots i deres robots.txt-filer. GPTBot er den mest blokerede crawler, med 312 domæner (250 fuldt, 62 delvist) der eksplicit forbyder den, men det er også den mest eksplicit tilladte crawler med 61 domæner, der eksplicit giver adgang. Andre ofte blokerede crawlere inkluderer CCBot (Common Crawl) og Google-Extended (Googles AI-trænings-token). Udfordringen med robots.txt er, at overholdelse er frivillig—crawlere følger kun reglerne, hvis deres operatører vælger at implementere denne funktionalitet, og nogle nyere eller mindre gennemsigtige crawlere respekterer måske ikke robots.txt-direktiver overhovedet. Desuden svarer robots.txt-tokens som “Google-Extended” ikke direkte til user-agent-strenge i HTTP-forespørgsler; i stedet signalerer de formålet med crawlingen, hvilket betyder, at du ikke altid kan verificere overholdelse via serverlogs. For stærkere håndhævelse vælger website-ejere i stigende grad firewall-regler og Web Application Firewalls (WAFs), der aktivt kan blokere bestemte crawler-user-agents, hvilket giver mere pålidelig kontrol end robots.txt alene. Dette skift mod aktive blokeringmekanismer afspejler voksende bekymringer om indholdsrettigheder og ønsket om mere håndgribelige kontroller over AI-crawleres adgang.
Overvågning af AI-crawler-aktivitet på dit website er afgørende for at forstå din synlighed i AI-søgning, men stiller unikke udfordringer sammenlignet med overvågning af traditionelle søgemaskinecrawlere. Traditionelle analysetools som Google Analytics er afhængige af JavaScript-tracking, som AI-crawlere ikke udfører, hvilket betyder, at disse værktøjer ikke giver indsigt i AI-bot-besøg. Ligeledes virker pixel-baseret tracking ikke, fordi de fleste AI-crawlere kun læser tekst og ignorerer billeder. Den eneste pålidelige metode til at spore AI-crawler-aktivitet er gennem server-side overvågning—analyse af HTTP request headers og serverlogs for at identificere crawler-user-agents, inden siden sendes. Dette kræver enten manuel loganalyse eller specialiserede værktøjer, der er designet til at identificere og spore AI-crawler-trafik. Realtidsovervågning er især kritisk, fordi AI-crawlere arbejder på uforudsigelige tidspunkter og måske ikke vender tilbage til sider, hvis de støder på problemer, hvilket betyder, at en ugentlig eller månedlig crawl-audit kan overse vigtige problemer. Hvis en AI-crawler besøger dit site og finder en teknisk fejl eller dårlig indholdskvalitet, får du måske ikke en ny mulighed for at gøre et godt indtryk. Ved at implementere 24/7-overvågningsløsninger, der advarer dig øjeblikkeligt, når AI-crawlere støder på problemer—såsom 404-fejl, lange indlæsningstider eller manglende schema-markup—kan du rette problemer, inden de påvirker din AI-synlighed. Denne realtids-tilgang repræsenterer et fundamentalt skift fra traditionelle SEO-overvågningspraksisser og afspejler den hastighed og uforudsigelighed, der præger AI-crawleres adfærd.
Optimering af dit website for AI-crawlere kræver en anden tilgang end traditionel SEO, med fokus på tekniske faktorer, der direkte påvirker, hvordan AI-systemer kan tilgå og forstå dit indhold. Første prioritet er server-side rendering: Sørg for, at alt kritisk indhold—overskrifter, brødtekst, metadata, struktureret data—er inkluderet i det indledende HTML-svar og ikke indlæses dynamisk via JavaScript. Dette gælder for din forside, nøglesider og alt indhold, du ønsker, at AI-systemer skal kunne citere eller referere. For det andet skal du implementere struktureret datamarkup (Schema.org) på dine mest betydningsfulde sider, inklusive artikel-schema for blogindlæg, produkt-schema for e-commerce og forfatter-schema for at etablere ekspertise og autoritet. AI-crawlere bruger struktureret data til hurtigt at forstå indholdets hierarki og kontekst, hvilket gør det betydeligt lettere for dem at fortolke og citere dit indhold. For det tredje skal du opretholde stærke kvalitetsstandarder for indhold på alle sider, da AI-crawlere tilsyneladende hurtigt vurderer, om indholdet er værd at indeksere og citere. Det betyder, at dit indhold skal være originalt, velresearchet, faktuelt korrekt og give reel værdi for læserne. For det fjerde, overvåg og optimer Core Web Vitals og den samlede sideydelse, da langsomt-ladende sider signalerer dårlig brugeroplevelse og kan afskrække AI-crawlere fra at vende tilbage. Endelig skal du holde din URL-struktur enkel og konsistent, vedligeholde et opdateret XML-sitemap og sikre, at din robots.txt-fil er korrekt konfigureret til at guide crawlere til dit vigtigste indhold. Disse tekniske optimeringer skaber fundamentet for, at dit indhold kan opdages, forstås og citeres af AI-systemer.
Landskabet for AI-crawlere vil fortsat udvikle sig hurtigt, efterhånden som konkurrencen intensiveres blandt AI-virksomheder, og teknologien modnes. En tydelig tendens er konsolideringen af markedsandele omkring de mest succesfulde platforme—OpenAIs GPTBot er blevet den dominerende aktør, mens nye spillere som Meta-ExternalAgent skalerer aggressivt, hvilket antyder, at markedet sandsynligvis vil stabilisere sig omkring et fåtal af store aktører. Efterhånden som AI-crawlere modnes, kan vi forvente forbedringer i deres tekniske evner, især omkring JavaScript-rendering og mere effektive crawlmønstre, der begrænser spildte forespørgsler på 404-sider og forældet indhold. Branchen bevæger sig også mod mere standardiserede kommunikationsprotokoller, såsom den nye llms.txt-specifikation, der gør det muligt for websites eksplicit at kommunikere deres indholdsstruktur og crawlpræferencer til AI-systemer. Desuden bliver håndhævelsesmekanismerne til at kontrollere AI-crawler-adgang mere sofistikerede, med platforme som Cloudflare, der nu tilbyder automatisk blokering af AI-træningsbots som standard, hvilket giver website-ejere mere detaljeret kontrol over deres indhold. For indholdsskabere og websiteejere betyder det at være på forkant med disse ændringer, at man løbende overvåger AI-crawler-aktivitet, holder sin tekniske infrastruktur optimeret til AI-adgang og tilpasser sin indholdsstrategi til virkeligheden, hvor AI-systemer nu udgør en betydelig del af dit websites trafik og en kritisk kanal for brandsynlighed. Fremtiden tilhører dem, der forstår og optimerer til dette nye crawler-økosystem.
AI-crawlere er automatiserede programmer, der indsamler webdata specifikt for at træne og forbedre kunstige intelligensmodeller som ChatGPT og Claude. I modsætning til traditionelle søgemaskinecrawlere som Googlebot, der indekserer indhold til søgeresultater, samler AI-crawlere rå webdata til brug i store sprogmodeller. Begge typer crawlere gennemtrawler systematisk internettet, men de har forskellige formål og tekniske evner.
AI-crawlere tilgår dit website for at indsamle data til træning af AI-modeller, forbedre søgefunktioner og forankre AI-svar med opdateret information. Når AI-systemer som ChatGPT eller Perplexity besvarer brugerspørgsmål, skal de ofte hente dit indhold i realtid for at levere præcise, citerede oplysninger. Ved at tillade AI-crawlere adgang til dit site øges chancen for, at dit brand bliver nævnt og citeret i AI-genererede svar.
Ja, du kan bruge din robots.txt-fil til at blokere specifikke AI-crawlere ved at angive deres user-agent-navne. Dog er overholdelse af robots.txt frivillig, og ikke alle crawlere respekterer disse regler. For stærkere håndhævelse kan du bruge firewall-regler og Web Application Firewalls (WAFs) til aktivt at blokere bestemte crawler user-agents. Dette giver dig mere pålidelig kontrol over, hvilke AI-crawlere der kan tilgå dit indhold.
Nej, de fleste AI-crawlere (GPTBot, ClaudeBot, Meta-ExternalAgent) udfører ikke JavaScript. De læser kun den rå HTML på dine sider, hvilket betyder at alt indhold, der indlæses dynamisk via JavaScript, er usynligt for dem. Derfor er server-side rendering afgørende for AI-crawlbarhed. Hvis dit site er afhængigt af client-side rendering, vil AI-crawlere kun se en ufuldstændig version af dine sider.
AI-crawlere besøger websites oftere end traditionelle søgemaskiner i den korte periode efter publicering af indhold. Forskning viser, at de kan besøge sider 8-100 gange oftere end Google inden for de første par dage. Dog, hvis indholdet ikke lever op til kvalitetskrav, vender de måske ikke tilbage. Det gør førstehåndsindtrykket kritisk—du får måske ikke en ny chance for at optimere indhold til AI-crawlere.
De vigtigste optimeringer er: (1) Brug server-side rendering for at sikre, at kritisk indhold er i den indledende HTML, (2) Tilføj struktureret datamarkup (Schema) for at hjælpe AI med at forstå dit indhold, (3) Vedligehold høj indholdskvalitet og aktualitet, (4) Overvåg Core Web Vitals for god brugeroplevelse, og (5) Hold din URL-struktur enkel og vedligehold et opdateret sitemap. Disse tekniske optimeringer danner grundlaget for, at dit indhold kan opdages og citeres af AI-systemer.
GPTBot fra OpenAI er i øjeblikket den dominerende AI-crawler og står for 30% af al AI-crawlertrafik og vokser 305% år-for-år. Du bør dog optimere for alle større crawlere, herunder ClaudeBot (Anthropic), Meta-ExternalAgent (Meta), PerplexityBot (Perplexity) og andre. Forskellige AI-platforme har forskellige brugerbaser, så synlighed på tværs af flere crawlere maksimerer dit brands tilstedeværelse i AI-søgning.
Traditionelle analysetools som Google Analytics registrerer ikke AI-crawler-aktivitet, fordi de er afhængige af JavaScript-tracking. I stedet skal du bruge server-side overvågning, der analyserer HTTP request headers og serverlogs for at identificere crawler user-agents. Specialiserede værktøjer designet til AI-crawler-sporing giver realtidsoverblik over, hvilke sider der crawles, hvor ofte og om crawlerne støder på tekniske problemer.
Følg hvordan AI-crawlere som GPTBot og ClaudeBot tilgår og citerer dit indhold. Få realtidsindsigt i din AI-synlighed med AmICited.
Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
Lær hvordan du tillader AI-bots som GPTBot, PerplexityBot og ClaudeBot at crawle dit website. Konfigurer robots.txt, opsæt llms.txt og optimer for AI-synlighed....

Lær at træffe strategiske beslutninger om blokering af AI-crawlere. Vurder indholdstype, trafikkilder, indtægtsmodeller og konkurrenceposition med vores omfatte...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.