Hvorfor ChatGPT Elsker Reddit: Forståelse af Kildepræferencer
Opdag hvorfor Reddit dominerer ChatGPT-citater med 40,1% af alle AI-svar. Lær hvordan AI's kildepræferencer fungerer og hvad det betyder for din virksomheds syn...
10 min læsning

Opdag hvor ChatGPT får sine træningsdata fra, hvordan den citerer kilder, vidensafgrænsningsdatoer, og hvorfor overvågning af AI-citationer er vigtig for dit brand.
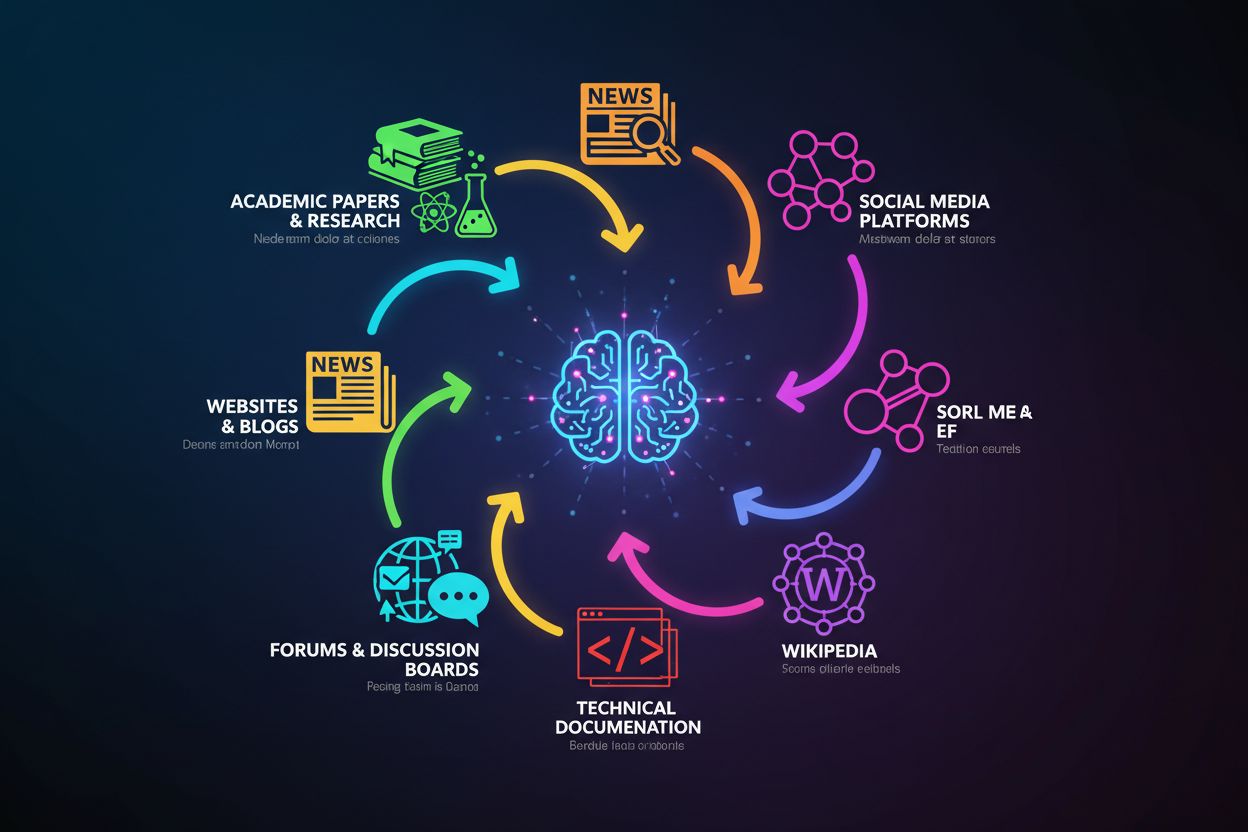
ChatGPT’s vidensbase er opbygget af en mangfoldig samling af offentligt tilgængelige internetdata, kombineret med licenserede datasæt og forbedret gennem menneskelig feedback. Modellen blev trænet på tre primære kilder: offentligt tilgængelige internetdata (websites, artikler og onlineindhold), licenserede datasæt (herunder bøger og akademiske publikationer) og menneskelig feedback fra trænere, der hjalp med at forfine svarene. Disse træningsdata omfatter et ekstraordinært bredt udvalg af kilder, herunder nyhedssites, akademiske tidsskrifter, bøger, teknisk dokumentation, fora som Reddit og Stack Overflow, Wikipedia-artikler og utallige andre offentligt tilgængelige websider. Det store omfang og den store diversitet af disse kilder—på tværs af sprog, fagområder og perspektiver—skaber en omfattende vidensbase, der gør ChatGPT i stand til at diskutere emner fra kvantefysik til middelalderhistorie til moderne popkultur. Det er dog vigtigt at forstå, at ChatGPT ikke har adgang til realtidsinformation eller proprietære databaser; den kan kun trække på det, der var tilgængeligt under dens træningsperiode.
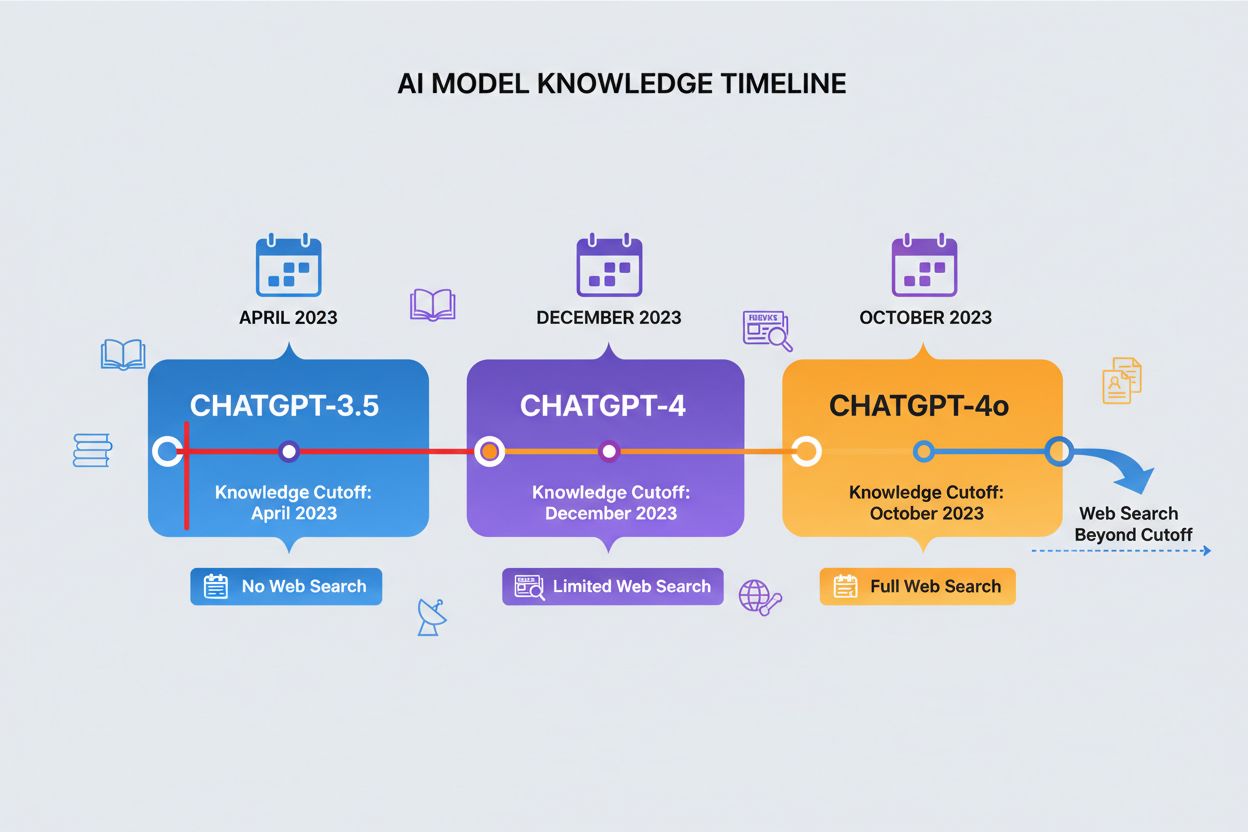
En vidensafgrænsningsdato repræsenterer det tidspunkt, efter hvilket ChatGPT ikke har træningsdata—det er en fast grænse for, hvilken information den kan tilgå. Forskellige versioner af ChatGPT har forskellige afgrænsningsdatoer: ChatGPT-4 blev trænet på data indtil december 2023, mens ChatGPT-4o (den optimerede version) har en vidensafgrænsning i oktober 2023. Disse afgrænsningsdatoer har stor betydning for nøjagtigheden og relevansen af svar, især for nyere begivenheder, nyligt publiceret forskning eller aktuelle statistikker, der kan være ændret siden træningsdataene blev indsamlet. Nogle nyere versioner af ChatGPT kan udføre websøgninger for at hente opdateret information ud over deres afgrænsningsdato, men denne funktion er ikke tilgængelig i alle versioner eller sammenhænge. At kende din models afgrænsningsdato er afgørende for brugere, der har brug for opdateret information, da ChatGPT ikke kan give præcise svar om begivenheder eller udviklinger, der er sket efter dens træningsperiode. Denne begrænsning er en af de vigtigste faktorer at tage højde for, når man vurderer ChatGPT’s pålidelighed til tidssensitive spørgsmål.
| ChatGPT-version | Vidensafgrænsningsdato | Websøgningsmulighed | Primær anvendelse |
|---|---|---|---|
| ChatGPT-4 | December 2023 | Begrænset | Generel viden, analyse, ræsonnement |
| ChatGPT-4o | Oktober 2023 | Tilgængelig | Optimeret ydeevne, multimodale opgaver |
| ChatGPT-3.5 | April 2023 | Nej | Basale forespørgsler, omkostningseffektiv løsning |
| ChatGPT med browsing | Realtid | Ja | Aktuelle begivenheder, nylig forskning |
I modsætning til søgemaskiner, der henter specifikke dokumenter eller websider som svar på forespørgsler, genererer ChatGPT svar ved at syntetisere mønstre, den har lært under træning—en grundlæggende anderledes proces. Når du stiller ChatGPT et spørgsmål, søger den ikke i en database eller et indeks; i stedet bruger den statistiske mønstre fra sine træningsdata til at forudsige den mest sandsynlige ordsekvens, der udgør et brugbart svar. Denne genereringsbaserede tilgang betyder, at ChatGPT kombinerer information fra flere kilder i sine træningsdata for at skabe nye svar, som måske ikke eksisterer ordret i noget af kildematerialet. Modellen lærer i bund og grund relationer mellem begreber, fakta og ideer og rekonstruerer denne viden som svar på din specifikke forespørgsel. Denne proces har dog en væsentlig ulempe: når modellen er usikker på information eller når mønstre i dens træningsdata er modstridende eller sparsomme, kan den generere sandsynlige, men forkerte oplysninger, et fænomen kendt som “hallucination”. Nyere versioner af ChatGPT, der integrerer websøgningsfunktionalitet, kan supplere denne genereringsproces ved at hente aktuel information fra internettet, men denne funktion kræver eksplicit aktivering og er ikke tilgængelig på alle platforme.
ChatGPT’s træningsdata stammer fra flere hovedkategorier af kilder, som hver især bidrager med unik værdi til dens vidensbase:
Vigtigheden af disse forskellige kilder ligger i deres komplementære styrker: akademiske artikler giver grundighed, nyhedsartikler giver aktualitet, bøger giver dybde, og fora giver praktisk anvendelse. Men kvaliteten af kilderne varierer betydeligt—en peer-reviewet artikel vejer tungere end et tilfældigt blogindlæg, men ChatGPT’s træningsproces skelner ikke eksplicit mellem dem. Det betyder, at ChatGPT’s viden afspejler både højkvalitets, autoritative kilder og lavere kvalitet eller potentielt vildledende indhold, hvilket gør verificering afgørende, når modellen bruges til vigtige beslutninger.
Efter den indledende træning på store tekstmængder benyttede OpenAI en teknik kaldet forstærkningslæring fra menneskelig feedback (RLHF) for at forfine ChatGPT’s svar. I denne proces evaluerede menneskelige trænere modellens output og gav feedback, hvilket hjalp systemet med at lære, hvilke svar der var mest hjælpsomme, præcise og i tråd med menneskelige værdier. Disse trænere faktatjekkede ikke hvert enkelt udsagn; de vurderede overordnet svarernes kvalitet, hjælpsomhed og sikkerhed, hvilket indirekte formede, hvordan modellen prioriterer og præsenterer information. RLHF-processen har stor indflydelse på, hvilke oplysninger der fremhæves i svar, og hvordan forskellige emner vinklas, hvilket tilfører menneskelig dømmekraft til en ellers rent statistisk model. Men denne feedback-proces har iboende begrænsninger: trænere har deres egne bias, videnshuller og begrænsninger, og de kan ikke vurdere alle udsagns korrekthed på tværs af alle fagområder. Desuden er feedback-processen ressourcekrævende og kan kun anvendes på en brøkdel af modellens mulige outputs, hvilket betyder, at meget af ChatGPT’s adfærd stadig afspejler de rå mønstre i træningsdataene frem for eksplicit menneskelig kuratering.
At citere ChatGPT er vigtigt for akademisk integritet og gennemsigtighed, så læsere kan forstå, hvor informationen kommer fra og potentielt genskabe eller verificere dine fund. Citeringsformatet afhænger af den påkrævede stilmanual, men her er de mest almindelige tilgange:
Eksempel på MLA-format:
OpenAI. "ChatGPT." Adgang til [Dato], https://chat.openai.com.
I MLA-stil citeres ChatGPT som en hjemmeside, inklusive adgangsdato, da indholdet er dynamisk og kan ændre sig. Hvis du citerer et specifikt svar, bør du angive den dato, du tilgik det, og helst inkludere den prompt eller det spørgsmål, du stillede.
Eksempel på APA-format:
OpenAI. (2024). ChatGPT (Version 4) [Stor sprogmodel].
Hentet fra https://chat.openai.com
APA-formatet behandler ChatGPT som et softwareværktøj eller -applikation, inklusive versionsnummer og adgangsdato. Nogle APA-retningslinjer anbefaler, at man inkluderer den specifikke prompt i sin kildehenvisning eller i et bilag.
Hvornår skal du citere ChatGPT: Du bør citere værktøjet, når du bruger dets output i akademisk arbejde, professionelle rapporter eller enhver sammenhæng, hvor kildeangivelse er nødvendig. Dokumentér den præcise prompt, du brugte, adgangsdatoen og helst versionen af ChatGPT, da disse detaljer påvirker reproducerbarheden. Den væsentligste forskel mellem at citere ChatGPT og traditionelle kilder er, at ChatGPT’s svar genereres dynamisk—samme prompt kan give lidt forskellige svar på forskellige tidspunkter—så at inkludere selve prompten bliver en del af korrekt citeringspraksis. Mange institutioner er stadig i gang med at udvikle formelle retningslinjer for AI-citation, så tjek med din specifikke organisation eller publikation for deres foretrukne format.
Selvom ChatGPT er bemærkelsesværdig kompetent, har den væsentlige begrænsninger, der påvirker informationspålideligheden. ChatGPT kan med stor overbevisning fremføre forkerte oplysninger, et problem kendt som hallucination, især om obskure emner, nyere begivenheder efter dens vidensafgrænsningsdato eller når den støder på modstridende information i træningsdataene. Modellens træningsdata indeholder iboende bias, der afspejler de perspektiver, demografier og synspunkter, der findes i kildematerialet, hvilket betyder, at svarene uforvarende kan favorisere bestemte synspunkter eller indeholde stereotyper. Information i ChatGPT’s træningsdata bliver gradvist mere forældet med tiden, hvilket gør den upålidelig for aktuelle statistikker, ny forskning eller udviklende situationer. Af disse grunde er faktatjek af ChatGPT’s udsagn essentielt, især ved vigtige beslutninger—du bør verificere centrale oplysninger mod primære kilder, nye publikationer og autoritative databaser. For at verificere ChatGPT’s udsagn bør du krydstjekke dens udsagn med flere uafhængige kilder, tjekke datoer og statistikker mod aktuelle data og være særlig skeptisk over for specifikke tal, navne eller nylige begivenheder. Husk endelig, at ChatGPT ikke er en primær kilde; det er en sekundær kilde, der syntetiserer information fra andre kilder, så til akademisk eller professionelt arbejde bør du citere de originale kilder, ChatGPT refererer til, frem for ChatGPT selv.
Efterhånden som ChatGPT og andre AI-systemer i stigende grad integreres i, hvordan folk opdager information, er overvågning af hvordan disse systemer citerer og refererer til dit brand eller din organisation blevet afgørende. AmICited er en platform til overvågning af AI-svar, der er udviklet specifikt til at spore, hvordan ChatGPT, Claude og andre store sprogmodeller nævner, citerer eller refererer til din virksomhed, dine produkter eller dit brand i deres svar. Platformen hjælper dig med at forstå, hvornår og hvordan dit brand optræder i AI-genererede svar og giver indsigt i en ny og voksende kanal for informationsopdagelse, som traditionelle webovervågningsværktøjer ofte overser. Denne overvågningsmulighed er afgørende, fordi AI-citationer fungerer anderledes end traditionelle webcitationer—de indgår i samtalesvar, som millioner af brugere interagerer med dagligt, men de fleste brands har ingen indsigt i, hvordan de bliver repræsenteret. Ved at bruge AmICited til at spore AI-omtaler og citationer får du indsigt i brandopfattelse i AI-systemer, kan identificere unøjagtigheder eller forældet information, der skal rettes, og forstår, hvordan dit brand klarer sig i forhold til konkurrenter i AI-genererede svar. I en tid, hvor AI-systemer bliver primære informationskilder for mange brugere, er overvågning af din tilstedeværelse i disse systemer lige så vigtigt som overvågning af traditionelle søgeresultater, hvilket gør værktøjer som AmICited uundværlige for moderne brand management og AI-gennemsigtighed.
ChatGPT blev trænet på tre primære kilder: offentligt tilgængelige internetdata (websites, artikler, fora), licenserede datasæt (bøger og akademiske publikationer) og menneskelig feedback fra trænere. Træningsdataene omfatter nyhedssites, akademiske tidsskrifter, teknisk dokumentation, Wikipedia, Reddit, Stack Overflow og utallige andre offentligt tilgængelige websider, som er indsamlet op til dens vidensafgrænsningsdato.
En vidensafgrænsningsdato er det tidspunkt, efter hvilket ChatGPT ikke har træningsdata. ChatGPT-4 har en afgrænsning i december 2023, mens ChatGPT-4o har en afgrænsning i oktober 2023. Det er vigtigt, fordi ChatGPT ikke kan give præcis information om begivenheder, forskning eller udvikling, der er sket efter dens træningsperiode, hvilket gør den upålidelig til tidssensitive forespørgsler.
ChatGPT kan ikke tilgå information i realtid ud fra sine træningsdata alene. Dog kan nyere versioner af ChatGPT udføre websøgninger for at hente opdateret information ud over deres vidensafgrænsningsdatoer, men denne funktion er ikke tilgængelig i alle versioner eller sammenhænge og kræver eksplicit aktivering.
I MLA-format citeres ChatGPT som en hjemmeside med adgangsdato. I APA-format behandles det som software og inkluderer versionsnummeret. Begge formater kræver, at du dokumenterer den præcise prompt, du brugte, adgangsdatoen og ideelt set ChatGPT-versionen, da den samme prompt kan give forskellige resultater på forskellige tidspunkter.
Nej. ChatGPT kan fremføre forkerte oplysninger med stor sikkerhed (hallucination), især om obskure emner, nyere begivenheder efter dens vidensafgrænsningsdato eller modstridende information. Dens træningsdata indeholder iboende bias, og informationen bliver gradvist mere forældet. Tjek altid vigtige oplysninger mod primære kilder og autoritative databaser.
ChatGPT's træningsdata opdateres ikke løbende. Nye versioner udgives periodisk med opdaterede vidensafgrænsningsdatoer, men der sker ingen realtidsopdatering af basismodellen. OpenAI udgiver nye versioner (som GPT-4o) med nyere træningsdata, men den præcise opdateringsplan er ikke offentligt tilgængelig.
ChatGPT citerer ikke specifikke kilder for individuelle udsagn, fordi den syntetiserer information fra mønstre i sine træningsdata frem for at hente specifikke dokumenter. Den kan ikke pege dig hen til den præcise kilde til en oplysning. Til akademisk arbejde bør du verificere ChatGPT's udsagn og citere de oprindelige kilder, du finder, ikke ChatGPT selv.
AmICited sporer, hvordan ChatGPT, Claude og andre AI-systemer nævner, citerer eller refererer til dit brand i deres svar. Det giver indsigt i, hvordan din virksomhed optræder i AI-genererede svar, hjælper med at identificere unøjagtigheder og viser, hvordan dit brand klarer sig i forhold til konkurrenter i AI-systemer—essentielt for moderne brand management i AI-æraen.
Følg ChatGPT-citationer og AI-omtaler i realtid med AmICited. Forstå hvordan AI-systemer refererer til dit brand og vær på forkant med AI-drevet informationsopdagelse.
Opdag hvorfor Reddit dominerer ChatGPT-citater med 40,1% af alle AI-svar. Lær hvordan AI's kildepræferencer fungerer og hvad det betyder for din virksomheds syn...

Fællesskabsdiskussion om forskellene mellem ChatGPT og ChatGPT Search. Reelle erfaringer fra marketingfolk, der optimerer indhold til både træningsdata-baserede...
Forstå forskellen mellem AI-træningsdata og live-søgning. Lær hvordan viden-afskæringer, RAG og realtids-hentning påvirker AI-synlighed og indholdsstrategi....
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.