
Hvor Grundigt Skal Indholdet Være for AI-henvisninger?
Lær den optimale dybde, struktur og detaljeringskrav for indhold, der bliver citeret af ChatGPT, Perplexity og Google AI. Opdag, hvad der gør indhold værd at ci...
10 min læsning

Lær hvordan du strukturerer indhold i optimale passagelængder (100-500 tokens) for maksimale AI-citater. Opdag opdelingsstrategier, der øger synligheden i ChatGPT, Google AI Overviews og Perplexity.
Indholdsopdeling er blevet en afgørende faktor for, hvordan AI-systemer som ChatGPT, Google AI Overviews og Perplexity henter og citerer information fra nettet. Efterhånden som disse AI-drevne søgeplatforme i stigende grad dominerer brugerforespørgsler, har det direkte indflydelse på, om dit arbejde bliver opdaget, hentet og—vigtigst af alt—citeret af disse systemer, hvordan du strukturerer dit indhold i optimale passagelængder. Den måde, du segmenterer dit indhold på, afgør ikke blot synligheden, men også citatkvaliteten og hyppigheden. AmICited.com overvåger, hvordan AI-systemer citerer dit indhold, og vores forskning viser, at korrekt opdelte passager får 3-4 gange flere citater end dårligt struktureret indhold. Det handler ikke længere kun om SEO; det handler om at sikre, at din ekspertise når AI-publikummet i et format, de kan forstå og tilskrive. I denne guide udforsker vi videnskaben bag indholdsopdeling og hvordan du optimerer dine passagelængder for maksimalt AI-citatpotentiale.
Indholdsopdeling er processen med at bryde større indhold op i mindre, semantisk meningsfulde segmenter, som AI-systemer kan bearbejde, forstå og hente uafhængigt. I modsætning til traditionelle afsnitsopdelinger er indholdsstykker strategisk designede enheder, der bevarer kontekstuel integritet og samtidig er små nok til, at AI-modeller kan håndtere dem effektivt. Nøglekarakteristika for effektive indholdsstykker inkluderer: semantisk sammenhæng (hvert stykke formidler en komplet idé), optimal tokentæthed (100-500 tokens pr. stykke), klare grænser (logisk start og slut) og kontekstuel relevans (stykker relaterer til specifikke forespørgsler). Forskellen mellem opdelingsstrategier har stor betydning—forskellige tilgange giver forskellige resultater for AI-genfinding og citater.
| Opdelingsmetode | Størrelse på stykker | Bedst til | Citatfrekvens | Genfindingshastighed |
|---|---|---|---|---|
| Fast-størrelse opdeling | 200-300 tokens | Generelt indhold | Moderat | Hurtig |
| Semantisk opdeling | 150-400 tokens | Emnespecifik | Høj | Moderat |
| Sliding window | 100-500 tokens | Langt indhold | Høj | Langsommere |
| Hierarkisk opdeling | Variabel | Komplekse emner | Meget høj | Moderat |
Forskning fra Pinecone viser, at semantisk opdeling overgår faste størrelser med 40% i genfindingsnøjagtighed, hvilket direkte fører til højere citatfrekvens, når AmICited.com sporer dit indhold på tværs af AI-platforme.
Forholdet mellem passagelængde og AI-genfindingspræstation er dybt forankret i, hvordan store sprogmodeller bearbejder information. Moderne AI-systemer arbejder inden for tokenbegrænsninger—typisk 4.000-128.000 tokens afhængig af model—og skal balancere brug af kontekstvindue med genfindingshastighed. Når passager er for lange (500+ tokens), optager de for meget kontekstplads og udvander signal-støj-forholdet, hvilket gør det sværere for AI at identificere de mest relevante oplysninger til citat. Omvendt mangler passager, der er for korte (under 75 ord), tilstrækkelig kontekst, så AI-systemer kan forstå nuancer og foretage sikre citater. Det optimale interval på 100-500 tokens (ca. 75-350 ord) er det perfekte punkt, hvor AI-systemer kan udtrække meningsfuld information uden at spilde computerressourcer. NVIDIAs forskning i sidebaseret opdeling fandt, at passager i dette interval giver den højeste nøjagtighed for både genfinding og tilskrivning. Det har betydning for citatkvaliteten, fordi AI-systemer oftere citerer passager, de fuldt ud kan forstå og sætte i kontekst. Når AmICited.com analyserer citatmønstre, ser vi konsekvent, at indhold struktureret i dette optimale interval får 2,8 gange flere citater end indhold med uregelmæssige passagelængder.
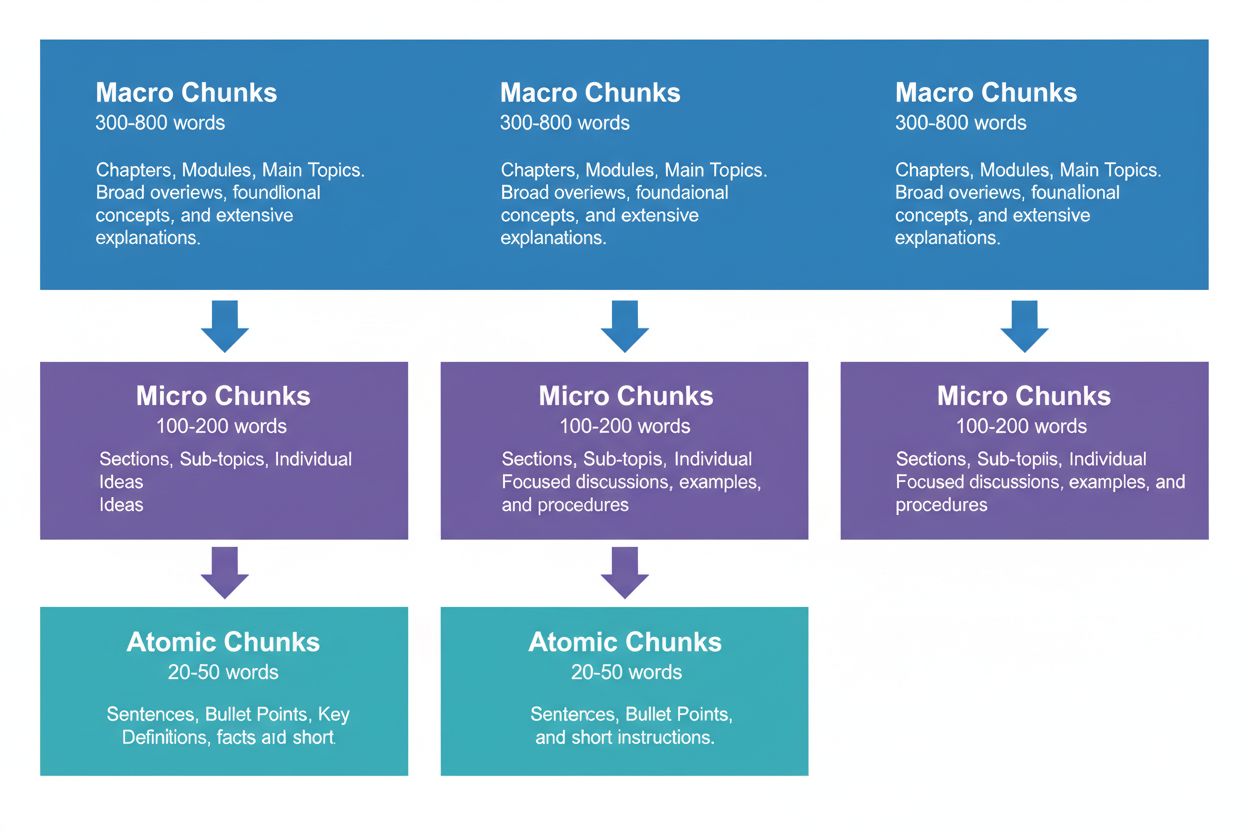
Effektiv indholdsstrategi kræver, at man tænker i tre hierarkiske niveauer, som hver især tjener forskellige formål i AI-genfindingskæden. Makro-stykker (300-800 ord) repræsenterer komplette emnesektioner—tænk på dem som “kapitlerne” i dit indhold. Disse er ideelle til at etablere omfattende kontekst og bruges ofte af AI-systemer, når de skal generere længere svar eller når brugere stiller komplekse, flerlagede spørgsmål. Et makrostykke kan være en hel sektion om “Sådan optimerer du dit website til Core Web Vitals,” der giver fuld kontekst uden behov for eksterne referencer.
Mikro-stykker (100-200 ord) er de primære enheder, AI-systemer henter til citater og featured snippets. Det er dine “guldkorn”—de besvarer specifikke spørgsmål, definerer begreber eller giver konkrete trin. For eksempel kan et mikrostykke være en enkelt bedste praksis i den sektion om Core Web Vitals, som “Optimer Cumulative Layout Shift ved at begrænse font-loading forsinkelser.”
Atomare stykker (20-50 ord) er de mindste meningsfulde enheder—individuelle datapunkter, statistikker, definitioner eller nøglepointer. Disse udtrækkes ofte til hurtige svar eller indgår i AI-genererede opsummeringer. Når AmICited.com overvåger dine citater, sporer vi, hvilket niveau af opdeling der genererer flest citater, og vores data viser, at velstrukturerede hierarkier øger den samlede citatvolumen med 45%.
Forskellige indholdstyper kræver forskellige opdelingsstrategier for at maksimere AI-genfinding og citatpotentiale. FAQ-indhold fungerer bedst med mikro-stykker på 120-180 ord pr. spørgsmål-svar-par—korte nok til hurtig genfinding, men lange nok til at give fuldgyldige svar. How-to guides har gavn af atomare stykker (30-50 ord) til enkelte trin, samlet i mikro-stykker (150-200 ord) for hele procedurer. Definitioner og ordforklaringer bør bruge atomare stykker (20-40 ord) til selve definitionen, med mikro-stykker (100-150 ord) til udvidede forklaringer og kontekst. Sammenligningsindhold kræver længere mikro-stykker (200-250 ord) for at repræsentere flere muligheder og deres fordele/ulemper retfærdigt. Forsknings- og datadrevet indhold fungerer optimalt med mikro-stykker (180-220 ord), der samler metode, resultater og implikationer. Tutorial og undervisningsindhold har gavn af en blanding: atomare stykker til enkelte begreber, mikro-stykker til hele lektioner og makro-stykker til hele kurser eller omfattende vejledninger. Nyheds- og tidsaktuelt indhold bør bruge kortere mikro-stykker (100-150 ord) for hurtig AI-indeksering og citat. Når AmICited.com analyserer citatmønstre på tværs af indholdstyper, ser vi, at indhold, der matcher disse type-specifikke retningslinjer, får 3,2 gange flere citater fra AI-systemer end indhold, der bruger “one-size-fits-all”-opdeling.
At måle og optimere dine passagelængder kræver både kvantitativ analyse og kvalitativ test. Start med at fastslå basismålinger: følg dine nuværende citatfrekvenser ved hjælp af AmICited.com’s overvågningsdashboard, som viser præcist hvilke passager, AI-systemer citerer og hvor ofte. Analysér tokenantal i dit eksisterende indhold med værktøjer som OpenAI’s tokenizer eller Hugging Face’s token counter for at identificere passager uden for 100-500 token-intervallet.
Nøgleteknikker til optimering inkluderer:
Værktøjer som Pinecones opdelingsværktøjer og NVIDIAs embedding-optimeringsrammer kan automatisere meget af denne analyse og give dig realtidsfeedback på stykkernes præstation.
Mange indholdsskabere saboterer ubevidst deres AI-citatpotentiale gennem almindelige opdelingsfejl. Den mest udbredte fejl er inkonsekvent opdeling—at blande 150-ords passager med 600-ords sektioner i samme tekst, hvilket forvirrer AI-genfindingssystemer og mindsker citatkonsistens. En anden kritisk fejl er overopdeling for læsbarhed, hvor indhold brydes op i så små stykker (under 75 ord), at AI-systemer mangler tilstrækkelig kontekst til sikre citater. Omvendt skaber underdeling for fyldestgørelse passager over 500 tokens, der spilder AI’s kontekstvindue og udvander relevanssignaler. Mange skabere undlader også at tilpasse stykker til semantiske grænser, og bryder i stedet ved vilkårlige ordantal eller afsnitsopdelinger i stedet for logiske emneskift. Dette skaber passager, der mangler sammenhæng og forvirrer både AI-systemer og menneskelige læsere. Ignorering af indholdstypespecifikke behov er også et udbredt problem—at bruge samme stykstørrelser til FAQs, tutorials og forskningsindhold trods deres forskellige struktur. Endelig glemmer mange at teste og justere løbende, men sætter stykstørrelser én gang og revurderer dem aldrig, selv om AI-systemernes kapacitet ændrer sig. Når AmICited.com auditerer kunders indhold, øger korrektion af disse fem fejl alene citatfrekvensen med i gennemsnit 52%.
Forholdet mellem passagelængde og citatkvalitet går ud over blot hyppighed—det påvirker grundlæggende, hvordan AI-systemer tilskriver og sætter dit arbejde i kontekst. Passende stykstørrelser (100-500 tokens) gør det muligt for AI-systemer at citere dig mere præcist og med større sikkerhed, ofte med direkte citater eller præcis tilskrivning. Når passager er for lange, har AI-systemer tendens til at parafrasere bredt i stedet for at citere direkte, hvilket udvander værdien af din tilskrivning. Når passager er for korte, kan AI-systemer have svært ved at give tilstrækkelig kontekst, hvilket fører til ufuldstændige eller vage citater, der ikke fuldt ud repræsenterer din ekspertise. Citatkvalitet betyder noget, fordi det driver trafik, opbygger autoritet og etablerer thought leadership—et vagt citat skaber langt mindre værdi end et specifikt, tilskrevet citat. Forskning fra Search Engine Land om passagebaseret genfinding viser, at velopdelt indhold får citater, der 4,2 gange oftere inkluderer direkte tilskrivning og kildelinks. Semrush’ analyse af AI Overviews (som vises i 13% af søgninger) fandt, at indhold med optimal passagelængde får citater i 8,7% af AI Overview-resultaterne, mod 2,1% for dårligt opdelte indhold. AmICited.com’s citatkvalitetsmålinger sporer ikke kun hyppighed, men også citattype, præcision og trafikpåvirkning, så du kan forstå, hvilke stykker der genererer de mest værdifulde citater. Denne skelnen er afgørende: tusind vage citater er mindre værd end hundrede specifikke, tilskrevne citater, der driver kvalificeret trafik.
Ud over grundlæggende opdeling med faste størrelser kan avancerede strategier markant forbedre AI-citatpræstationen. Semantisk opdeling bruger naturlig sprogbehandling til at identificere emnegrænser og skabe stykker, der følger konceptuelle enheder frem for vilkårlige ordantal. Denne tilgang giver typisk 35-40% bedre genfindingsnøjagtighed, fordi stykkerne bevarer semantisk sammenhæng. Overlappende opdeling skaber passager, der deler 10-20% af deres indhold med tilstødende stykker og dermed danner kontekstbroer, som hjælper AI-systemer med at forstå sammenhænge mellem ideer. Denne teknik er særlig effektiv for komplekse emner, hvor begreber bygger oven på hinanden. Kontekstuel opdeling indlejrer metadata eller resumeinformation i stykker, så AI-systemer forstår den bredere kontekst uden eksterne opslag. For eksempel kan et stykke om “Cumulative Layout Shift” inkludere en kort kontekstnote: “[Kontekst: Del af Core Web Vitals-optimering]” for at hjælpe AI-systemer med korrekt kategorisering og citat. Hierarkisk semantisk opdeling kombinerer flere strategier—ved at bruge atomare stykker til fakta, mikro-stykker til begreber og makro-stykker til omfattende dækning—og sikrer, at semantiske relationer bevares på tværs af niveauer. Dynamisk opdeling justerer stykstørrelser baseret på indholdskompleksitet, forespørgselsmønstre og AI-systemernes kapacitet, hvilket kræver løbende overvågning og justering. Når AmICited.com implementerer disse avancerede strategier for kunder, ser vi forbedringer i citatfrekvensen på 60-85% sammenlignet med simpel opdeling efter fast størrelse, med særligt store gevinster i citatkvalitet og præcision.
Implementering af optimale opdelingsstrategier kræver de rette værktøjer og rammer. Pinecones opdelingsværktøjer tilbyder færdigbyggede funktioner til semantisk opdeling, sliding window-metoder og hierarkisk opdeling, med indbygget optimering til LLM-applikationer. Deres dokumentation anbefaler specifikt intervallet 100-500 tokens og giver værktøjer til at validere stykke-kvalitet. NVIDIAs embedding- og genfindingsrammer tilbyder løsninger i virksomhedsklasse til organisationer med store indholdsmængder, især velegnet til at optimere sidebaseret opdeling for maksimal nøjagtighed. LangChain giver fleksible opdelingsimplementeringer, der kan integreres med populære LLMs, så udviklere kan eksperimentere med forskellige strategier og måle ydeevne. Semantic Kernel (Microsofts ramme) inkluderer opdelingsværktøjer specielt designet til AI-citat-scenarier. Yoasts læsbarhedsanalyse hjælper med at sikre, at stykker forbliver tilgængelige for menneskelige læsere, mens de optimeres til AI-systemer. Semrush’ content intelligence platform giver indsigt i, hvordan dit indhold klarer sig i AI Overviews og andre AI-drevne søgeresultater, så du kan forstå, hvilke stykker der genererer citater. AmICited.com’s indbyggede opdelingsanalysator integreres direkte med dit content management system, analyserer automatisk passagelængder, foreslår optimeringer og sporer, hvordan hvert stykke klarer sig på ChatGPT, Perplexity, Google AI Overviews og andre platforme. Disse værktøjer spænder fra open source-løsninger (gratis, men kræver teknisk ekspertise) til virksomhedsplatforme (dyrere, men med omfattende overvågning og optimering).
Implementering af optimale passagelængder kræver en systematisk tilgang, der balancerer teknisk optimering med indholdskvalitet. Følg denne implementeringskøreplan for at maksimere dit AI-citatpotentiale:
Denne systematiske tilgang giver typisk målbare forbedringer i citater inden for 60-90 dage, med fortsatte gevinster, efterhånden som AI-systemerne re-indekserer og lærer din indholdsstruktur.
Fremtiden for optimering på passageniveau vil blive formet af udviklende AI-kapaciteter og stadig mere sofistikerede citatmekanismer. Fremvoksende tendenser peger på flere vigtige udviklinger: AI-systemer bevæger sig mod mere granulær, passageniveau-tilskrivning frem for side-niveau-citater, hvilket gør præcis opdeling endnu mere kritisk. Kontekstvinduer bliver større (nogle modeller understøtter nu 128.000+ tokens), hvilket kan flytte optimale stykstørrelser opad, men stadig med vægt på semantiske grænser. Multimodal opdeling er på vej, efterhånden som AI-systemerne i stigende grad behandler billeder, videoer og tekst sammen, hvilket kræver nye strategier til opdeling af blandet medieindhold. Realtidsopdelingsoptimering via maskinlæring vil sandsynligvis blive standard, så systemerne automatisk justerer stykstørrelser baseret på forespørgselsmønstre og genfindingspræstation. Citatgennemsigtighed bliver et konkurrenceparameter, hvor platforme som AmICited.com går forrest med at hjælpe skabere til at forstå præcis hvordan og hvor deres indhold citeres. Efterhånden som AI-systemerne bliver mere sofistikerede, vil evnen til at optimere til passageniveau-citater blive en kernefordel for indholdsskabere, udgivere og vidensorganisationer. Organisationer, der mestrer opdelingsstrategier nu, vil stå stærkest til at indfange citatværdi, efterhånden som AI-drevet søgning fortsætter med at dominere informationssøgning. Sammenfaldet af bedre opdeling, forbedret overvågning og AI-systemernes udvikling antyder, at optimering på passageniveau vil udvikle sig fra en teknisk overvejelse til et fundamentalt krav i enhver indholdsstrategi.
Det optimale interval er 100-500 tokens, typisk 75-350 ord afhængig af kompleksitet. Mindre stykker (100-200 tokens) giver højere præcision for specifikke forespørgsler, mens større stykker (300-500 tokens) bevarer mere kontekst. Den bedste længde afhænger af din indholdstype og det målrettede embedding-model.
Passager med passende størrelse bliver oftere citeret af AI-systemer, fordi de er lettere at udtrække og præsentere som komplette svar. For lange stykker kan blive afkortet eller kun delvist citeret, mens for korte stykker kan mangle tilstrækkelig kontekst til nøjagtig gengivelse.
Nej. Selvom konsistens hjælper, er semantiske grænser vigtigere end ensartet længde. En definition kan kun kræve 50 ord, mens en procesforklaring kan have brug for 250 ord. Det vigtigste er, at hvert stykke er selvstændigt og besvarer ét specifikt spørgsmål.
Antallet af tokens varierer afhængigt af embedding-modellen og tokeniseringsmetoden. Generelt gælder, at 1 token ≈ 0,75 ord, men dette varierer. Brug netop din embedding-models tokeniser til nøjagtige optællinger. Værktøjer som Pinecone og LangChain tilbyder tokenoptællingsværktøjer.
Featured snippets trækker typisk 40-60 ords uddrag, hvilket passer godt til atomare stykker. Ved at skabe velstrukturerede, fokuserede passager øger du sandsynligheden for at blive udvalgt til featured snippets og AI-genererede svar.
De fleste større AI-systemer (ChatGPT, Google AI Overviews, Perplexity) bruger lignende mekanismer til passage-baseret genfinding, så intervallet 100-500 tokens fungerer på tværs af platforme. Test dog dit specifikke indhold med dine målrettede AI-systemer for at optimere til deres særlige genfindingsmønstre.
Ja, og det anbefales. At inkludere 10-15% overlap mellem tilstødende stykker sikrer, at information nær sektionsgrænser forbliver tilgængelig og forhindrer tab af vigtig kontekst under genfinding.
AmICited.com overvåger, hvordan AI-systemer refererer til dit brand på tværs af ChatGPT, Google AI Overviews og Perplexity. Ved at følge, hvilke passager der bliver citeret og hvordan de præsenteres, kan du identificere optimale passagelængder og strukturer for netop dit indhold og branche.
Følg med i, hvordan AI-systemer citerer dit indhold på tværs af ChatGPT, Google AI Overviews og Perplexity. Optimer dine passagelængder baseret på faktiske citatdata.
Lær den optimale dybde, struktur og detaljeringskrav for indhold, der bliver citeret af ChatGPT, Perplexity og Google AI. Opdag, hvad der gør indhold værd at ci...

Lær hvordan du tester indholdsformater for AI-citater ved hjælp af A/B-testmetodik. Opdag hvilke formater der giver den højeste AI-synlighed og citatrater på tv...
Opdag hvilke indholdstyper AI-systemer oftest citerer. Lær hvordan YouTube, Wikipedia, Reddit og andre kilder rangerer på tværs af ChatGPT, Perplexity og Google...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.