Opdag hvordan Retrieval-Augmented Generation forvandler AI-citater og muliggør nøjagtig kildeangivelse og forankrede svar på tværs af ChatGPT, Perplexity og Google AI Overviews.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
Store sprogmodeller har revolutioneret AI, men de har en kritisk fejl: viden-cutoffs. Disse modeller er trænet på data op til et bestemt tidspunkt, hvilket betyder, at de ikke kan få adgang til information efter denne dato. Ud over forældethed lider traditionelle LLM’er af hallucinationer—de genererer selvsikkert falsk information, der lyder plausibel—og de giver ingen kildeangivelse for deres påstande. Når en virksomhed har brug for aktuelle markedsdata, proprietær forskning eller verificerbare fakta, slår traditionelle LLM’er ikke til og efterlader brugerne med svar, de ikke kan stole på eller verificere.
Hvad er RAG – Kernebegreb & Komponenter
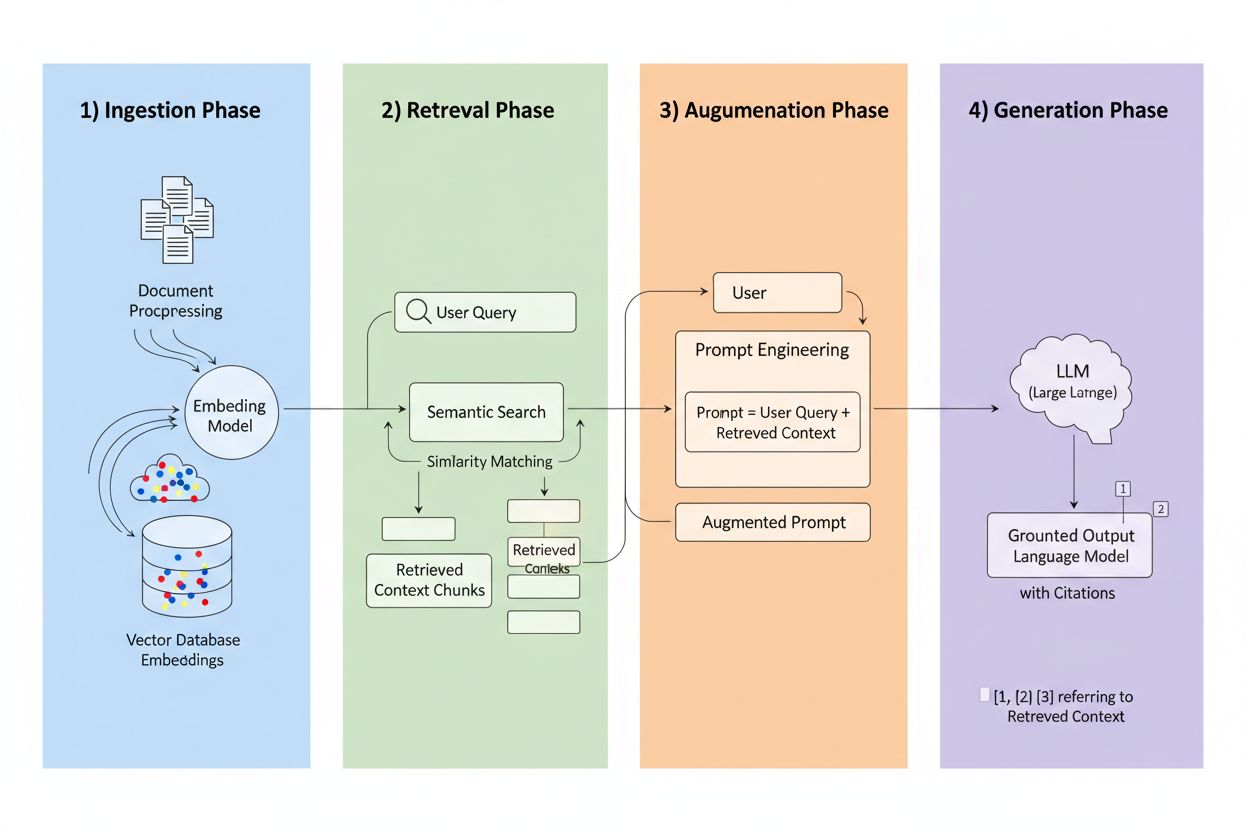
Retrieval-Augmented Generation (RAG) er en ramme, der kombinerer de generative kræfter fra LLM’er med præcisionen fra informationshentningssystemer. I stedet for kun at stole på træningsdata henter RAG-systemer relevant information fra eksterne kilder, før de genererer svar, og skaber dermed en pipeline, der forankrer svar i faktiske data. De fire kernekomponenter arbejder sammen: Ingestion (konvertering af dokumenter til søgbare formater), Retrieval (finde de mest relevante kilder), Augmentation (berigelse af prompten med hentet kontekst), og Generation (skabelse af det endelige svar med citater). Her er hvordan RAG sammenlignes med traditionelle tilgange:
Aspect
Traditionel LLM
RAG-system
Videnskilde
Statisk træningsdata
Eksterne indekserede kilder
Citeringsmulighed
Ingen/hallucineret
Sporbar til kilder
Nøjagtighed
Tilbøjelig til fejl
Forankret i fakta
Realtidsdata
Nej
Ja
Hallucinationsrisiko
Høj
Lav
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Hvordan RAG-hentning fungerer – Teknisk fordybning
Hentningsmotoren er RAG’s bankende hjerte, og den er langt mere sofistikeret end simpel nøgleordsmatchning. Dokumenter konverteres til vektor-indlejringer—matematiske repræsentationer, der fanger semantisk betydning—hvilket gør det muligt for systemet at finde konceptuelt lignende indhold, selv når de præcise ord ikke matcher. Systemet opdeler dokumenter i håndterbare stykker, typisk 256-1024 tokens, hvilket balancerer kontekstbevarelse med præcision i hentningen. De mest avancerede RAG-systemer anvender hybrid-søgning, der kombinerer semantisk lighed med traditionel nøgleordsmatchning for at fange både konceptuelle og præcise matches. En reranking-mekanisme scorer derefter disse kandidater, ofte ved hjælp af cross-encoder-modeller, der vurderer relevans mere nøjagtigt end den indledende hentning. Relevans beregnes gennem flere signaler: semantiske lighedsscorer, overlap af nøgleord, metadata-match og domæneautoritet. Hele processen foregår på millisekunder, så brugerne får hurtige, nøjagtige svar uden mærkbar ventetid.
Fordelen ved citater
Her forandrer RAG citeringslandskabet: Når et system henter information fra en specifik indekseret kilde, bliver denne kilde sporbar og verificerbar. Hvert tekststykke kan føres tilbage til dets oprindelige dokument, URL eller publikation, hvilket gør citering automatisk i stedet for hallucineret. Dette fundamentale skift skaber hidtil uset gennemsigtighed i AI-beslutningstagning—brugere kan se præcis hvilke kilder, der har informeret svaret, verificere påstande uafhængigt og selv vurdere kildens troværdighed. I modsætning til traditionelle LLM’er, hvor citater ofte er opfundne eller generiske, er RAG-citater forankret i faktiske hentningsbegivenheder. Denne sporbarhed opbygger brugertillid markant, da folk kan validere information frem for blot at acceptere den på tro og love. For indholdsskabere og udgivere betyder det, at deres arbejde kan blive opdaget og krediteret gennem AI-systemer, hvilket åbner helt nye synlighedskanaler.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Faktorer for citeringskvalitet i RAG-systemer
Ikke alle kilder er lige i RAG-systemer, og flere faktorer bestemmer, hvilket indhold der citeres hyppigst:
Autoritet: Domænets omdømme, backlink-profiler og tilstedeværelse i viden-grafer signalerer troværdighed til hentningsalgoritmer
Aktualitet: Indhold, der opdateres inden for 48-72 timers cyklusser, rangerer højere, da friskhed indikerer aktiv vedligeholdelse og pålidelighed
Relevans: Semantisk overensstemmelse med brugerforespørgsler afgør, om indholdet overhovedet vises i hentningsresultaterne
Struktur: Klar hierarki, beskrivende overskrifter og semantisk markup hjælper systemer med at forstå og udtrække information nøjagtigt
Faktuel tæthed: Indhold fyldt med specifikke data, statistikker og citater giver flere hentbare bidder end generiske overblik
Viden-graf: Tilstedeværelse i Wikipedia, Wikidata eller branchespecifikke videnbaser øger sandsynligheden for citering markant
Hver faktor forstærker de andre—en velstruktureret, hyppigt opdateret artikel fra et autoritativt domæne med stærke backlinks og viden-graf-tilstedeværelse bliver en citatmagnet i RAG-systemer. Dette skaber et nyt optimeringsparadigme, hvor synlighed afhænger mindre af trafikdrevet SEO og mere af at blive en betroet, struktureret informationskilde.
Hvordan forskellige AI-platforme bruger RAG til citater
Forskellige AI-platforme implementerer RAG med forskellige strategier, hvilket skaber varierede citeringsmønstre. ChatGPT vægter Wikipedia-kilder tungt, og studier viser, at cirka 26-35% af citaterne kommer fra Wikipedia alene, hvilket afspejler dets autoritet og strukturerede format. Google AI Overviews benytter en mere varieret kildeudvælgelse, idet de trækker fra nyhedssider, akademiske artikler og fora, hvor Reddit optræder i cirka 5% af citaterne trods lavere traditionel autoritet. Perplexity AI citerer typisk 3-5 kilder per svar og udviser en stærk præference for branchespecifikke publikationer og nyere nyheder, hvor der optimeres for grundighed og aktualitet. Disse platforme vægter domæneautoritet forskelligt—nogle prioriterer traditionelle indikatorer som backlinks og domænealder, mens andre lægger vægt på indholdsaktualitet og semantisk relevans. At forstå disse platformspecifikke hentningsstrategier er afgørende for indholdsskabere, da optimering til én platforms RAG-system kan adskille sig markant fra en andens.
RAG vs traditionel søgning – Citeringsimplikationer
Fremkomsten af RAG forstyrrer fundamentalt den traditionelle SEO-visdom. I søgemaskineoptimering korrelerer citater og synlighed direkte med trafik—du skal have klik for at have betydning. RAG vender denne ligning på hovedet: indhold kan blive citeret og påvirke AI-svar uden at generere nogen trafik. En velstruktureret, autoritativ artikel kan optræde i dusinvis af AI-svar dagligt uden at modtage et eneste klik, da brugerne får deres svar direkte fra AI-opsummeringen. Det betyder, at autoritetssignaler er vigtigere end nogensinde, da de er den primære mekanisme, RAG-systemer bruger til at vurdere kildekvalitet. Konsistens på tværs af platforme bliver kritisk—hvis dit indhold findes på din hjemmeside, LinkedIn, branchedatabaser og viden-grafer, ser RAG-systemer forstærkede autoritetssignaler. Tilstedeværelse i viden-grafer går fra at være et “nice-to-have” til at være essentiel infrastruktur, da disse strukturerede databaser er primære hentekilder for mange RAG-implementeringer. Citeringsspillet er fundamentalt ændret fra “skab trafik” til “bliv en betroet informationskilde”.
Optimering af indhold til RAG-citater
For at maksimere RAG-citater skal indholdsstrategien skifte fra trafikoptimering til kildeoptimering. Implementer opdateringscyklusser på 48-72 timer for evergreen-indhold, hvilket signalerer til hentningssystemer, at din information er aktuel. Brug struktureret data markup (Schema.org, JSON-LD) for at hjælpe systemerne med at forstå indholdets betydning og relationer. Tilpas dit indhold semantisk til almindelige forespørgselsmønstre—brug naturligt sprog, der matcher, hvordan folk stiller spørgsmål, ikke kun hvordan de søger. Formater indhold med FAQ- og Q&A-sektioner, da disse direkte matcher det spørgsmål-svar-mønster, RAG-systemer bruger. Udvikl eller bidrag til Wikipedia- og viden-graf-opslag, da disse er primære hentekilder for de fleste platforme. Opbyg backlink-autoritet gennem strategiske partnerskaber og citater fra andre autoritative kilder, da linkprofiler fortsat er stærke autoritetssignaler. Endelig, oprethold konsistens på tværs af platforme—sørg for, at dine kernepåstande, data og budskaber er ensartede på din hjemmeside, sociale profiler, branchedatabaser og viden-grafer, hvilket skaber forstærkede signaler om pålidelighed.
Fremtiden for RAG og citater
RAG-teknologien udvikler sig fortsat hurtigt, og flere tendenser omformer måden, citater fungerer på. Mere sofistikerede hentningsalgoritmer vil bevæge sig ud over semantisk lighed mod dybere forståelse af forespørgselsintention og kontekst, hvilket forbedrer citeringsrelevans. Specialiserede videnbaser vil opstå for specifikke domæner—medicinske RAG-systemer, der bruger kurateret medicinsk litteratur, juridiske systemer, der bruger lovsamlinger og retspraksis—hvilket skaber nye citeringsmuligheder for autoritative domænekilder. Integration med multi-agent-systemer vil gøre det muligt for RAG at orkestrere flere specialiserede hentere, der kombinerer indsigt fra forskellige videnbaser for mere omfattende svar. Realtidsdataadgang vil blive markant forbedret, så RAG-systemer kan inkorporere live information fra API’er, databaser og streamingkilder. Agentisk RAG—hvor AI-agenter selvstændigt beslutter, hvad de skal hente, hvordan de skal behandle det, og hvornår de skal iterere—vil skabe mere dynamiske citeringsmønstre, hvor kilder potentielt citeres flere gange, efterhånden som agenter forfiner deres ræsonnement.
AmICiteds rolle i RAG-citeringsmonitorering
Efterhånden som RAG omformer måden, AI-systemer opdager og citerer kilder på, bliver forståelsen af din citeringspræstation afgørende. AmICited overvåger AI-citater på tværs af platforme, og sporer hvilke af dine kilder, der vises i ChatGPT, Google AI Overviews, Perplexity og nye AI-systemer. Du får vist hvilke specifikke kilder, der bliver citeret, hvor ofte de optræder, og i hvilken kontekst—hvilket afslører, hvilket indhold der resonerer med RAG-hentningsalgoritmerne. Vores platform hjælper dig med at forstå citeringsmønstre på tværs af din indholdsportefølje og identificere, hvad der gør visse dele værd at citere og andre usynlige. Mål dit brands synlighed i AI-svar med metrics, der betyder noget i RAG-æraen, og gå ud over traditionelle trafikanalyser. Udfør konkurrentanalyse af citeringspræstation, og se hvordan dine kilder klarer sig i forhold til konkurrenterne i AI-genererede svar. I en verden, hvor AI-citater driver synlighed og autoritet, er klar indsigt i din citeringspræstation ikke valgfri—det er sådan, du forbliver konkurrencedygtig.
Ofte stillede spørgsmål
Hvad er forskellen mellem RAG og traditionelle LLM'er?
Traditionelle LLM'er er afhængige af statiske træningsdata med viden-cutoffs og kan ikke få adgang til realtidsinformation, hvilket ofte resulterer i hallucinationer og uverificerbare påstande. RAG-systemer henter information fra eksterne indekserede kilder, før de genererer svar, hvilket muliggør nøjagtige citater og forankrede svar baseret på aktuel, verificerbar data.
Hvordan forbedrer RAG citeringsnøjagtighed?
RAG sporer hvert stykke hentet information tilbage til dets oprindelige kilde, hvilket gør citater automatiske og verificerbare i stedet for hallucinerede. Dette skaber en direkte forbindelse mellem svaret og kildematerialet, så brugere kan verificere påstande uafhængigt og vurdere kildens troværdighed.
Hvilke faktorer bestemmer, hvilke kilder der bliver citeret i RAG-systemer?
RAG-systemer vurderer kilder baseret på autoritet (domænets omdømme og backlinks), aktualitet (indhold opdateret inden for 48-72 timer), semantisk relevans til forespørgslen, indholdsstruktur og klarhed, faktuel tæthed med specifikke datapunkter samt tilstedeværelse i viden-grafer som Wikipedia. Disse faktorer kombineres for at bestemme sandsynligheden for citering.
Hvordan kan jeg optimere mit indhold til RAG-citater?
Opdater indhold hver 48-72 timer for at opretholde friskhedssignaler, implementer struktureret data markup (Schema.org), tilpas indhold semantisk til almindelige forespørgsler, brug FAQ- og Q&A-formatering, udvikl Wikipedia- og viden-graf-tilstedeværelse, opbyg backlink-autoritet og oprethold konsistens på tværs af alle platforme.
Hvorfor er tilstedeværelse i viden-grafer vigtig for AI-citater?
Viden-grafer som Wikipedia og Wikidata er primære kilder til hentning for de fleste RAG-systemer. Tilstedeværelse i disse strukturerede databaser øger sandsynligheden for citering markant og skaber grundlæggende tillidssignaler, som AI-systemer gentagne gange henviser til på tværs af forskellige forespørgsler.
Hvor ofte skal jeg opdatere indhold for RAG-synlighed?
Indhold bør opdateres hver 48-72 timer for at opretholde stærke aktualitetssignaler i RAG-systemer. Det kræver ikke komplette omskrivninger—tilføjelse af nye datapunkter, opdatering af statistikker eller udvidelse af sektioner med seneste udviklinger er tilstrækkeligt til at bevare citeringsberettigelse.
Hvilken rolle spiller domæneautoritet i RAG-citater?
Domæneautoritet fungerer som en pålidelighedsindikator i RAG-algoritmer og tegner sig for ca. 5% af sandsynligheden for citering. Det vurderes gennem domænealder, SSL-certifikater, backlink-profiler, ekspertattribution og tilstedeværelse i viden-grafer, som alle bidrager til valg af kilde.
Hvordan hjælper AmICited med at overvåge RAG-citater?
AmICited sporer hvilke af dine kilder, der vises i AI-genererede svar på ChatGPT, Google AI Overviews, Perplexity og andre platforme. Du får vist citeringsfrekvens, kontekst og konkurrencepræstation, hvilket hjælper dig med at forstå, hvad der gør indhold værd at citere i RAG-æraen.
Overvåg din brands AI-citater
Forstå hvordan dit brand vises i AI-genererede svar på ChatGPT, Perplexity, Google AI Overviews og flere. Spor citeringsmønstre, mål synlighed og optimer din tilstedeværelse i det AI-drevne søgelandskab.
Hvad er RAG i AI-søgning: Komplet guide til Retrieval-Augmented Generation
Lær hvad RAG (Retrieval-Augmented Generation) er i AI-søgning. Opdag hvordan RAG forbedrer nøjagtighed, reducerer hallucinationer og driver ChatGPT, Perplexity ...
Sådan fungerer Retrieval-Augmented Generation: Arkitektur og proces
Lær hvordan RAG kombinerer LLM'er med eksterne datakilder for at generere nøjagtige AI-svar. Forstå femtrinsprocessen, komponenterne og hvorfor det er vigtigt f...
Hvordan håndterer RAG-systemer forældet information?
Lær hvordan Retrieval-Augmented Generation-systemer håndterer opdatering af vidensbaser, forhindrer forældede data og opretholder ajourført information gennem i...
10 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.