Sådan identificerer du AI-crawlere i dine serverlogs
Lær at identificere og overvåge AI-crawlere som GPTBot, ClaudeBot og PerplexityBot i dine serverlogs. Komplet guide med user-agent strings, IP-verificering og praktiske overvågningsstrategier.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
Landskabet for webtrafik har ændret sig fundamentalt med fremkomsten af AI-datainhentning, som går langt ud over traditionel søgemaskineindeksering. I modsætning til Googles Googlebot eller Bings crawler, der har eksisteret i årtier, udgør AI-crawlere nu en betydelig og hastigt voksende del af servertrafikken—med nogle platforme, der oplever vækstrater på over 2.800% år for år. Forståelse af AI-crawleraktivitet er afgørende for hjemmesideejere, fordi det direkte påvirker båndbreddeomkostninger, serverens ydeevne, databrugsmålinger og især din evne til at kontrollere, hvordan dit indhold bruges til at træne AI-modeller. Uden ordentlig overvågning flyver du reelt i blinde over for et stort skift i, hvordan dine data tilgås og udnyttes.
Forstå AI-crawlertyper & User-Agent Strings
AI-crawlere findes i mange former, hver med forskellige formål og genkendelige karakteristika gennem deres user-agent strings. Disse strings er de digitale fingeraftryk, crawlere efterlader i dine serverlogs, hvilket gør dig i stand til at identificere præcis, hvilke AI-systemer der tilgår dit indhold. Herunder er en omfattende referencetabel over de største AI-crawlere, der aktuelt er aktive på nettet:
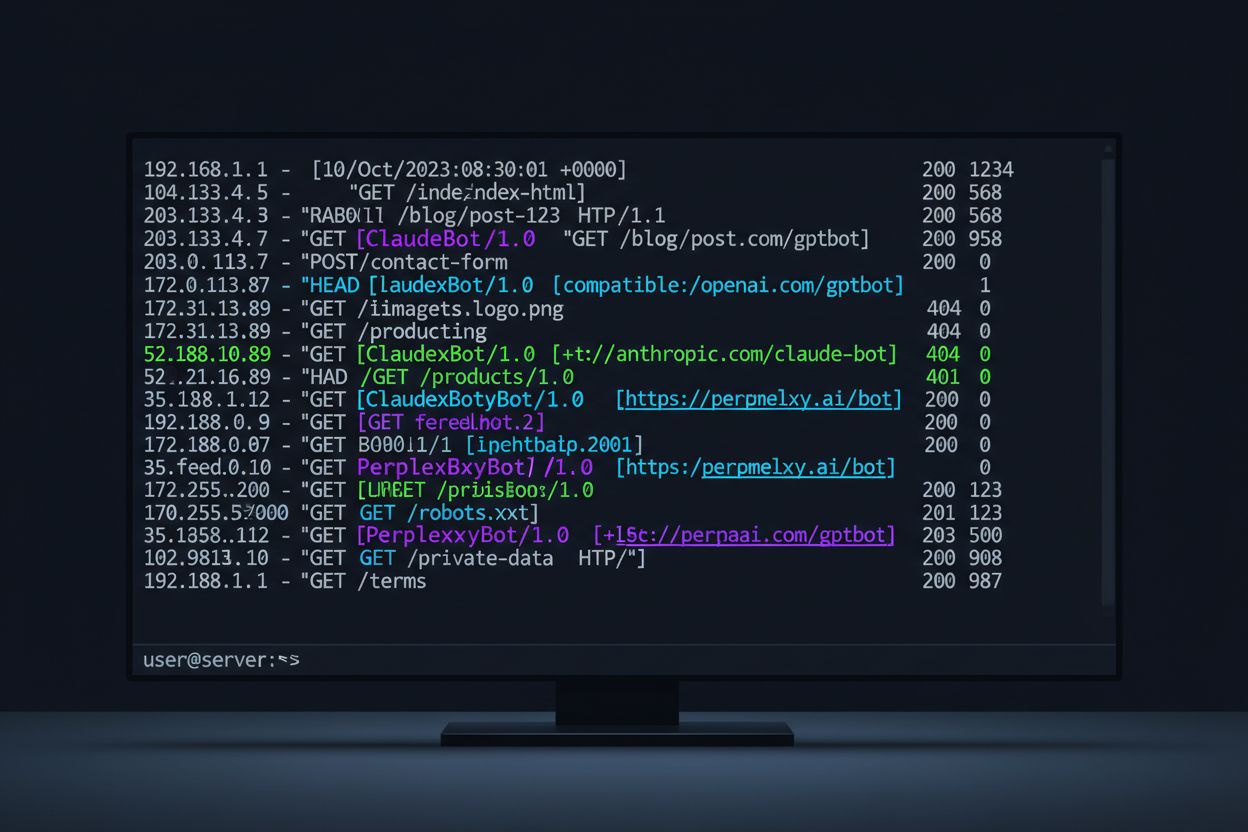
Analyse af dine serverlogs for AI-crawleraktivitet kræver en systematisk tilgang og kendskab til de logformater, din webserver genererer. De fleste websites bruger enten Apache eller Nginx, der har lidt forskellige logstrukturer, men begge er lige velegnede til at identificere crawlertrafik. Det vigtige er at vide, hvor du skal kigge, og hvilke mønstre du skal søge efter. Her er et eksempel på en Apache access-log post:
Denne kommando udtrækker user-agent stringen, filtrerer efter bot-lignende poster og tæller forekomster, hvilket giver dig et klart billede af, hvilke crawlere der rammer dit site oftest.
IP-verificering & autentifikation
User-agent strings kan forfalskes, hvilket betyder, at en ondsindet aktør kan udgive sig for at være GPTBot, selvom de i virkeligheden er noget helt andet. Derfor er IP-verificering essentiel for at bekræfte, at trafik, der hævder at komme fra legitime AI-virksomheder, faktisk stammer fra deres infrastruktur. Du kan udføre et reverse DNS-opslag på IP-adressen for at verificere ejerskab:
nslookup 192.0.2.1
Hvis reverse DNS opløses til et domæne ejet af OpenAI, Anthropic eller en anden legitim AI-virksomhed, kan du være mere sikker på, at trafikken er ægte. Her er de vigtigste verificeringsmetoder:
Reverse DNS-opslag: Tjek om IP’ens reverse DNS matcher virksomhedens domæne
IP-range-verificering: Sammenlign med offentliggjorte IP-ranges fra OpenAI, Anthropic og andre AI-virksomheder
WHOIS-opslag: Verificér, at IP-blokken er registreret til den pågældende organisation
Historisk analyse: Følg om IP’en konsekvent har besøgt dit site med samme user-agent
IP-verificering er vigtig, fordi det forhindrer dig i at blive narret af falske crawlere, der kan være konkurrenter, der scraper dit indhold, eller ondsindede aktører, der forsøger at overbelaste dine servere, mens de udgiver sig for at være legitime AI-tjenester.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Detektering af AI-crawlere i analysetools
Traditionelle analyseplatforme som Google Analytics 4 og Matomo er designet til at filtrere bottrafik fra, hvilket betyder, at AI-crawleraktivitet stort set er usynlig i dine almindelige analyseskærmbilleder. Dette skaber et blindt punkt, hvor du ikke er opmærksom på, hvor meget trafik og båndbredde AI-systemer forbruger. For at overvåge AI-crawleraktivitet korrekt skal du bruge server-side løsninger, der indsamler rå logdata, før det bliver filtreret:
ELK Stack (Elasticsearch, Logstash, Kibana): Centraliseret logindsamling og visualisering
Splunk: Enterprise-grade loganalyse med realtidsalarmering
Datadog: Cloud-native overvågning med botdetektering
Grafana + Prometheus: Open source overvågningsstack til brugerdefinerede dashboards
Du kan også integrere AI-crawlerdata i Google Data Studio via Measurement Protocol for GA4, så du kan oprette brugerdefinerede rapporter, der viser AI-trafik sammen med dine almindelige analyser. Dette giver dig et komplet billede af al trafik til dit site, ikke kun menneskelige besøgende.
Praktisk loganalyse-workflow
Implementering af et praktisk workflow for overvågning af AI-crawleraktivitet kræver etablering af baseline-målinger og regelmæssig kontrol. Start med at indsamle en uges baseline-data for at forstå dine normale crawlertrafikmønstre, og opsæt derefter automatiseret overvågning til at opdage afvigelser. Her er en daglig overvågningscheckliste:
Gennemgå samlede crawlerforespørgsler og sammenlign med baseline
Identificér eventuelle nye crawlere, der ikke er set før
Tjek for usædvanlige crawl-rater eller -mønstre
Verificér IP-adresser for de mest aktive crawlere
Overvåg båndbreddeforbrug pr. crawler
Opret alarmer for crawlere, der overskrider rate limits
Brug dette bash-script til at automatisere daglig analyse:
Planlæg dette script til at køre dagligt med cron:
09 * * * /usr/local/bin/crawler_analysis.sh
Til dashboard-visualisering, brug Grafana til at oprette paneler, der viser crawlertrafik over tid, med separate visualiseringer for hver større crawler og alarmer konfigureret for afvigelser.
Kontrol af AI-crawleradgang
Kontrol af AI-crawleradgang starter med at forstå dine muligheder og hvilket kontrolniveau, du faktisk har brug for. Nogle hjemmesideejere ønsker at blokere alle AI-crawlere for at beskytte fortroligt indhold, mens andre byder trafikken velkommen, men ønsker at håndtere den ansvarligt. Dit første forsvar er robots.txt-filen, der giver crawlere instrukser om, hvad de må og ikke må tilgå. Sådan bruger du den:
Dog har robots.txt betydelige begrænsninger: det er kun en anbefaling, som crawlere kan ignorere, og ondsindede aktører vil slet ikke respektere den. For mere robust kontrol, implementér firewall-baseret blokering på serverniveau med iptables eller din cloud-udbyders sikkerhedsgrupper. Du kan blokere specifikke IP-ranges eller user-agent strings på webserverniveau med Apache’s mod_rewrite eller Nginx’s if statements. For praktisk implementering, kombiner robots.txt for legitime crawlere med firewallregler for dem, der ikke respekterer den, og overvåg dine logs for at fange overtrædelser.
Avancerede detektionsteknikker
Avancerede detektionsteknikker går videre end simpel user-agent matching for at identificere sofistikerede crawlere og endda forfalsket trafik. RFC 9421 HTTP Message Signatures giver en kryptografisk måde for crawlere at bevise deres identitet ved at signere deres forespørgsler med private nøgler, hvilket gør forfalskning næsten umulig. Nogle AI-virksomheder er begyndt at implementere Signature-Agent headers, der indeholder kryptografisk bevis på deres identitet. Udover signaturer kan du analysere adfærdsmønstre, der adskiller legitime crawlere fra bedragere: legitime crawlere udfører JavaScript konsekvent, følger forudsigelige crawl-hastigheder, respekterer ratelimits og bevarer konsistente IP-adresser. Rate limiting-analyse afslører mistænkelige mønstre—en crawler, der pludselig øger forespørgsler med 500% eller tilgår sider i tilfældig rækkefølge i stedet for at følge strukturen på sitet, er sandsynligvis ondsindet. Efterhånden som agentiske AI-browsere bliver mere avancerede, kan de udvise menneskelignende adfærd, inklusiv JavaScript-udførelse, cookie-håndtering og referrer-mønstre, hvilket kræver mere nuancerede detektionsmetoder, der ser på hele request-signaturen og ikke kun user-agent strings.
Overvågningsstrategi i praksis
En omfattende overvågningsstrategi for produktionsmiljøer kræver etablering af baselines, detektion af afvigelser og vedligeholdelse af detaljerede optegnelser. Start med at indsamle to ugers baseline-data for at forstå dine normale crawlertrafikmønstre, herunder spidsbelastningstider, typiske forespørgselsrater pr. crawler og båndbreddeforbrug. Opsæt anomalidetektion, der advarer dig, når en crawler overstiger 150% af sin baseline-rate, eller når nye crawlere dukker op. Konfigurer alarmgrænser såsom øjeblikkelig besked, hvis en enkelt crawler bruger mere end 30% af din båndbredde, eller hvis samlet crawlertrafik overstiger 50% af din samlede trafik. Spor rapporterings-metrics inklusiv samlede crawlerforespørgsler, forbrugt båndbredde, unikke crawlere detekteret og blokerede forespørgsler. For organisationer, der er bekymrede for brug af AI-træningsdata, tilbyder AmICited.com supplerende AI-citationssporing, der viser præcis, hvilke AI-modeller der citerer dit indhold, så du får indsigt i, hvordan dine data bruges videre. Implementér denne strategi med en kombination af serverlogs, firewallregler og analysetools for at opretholde fuldt overblik og kontrol over AI-crawleraktivitet.
Ofte stillede spørgsmål
Hvad er forskellen mellem AI-crawlere og søgemaskinecrawlere?
Søgemaskinecrawlere som Googlebot indekserer indhold til søgeresultater, mens AI-crawlere indsamler data til at træne store sprogmodeller eller drive AI-svarmotorer. AI-crawlere crawler ofte mere aggressivt og kan få adgang til indhold, som søgemaskiner ikke gør, hvilket gør dem til særlige trafikkilder, der kræver separat overvågning og håndtering.
Kan AI-crawlere forfalske deres user-agent strings?
Ja, user-agent strings er nemme at forfalske, da de blot er tekst-headere i HTTP-forespørgsler. Derfor er IP-verificering essentiel—legitime AI-crawlere kommer fra specifikke IP-ranges ejet af deres virksomheder, hvilket gør IP-baseret verificering langt mere pålidelig end blot user-agent matching.
Hvordan blokerer jeg specifikke AI-crawlere fra mit site?
Du kan bruge robots.txt til at foreslå blokering (selvom crawlere kan ignorere det), eller implementere firewall-baseret blokering på serverniveau med iptables, Apache mod_rewrite eller Nginx-regler. For maksimal kontrol, kombiner robots.txt for legitime crawlere med IP-baserede firewallregler for dem, der ikke respekterer robots.txt.
Hvorfor viser mine analysetools ikke AI-crawlertrafik?
Google Analytics 4, Matomo og lignende platforme er designet til at filtrere bottrafik fra, hvilket gør AI-crawlere usynlige i standard dashboards. Du skal bruge server-side løsninger som ELK Stack, Splunk eller Datadog for at fange rå logdata og se den fulde crawleraktivitet.
Hvilken indvirkning har AI-crawlere på serverbåndbredde?
AI-crawlere kan forbruge betydelig båndbredde—nogle sites rapporterer, at 30-50% af al trafik kommer fra crawlere. ChatGPT-User alene crawler med 2.400 sider/time, og med flere AI-crawlere aktive samtidigt kan båndbreddeomkostningerne stige markant uden ordentlig overvågning og kontrol.
Hvor ofte skal jeg overvåge mine serverlogs for AI-aktivitet?
Opsæt automatiseret daglig overvågning med cron-jobs for at analysere logs og generere rapporter. For kritiske applikationer, implementér realtidsovervågning, der straks giver besked, hvis en crawler overstiger baseline med 150% eller bruger mere end 30% af båndbredden.
Er IP-verificering nok til at autentificere AI-crawlere?
IP-verificering er langt mere pålidelig end user-agent matching, men det er ikke idiotsikkert—IP-spoofing er teknisk muligt. For maksimal sikkerhed, kombiner IP-verificering med RFC 9421 HTTP Message Signatures, som giver kryptografisk identitetsbevis, der næsten er umuligt at forfalske.
Hvad skal jeg gøre, hvis jeg opdager mistænkelig crawleraktivitet?
Verificér først IP-adressen mod officielle ranges fra den påståede virksomhed. Hvis den ikke matcher, så bloker IP'en på firewallniveau. Hvis den matcher, men adfærden virker unormal, implementér rate limiting eller midlertidig blokering af crawleren, mens du undersøger sagen. Bevar altid detaljerede logs til analyse og senere reference.
Følg hvordan AI-systemer refererer til dit indhold
AmICited overvåger, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews citerer dit brand og indhold. Få realtidsindsigt i din AI-synlighed og beskyt dine indholdsrettigheder.
Sådan identificerer du AI-crawlere i serverlogs: Komplet detektionsguide
Lær hvordan du identificerer og overvåger AI-crawlere som GPTBot, PerplexityBot og ClaudeBot i dine serverlogs. Opdag user-agent-strenge, IP-verificeringsmetode...
AI-crawler-adgangsrevision: Ser de rigtige bots dit indhold?
Lær at revidere AI-crawleres adgang til din hjemmeside. Find ud af, hvilke bots der kan se dit indhold og ret blokeringer, der forhindrer AI-synlighed i ChatGPT...
Spor AI-crawler-aktivitet: Komplet overvågningsguide
Lær hvordan du sporer og overvåger AI-crawler-aktivitet på din hjemmeside ved hjælp af serverlogs, værktøjer og bedste praksis. Identificer GPTBot, ClaudeBot og...
9 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.