
Sådan implementerer du LLMs.txt: En trin-for-trin teknisk guide
Lær hvordan du implementerer LLMs.txt på dit website for at hjælpe AI-systemer med bedre at forstå dit indhold. Komplet trin-for-trin guide til alle platforme, ...
9 min læsning

Kritisk analyse af LLMs.txt’s effektivitet. Find ud af, om denne AI-indholdsstandard er essentiel for dit site eller blot hype. Rigtige data om udbredelse, platformssupport og hvad der faktisk virker for AI-synlighed.
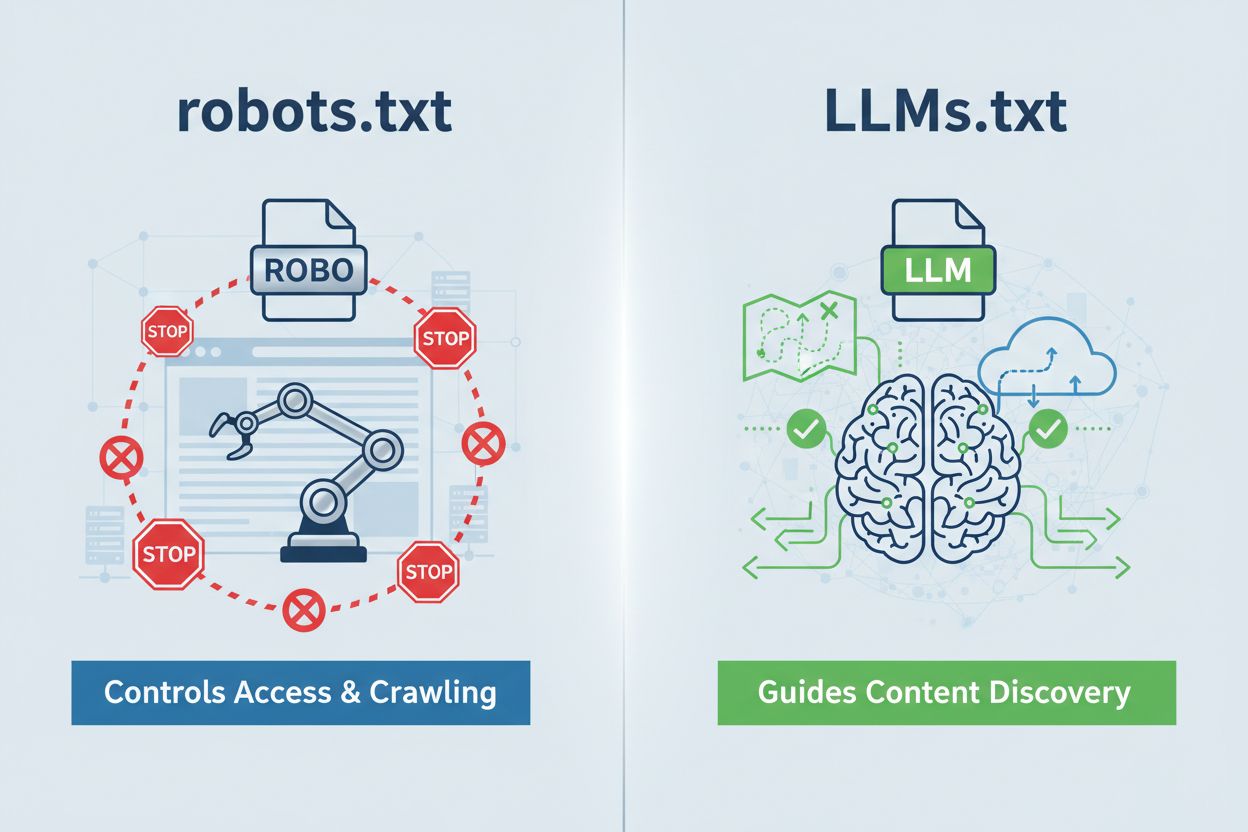
LLMs.txt er en almindelig tekstfil placeret på domain.com/llms.txt, som fungerer som en kurateret guide for AI-systemer til at opdage dit indhold af højest kvalitet. Det er grundlæggende anderledes end robots.txt—hvor robots.txt kontrollerer, om AI-crawlere kan tilgå dit site, virker LLMs.txt ved inferens-adgang, og hjælper AI-systemer med at forstå, hvilke sider der bør prioriteres, når de genererer svar. Tænk mindre på den som en trafikbetjent og mere som et skattekort: Den forhindrer ikke udforskning—den fremhæver blot, hvor den reelle værdi er gemt. Formatet er forfriskende simpelt—almindelig markdown uden kompleks syntaks—og dermed tilgængeligt for enhver organisation uanset teknisk niveau. Denne forskel er vigtig, fordi den ændrer hele samtalen: LLMs.txt handler ikke om at styre crawling; det handler om at optimere, hvordan AI-systemer fortolker og prioriterer dit AI-læselige indhold, når de allerede har fundet dig.
Tallene tyder på reel fremdrift: 844.000+ websites har implementeret LLMs.txt pr. oktober 2025, med udbredelsen koncentreret blandt virksomheder, der forstår AIs rolle i deres fremtid. Store spillere som Anthropic, Cloudflare, Stripe, Vercel og Supabase har alle implementeret standarden, hvilket signalerer, at seriøse infrastrukturvirksomheder ser værdi i eksperimentet. Mintlifys beslutning om automatisk at aktivere generering til tusindvis af dokumentationssites i november 2024 gav et markant spring i udbredelsen, hvilket viser, at værktøjsstøtte kan accelerere implementeringen. Tre fællesskabsdirektorier sporer nu implementeringer, med 788+ verificerede sites dokumenteret på tværs af dem. Dog afslører udbredelsesmønsteret noget vigtigt: implementeringen er stærkt koncentreret i udviklerværktøjer og dokumentationsplatforme—de sektorer, der mest sandsynligt får udbytte af AI-synlighed. Her er, hvordan landskabet egentlig ser ud:
| Virksomhed/Platform | Implementering | Token-antal | Status |
|---|---|---|---|
| Anthropic | Ja | ~2.000 | Aktiv |
| Cloudflare | Ja | ~5.000 | Aktiv |
| Stripe | Ja | ~8.000 | Aktiv |
| Vercel | Ja | ~3.500 | Aktiv |
| Supabase | Ja | ~4.200 | Aktiv |
| Mintlify (auto-genereret) | Ja | Varierer | Aktiv |
Her bliver skepsissen berettiget: INGEN større AI-platforme har officielt bekræftet brugen af LLMs.txt i deres retrieval-systemer. Googles John Mueller sagde direkte: “Intet AI-system bruger pt. llms.txt,” en kommentar der burde have afsluttet diskussionen, men som på en eller anden måde ikke gjorde det. OpenAI, Anthropic, Google, Microsoft og Perplexity har alle holdt strategisk tavshed—ingen officiel dokumentation, ingen bekræftet brug, ingen offentlige roadmaps. Der er tegn på, at nogle platforme crawler filerne (Microsoft- og OpenAI-bots er observeret hente LLMs.txt-filer), men crawling og reel brug er to helt forskellige ting. Den optimistiske tolkning antyder, at platforme tester stille og roligt før offentlig udmelding; den skeptiske antyder, at de aldrig adopterer det, fordi det ikke løser et reelt problem for dem. Denne tavshed er kernen i argumentet om, at det er “overvurderet”: 18 måneder efter forslaget fik momentum, har vi bred implementering men nul officiel platform-adoption. Det er ikke en standard—det er et håb.
Det skeptiske synspunkt bygger på en simpel grund: Der er intet bevis for, at LLMs.txt forbedrer AI-retrieval, øger trafik eller styrker indholdssynlighed. Tillidsproblemet går dybere—ved at skabe en separat fil, der kan indeholde andet indhold end på dine HTML-sider, muliggør man manipulation. Forskning i LLM-adfærd viser, at de er 2,5 gange mere tilbøjelige til at anbefale indhold, der specifikt fremhæves eller målrettes, hvilket skaber oplagte incitamenter til at “game” systemet. En organisation kunne i teorien udfylde LLMs.txt med sit bedst performende indhold, skjule svagere sider, eller værre, inkludere indhold i LLMs.txt, der ikke findes på sitet. SEO-værktøjsudbydere har øget presset ved at markere manglende LLMs.txt som optimeringsmulighed—Rank Math, SEMrush m.fl. har skabt en selvforstærkende cyklus, hvor sites implementerer standarden ikke fordi det virker, men fordi værktøjerne siger, de mangler noget. Dette er det reelle problem: 18 måneders implementeringspres uden et eneste dokumenteret tilfælde af målbar værdi. Det er det digitale svar på, at alle køber lodder, fordi lotteriet bliver promoveret.
LLMs.txt-tilhængerne argumenterer anderledes, med fokus på uundgåelig forandring snarere end nuværende bevis. Carolyn Shelby fra Yoast udtrykte det perfekt: “Placering er ikke længere gevinsten—inclusion er det.” Windsurf, en AI-kodeeditor, rapporterede at LLMs.txt sparer betydelig tid og tokens, når dokumentation parses, hvilket antyder reel effektivitet for AI-systemer, der faktisk bruger det. Anthropic bad specifikt Mintlify implementere LLMs.txt til deres dokumentation, hvilket antyder intern værdi, selv om de ikke offentligt bekræfter det. Google inkluderede LLMs.txt i deres A2A (Agents to Agents)-protokol, hvilket antyder, at virksomheden ser det som del af fremtidens AI-infrastruktur. Implementering tager 1-4 timer uden nogen påvist ulempe—du ødelægger intet, skader ikke SEO, du opretter blot en fil. Jeremy Howards iagttagelse rammer kernen i tilhængernes logik: “99,9% af opmærksomheden bliver snart LLM-opmærksomhed, ikke menneskelig opmærksomhed,” hvilket betyder, at optimering til AI-systemer ikke er valgfrit, men uundgåeligt. Springs Apps rapporterede en stigning på 20% i søgesynlighed efter implementering, dog er dette ubekræftet og kan skyldes sammenfald frem for årsag.
For at forstå hvorfor LLMs.txt kan fejle, skal man se på, hvorfor andre standarder lykkedes. Robots.txt lykkedes, fordi det skabte gensidig fordel med minimal omkostning og fik officiel RFC-understøttelse (RFC 9309)—søgemaskiner ville crawle effektivt, sites ville kontrollere crawling, og løsningen var så simpel, at adoption gik gnidningsløst. Schema.org lykkedes gennem udvikling på tværs af Google, Microsoft, Yahoo og Yandex fra starten—ingen enkelt virksomhed kunne tage ejerskab, hvilket skabte tillid. Sitemap.xml opnåede bred platformsstøtte før udbredt adoption, ikke efter. LLMs.txt mangler alle tre succesfaktorer: ingen W3C-involvering, intet konsortium, ingen officiel platformsstøtte og ingen dokumenteret værdi i trafik, rangering eller præcision. Det, der får standarder til at virke, er fælles opbakning, klare og målbare fordele og lav gaming-risiko. LLMs.txt har håb. Det har adoption blandt førstebrugere. Det har værktøjsstøtte. Men det mangler de grundlæggende elementer, der forvandlede tidligere standarder fra eksperimenter til infrastruktur.
Hvis LLMs.txt stadig er uprøvet, hvad rykker så reelt på AI-synlighed og AI-citater? Svaret er mindre eksotisk end et nyt filformat:
Disse taktikker virker, fordi de matcher den måde, AI-systemer faktisk behandler information på, ikke fordi de er optimeret til et bestemt filformat.

Diskussionen om LLMs.txt afspejler et dybere skifte i, hvordan indhold får succes online: sammenfaldet mellem menneskelig UX og AI-optimering. Forskning i Generative Engine Optimization (GEO) viser, at det indhold, der vinder i AI-genererede svar, har visse egenskaber—klarhed, struktur, autoritet og specificitet. Vercel rapporterede, at 10% af deres signups nu kommer direkte fra ChatGPT-henvisninger frem for traditionel organisk søgning—et tal, der ville have været utænkeligt for fem år siden. Succes handler i stigende grad om at blive nævnt i AI-genererede svar, ikke blot om at rangere i organiske resultater—det er forskellige optimeringsmål med forskellige krav. Værktøjslandskabet har udviklet sig til at spore dette skifte: SEMrush AIO, Profounds GEO-tracking og Ahrefs Brand Radar overvåger nu AI-synlighed sammen med traditionelle placeringer. Det grundlæggende perspektiv er dette: at blive citeret betyder mere end at blive rangeret, og at blive refereret betyder mere end at blive indekseret. Dette skifte forklarer, hvorfor LLMs.txt fik trækkraft trods manglende officiel støtte—det er et forsøg på at optimere til en ny opmærksomhedsøkonomi, hvor AI-systemer er den primære distributionskanal.
Hvis du vælger at implementere, så gør det rigtigt. Filen skal ligge på domain.com/llms.txt (bemærk: flertal, ikke ental), formateret som almindelig markdown, ikke XML eller JSON. Start med en H1-overskrift med dit sitenavn, evt. efterfulgt af et kort resumé af dit sites formål som blockquote. Organisér indholdet i H2-sektioner, hvis dit site har forskellige områder (dokumentation, blog, API-reference osv.), med beskrivelser af indholdet i hver sektion. Brug formatet [Titel](URL): Beskrivelse for enkelte sider, og hold beskrivelserne korte men informative. Hvad du bør inkludere: evergreen-indhold, velstrukturerede sider og indhold, der demonstrerer ægte ekspertise. Hvad du bør undgå: forsiden (ofte ikke værdifuld alene), alle URL’er på dit site (kvalitet over kvantitet) og sider, der ikke giver mening uden kontekst. Her er et grundlæggende eksempel:
# Firmanavn
> Kort beskrivelse af, hvad din virksomhed laver, og hvorfor AI-systemer bør interessere sig for dit indhold
## Dokumentation
[Kom godt i gang](https://example.com/docs/getting-started): Trin-for-trin guide for nye brugere
[API Reference](https://example.com/docs/api): Komplet API-dokumentation med eksempler
[Best Practices](https://example.com/docs/best-practices): Afprøvede mønstre til brug af vores platform
## Blog
[Derfor byggede vi dette](https://example.com/blog/why-we-built-this): Problemet vi løste og hvordan
Du kan eventuelt inkludere en sektion for URL’er, der skal springes over, hvis der er behov for kortere kontekst, men de fleste implementeringer kræver ikke dette detaljeringsniveau.
Ja, du bør implementere LLMs.txt. Ikke fordi det er bevist, at det virker, men fordi der er ingen ulempe og et reelt potentielt udbytte. Hvis AI-platforme aldrig officielt tager det i brug, ligger filen bare på din server uden skadelige effekter—ingen SEO-straf, intet trafik-tab, ingen ødelagt funktionalitet. Implementering tager ca. 10 minutter for et lille site og måske en time for større websteder. Samtidig fragmenteres trafikken på tværs af flere AI-systemer: ChatGPT, Perplexity, Claude og nye konkurrenter håndterer samlet hundredvis af millioner af forespørgsler hver måned. Du er allerede synlig for AI-systemer—LLMs.txt hjælper dem blot med at finde dit bedste indhold fremfor tilfældige sider. Selv hvis LLMs.txt aldrig bliver en officiel standard, træner du AI-systemer til bedre at forstå dit sites struktur og prioriteringer, hvilket har værdi uanset hvad. Den reelle indsigt er: sikr dig gratis. Implementer standarden, optimer dit indhold for AI-synlighed med dokumenterede metoder, og overvåg, hvad der faktisk driver trafik fra AI-systemer. Om 12 måneder har du rigtige data for, om LLMs.txt betyder noget for din virksomhed—og det er langt mere værdifuldt end spekulationer.
LLMs.txt er en almindelig tekstfil, der guider AI-systemer til dit bedste indhold for adgang under inferens, mens robots.txt styrer crawleradgang og indeksering. LLMs.txt begrænser intet—det kuraterer og fremhæver dine mest værdifulde sider for AI-forståelse. Tænk på robots.txt som en trafikbetjent og LLMs.txt som et skattekort.
Ikke officielt. På trods af at over 844.000 websites har implementeret det, har ingen større AI-platform bekræftet, at de bruger LLMs.txt til at generere svar. Der er nogle tegn på crawling fra OpenAI- og Microsoft-bots, men ingen bekræftet brug til inferens- eller referenceformål. Dette er kernen i argumentet om, at det er 'overvurderet'.
Ja. Implementering tager 10-30 minutter uden nogen ulemper. Hvis platforme vælger at bruge det, er du allerede klar. Hvis ikke, gør filen ingen skade. Det er en lavrisiko, potentiel gevinst for AI-synlighed. Du satser i bund og grund på fremtiden for AI-formidlet indholdsopdagelse.
Inkluder evergreen, velstruktureret indhold, der besvarer specifikke spørgsmål: guides, FAQs, API-dokumentation, pæleindhold og autoritative artikler. Undgå din forside, alle URL'er på dit site og sider, der ikke giver mening uden kontekst. Kvalitet frem for kvantitet er det vigtigste princip.
Ja, det er en reel bekymring. Du kan indsætte andet indhold i LLMs.txt end det, der faktisk vises på dine sider, hvilket underminerer tilliden. Derfor forbliver nogle eksperter skeptiske omkring standardens langsigtede levedygtighed, og platformenes adoption er forsigtig.
llms.txt indeholder kuraterede links til dine bedste sider med beskrivelser. llms-full.txt er en omfattende version med al din dokumentation samlet i én stor fil (nogle gange over 400.000 ord). Brug llms-full.txt, hvis du vil give AI-systemer alt fra start uden at de skal følge links.
LLMs.txt er et værktøj inden for den bredere GEO-strategi. GEO handler om at gøre dit indhold opdageligt og citerbart for AI-systemer gennem klar struktur, referencer, data og autoritativ ekspertise. LLMs.txt hjælper med at guide AI-systemer til dit bedst GEO-optimerede indhold.
Ja. Ethvert website har fordel af at hjælpe AI-systemer med at forstå og citere dit indhold. Blogs, lokale virksomheder, e-handelswebsites og nichefællesskaber får alle trafik fra AI-drevne søgninger. LLMs.txt er en enkel måde at forbedre din synlighed på tværs af ChatGPT, Claude, Perplexity og andre AI-platforme.
Følg med i, hvordan AI-systemer som ChatGPT, Claude og Perplexity refererer til dit indhold. Få indsigt i realtid om dine AI-citater og synlighed på tværs af AI-platforme.
Lær hvordan du implementerer LLMs.txt på dit website for at hjælpe AI-systemer med bedre at forstå dit indhold. Komplet trin-for-trin guide til alle platforme, ...

Lær hvad LLMs.txt-filer er, hvordan de adskiller sig fra robots.txt, og hvorfor de er essentielle for AI-synlighed og citationer i ChatGPT, Perplexity og Google...

Lær hvad LLMs.txt er, om det faktisk virker, og om du bør implementere det på dit website. Ærlig analyse af denne nye AI SEO-standard.
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.