Lær hvordan du implementerer noai og noimageai meta tags for at kontrollere AI-crawleres adgang til dit websteds indhold. Komplet guide til AI-adgangskontrol-headere og implementeringsmetoder.
Udgivet den Jan 3, 2026.Sidst ændret den Jan 3, 2026 kl. 3:24 am
Webcrawlere er automatiserede programmer, der systematisk gennemgår internettet og indsamler information fra hjemmesider. Historisk set blev disse bots primært drevet af søgemaskiner som Google, hvis Googlebot crawlede sider, indekserede indhold og sendte brugere tilbage til hjemmesider via søgeresultater—hvilket skabte et gensidigt fordelagtigt forhold. Fremkomsten af AI-crawlere har dog fundamentalt ændret denne dynamik. I modsætning til traditionelle søgemaskinebots, der leverer henvisningstrafik til gengæld for adgang til indhold, forbruger AI-træningscrawlere store mængder webindhold for at opbygge datasæt til store sprogmodeller og returnerer ofte minimal til ingen trafik tilbage til udgivere. Dette skift har gjort meta tags—små HTML-anvisninger, der kommunikerer instruktioner til crawlere—stadig vigtigere for indholdsskabere, der ønsker at bevare kontrol over, hvordan deres arbejde bruges af kunstig intelligens.
Hvad er NoAI og NoImageAI meta tags?
noai og noimageai meta tags er anvisninger, der blev oprettet af DeviantArt i 2022 for at hjælpe indholdsskabere med at forhindre, at deres arbejde bruges til at træne AI-billedgeneratorer. Disse tags fungerer på samme måde som den veletablerede noindex-anvisning, der fortæller søgemaskiner ikke at indeksere en side. noai-anvisningen signalerer, at intet indhold på siden bør bruges til AI-træning, mens noimageai specifikt forhindrer billeder i at blive brugt til AI-modeltræning. Du kan implementere disse tags i din HTML-head-sektion med følgende syntaks:
<!-- Bloker alt indhold fra AI-træning --><metaname="robots"content="noai">
<!-- Bloker kun billeder fra AI-træning --><metaname="robots"content="noimageai">
<!-- Bloker både indhold og billeder --><metaname="robots"content="noai, noimageai">
Her er en sammenligningstabel over forskellige meta tag-anvisninger og deres formål:
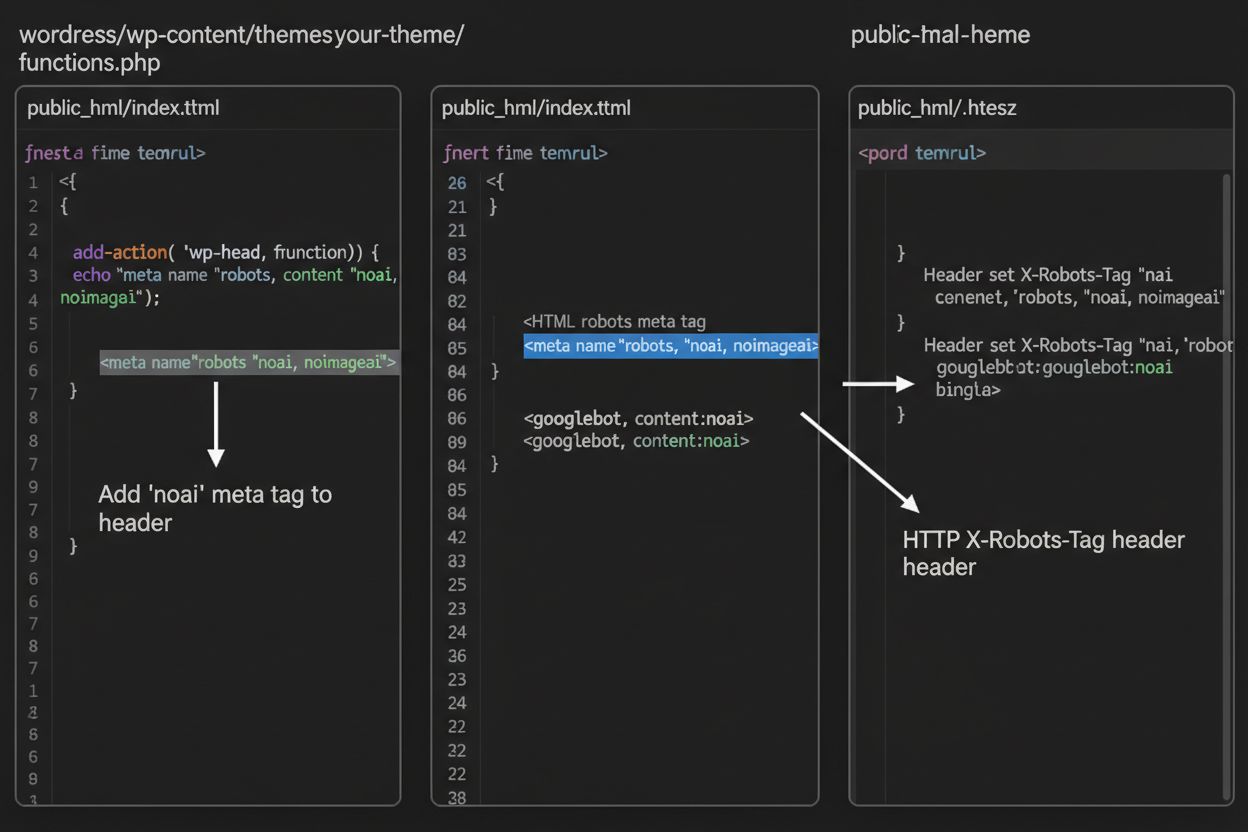
Mens meta tags placeres direkte i din HTML, giver HTTP-headere en alternativ metode til at kommunikere crawler-anvisninger på serverniveau. X-Robots-Tag-headeren kan inkludere de samme anvisninger som meta tags, men fungerer anderledes—den sendes i HTTP-svaret, før sideindholdet leveres. Denne tilgang er især værdifuld til at kontrollere adgang til ikke-HTML-filer som PDF’er, billeder og videoer, hvor du ikke kan indlejre HTML-meta tags.
For Apache-servere kan du sætte X-Robots-Tag-headere i din .htaccess-fil:
<IfModulemod_headers.c> Header set X-Robots-Tag "noai, noimageai"</IfModule>
For NGINX-servere skal du tilføje headeren i din serverkonfiguration:
Headere giver global beskyttelse på tværs af hele dit websted eller specifikke mapper, hvilket gør dem ideelle til omfattende AI-adgangskontrolstrategier.
Hvordan AI-crawlere respekterer (eller ignorerer) disse anvisninger
Effektiviteten af noai og noimageai tags afhænger fuldstændigt af, om crawlere vælger at respektere dem. Velfungerende crawlere fra større AI-virksomheder overholder generelt disse anvisninger:
Mindre/ukendte crawlere - Respekterer måske ikke anvisninger
Dog kan dårligt fungerende bots og ondsindede crawlere bevidst ignorere disse anvisninger, fordi der ikke er nogen håndhævelsesmekanisme. I modsætning til robots.txt, som søgemaskiner har aftalt at respektere som en industristandard, er noai ikke en officiel webstandard, hvilket betyder, at crawlere ikke har nogen forpligtelse til at overholde den. Derfor anbefaler sikkerhedseksperter en lagdelt tilgang, der kombinerer flere beskyttelsesmetoder i stedet for kun at stole på meta tags.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Implementeringsmetoder på forskellige platforme
Implementering af noai og noimageai tags varierer afhængigt af din webstedsplatform. Her er trin-for-trin-vejledninger til de mest almindelige platforme:
1. WordPress (via functions.php)
Tilføj denne kode til dit child themes functions.php-fil:
3. Squarespace
Gå til Indstillinger > Avanceret > Kodeindsprøjtning, og tilføj derefter til Header-sektionen:
<metaname="robots"content="noai, noimageai">
4. Wix
Gå til Indstillinger > Brugerdefineret kode, klik på “Tilføj brugerdefineret kode”, indsæt meta tagget, vælg “Head” og anvend på alle sider.
Hver platform tilbyder forskellige niveauer af kontrol—WordPress tillader sidespecifik implementering via plugins, mens Squarespace og Wix tilbyder globale site-wide muligheder. Vælg den metode, der passer bedst til dit tekniske komfortniveau og dine specifikke behov.
Begrænsninger og effektivitet af NoAI tags
Selvom noai og noimageai tags udgør et vigtigt skridt mod beskyttelse af indholdsskabere, har de betydelige begrænsninger. For det første er disse ikke officielle webstandarder—DeviantArt oprettede dem som et fællesskabsinitiativ, hvilket betyder, at der ikke er nogen formel specifikation eller håndhævelsesmekanisme. For det andet er overholdelse fuldstændig frivillig. Velfungerende crawlere fra store virksomheder respekterer disse anvisninger, men dårligt fungerende bots og scrapers kan ignorere dem uden konsekvens. For det tredje betyder manglen på standardisering, at udbredelsen varierer. Nogle mindre AI-virksomheder og forskningsorganisationer kender måske ikke engang til disse anvisninger, og slet ikke implementerer støtte for dem. Endelig kan meta tags alene ikke forhindre beslutsomme ondsindede aktører i at scrape dit indhold. En ondsindet crawler kan fuldstændigt ignorere dine anvisninger, hvilket gør yderligere beskyttelseslag afgørende for omfattende indholdssikkerhed.
Kombiner meta tags med robots.txt og andre metoder
Den mest effektive AI-adgangskontrolstrategi bruger flere beskyttelseslag i stedet for at stole på en enkelt metode. Her er en sammenligning af forskellige beskyttelsesmetoder:
Metode
Omfang
Effektivitet
Sværhedsgrad
Meta tags (noai)
Side-niveau
Medium (frivillig overholdelse)
Let
robots.txt
Site-wide
Medium (vejledende)
Let
X-Robots-Tag headere
Server-niveau
Medium-høj (dækker alle filtyper)
Medium
Firewall-regler
Netværksniveau
Høj (blokerer på infrastrukturniveau)
Svær
IP-allowlisting
Netværksniveau
Meget høj (kun verificerede kilder)
Svær
En omfattende strategi kan omfatte: (1) implementering af noai meta tags på alle sider, (2) tilføjelse af robots.txt-regler, der blokerer kendte AI-træningscrawlere, (3) opsætning af X-Robots-Tag-headere på serverniveau for ikke-HTML-filer, og (4) overvågning af serverlogs for at identificere crawlere, der ignorerer dine anvisninger. Denne lagdelte tilgang øger betydeligt sværhedsgraden for ondsindede aktører, samtidig med at den bevarer kompatibilitet med velfungerende crawlere, der respekterer dine præferencer.
Overvågning og verifikation af crawler-overholdelse
Efter implementering af noai-tags og andre anvisninger bør du verificere, at crawlere faktisk respekterer dine regler. Den mest direkte metode er at tjekke dine server access logs for crawleraktivitet. På Apache-servere kan du søge efter specifikke crawlere:
Hvis du ser anmodninger fra crawlere, du har blokeret, ignorerer de dine anvisninger. For NGINX-servere tjek /var/log/nginx/access.log med samme grep-kommando. Derudover giver værktøjer som Cloudflare Radar indsigt i AI-crawlertrafikmønstre på dit websted, så du kan se hvilke bots, der er mest aktive, og hvordan deres adfærd ændrer sig over tid. Regelmæssig logovervågning—mindst månedligt—hjælper dig med at identificere nye crawlere og verificere, at dine beskyttelsesforanstaltninger fungerer som tiltænkt.
Fremtiden for AI-adgangskontrolstandarder
I øjeblikket eksisterer noai og noimageai i et gråzoneområde: de er bredt anerkendt og respekteret af store AI-virksomheder, men de forbliver uofficielle og ikke-standardiserede. Der er dog voksende momentum mod formel standardisering. W3C (World Wide Web Consortium) og forskellige branchegrupper diskuterer, hvordan man kan skabe officielle standarder for AI-adgangskontrol, der ville give disse anvisninger samme vægt som etablerede standarder som robots.txt. Hvis noai bliver en officiel webstandard, vil overholdelse blive forventet brancheskik i stedet for frivillig, hvilket øger dens effektivitet betydeligt. Dette standardiseringsarbejde afspejler et bredere skift i, hvordan teknologibranchen ser på indholdsskaberes rettigheder og balancen mellem AI-udvikling og udgiverbeskyttelse. Efterhånden som flere udgivere tager disse tags i brug og kræver stærkere beskyttelse, øges sandsynligheden for officiel standardisering, hvilket potentielt vil gøre AI-adgangskontrol lige så grundlæggende for webstyring som regler for søgemaskineindeksering.
Ofte stillede spørgsmål
Hvad er noai meta tagget, og hvordan virker det?
Noai meta tagget er en anvisning placeret i dit websteds HTML-head-sektion, der signalerer til AI-crawlere, at dit indhold ikke bør bruges til at træne kunstige intelligensmodeller. Det fungerer ved at kommunikere dit ønske til velfungerende AI-bots, selvom det ikke er en officiel webstandard, og nogle crawlere kan ignorere det.
Er noai en officiel webstandard?
Nej, noai og noimageai er ikke officielle webstandarder. De blev skabt af DeviantArt som et fællesskabsinitiativ for at hjælpe indholdsskabere med at beskytte deres arbejde mod AI-træning. Dog er store AI-virksomheder som OpenAI, Anthropic og andre begyndt at respektere disse anvisninger i deres crawlere.
Hvilke AI-crawlere respekterer noai meta tagget?
Store AI-crawlere, herunder GPTBot (OpenAI), ClaudeBot (Anthropic), PerplexityBot (Perplexity), Amazonbot (Amazon) og andre respekterer noai-anvisningen. Dog kan nogle mindre eller dårligt fungerende crawlere ignorere det, hvilket er grunden til, at en lagdelt beskyttelsesstrategi anbefales.
Hvad er forskellen på meta tags og HTTP-headere til AI-kontrol?
Meta tags placeres i din HTML-head-sektion og gælder for individuelle sider, mens HTTP-headere (X-Robots-Tag) indstilles på serverniveau og kan gælde globalt eller for specifikke filtyper. Headere fungerer for ikke-HTML-filer som PDF'er og billeder, hvilket gør dem mere alsidige til omfattende beskyttelse.
Kan jeg implementere noai-tags på WordPress?
Ja, du kan implementere noai-tags på WordPress via flere metoder: ved at tilføje kode til dit temas functions.php-fil, bruge et plugin som WPCode eller via sidebygger-værktøjer som Divi og Elementor. Metoden med functions.php er mest almindelig og indebærer at tilføje et simpelt hook for at indsætte meta tagget i dit websteds header.
Bør jeg blokere alle AI-crawlere eller kun træningscrawlere?
Dette afhænger af dine forretningsmål. At blokere træningscrawlere beskytter dit indhold mod at blive brugt til AI-modeludvikling. Dog kan blokering af søgecrawlere som OAI-SearchBot reducere din synlighed i AI-drevne søgeresultater og opdagelsesplatforme. Mange udgivere bruger en selektiv tilgang, hvor træningscrawlere blokeres, mens søgecrawlere tillades.
Hvordan kan jeg verificere, at AI-crawlere respekterer mine noai-anvisninger?
Du kan tjekke dine serverlogs for crawler-aktivitet ved at bruge kommandoer som grep til at søge efter specifikke bot-user agents. Værktøjer som Cloudflare Radar giver indsigt i AI-crawlertrafikmønstre. Overvåg dine logs regelmæssigt for at se, om blokerede crawlere stadig får adgang til dit indhold, hvilket ville indikere, at de ignorerer dine anvisninger.
Hvad skal jeg gøre, hvis crawlere ignorerer mine noai meta tags?
Hvis crawlere ignorerer dine meta tags, skal du implementere yderligere beskyttelseslag, herunder robots.txt-regler, X-Robots-Tag HTTP-headere og serverniveau-blokering via .htaccess eller firewall-regler. For stærkere verifikation kan du bruge IP-allowlisting for kun at tillade anmodninger fra verificerede crawler-IP-adresser, som offentliggøres af store AI-virksomheder.
Overvåg hvordan AI refererer til dit brand
Brug AmICited til at spore, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews citerer og refererer til dit indhold på tværs af forskellige AI-platforme.
Hvad er noai meta-tagget, og hvordan beskytter det dit indhold mod AI?
Lær om noai meta-tagget, hvordan det fungerer for at forhindre AI-træningsdatakollektion, dets begrænsninger, og hvordan du implementerer det på din hjemmeside ...
Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...
Hvilke AI-crawlere bør jeg give adgang? Komplet guide til 2025
Lær hvilke AI-crawlere du skal tillade eller blokere i din robots.txt. Omfattende guide, der dækker GPTBot, ClaudeBot, PerplexityBot og 25+ AI-crawlere med konf...
10 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.