
Perplexity AI-optimering: Sådan bliver du citeret i realtidssøgning
Lær hvordan du optimerer dit indhold til Perplexity AI og bliver citeret i realtidssøgningsresultater. Opdag citeringsklare indholdsstrategier, teknisk optimeri...
5 min læsning

Lær hvordan du formaterer indhold for maksimal optagelse i Perplexity-citater. Bliv ekspert i citerbart indhold, schema markup og citatstrategier for at dominere AI-søgning.
Perplexity AI repræsenterer et grundlæggende skifte i, hvordan søgemaskiner præsenterer information, og bevæger sig væk fra den traditionelle linkbaserede rangeringsmodel, som Google har forfinet over to årtier. I modsætning til Googles PageRank-algoritme, der prioriterer domæneautoritet og backlink-profiler, fungerer Perplexity som en citat-fremad svarmotor, der sammensætter information fra flere kilder og præsenterer dem som nummererede citater i samtalebaserede svar. Denne forskel er afgørende for indholdsskabere, fordi det betyder, at dit indholds synlighed afhænger mindre af traditionelle SEO-målepunkter og mere af, om Perplexitys AI-modeller identificerer dit arbejde som autoritativt, citerbart og direkte relevant for brugerens forespørgsler. Platformens arkitektur behandler citater som den primære valuta for troværdighed, hvilket betyder, at velstruktureret og tydeligt kildesat indhold har eksponentielt større sandsynlighed for at blive udvalgt og vist for millioner af brugere. At forstå dette paradigmeskifte er det første skridt mod at optimere din indholdsstrategi til AI-drevet opdagelse.
Citerbart indhold adskiller sig grundlæggende fra indhold optimeret til traditionelle søgemaskiner og kræver en specifik strukturel og stilistisk tilgang, der gør udtrækning og tilskrivning problemfri for AI-systemer. Det mest citerbare indhold følger en svar-først metode, hvor den centrale indsigt, statistik eller konklusion fremgår med det samme, efterfulgt af dokumentation og kontekst i stedet for at være gemt væk i lange indledninger. Perplexitys citatalgoritme favoriserer indhold, der præsenterer information i adskilte, selvstændige enheder—tænk hvert afsnit eller sektion som et potentielt citat, der kan stå alene og stadig give mening for en læser, der møder det i et AI-genereret svar. Autoritative citater kræver tydelig tilskrivning af datakilder, ekspertkredentialer og udgivelsesdatoer, hvilket signalerer for AI, at dit indhold er troværdigt og verificerbart. Formateringen af dette indhold er enormt vigtig; indhold med korrekte overskriftshierarkier, definitionslister og strukturerede data bliver betydeligt oftere korrekt udtrukket og udvalgt til citat. Desuden klarer indhold, der direkte besvarer specifikke spørgsmål frem for at udforske sideemner, sig bedre, da Perplexitys modeller er trænet til at matche brugerens hensigt med præcise, relevante svar.
| Aspect | Citerbart indhold | Ikke-citerbart indhold |
|---|---|---|
| Struktur | Svar-først med dokumentation | Lange indledninger før hovedpointe |
| Tydelighed | Én klar påstand pr. sektion | Flere konkurrerende idéer pr. afsnit |
| Kildesætning | Eksplicitte kildeangivelser og datoer | Vage referencer eller ingen kilder |
| Formatering | Semantisk HTML, korrekte overskrifter, lister | Ren tekst med minimal markup |
| Specificitet | Konkrete data, statistikker, definitioner | Generelle observationer og meninger |
| Længde | Korte, citerbare afsnit (2-4 sætninger) | Tætte afsnit, der kræver kontekst |
| Verificerbarhed | Linkede kilder og ekspertkredentialer | Uverificerede påstande og anonyme forfattere |
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Det tekniske fundament for citerbart indhold starter med HTML-først design, hvor semantisk markup ikke er valgfrit, men essentielt for, at AI-systemer korrekt kan udtrække information. Perplexitys crawlers prioriterer indhold bygget med semantiske HTML5-elementer som <article>, <section>, <header> og <footer> frem for generiske <div>-containere, da disse tags giver tydelig mening om indholdets struktur, som maskinlæringsmodeller kan udnytte. Dit overskriftshierarki skal være logisk og ubrudt—start med H1 til hovedemnet, brug H2 til hovedsektioner og H3 til undersektioner—fordi AI-systemer bruger denne struktur til at forstå indholdsrelationer og udtrække relevante afsnit. Schema markup, især JSON-LD-implementeringer, giver yderligere kontekst, der hjælper Perplexity med at forstå dit indholds formål, autoritet og relevans uden udelukkende at skulle stole på naturlig sprogforståelse.
<article>, <section>, <aside>, <nav>) i stedet for generiske divs<dl>, <dt>, <dd>) til terminologi og begrebsforklaringer<thead>, <tbody> og <th> elementer til strukturerede dataOpbygning af citatautoritet kræver en bevidst strategi, der skelner mellem primære og sekundære kilder, mens du etablerer dit indhold som et pålideligt samlingspunkt for information. Primære kilder—original forskning, officielle statistikker, peer-reviewede studier og førstehåndsberetninger—vejer tungest i Perplexitys citatalgoritme, da de repræsenterer den oprindelige sandhedskilde frem for afledt kommentar. Sekundære kilder, herunder anerkendte nyhedsmedier, brancheanalyser og ekspertkommentarer, giver værdifuld kontekst og fortolkning, men bør bruges til at understøtte, ikke erstatte, primære citater. Den mest effektive citatstrategi indebærer at oprette en konsolideret referenceliste sidst i dit indhold, hvor alle kilder listes med direkte links, udgivelsesdatoer og forfatterkredentialer, så det er let for Perplexitys systemer at verificere dine påstande og udtrække citater. Denne tilgang opbygger også det forskere kalder “citatautoritet”—jo flere autoritative kilder, der citerer dit arbejde, desto mere anerkender Perplexity dig som en troværdig node i vidensgrafen.
[1], der matcher din referenceliste, i stil med akademiske standarderGet the latest insights on AI mentions, brand monitoring, and optimization strategies.
Den optimale sideopbygning for Perplexity-citatoptagelse følger en specifik struktur, der maksimerer sandsynligheden for udtræk og tilskrivning. Begynd med en definitionsboks eller et resumeafsnit umiddelbart efter din H1-overskrift, der giver et kort svar på det primære spørgsmål, dit indhold adresserer—dette er ofte det første, Perplexity udtrækker til sine svar. Følg op med en logisk opdeling i H2-sektioner, der hver dækker et bestemt aspekt af emnet, med H3-undersektioner for detaljer og dokumentation. Mini-tabeller og sammenligningsmatricer spredt ud over dit indhold tjener to formål: de giver let udtrækkelige strukturerede data til Perplexity og forbedrer læsbarheden for menneskelige besøgende. Inkluder en omfattende referenceliste til sidst, der oplister hver kilde med fuld citat, udgivelsesdato og direkte link, da dette signalerer fuldstændighed og autoritet til både AI-systemer og mennesker. Vedligehold desuden en changelog eller ‘Sidst opdateret’-sektion, der dokumenterer, hvornår indholdet senest blev gennemgået og hvilke ændringer, der er foretaget, da Perplexitys algoritmer foretrækker frisk, aktivt vedligeholdt indhold frem for forældede informationer.
Topic clusters er et kritisk, men ofte overset element i Perplexity-optimering, da de hjælper AI-systemer med at forstå de semantiske relationer mellem dine indholdsstykker og etablere dig som autoritet på et videnområde. I stedet for at skabe isolerede artikler indebærer succesfulde Perplexity-optimerede indholdsstrategier at bygge sammenkædede klynger af relateret indhold, hvor en pilleartikel dækker et bredt emne, og satellitartikler udforsker specifikke underemner, alle forbundet gennem strategisk intern linking. Disse klynger spejler, hvordan vidensgrafer er struktureret—som sammenkædede noder af beslægtet information—hvilket passer perfekt til, hvordan Perplexitys AI-modeller forstår og henter information. Når Perplexity støder på din pilleartikel, kan den følge interne links for at opdage dit satellitindhold, hvilket øger chancen for, at flere af dine sider citeres i svar på relaterede forespørgsler. Den interne linking-strategi bør være bevidst og semantisk; brug beskrivende ankertekst, der indeholder relevante søgeord og begreber, så Perplexity forstår relationen mellem de sammenkædede sider. Denne tilgang forvandler dit website fra en samling af isolerede artikler til en sammenhængende vidensbase, som Perplexity anerkender som autoritativ på hele emneområdet.
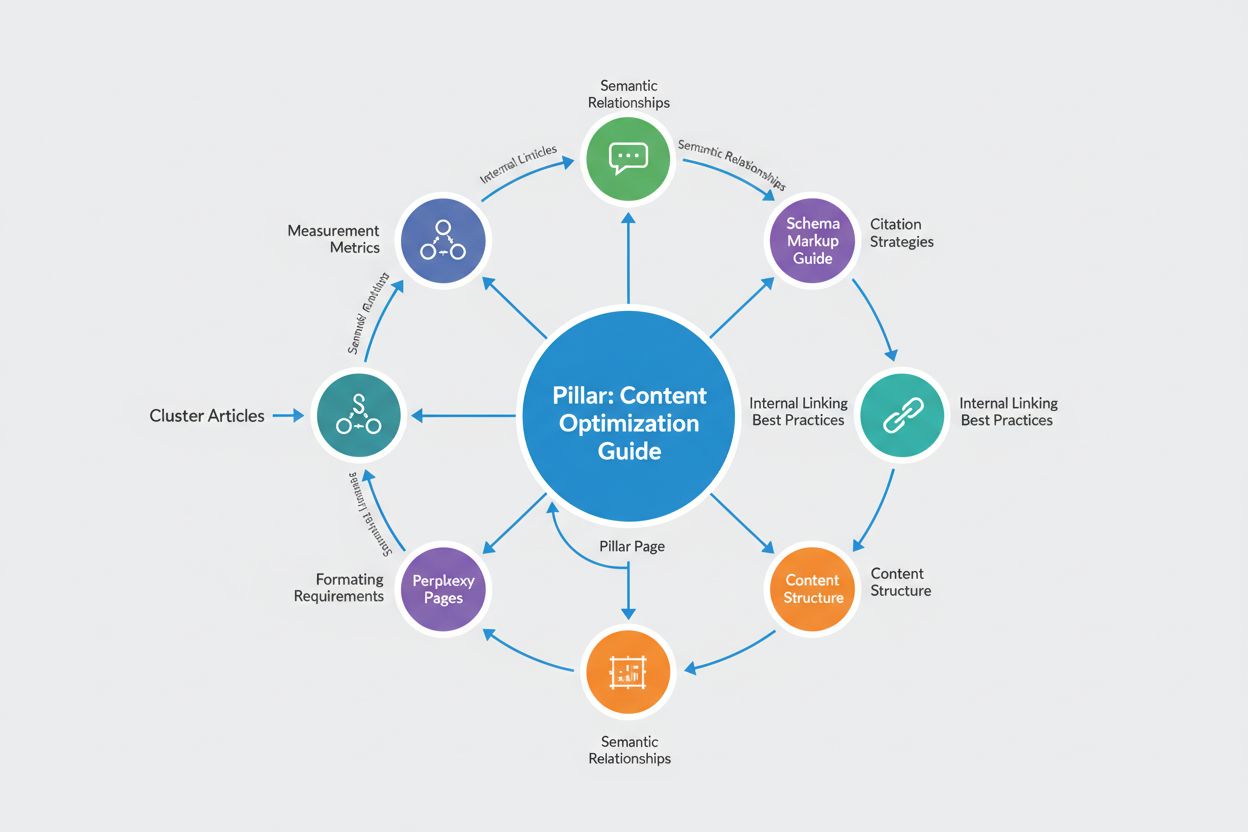
Implementering af JSON-LD schema markup er ikke længere blot en valgfri optimering, men et fundamentalt krav for maksimal Perplexity-citatoptagelse, da det giver maskinlæsbar kontekst, der eliminerer tvetydighed i fortolkningen. De mest effektive implementeringer anvender flere schema-typer i kombination: Article schema til grundlæggende metadata, FAQPage schema til Q&A-indhold, BreadcrumbList for navigationshierarki og domænespecifikke schemas som ScholarlyArticle til forskningsbaseret indhold. Fordelen ved JSON-LD frem for andre schema-formater er, at det indlejres i en <script>-tag separat fra dit HTML-indhold, hvilket gør det lettere at vedligeholde og mindre tilbøjeligt til at give gengivelsesproblemer. Her er et praktisk eksempel på implementering af Article schema:
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "Perplexitys citatstil: Sådan formaterer du indhold for maksimal optagelse",
"description": "En omfattende guide til optimering af indhold til Perplexity AIs citat-fremad model",
"author": {
"@type": "Person",
"name": "Dit Navn",
"url": "https://dinside.dk/om"
},
"datePublished": "2024-01-15T10:00:00Z",
"dateModified": "2024-01-20T14:30:00Z",
"mainEntity": {
"@type": "Thing",
"name": "Perplexity Citatoptimering"
}
}
Ud over grundlæggende Article schema, implementer FAQPage schema til alt indhold med Q&A-sektioner, da Perplexity ofte udtrækker FAQ-indhold til sine svar. Inkluder author, datePublished og dateModified felter i al schema markup, da disse hjælper Perplexity med at vurdere indholdets autoritet og aktualitet. Brug også sameAs egenskaber til at linke din forfatterprofil til verificerede kredentialer (LinkedIn, Twitter, professionelle websites), hvilket styrker de troværdighedssignaler, Perplexity bruger til at vurdere kilde-pålidelighed.
Perplexity Pages repræsenterer en direkte integrationsmulighed, som indholdsskabere aktivt bør forfølge, da de giver dig mulighed for at kuratere og præsentere dit indhold direkte i Perplexitys interface, mens du bevarer redaktionel kontrol og får direkte tilskrivning. At oprette en Perplexity Page indebærer at indsende en samling af dit bedste indhold om et specifikt emne, som Perplexity derefter organiserer og præsenterer som en kurateret vidensressource, brugere kan få direkte adgang til. Denne tilgang giver flere fordele: dit indhold får fremtrædende placering, du bevarer kontrol over præsentationen af dit arbejde, og du opbygger en direkte relation til Perplexitys brugerbase. Nøglen til succesfulde Perplexity Pages er kildekonsolidering—udvælg dine 5-10 mest autoritative, velstrukturerede stykker om et emne, og sørg for, at de er korrekt linket og krydsrefereret.
Mange indholdsskabere saboterer uforvarende deres Perplexity-citatpotentiale gennem undgåelige formaterings- og strukturfejl, der gør deres indhold svært for AI-systemer at udtrække og parse. Multi-intent sider, der forsøger at besvare flere urelaterede spørgsmål på én side, forvirrer Perplexitys algoritmer, som forventer klart, fokuseret indhold med ét primært formål; opret i stedet separate, fokuserede artikler for hvert særskilt emne. JavaScript-gated indhold—information, der kun indlæses efter JavaScript-eksekvering—er stort set usynligt for Perplexitys crawlers, så undgå at gemme nøgleinformation bag interaktive elementer eller dynamisk indholdsindlæsning. Vagt, tøvende sprog som “måske”, “kan”, “muligvis” og “nogle eksperter mener” svækker citatautoritet; brug i stedet definitive udsagn bakket op af specifikke kilder. Tynde eller manglende referencer er måske den mest almindelige fejl; enhver faktuel påstand bør kunne spores til en kilde, og din referenceliste bør være omfattende og detaljeret. Endelig ustabile eller ofte ændrede URL-slugs ødelægger Perplexitys evne til at opretholde konsistente citater, så fastlæg din URL-struktur omhyggeligt og undgå unødvendig reorganisering.
At spore din citatperformance kræver overvågning af målepunkter, der adskiller sig markant fra traditionelle SEO-analyser, med fokus på hvor ofte Perplexity vælger dit indhold til sine svar frem for organiske klikfrekvenser. Citatfrekvens er din primære metrik—overvåg hvor ofte dit indhold optræder i Perplexity-svar ved at foretage regelmæssige søgninger på dine målsøgeord og bemærke, hvilke af dine sider der citeres. Værktøjer som Perplexitys eget analyse-dashboard (hvis du har oprettet en Perplexity Page) giver direkte indsigt i citattællinger, men du kan også manuelt spore citater ved at søge på dit domæne i Perplexity og analysere, hvilke sider der hyppigst optræder. AI-drevet trafik fra Perplexity og lignende AI-svarmotorer udgør en stigende andel af den samlede søgetrafik, hvilket gør det essentielt at spore henvisningskilder særskilt og forstå, hvilke indholdsstykker der driver flest AI-besøg. Optimer løbende ved at analysere, hvilke af dine citerede stykker der har stærkest formatering, klareste citater og mest autoritative kilder, og anvend de mønstre på underpræsterende indhold. Overvåg desuden, hvordan dit indhold klarer sig i forhold til konkurrenterne i Perplexity-svar—hvis konkurrenternes indhold citeres oftere, analyser deres formatering, struktur og citatstrategier for at identificere forbedringsmuligheder.
Følg med i, hvordan AI-systemer som Perplexity citerer dit indhold med AmICited – den eneste platform, der overvåger dit brand på tværs af GPT'er, Perplexity og Google AI Overviews.
Lær hvordan du optimerer dit indhold til Perplexity AI og bliver citeret i realtidssøgningsresultater. Opdag citeringsklare indholdsstrategier, teknisk optimeri...

Lær hvordan du får din hjemmeside citeret af Perplexity AI. Opdag de tekniske krav, strategier for indholdsoptimering og autoritetsopbyggende tiltag, der hjælpe...
Lær hvordan citationsposition fungerer på tværs af ChatGPT, Perplexity, Google AI Overviews og andre AI-systemer. Forstå strategier for citatplacering, og hvord...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.