
Reddit-trådoptimering
Lær Reddit-trådoptimeringsstrategier for at øge AI-synlighed på ChatGPT, Perplexity og Google AI Overviews. Opdag hvordan du skaber citeringsværdigt indhold og ...
9 min læsning

Opdag hvordan Stack Overflow-indhold former AI-svar, og lær strategier til at maksimere din udviklersynlighed i ChatGPT, Gemini og andre AI-platforme.
Stack Overflows 50 millioner spørgsmål og svar er blevet en hjørnesten i udviklingen af store sprogmodeller. Store AI-virksomheder, herunder OpenAI, Google og Meta, har inkorporeret Stack Overflow-data i deres træningsdatasæt, fordi udviklernes viden repræsenterer noget af det mest kvalitetsrige og peer-reviewede tekniske indhold, der findes på internettet. Udviklingen af avancerede AI-systemer koster hundredvis af millioner af dollars, og en stor del af denne udgift går til anskaffelse og behandling af træningsdata. Historisk set har AI-virksomheder hentet disse data gratis, men Stack Overflows CEO Prashanth Chandrasekar annoncerede i 2023, at platformen ville begynde at opkræve betaling fra store AI-udviklere for adgang til indholdet, idet han anerkendte, at viden genereret af fællesskabet bør kompenseres. Dette skifte afspejler en bredere bevægelse i branchen, hvor platforme med værdifulde data kræver rimelig kompensation fra virksomheder, der tjener penge på deres indhold.
Stack Overflow-indhold er licenseret under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), hvilket juridisk kræver, at enhver der bruger indholdet, giver attribution til de oprindelige forfattere. Denne licensramme er ikke til forhandling for Stack Overflow, da platformen mener, at attribution er fundamentet for udviklernes tillid til AI-genereret indhold. Når AI-virksomheder træner modeller på Stack Overflow-data uden korrekt attribution, overtræder de teknisk set Creative Commons-licensen, og derfor kræver Stack Overflow nu, at alle API-partnere inkluderer krav om attribution i deres kontrakter. Betydningen af dette kan ikke overvurderes: Ifølge Stack Overflows Developer Survey 2024 nævner 65% af udviklerne manglende eller forkert attribution som en af de største etiske bekymringer ved AI-værktøjer.
| Aspect | Requirement | Impact |
|---|---|---|
| License Type | CC BY-SA 4.0 | Attribution obligatorisk |
| Developer Trust | 72% positivt | Kritisk for adoption |
| AI Compliance | RAG-implementering | Sikrer korrekt kildeangivelse |
| Citation Rate | 65% bekymring | Største etiske problem |
| Content Ownership | Bruger-beholdt | Fællesskabsbeskyttelse |
Stack Overflows tilgang til AI-licensering skelner mellem gratis og kommercielle brugsscenarier. Platformen tilbyder fortsat gratis adgang til sin API og data dumps til ikke-kommercielle formål, undervisningsbrug og open source-projekter, hvilket fastholder dens engagement i udviklerfællesskabet. Virksomheder, der udvikler store sprogmodeller til kommercielt brug, skal dog forhandle licensaftaler med Stack Overflow, hvor prisen baseres på faktorer som modellens størrelse, brugsmængde og genererede indtægter. Stack Overflows CEO Chandrasekar understregede, at virksomheden kun søger kompensation fra organisationer, der udvikler LLM’er til “store, kommercielle formål”, ikke fra individuelle udviklere eller små projekter. Denne dobbeltlicensmodel gør det muligt for Stack Overflow at skabe nye indtægtskilder, samtidig med at fællesskabsmedlemmernes interesser beskyttes — mange bidrager med indhold uden forventning om direkte betaling. Virksomheden har også forpligtet sig til at geninvestere licensindtægterne i fællesskabsværktøjer og funktioner, hvilket skaber en bæredygtig model, hvor udviklerbidrag direkte finansierer forbedringer af platformen.
Stack Overflow-indhold optræder nu fremtrædende i AI-genererede svar på tværs af store platforme som ChatGPT, Google Gemini, Perplexity og Microsoft Copilot. Googles Gemini Cloud Assist angiver eksplicit Stack Overflow-svar, når der gives kodningsløsninger, og viser det oprindelige spørgsmål, svar og forfatteroplysninger direkte i AI-svaret. OpenAIs ChatGPT viser Stack Overflow-links i samtaler om kodningsrelaterede emner, og SearchGPT—OpenAIs søgeprototype—inkluderer Stack Overflow-resultater i både samtalerespons og søgeresultatlister. Denne synlighed er afgørende for udviklere, fordi det driver trafik tilbage til deres svar og etablerer dem som anerkendte eksperter på deres felt. Ikke alle AI-platforme giver dog lige god attribution, og udviklere kæmper ofte med at forstå, hvilke af deres svar der bliver citeret, hvor ofte og i hvilken sammenhæng på tværs af forskellige AI-systemer.
Stack Overflows Developer Survey 2024 afslører en voksende kløft mellem AI-adoption og tillid: Selvom 76% af udviklerne bruger eller planlægger at bruge AI-værktøjer (op fra 70% i 2023), er AI’s popularitetsvurdering faldet fra 77% til 72%. Kun 43% af udviklerne stoler på nøjagtigheden af AI-værktøjer, og undersøgelsen identificerede tre kritiske etiske bekymringer, som udviklere prioriterer:
Denne tillidskløft påvirker direkte, hvordan AI-virksomheder tilgår datasourcing og modeltræning. Udviklere kræver i stigende grad, at AI-systemer citerer deres kilder, anerkender fællesskabsbidrag og opretholder nøjagtighedsstandarder, der afspejler Stack Overflows peer-reviewede indhold. Presset for at bygge troværdige AI-systemer har skabt et akut fokus på dataindkøb, hvor høj kvalitet er i højsædet, og Stack Overflows verificerede, fællesskabsudvalgte viden er mere værdifuld end nogensinde.
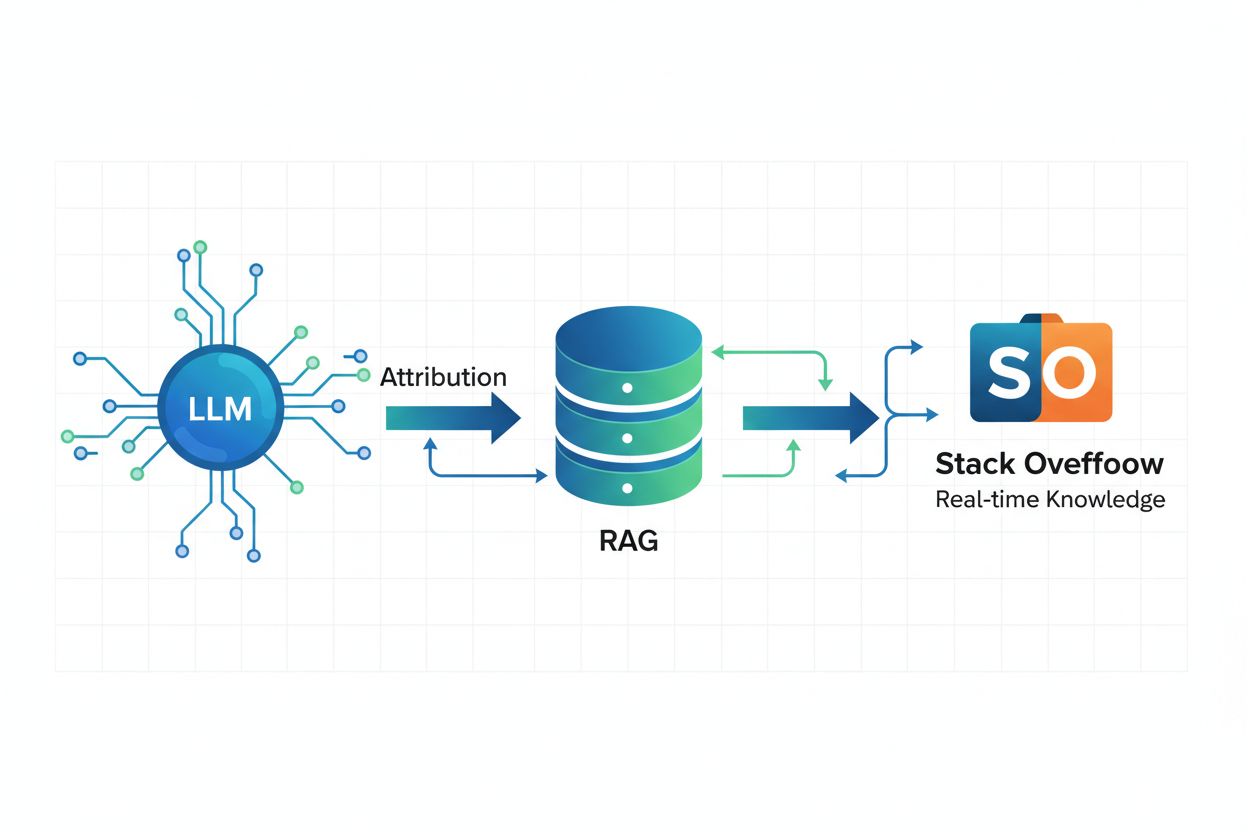
Retrieval Augmented Generation (RAG) er en AI-ramme, der kombinerer store sprogmodeller med traditionelle informationssøgningsteknologier for at levere aktuelle, nøjagtige og korrekt tilskrevne svar. I stedet for udelukkende at stole på træningsdata, der er frosset på et bestemt tidspunkt, gør RAG det muligt for AI-systemer at hente realtidsinformation fra eksterne kilder som Stack Overflow, så svarene afspejler den nyeste viden og bedste praksis. Alle Stack Overflows OverflowAPI-partnere har implementeret RAG for at muliggøre korrekt attribution, hvilket betyder, at når et AI-system genererer et svar ved hjælp af Stack Overflow-indhold, kan det identificere og citere de specifikke opslag, der har påvirket svaret. Denne teknologi er særligt stærk for domænespecifik viden, hvor nøjagtighed og aktualitet tæller — for eksempel sikrer man ved at få et AI-system til at skrive C#-kode baseret på eksempler fra din egen kodebase, at den genererede kode følger dit teams standarder og konventioner. RAG mindsker risikoen for fejlinformation ved at forankre AI-svar i troværdige, verificerede fakta, som brugerne udtrykkeligt identificerer, og gør det til det tekniske fundament for ansvarlig AI-udvikling.
Udviklere, der bidrager til Stack Overflow, bør aktivt overvåge, hvordan deres indhold optræder i AI-genererede svar på tværs af forskellige platforme. Værktøjer som AmICited.com, XFunnel, Profound og andre tilbyder nu synlighedssporing, der specifikt viser udviklere, hvor deres svar bliver citeret, hvor ofte og i hvilken sammenhæng på tværs af ChatGPT, Gemini, Perplexity og andre AI-systemer. Nøglemålepunkter inkluderer citationsfrekvens (hvor ofte dit indhold refereres), tone (om omtalen er positiv eller neutral), platformsfordeling (hvilke AI-systemer der citerer dig mest) og kildeattribution (om korrekt kredit gives). Ved at overvåge disse målepunkter kan udviklere identificere, hvilke af deres svar der giver mest værdi til AI-systemer, forstå hvilke emner der er mest efterspurgte og justere deres bidragsstrategi derefter. Desuden hjælper synlighedssporing udviklere med at opdage ukorrekte eller ufuldstændige citater, så de kan opdatere deres originale svar eller kontakte AI-virksomheder for at anmode om rettelser. Denne proaktive tilgang gør passiv indholdslevering til en aktiv strategi for at opbygge autoritet og indflydelse i det AI-drevne informationsøkosystem.
For at maksimere synlighed i AI-søgeresultater og sikre, at dine Stack Overflow-bidrag bliver korrekt citeret, bør du fokusere på at lave omfattende, veldokumenterede svar, der adresserer hele spørgsmålet med klare forklaringer og fungerende kodeeksempler. Hold dine svar ajour ved jævnligt at gennemgå og opdatere dem, efterhånden som teknologier udvikler sig, da AI-systemer prioriterer nyere indhold — gennemsnitligt er indhold citeret i AI-resultater 25,7% nyere end det, der rangerer i Google. Opbyg autoritet ved konsekvent at levere svar af høj kvalitet på tværs af flere relaterede emner, da udviklere i top 25% for webomtale får 10 gange flere AI-citater end andre. Engager dig i det bredere udviklerfællesskab ved at deltage i diskussioner, besvare opfølgende spørgsmål og hjælpe andre medlemmer med at forbedre deres bidrag. Overvej endelig, hvordan dine svar kan blive brugt af AI-systemer: strukturer dine svar med klare overskrifter, inkluder relevante kodeudsnit, og giv kontekst for, hvornår og hvorfor bestemte tilgange er relevante — det gør dit indhold mere brugbart for både menneskelige læsere og AI-systemer, der skal udtrække og tilskrive information korrekt.
Stack Overflow's 50 millioner spørgsmål og svar bliver inkorporeret i store sprogmodeller, fordi de repræsenterer teknisk indhold af høj kvalitet og peer-reviewet. AI-virksomheder som OpenAI, Google og Meta bruger disse data til at træne deres modeller, så de bedre kan forstå og generere kode og tekniske løsninger. Historisk set blev disse data skrabet gratis, men Stack Overflow kræver nu, at kommercielle AI-udviklere licenserer dataene gennem betalte aftaler.
Stack Overflow tilbyder gratis API-adgang til ikke-kommercielle formål, undervisningsbrug og open source-projekter. Virksomheder, der udvikler store sprogmodeller til kommerciel brug, skal dog forhandle betalte licensaftaler. Prissætningen afhænger af faktorer som modellens størrelse, brugsmængde og genererede indtægter, hvilket sikrer at fællesskabets bidrag bliver behørigt kompenseret.
Lav omfattende, veldokumenterede svar med klare forklaringer og fungerende kodeeksempler. Hold dine svar opdaterede, efterhånden som teknologier udvikler sig, da AI-systemer prioriterer nyere indhold. Opbyg autoritet ved konsekvent at levere svar af høj kvalitet på tværs af flere emner, og strukturer dine svar med klare overskrifter og relevante kodeudsnit, som AI-systemer nemt kan udtrække og tilskrive.
Retrieval Augmented Generation (RAG) er en AI-ramme, der kombinerer sprogmodeller med informationssøgning for at give aktuelle, nøjagtige og korrekt tilskrevne svar. RAG gør det muligt for AI-systemer at hente realtidsinformation fra kilder som Stack Overflow og citere de specifikke opslag, der har påvirket svaret, hvilket sikrer korrekt attribution og reducerer risikoen for fejlinformation.
Værktøjer som AmICited.com, XFunnel, Profound og andre tilbyder synlighedssporing, der er specifikt designet til at vise udviklere, hvor deres svar bliver citeret på tværs af ChatGPT, Gemini, Perplexity og andre AI-systemer. Disse værktøjer sporer citationsfrekvens, tone, platformsfordeling og kildeattribution, så du kan forstå, hvilke af dine svar der giver mest værdi til AI-systemer.
Ifølge Stack Overflows Developer Survey 2024 har udviklere tre primære etiske bekymringer: risiko for fejlinformation (79% bekymrede), manglende eller forkert attribution (65% bekymrede) og bias, der ikke repræsenterer forskellige synspunkter (50% bekymrede). Disse bekymringer driver behovet for korrekt licensering, krav om attribution og træningsdata af høj kvalitet fra verificerede kilder som Stack Overflow.
Stack Overflow-indhold er licenseret under Creative Commons Attribution-ShareAlike 4.0 (CC BY-SA), hvilket juridisk kræver, at enhver der bruger indholdet, giver attribution til de oprindelige forfattere. Stack Overflow kræver nu, at alle API-partnere inkluderer krav om attribution i deres kontrakter, så udviklere får korrekt kredit, når deres svar bruges af AI-systemer.
Der findes flere værktøjer til at spore AI-citater, herunder AmICited.com (specialiseret i AI-overvågning), XFunnel (enterprise LLM-overvågning), Profound (avanceret GEO-tracking), Semrush AI Toolkit, BrightEdge og andre. Disse værktøjer hjælper dig med at spore, hvilke AI-platforme der citerer dig, hvor ofte, i hvilken sammenhæng, og om korrekt attribution er givet.
Følg med i, hvordan din tekniske ekspertise bliver citeret på tværs af ChatGPT, Gemini, Perplexity og andre AI-platforme. Få indsigt i realtid i din udviklersynlighed og optimer din tilstedeværelse i fællesskabet.
Lær Reddit-trådoptimeringsstrategier for at øge AI-synlighed på ChatGPT, Perplexity og Google AI Overviews. Opdag hvordan du skaber citeringsværdigt indhold og ...
Opdag hvorfor Reddit dominerer ChatGPT-citater med 40,1% af alle AI-svar. Lær hvordan AI's kildepræferencer fungerer og hvad det betyder for din virksomheds syn...

Opdag hvordan Wikipedia fungerer som et kritisk AI-træningsdatasæt, dets indflydelse på modelnøjagtighed, licensaftaler, og hvorfor AI-virksomheder er afhængige...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.