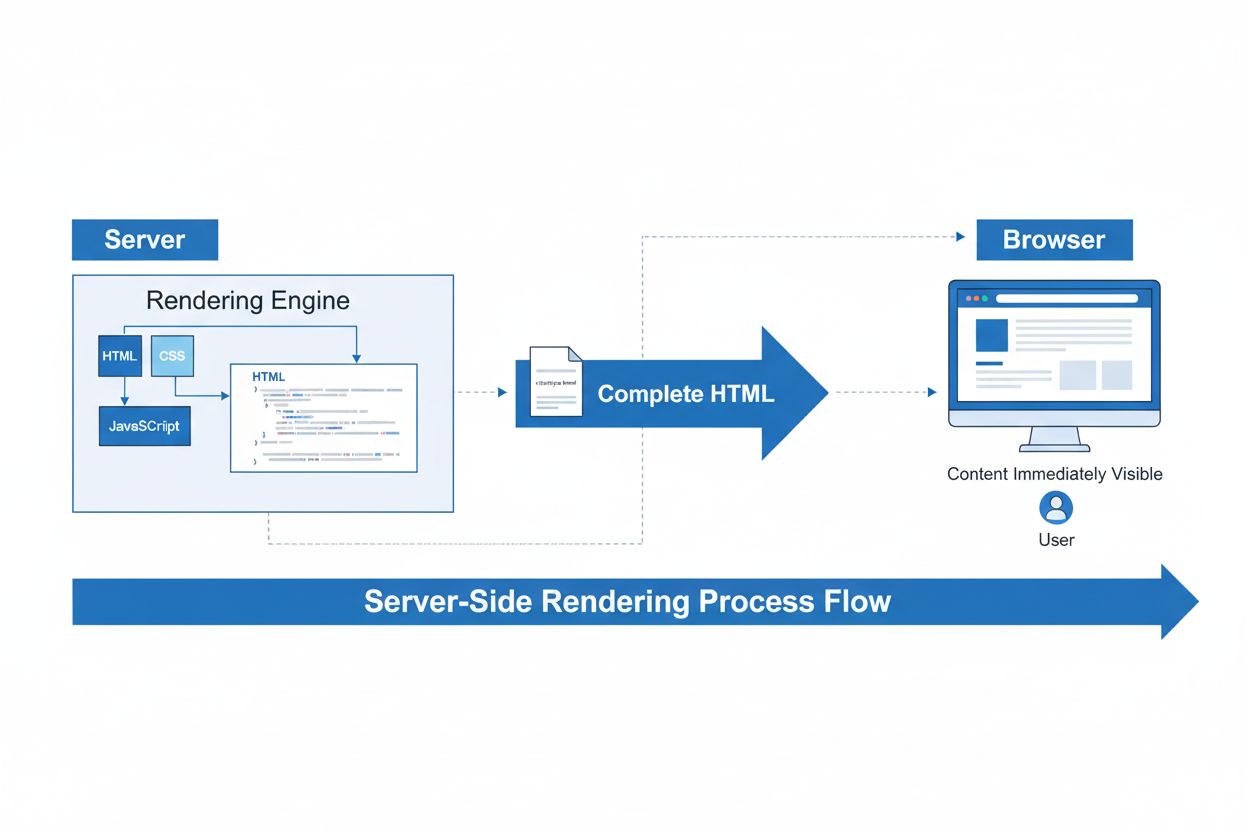
Server-Side Rendering (SSR)
Server-Side Rendering (SSR) er en webteknik, hvor servere renderer komplette HTML-sider, før de sendes til browsere. Lær hvordan SSR forbedrer SEO, sidehastighe...
10 min læsning

Lær hvordan server-side rendering muliggør effektiv AI-behandling, modeludrulning og realtidsinference for AI-drevne applikationer og LLM-arbejdsbelastninger.
Server-side rendering for AI er en arkitektonisk tilgang, hvor kunstige intelligensmodeller og inferensbehandling foregår på serveren frem for på klientenheder. Dette muliggør effektiv håndtering af beregningstunge AI-opgaver, sikrer ensartet ydeevne for alle brugere og forenkler udrulning og opdateringer af modeller.
Server-side rendering for AI refererer til et arkitektonisk mønster, hvor kunstig intelligensmodeller, inferensbehandling og beregningsopgaver udføres på backend-servere i stedet for på klientenheder som browsere eller mobiltelefoner. Denne tilgang adskiller sig fundamentalt fra traditionel client-side rendering, hvor JavaScript kører i brugerens browser for at generere indhold. I AI-applikationer betyder server-side rendering, at store sprogmodeller (LLM’er), maskinlæringsinference og AI-drevet indholdsgenerering sker centralt på kraftfuld serverinfrastruktur før resultaterne sendes til brugerne. Dette arkitektoniske skifte er blevet stadig vigtigere, efterhånden som AI-funktionaliteter er blevet mere beregningstunge og integreret i moderne webapplikationer.
Konceptet opstod fra erkendelsen af et kritisk misforhold mellem, hvad moderne AI-applikationer kræver, og hvad klientenheder realistisk kan levere. Traditionelle webudviklingsrammer som React, Angular og Vue.js populariserede client-side rendering gennem 2010’erne, men denne tilgang skaber betydelige udfordringer, når den anvendes på AI-tunge arbejdsbelastninger. Server-side rendering for AI adresserer disse udfordringer ved at udnytte specialiseret hardware, centraliseret modelstyring og optimeret infrastruktur, som klientenheder simpelthen ikke kan matche. Dette repræsenterer et grundlæggende paradigmeskifte i måden, udviklere opbygger AI-drevne applikationer på.
De beregningsmæssige krav i moderne AI-systemer gør server-side rendering ikke blot fordelagtig, men ofte nødvendig. Klientenheder, især smartphones og billige bærbare computere, mangler den processorkraft, der skal til for at håndtere realtids-AI-inference effektivt. Når AI-modeller kører på klientenheder, oplever brugerne mærkbare forsinkelser, øget batteriforbrug og svingende ydeevne afhængigt af hardwarekapacitet. Server-side rendering eliminerer disse problemer ved at centralisere AI-behandlingen på infrastruktur udstyret med GPU’er, TPU’er og specialiserede AI-acceleratorer, der giver en langt bedre ydeevne end forbrugerenheder.
Ud over ren ydeevne giver server-side rendering for AI afgørende fordele inden for modelstyring, sikkerhed og konsistens. Når AI-modeller kører på servere, kan udviklere opdatere, finjustere og udrulle nye versioner øjeblikkeligt uden at brugerne skal downloade opdateringer eller håndtere forskellige modelversioner lokalt. Dette er især vigtigt for store sprogmodeller og maskinlæringssystemer, der udvikler sig hurtigt med hyppige forbedringer og sikkerhedsrettelser. Desuden forhindrer det at holde AI-modeller på servere uautoriseret adgang, modeludtræk og tyveri af intellektuel ejendom, som bliver mulig, når modeller distribueres til klientenheder.
| Aspekt | Client-Side AI | Server-Side AI |
|---|---|---|
| Behandlingssted | Brugerens browser eller enhed | Backend-servere |
| Hardwarekrav | Begrænset til enhedens kapaciteter | Specialiserede GPU’er, TPU’er, AI-acceleratorer |
| Ydeevne | Variabel, afhænger af enheden | Konsistent, optimeret |
| Modelopdateringer | Kræver brugerdownloads | Øjeblikkelig udrulning |
| Sikkerhed | Modeller udsat for udtræk | Modeller beskyttet på servere |
| Latens | Afhænger af enhedens styrke | Optimeret infrastruktur |
| Skalerbarhed | Begrænset pr. enhed | Meget skalerbar på tværs af brugere |
| Udviklingskompleksitet | Høj (enhedsfragmentering) | Lavere (centraliseret styring) |
Netværksoverhead og latens udgør betydelige udfordringer i AI-applikationer. Moderne AI-systemer kræver konstant kommunikation med servere for modelopdateringer, hentning af træningsdata og hybride behandlingsscenarier. Client-side rendering øger paradoksalt nok netværksanmodninger sammenlignet med traditionelle applikationer, hvilket reducerer de ydelsesfordele, client-side behandling skulle give. Server-side rendering samler denne kommunikation, reducerer rundrejsetider og muliggør, at realtids-AI-funktioner som liveoversættelse, indholdsgenerering og computer vision-behandling fungerer gnidningsfrit uden latensstraf fra client-side inference.
Synkroniseringskompleksitet opstår, når AI-applikationer skal opretholde tilstandskonsistens på tværs af flere AI-tjenester samtidigt. Moderne applikationer bruger ofte embeddings-tjenester, completion-modeller, finjusterede modeller og specialiserede inferensmotorer, der skal koordinere med hinanden. At styre denne distribuerede tilstand på klientenheder introducerer betydelig kompleksitet og skaber risiko for datainkonsistens, især i realtidssamarbejdende AI-funktioner. Server-side rendering centraliserer denne tilstandsstyring, så alle brugere ser konsistente resultater og eliminerer den tekniske byrde ved at vedligeholde kompleks client-side tilstandssynkronisering.
Enhedsfragmentering skaber betydelige udviklingsudfordringer for client-side AI. Forskellige enheder har varierende AI-egenskaber, herunder Neural Processing Units, GPU-acceleration, WebGL-understøttelse og hukommelsesbegrænsninger. At skabe ensartede AI-oplevelser på tværs af dette fragmenterede landskab kræver betydelig ingeniørindsats, strategier for graciøs nedskalering og flere kodeveje for forskellige enheders egenskaber. Server-side rendering eliminerer denne fragmentering fuldstændigt ved at sikre, at alle brugere får adgang til den samme optimerede AI-behandlingsinfrastruktur, uanset deres enhedsspecifikationer.
Server-side rendering muliggør forenklede og lettere vedligeholdelige AI-applikationsarkitekturer ved at centralisere kritisk funktionalitet. I stedet for at distribuere AI-modeller og inferenslogik på tusindvis af klientenheder, vedligeholder udviklerne en enkelt, optimeret implementering på serverne. Denne centralisering giver øjeblikkelige fordele, herunder hurtigere udrulningscyklusser, lettere fejlfinding og mere ligetil ydelsesoptimering. Når en AI-model skal forbedres, eller der opdages en fejl, retter udviklerne det én gang på serveren i stedet for at forsøge at skubbe opdateringer ud til millioner af klientenheder med varierende opdateringshastighed.
Ressourceeffektivitet forbedres markant med server-side rendering. Serverinfrastruktur muliggør effektiv ressourceudnyttelse på tværs af alle brugere, hvor forbindelsespuljer, cachingstrategier og load balancing optimerer hardwareudnyttelsen. En enkelt GPU på en server kan behandle inferensanmodninger fra tusindvis af brugere sekventielt, hvor det ville kræve millioner af GPU’er at distribuere den samme kapacitet til klientenheder. Denne effektivitet fører til lavere driftsomkostninger, reduceret miljøpåvirkning og bedre skalerbarhed, efterhånden som applikationer vokser.
Sikkerhed og beskyttelse af intellektuel ejendom bliver markant lettere med server-side rendering. AI-modeller repræsenterer store investeringer i forskning, træningsdata og beregningsressourcer. At holde modeller på servere forhindrer modeludtræksangreb, uautoriseret adgang og tyveri af intellektuel ejendom, som bliver muligt, når modeller distribueres til klientenheder. Desuden muliggør server-side behandling finmasket adgangskontrol, auditlogning og compliance-overvågning, som ville være umuligt at håndhæve på distribuerede klientenheder.
Moderne frameworks har udviklet sig til effektivt at understøtte server-side rendering til AI-arbejdsbelastninger. Next.js fører an i denne udvikling med Server Actions, der muliggør nem AI-behandling direkte fra serverkomponenter. Udviklere kan kalde AI-API’er, behandle store sprogmodeller og streame svar tilbage til klienten med minimal boilerplate-kode. Frameworket håndterer kompleksiteten ved server-klient-kommunikation, så udvikleren kan fokusere på AI-logik i stedet for infrastruktur.
SvelteKit tilbyder en performance-first tilgang til server-side AI-rendering med dets load-funktioner, der eksekveres på serveren før rendering. Det muliggør forbehandling af AI-data, generering af anbefalinger og forberedelse af AI-beriget indhold før HTML sendes til klienten. De færdige applikationer har minimal JavaScript-størrelse og bevarer fulde AI-muligheder, hvilket skaber ekstremt hurtige brugeroplevelser.
Specialiserede værktøjer som Vercel AI SDK abstraherer kompleksiteten ved streaming af AI-svar, håndtering af tokenoptælling og integration med forskellige AI-udbyderes API’er. Disse værktøjer gør det muligt for udviklere at bygge avancerede AI-applikationer uden dyb infrastrukturviden. Infrastrukturmuligheder som Vercel Edge Functions, Cloudflare Workers og AWS Lambda giver globalt distribueret server-side AI-behandling, reducerer latens ved at behandle anmodninger tættere på brugeren og bevarer samtidig centraliseret modelstyring.
Effektiv server-side AI-rendering kræver sofistikerede cachingstrategier for at håndtere beregningsomkostninger og latens. Redis-caching gemmer ofte forespurgte AI-svar og brugersessioner, hvilket eliminerer overflødig behandling af lignende forespørgsler. CDN-caching distribuerer statisk AI-genereret indhold globalt, så brugerne får svar fra servere tæt på geografisk. Edge-cachingstrategier distribuerer AI-behandlet indhold på kantenetværk, hvilket giver ultra-lav latens og samtidig bevarer central modelstyring.
Disse cachingtilgange arbejder sammen for at skabe effektive AI-systemer, der kan skalere til millioner af brugere uden at de beregningsmæssige omkostninger følger med. Ved at cache AI-svar på flere niveauer kan applikationer levere langt de fleste forespørgsler fra cache og kun beregne nye svar for reelt nye forespørgsler. Det reducerer infrastrukturudgifterne markant og forbedrer brugeroplevelsen via hurtigere svartider.
Udviklingen mod server-side rendering repræsenterer en modning af webudviklingspraksis som reaktion på AI-krav. Efterhånden som AI bliver central i webapplikationer, kræver de beregningsmæssige realiteter servercentriske arkitekturer. Fremtiden indebærer sofistikerede hybridtilgange, der automatisk beslutter, hvor rendering skal ske ud fra indholdstype, enhedskapacitet, netværksforhold og AI-behandlingsbehov. Frameworks vil gradvist forbedre applikationer med AI-muligheder, så kernefunktionalitet fungerer universelt og oplevelsen forbedres, hvor det er muligt.
Dette paradigmeskifte inkorporerer erfaringer fra Single Page Application-æraen, samtidig med at det adresserer AI-native applikationsudfordringer. Værktøjerne og frameworks er klar til, at udviklere kan udnytte AI-tidens server-side rendering og muliggøre næste generation af intelligente, responsive og effektive webapplikationer.
Følg med i, hvordan dit domæne og brand vises i AI-genererede svar på ChatGPT, Perplexity og andre AI-søgemaskiner. Få realtidsindsigt i din AI-synlighed.
Server-Side Rendering (SSR) er en webteknik, hvor servere renderer komplette HTML-sider, før de sendes til browsere. Lær hvordan SSR forbedrer SEO, sidehastighe...
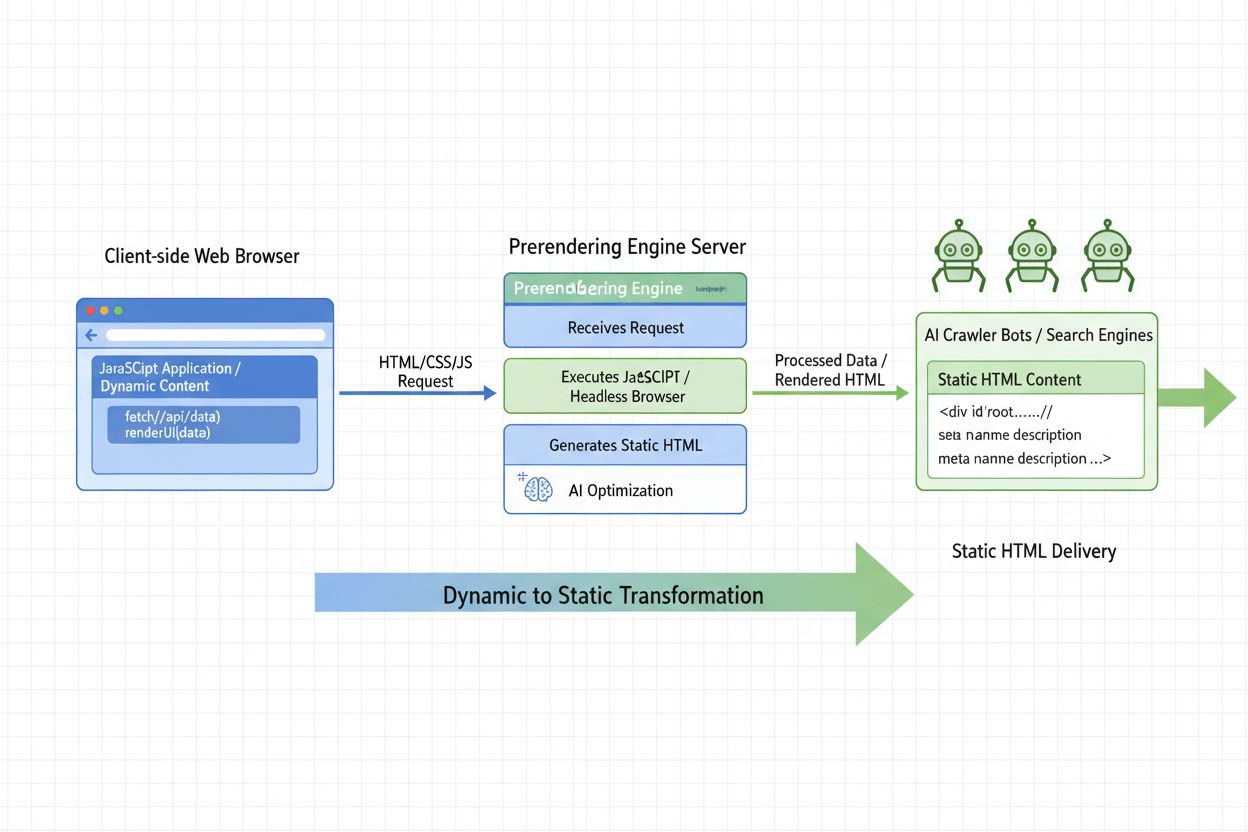
Lær hvad AI Prerendering er, og hvordan server-side rendering-strategier optimerer din hjemmeside til AI-crawleres synlighed. Opdag implementeringsstrategier fo...

Lær hvordan pre-rendering hjælper dit website med at blive vist i AI-søgeresultater fra ChatGPT, Perplexity og Claude. Forstå den tekniske implementering og for...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.