Hvordan optimerer jeg supportindhold til AI?
Lær essentielle strategier til at optimere dit supportindhold til AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Opdag bedste praksis for klarhed, ...
9 min læsning
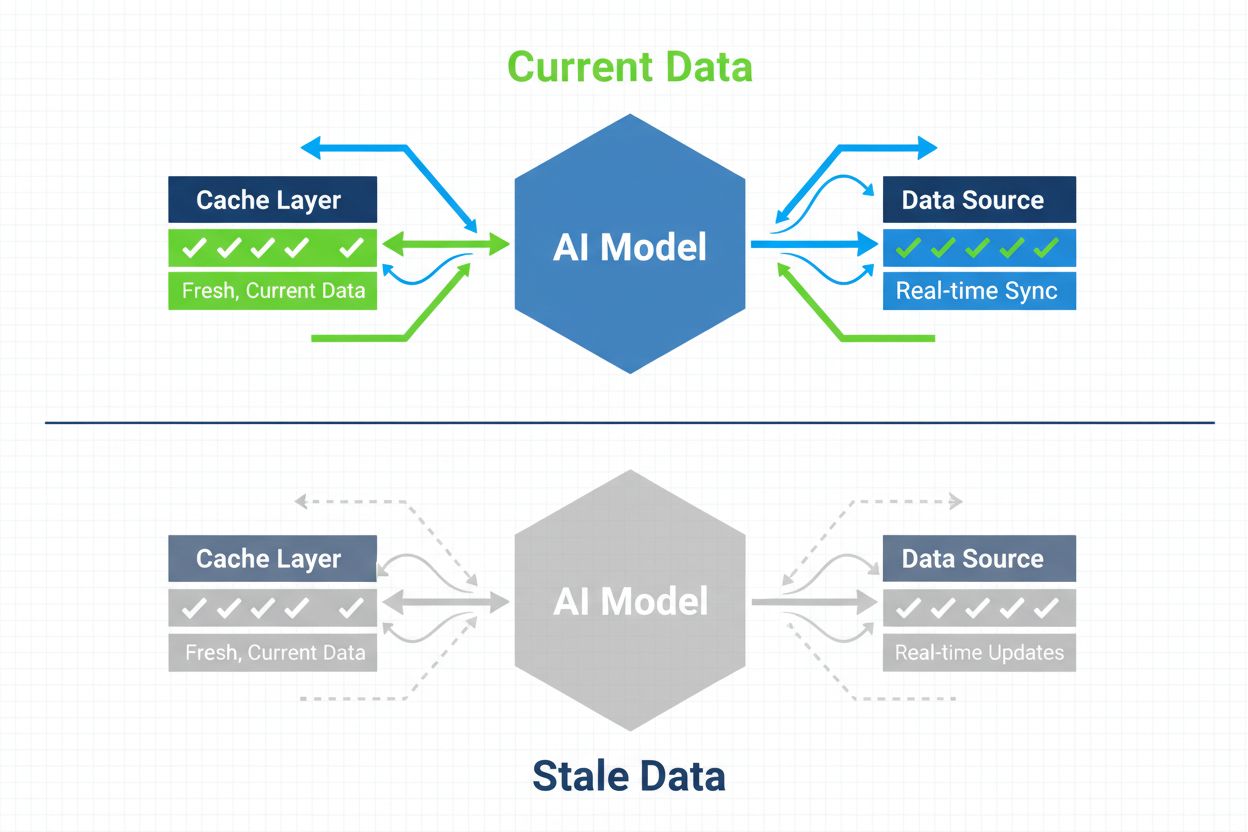
Strategier for at sikre, at AI-systemer har adgang til aktuelt indhold i stedet for forældede cachede versioner. Cachehåndtering balancerer ydeevnefordelene ved caching mod risikoen for at levere forældet information, ved at bruge invalideringsstrategier og overvågning for at opretholde dataaktualitet samtidig med at latenstid og omkostninger reduceres.
Strategier for at sikre, at AI-systemer har adgang til aktuelt indhold i stedet for forældede cachede versioner. Cachehåndtering balancerer ydeevnefordelene ved caching mod risikoen for at levere forældet information, ved at bruge invalideringsstrategier og overvågning for at opretholde dataaktualitet samtidig med at latenstid og omkostninger reduceres.
AI-cachehåndtering henviser til den systematiske tilgang til at lagre og hente tidligere beregnede resultater, modeluddata eller API-svar for at undgå redundant behandling og reducere latenstid i kunstig intelligens-systemer. Den centrale udfordring ligger i at balancere ydeevnefordelene ved cachede data mod risikoen for at levere forældede eller uaktuelle oplysninger, der ikke længere afspejler nuværende systemtilstand eller brugerkrav. Dette bliver særligt kritisk i store sprogmodeller (LLM’er) og AI-applikationer, hvor inferensomkostninger er betydelige, og svartiden har direkte indflydelse på brugeroplevelsen. Cachehåndteringssystemer skal intelligent bestemme, hvornår cachede resultater stadig er gyldige, og hvornår ny beregning er nødvendig, hvilket gør det til en grundlæggende arkitektonisk overvejelse for produktionsklare AI-udrulninger.
Effektiv cachehåndtering har en mærkbar og målbar indflydelse på AI-systemers ydeevne på flere dimensioner. Implementering af caching-strategier kan reducere svartiden med 80-90% for gentagne forespørgsler, samtidig med at API-omkostninger skæres med 50-90%, afhængigt af cache-hit-rater og systemarkitektur. Ud over ydelsesmæssige målinger påvirker cachehåndtering direkte nøjagtighedskonsistens og systempålidelighed, da korrekt invaliderede cacher sikrer, at brugerne modtager aktuelle informationer, mens dårligt administrerede cacher kan føre til problemer med dataforældelse. Disse forbedringer bliver stadig vigtigere, efterhånden som AI-systemer skaleres til at håndtere millioner af forespørgsler, hvor den kumulative effekt af cacheeffektivitet direkte bestemmer infrastrukturudgifter og brugertilfredshed.
| Aspekt | Cachede systemer | Ikke-cachede systemer |
|---|---|---|
| Svartid | 80-90% hurtigere | Standard |
| API-omkostninger | 50-90% reduktion | Fuld pris |
| Nøjagtighed | Konsistent | Variabel |
| Skalerbarhed | Høj | Begrænset |
Cacheinvalideringsstrategier afgør, hvordan og hvornår cachede data opdateres eller fjernes fra lageret, og udgør en af de mest kritiske beslutninger i cachearkitekturdesign. Forskellige invalideringsmetoder giver forskellige afvejninger mellem dataaktualitet og systemydelse:
Valget af invalideringsstrategi afhænger grundlæggende af applikationskrav: systemer, der prioriterer dataaktualitet, kan acceptere højere latenstid gennem aggressiv invalidering, mens ydelseskritiske applikationer kan tolerere let forældede data for at opretholde svartider under millisekunder.
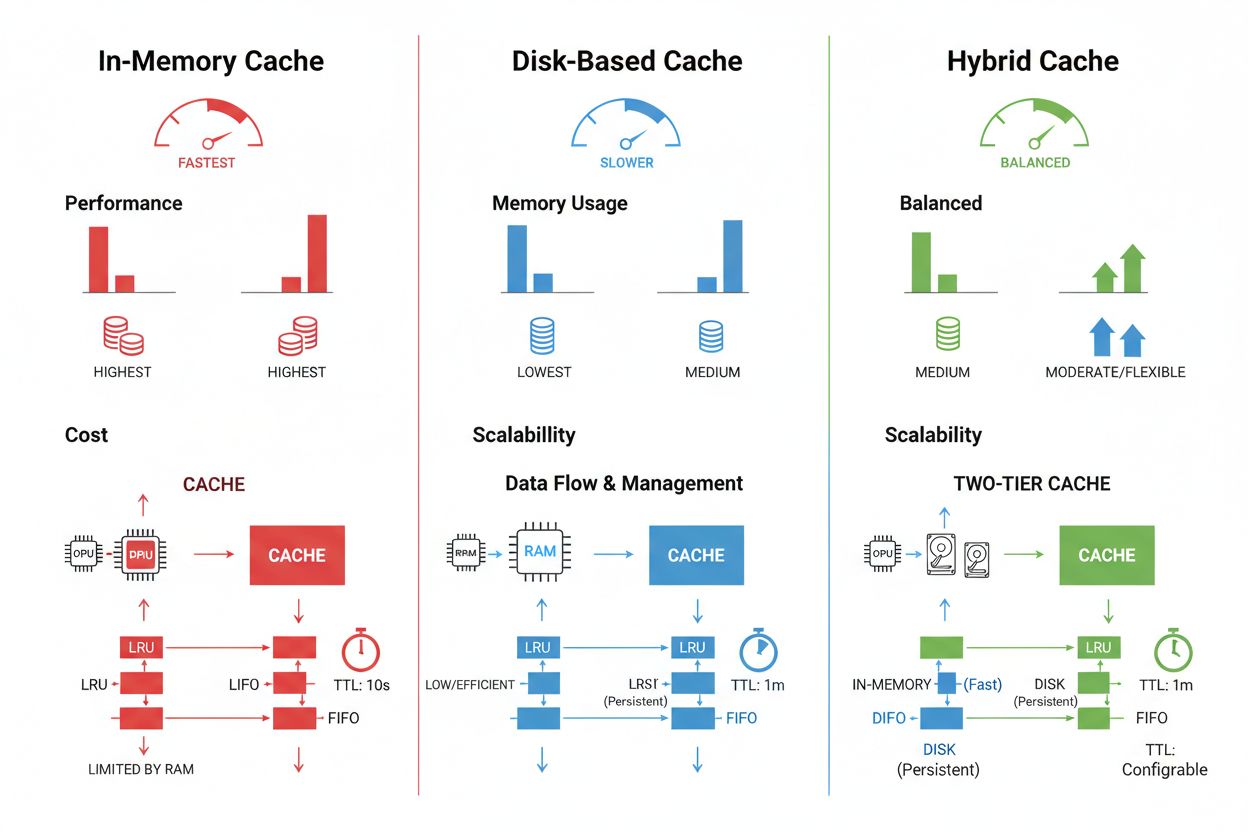
Prompt-caching i store sprogmodeller er en specialiseret anvendelse af cachehåndtering, der lagrer mellemliggende modeltilstande og tokensekvenser for at undgå genbehandling af identiske eller lignende input. LLM’er understøtter to primære caching-metoder: eksakt caching matcher identiske prompts tegn-for-tegn, mens semantisk caching identificerer funktionelt ækvivalente prompts på trods af forskellig formulering. OpenAI implementerer automatisk prompt-caching med 50% omkostningsreduktion på cachede tokens og kræver minimum promptsegmenter på 1024 tokens for at aktivere cachingfordele. Anthropic tilbyder manuel prompt-caching med mere aggressive 90% omkostningsreduktioner, men kræver, at udviklere eksplicit håndterer cache-nøgler og varigheder, med minimum cachekrav på 1024-2048 tokens afhængigt af modelkonfiguration. Cachevarighed i LLM-systemer spænder typisk fra minutter til timer og balancerer de beregningsmæssige besparelser ved genbrug af cachede tilstande mod risikoen for at levere forældede modeluddata til tidsfølsomme applikationer.
Cachelagrings- og håndteringsteknikker varierer betydeligt afhængigt af ydelseskrav, datamængde og infrastrukturbegrænsninger, hvor hver tilgang har sine egne fordele og begrænsninger. In-memory caching-løsninger som Redis giver adgangshastigheder på mikrosekund-niveau, hvilket er ideelt til højt-frekvente forespørgsler, men kræver betydelig RAM og omhyggelig hukommelsesstyring. Diskbaseret caching rummer større datasæt og bevares på tværs af systemgenstarter, men introducerer latenstid målt i millisekunder sammenlignet med in-memory-alternativer. Hybride tilgange kombinerer begge lagertyper og dirigerer hyppigt tilgåede data til hukommelsen, mens større datasæt bevares på disk:
| Lager-type | Bedst til | Ydelse | Hukommelsesforbrug |
|---|---|---|---|
| In-memory (Redis) | Hyppige forespørgsler | Hurtigst | Højere |
| Diskbaseret | Store datasæt | Moderat | Lavere |
| Hybrid | Blandede arbejdsbyrder | Afbalanceret | Afbalanceret |
Effektiv cachehåndtering kræver konfiguration af passende TTL-indstillinger, der afspejler datavolatilitet—korte TTL’er (minutter) for hurtigt skiftende data versus længere TTL’er (timer/dage) for stabilt indhold—kombineret med løbende overvågning af cache-hit-rater, udskiftningsmønstre og hukommelsesudnyttelse for at identificere optimeringsmuligheder.
Virkelige AI-applikationer demonstrerer både det transformerende potentiale og den driftsmæssige kompleksitet ved cachehåndtering på tværs af forskellige brugsscenarier. Kundeservice-chatbots udnytter caching til at levere konsistente svar på ofte stillede spørgsmål og reducere inferensomkostninger med 60-70%, hvilket muliggør omkostningseffektiv skalering til tusindvis af samtidige brugere. Kodeassistenter cacher almindelige kodeeksempler og dokumentationsuddrag, så udviklere kan modtage autocomplete-forslag med latens under 100 ms selv i spidsbelastningsperioder. Dokumentbehandlingssystemer cacher indlejrede og semantiske repræsentationer af ofte analyserede dokumenter, hvilket dramatisk accelererer lighedssøgninger og klassificeringsopgaver. Men produktionel cachehåndtering introducerer væsentlige udfordringer: invalideringskompleksiteten øges eksponentielt i distribuerede systemer, hvor cachekonsistens skal opretholdes på tværs af flere servere, ressourcebegrænsninger tvinger vanskelige kompromiser mellem cachestørrelse og dækning, sikkerhedsrisici opstår, når cachede data indeholder følsomme oplysninger, der kræver kryptering og adgangskontrol, og koordinering af cacheopdateringer på tværs af mikrotjenester introducerer potentielle race conditions og datainkonsistenser. Omfattende overvågningsløsninger, der sporer cacheaktualitet, hit-rater og invalideringshændelser, bliver afgørende for at opretholde systempålidelighed og identificere, hvornår cachestrategier skal justeres baseret på ændrede datamønstre og brugeradfærd.
Cacheinvalidering fjerner eller opdaterer forældede data, når der sker ændringer, hvilket giver øjeblikkelig aktualitet, men kræver hændelsesbaserede udløsere. Cacheudløb sætter en tidsgrænse (TTL) for, hvor længe data forbliver i cachen, hvilket giver en enklere implementering, men kan potentielt levere forældede data, hvis TTL er for lang. Mange systemer kombinerer begge tilgange for optimal ydeevne.
Effektiv cachehåndtering kan reducere API-omkostninger med 50-90% afhængigt af cache-hitrate og systemarkitektur. OpenAI's prompt-caching giver 50% omkostningsreduktion på cachede tokens, mens Anthropic tilbyder op til 90% reduktion. De faktiske besparelser afhænger af forespørgsmønstre og hvor meget data, der effektivt kan caches.
Prompt-caching gemmer mellemliggende modeltilstande og tokensekvenser for at undgå genbehandling af identiske eller lignende input i store sprogmodeller. Det understøtter både eksakt caching (tegn-for-tegn match) og semantisk caching (funktionelt ækvivalente prompts med forskellig formulering). Dette reducerer latenstid med 80% og omkostninger med 50-90% ved gentagne forespørgsler.
De primære strategier er: Tidsbaseret udløb (TTL) for automatisk fjernelse efter en fastsat varighed, hændelsesbaseret invalidering for øjeblikkelig opdatering, når data ændres, semantisk invalidering for lignende forespørgsler baseret på betydning, og hybride tilgange, der kombinerer flere strategier. Valget afhænger af datavolatilitet og aktualitetskrav.
In-memory caching (som Redis) giver mikrosekund-niveau adgangshastigheder, ideelt til hyppige forespørgsler, men bruger betydelig RAM. Diskbaseret caching rummer større datasæt og bevares på tværs af genstarter, men introducerer latenstid på millisekund-niveau. Hybride tilgange kombinerer begge, hvor hyppigt tilgåede data lægges i hukommelsen, mens større datasæt opbevares på disk.
TTL er en nedtællingstimer, der bestemmer, hvor længe cachede data forbliver gyldige før udløb. Korte TTL'er (minutter) passer til hurtigt skiftende data, mens længere TTL'er (timer/dage) fungerer for stabilt indhold. Korrekt TTL-konfiguration balancerer dataaktualitet mod unødvendige cacheopdateringer og serverbelastning.
Effektiv cachehåndtering gør det muligt for AI-systemer at håndtere markant flere forespørgsler uden proportional udvidelse af infrastrukturen. Ved at reducere den beregningsmæssige belastning pr. forespørgsel gennem caching, kan systemer betjene millioner af brugere mere omkostningseffektivt. Cache-hit-rater bestemmer direkte infrastrukturudgifter og brugertilfredshed i produktion.
Cachede følsomme data introducerer sikkerhedssårbarheder, hvis de ikke er korrekt krypteret og adgangskontrolleret. Risici inkluderer uautoriseret adgang til cachede oplysninger, dataeksponering under cacheinvalidering og utilsigtet caching af fortroligt indhold. Omfattende kryptering, adgangskontrol og overvågning er afgørende for at beskytte følsomme cachede data.
AmICited sporer, hvordan AI-systemer refererer til dit brand og sikrer, at dit indhold forbliver aktuelt i AI-cacher. Få indsigt i AI-cachehåndtering og indholdsaktualitet på tværs af GPT'er, Perplexity og Google AI Overviews.
Lær essentielle strategier til at optimere dit supportindhold til AI-systemer som ChatGPT, Perplexity og Google AI Overviews. Opdag bedste praksis for klarhed, ...
Lær hvordan du strukturerer dit indhold, så det bliver citeret af AI-søgemaskiner som ChatGPT, Perplexity og Google AI. Ekspertstrategier for AI-synlighed og ci...
Lær hvordan du optimerer indholdslæsbarhed for AI-systemer, ChatGPT, Perplexity og AI-søgemaskiner. Opdag best practices for struktur, formatering og klarhed, s...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.