
A/B-testning for AI-synlighed: Metodologi og bedste praksis
Bliv ekspert i A/B-testning for AI-synlighed med vores omfattende guide. Lær GEO-eksperimenter, metodologi, bedste praksis og virkelige casestudier for bedre AI...
10 min læsning

Isolerede sandkassemiljøer designet til at validere, evaluere og fejlfinde kunstig intelligens-modeller og -applikationer før implementering i produktion. Disse kontrollerede rum muliggør test af AI-indholds ydeevne på tværs af forskellige platforme, måling af metrikker og sikring af pålidelighed uden at påvirke live-systemer eller afsløre følsomme data.
Isolerede sandkassemiljøer designet til at validere, evaluere og fejlfinde kunstig intelligens-modeller og -applikationer før implementering i produktion. Disse kontrollerede rum muliggør test af AI-indholds ydeevne på tværs af forskellige platforme, måling af metrikker og sikring af pålidelighed uden at påvirke live-systemer eller afsløre følsomme data.
Et AI-testmiljø er et kontrolleret, isoleret computerrum designet til at validere, evaluere og fejlfinde kunstig intelligens-modeller og -applikationer før implementering til produktionssystemer. Det fungerer som en sandkasse, hvor udviklere, dataspecialister og QA-teams sikkert kan eksekvere AI-modeller, teste forskellige konfigurationer og måle ydeevne mod foruddefinerede metrikker uden at påvirke live-systemer eller afsløre følsomme data. Disse miljøer efterligner produktionsforhold, mens de opretholder fuldstændig isolation, så teams kan identificere problemer, optimere modeladfærd og sikre pålidelighed på tværs af forskellige scenarier. Testmiljøet fungerer som en kritisk kvalitetsbarriere i AI-udviklingslivscyklussen og bygger bro mellem eksperimentel prototyping og enterprise-implementering.

Et omfattende AI-testmiljø består af flere sammenkoblede tekniske lag, der arbejder sammen for at levere komplette testmuligheder. Modeludførelseslaget håndterer selve inferensen og beregningen og understøtter flere frameworks (PyTorch, TensorFlow, ONNX) og modeltyper (LLMs, computer vision, tidsserier). Datastyringslaget styrer testdatasæt, fixtures og syntetisk datagenerering, mens det opretholder dataisolering og compliance. Evalueringsframeworket inkluderer metrikmotorer, assertionsbiblioteker og scoringssystemer, der måler modeloutputs mod forventede resultater. Overvågnings- og logningslaget opfanger execution traces, ydeevnemetrikker, latensdata og fejllogs til analyse efter test. Orkestreringslaget styrer testarbejdsgange, parallel eksekvering, ressourceallokering og miljøprovisionering. Nedenfor ses en sammenligning af nøglearkitektur-komponenter på tværs af forskellige testmiljøtyper:
| Komponent | LLM-test | Computer Vision | Tidsserier | Multi-Modal |
|---|---|---|---|---|
| Model Runtime | Transformer-inferens | GPU-accelereret inferens | Sekventiel behandling | Hybrid eksekvering |
| Dataformat | Tekst/tokens | Billeder/tensors | Numeriske sekvenser | Blandet media |
| Evalueringsmetrikker | Semantisk lighed, hallucination | Nøjagtighed, IoU, F1-score | RMSE, MAE, MAPE | Cross-modal alignment |
| Latenskrav | 100-500ms typisk | 50-200ms typisk | <100ms typisk | 200-1000ms typisk |
| Isolationsmetode | Container/VM | Container/VM | Container/VM | Firecracker microVM |
Moderne AI-testmiljøer skal understøtte heterogene modeleksosystemer, så teams kan evaluere applikationer på tværs af forskellige LLM-udbydere, frameworks og deployment-targets samtidigt. Multiplatform-test gør det muligt for organisationer at sammenligne modeloutput fra OpenAI’s GPT-4, Anthropic’s Claude, Mistral og open source-alternativer som Llama i samme testmiljø, hvilket letter informerede modelvalg. Platforme som E2B tilbyder isolerede sandkasser, der eksekverer kode genereret af enhver LLM og understøtter Python, JavaScript, Ruby og C++ med fuld filsystemadgang, terminalfunktioner og pakkeinstallation. IntelIQ.dev muliggør side-om-side sammenligning af flere AI-modeller med forenede grænseflader, så teams kan teste guardrailede prompts og politikskabeloner på tværs af udbydere. Testmiljøer skal håndtere:
AI-testmiljøer opfylder forskellige organisatoriske behov på tværs af udvikling, kvalitetssikring og compliance-funktioner. Udviklingsteams bruger testmiljøer til at validere modeladfærd under iterativ udvikling, teste promptvariationer, finjustere parametre og fejlfinde uventede outputs før integration. Datascience-teams udnytter disse miljøer til at evaluere modelydelse på holdout-datasæt, sammenligne forskellige arkitekturer og måle metrikker som nøjagtighed, præcision, recall og F1-score. Produktionsovervågning indebærer kontinuerlig test af implementerede modeller mod baseline-metrikker, detektering af performanceforringelse og igangsættelse af retrainingspipelines, når kvalitetsgrænser overskrides. Compliance- og sikkerhedsteams bruger testmiljøer til at sikre, at modeller opfylder regulatoriske krav, ikke frembringer biased output og håndterer følsomme data korrekt. Enterprise-applikationer inkluderer:
AI-testlandskabet omfatter specialiserede platforme designet til forskellige testscenarier og organisatoriske skalaer. DeepEval er et open source-LLM-evalueringsframework, der tilbyder 50+ forskningsbaserede metrikker, herunder svarnøjagtighed, semantisk lighed, hallucinationsdetektion og toksicitetscore, med indbygget Pytest-integration til CI/CD-workflows. LangSmith (fra LangChain) tilbyder omfattende observabilitet, evaluering og deployment-muligheder med indbygget tracing, prompt-versionering og datasetstyring til LLM-applikationer. E2B tilbyder sikre, isolerede sandkasser drevet af Firecracker microVMs, understøtter kodeeksekvering med under 200ms opstartstid, op til 24-timers sessioner og integration med større LLM-udbydere. IntelIQ.dev lægger vægt på privacy-first test med end-to-end kryptering, rollebaseret adgangskontrol og understøttelse af flere AI-modeller, herunder GPT-4, Claude og open source-alternativer. Tabellen nedenfor sammenligner nøglefunktioner:
| Værktøj | Primært fokus | Metrikker | CI/CD-integration | Multi-model support | Prisstruktur |
|---|---|---|---|---|---|
| DeepEval | LLM-evaluering | 50+ metrikker | Native Pytest | Begrænset | Open source + cloud |
| LangSmith | Observabilitet & evaluering | Brugerdefinerede metrikker | API-baseret | LangChain-økosystem | Freemium + enterprise |
| E2B | Kodeeksekvering | Ydeevnemetrikker | GitHub Actions | Alle LLM’er | Pay-per-use + enterprise |
| IntelIQ.dev | Privacy-first test | Brugerdefinerede metrikker | Workflow builder | GPT-4, Claude, Mistral | Abonnementsbaseret |
Enterprise AI-testmiljøer skal implementere strenge sikkerhedskontroller for at beskytte følsomme data, opretholde regulatorisk overholdelse og forhindre uautoriseret adgang. Dataisolering kræver, at testdata aldrig lækker til eksterne API’er eller tredjepartstjenester; platforme som E2B bruger Firecracker microVMs til at levere komplet procesisolation uden delt kerneadgang. Krypteringsstandarder bør inkludere end-to-end kryptering af data i hvile og under overførsel, med understøttelse af HIPAA, SOC 2 Type 2 og GDPR-overholdelseskrav. Adgangskontrol skal håndhæve rollebaserede tilladelser, audit-logging og godkendelsesworkflows for følsomme testscenarier. Best practices inkluderer: at opretholde separate testdatasæt, der ikke indeholder produktionsdata, implementere datamaskering af personhenførbare oplysninger (PII), bruge syntetisk datagenerering for realistisk test uden privatlivsrisici, udføre regelmæssige sikkerhedsrevisioner af testinfrastruktur og dokumentere alle testresultater til compliance-formål. Organisationer bør også implementere bias-detektion for at identificere diskriminerende modeladfærd, bruge interpretabilitetsværktøjer som SHAP eller LIME til at forstå modelbeslutninger og indføre beslutningslogging for at spore, hvordan modeller når frem til specifikke outputs for regulatorisk ansvarlighed.
AI-testmiljøer skal sømløst integreres i eksisterende continuous integration og continuous deployment-pipelines for at muliggøre automatiserede kvalitetskontroller og hurtige iterationscyklusser. Native CI/CD-integration gør det muligt at udløse testeksekvering automatisk ved kode-commits, pull requests eller planlagte intervaller via platforme som GitHub Actions, GitLab CI eller Jenkins. DeepEvals Pytest-integration gør det muligt for udviklere at skrive testcases som standard Python-tests, der eksekveres inden for eksisterende CI-workflows, med resultater rapporteret sammen med traditionelle unittests. Automatiseret evaluering kan måle modelydelsesmetrikker, sammenligne outputs mod baseline-versioner og blokere deployment, hvis kvalitetsgrænser ikke opfyldes. Artefaktstyring indebærer opbevaring af testdatasæt, modelcheckpoints og evalueringsresultater i versionsstyringssystemer eller artefakt-repositories for reproducerbarhed og audit trails. Integrationsmønstre inkluderer:
AI-testmiljølandskabet udvikler sig hurtigt for at imødekomme nye udfordringer inden for modelkompleksitet, skala og heterogenitet. Agentisk test bliver stadig vigtigere, efterhånden som AI-systemer bevæger sig ud over enkelt-model-inferens til flertrins-workflows, hvor agenter bruger værktøjer, træffer beslutninger og interagerer med eksterne systemer—hvilket kræver nye evalueringsrammer, der måler opgavefuldførelse, sikkerhed og pålidelighed. Distribueret evaluering muliggør test i stor skala ved at køre tusindvis af samtidige testinstanser på tværs af cloudinfrastruktur, afgørende for reinforcement learning og storstilet modeltræning. Realtidsovervågning skifter fra batch-evaluering til kontinuerlig, produktionsklar test, der detekterer ydeevneforringelse, datadrift og fremvoksende bias i live-systemer. Observabilitetsplatforme som AmICited bliver essentielle værktøjer til omfattende AI-overvågning og indsigt, idet de leverer centraliserede dashboards, der sporer modelydelse, brugsmønstre og kvalitetsmetrikker på tværs af hele AI-porteføljer. Fremtidige testmiljøer vil i stigende grad inkorporere automatiseret udbedring, hvor systemer ikke kun detekterer problemer, men automatisk udløser retrainingspipelines eller modelopdateringer, samt cross-modal evaluering, der understøtter simultan test af tekst-, billede-, lyd- og videomodeller i forenede frameworks.
Et AI-testmiljø er en isoleret sandkasse, hvor du sikkert kan teste modeller, prompts og konfigurationer uden at påvirke live-systemer eller brugere. Produktionsimplementering er det live-miljø, hvor modellerne betjener rigtige brugere. Testmiljøer giver dig mulighed for at opdage problemer, optimere ydeevne og validere ændringer, før de når produktionen, hvilket reducerer risikoen og sikrer kvalitet.
Ja, moderne AI-testmiljøer understøtter test af flere modeller samtidigt. Platforme som E2B, IntelIQ.dev og DeepEval giver dig mulighed for at teste det samme prompt eller input på tværs af forskellige LLM-udbydere (OpenAI, Anthropic, Mistral osv.) samtidigt, hvilket gør det muligt direkte at sammenligne output og ydeevnemetrikker.
Enterprise AI-testmiljøer implementerer flere sikkerhedslag, herunder dataisolering (containerisering eller microVMs), end-to-end kryptering, rollebaseret adgangskontrol, audit-logging og overholdelsescertificeringer (SOC 2, GDPR, HIPAA). Data forlader aldrig det isolerede miljø, medmindre det udtrykkeligt eksporteres, hvilket beskytter følsomme oplysninger.
Testmiljøer muliggør overholdelse ved at tilbyde revisionsspor af alle modelevalueringer, understøtte datamaskering og syntetisk datagenerering, håndhæve adgangskontrol og opretholde fuldstændig isolation af testdata fra produktionssystemer. Denne dokumentation og kontrol hjælper organisationer med at opfylde regulatoriske krav som GDPR, HIPAA og SOC 2.
Vigtige metrikker afhænger af dit brugsscenarie: for LLM’er, spor nøjagtighed, semantisk lighed, hallucinationsrater og latenstid; for RAG-systemer, mål kontekst-præcision/recall og troværdighed; for klassifikationsmodeller, overvåg præcision, recall og F1-score; for alle modeller, spor ydeevneforringelse over tid og bias-indikatorer.
Omkostninger varierer efter platform: DeepEval er open-source og gratis; LangSmith tilbyder et gratis niveau med betalte planer fra $39/md.; E2B bruger pay-per-use-priser baseret på sandkasse-køretid; IntelIQ.dev tilbyder abonnementsbaseret prisstruktur. Mange platforme tilbyder også enterprise-pris for store implementeringer.
Ja, de fleste moderne testmiljøer understøtter CI/CD-integration. DeepEval integrerer sig naturligt med Pytest, E2B fungerer med GitHub Actions og GitLab CI, og LangSmith tilbyder API-baseret integration. Dette muliggør automatiseret test ved hver kode-commit og implementeringsgate-håndhævelse.
End-to-end-test behandler hele din AI-applikation som en black box og tester det endelige output mod forventede resultater. Komponentniveau-test evaluerer individuelle dele (LLM-kald, retrievere, værktøjsbrug) separat ved brug af tracing og instrumentering. Komponentniveau-test giver dybere indsigt i hvor problemer opstår, mens end-to-end-test validerer den samlede systemadfærd.
AmICited sporer, hvordan AI-systemer refererer til dit brand og indhold på tværs af ChatGPT, Claude, Perplexity og Google AI. Få realtidsindsigt i din AI-tilstedeværelse med omfattende overvågning og analyse.
Bliv ekspert i A/B-testning for AI-synlighed med vores omfattende guide. Lær GEO-eksperimenter, metodologi, bedste praksis og virkelige casestudier for bedre AI...

Lær, hvad AI-indholdskvalitetstærskler er, hvordan de måles, og hvorfor de er vigtige for overvågning af AI-genereret indhold på tværs af ChatGPT, Perplexity o...
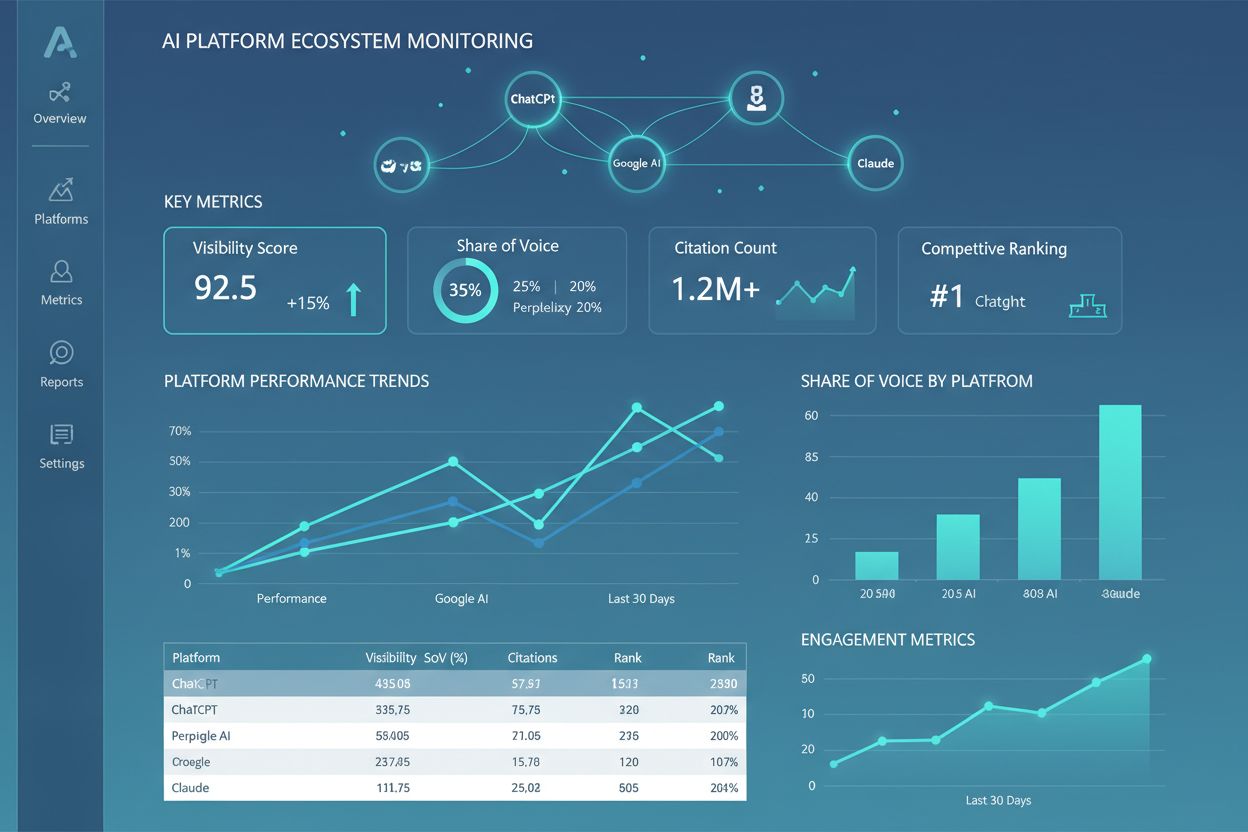
Lær, hvad et AI Platform-økosystem er, hvordan sammenkoblede AI-systemer arbejder sammen, og hvorfor det er vigtigt at styre din brandtilstedeværelse på tværs a...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.