
PerplexityBot: Hvad enhver hjemmesideejer bør vide
Komplet guide til PerplexityBot crawleren – forstå hvordan den fungerer, styr adgang, overvåg citater og optimer for synlighed på Perplexity AI. Lær om stealth ...
8 min læsning

Amazons webcrawler bruges til at forbedre produkter og tjenester, herunder Alexa, Rufus-shoppingassistenten og Amazons AI-drevne søgefunktioner. Den respekterer Robots Exclusion Protocol og kan kontrolleres gennem robots.txt-direktiver. Kan bruges til AI-modeltræning.
Amazons webcrawler bruges til at forbedre produkter og tjenester, herunder Alexa, Rufus-shoppingassistenten og Amazons AI-drevne søgefunktioner. Den respekterer Robots Exclusion Protocol og kan kontrolleres gennem robots.txt-direktiver. Kan bruges til AI-modeltræning.
Amazonbot er Amazons officielle webcrawler designet til at forbedre virksomhedens produkter og tjenester ved at indsamle og analysere webindhold. Denne sofistikerede crawler driver kritiske Amazon-funktioner, herunder Alexa-stemmeassistenten, Rufus AI-shoppingassistenten og Amazons AI-drevne søgeoplevelser. Amazonbot opererer ved hjælp af user agent-strengen Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Amazonbot/0.1; +https://developer.amazon.com/support/amazonbot) Chrome/119.0.6045.214 Safari/537.36, som identificerer den over for webservere. De data, der indsamles af Amazonbot, kan bruges til at træne Amazons kunstige intelligensmodeller, hvilket gør den til en afgørende komponent i Amazons bredere AI-infrastruktur og produktudviklingsstrategi.
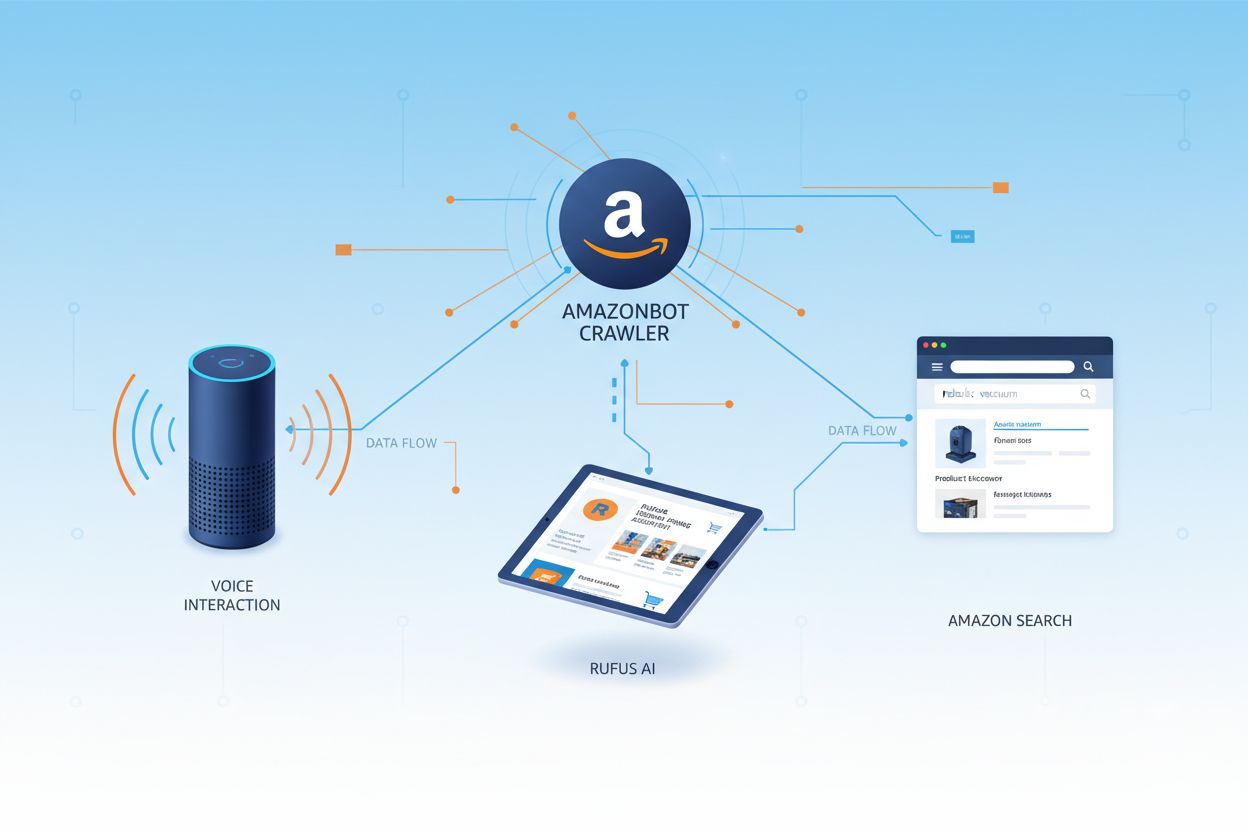
Amazon opererer tre forskellige webcrawlere, der hver tjener specifikke formål inden for dets økosystem. Amazonbot er den primære crawler, der bruges til generel produkt- og serviceforbedring, og den kan bruges til AI-modeltræning. Amzn-SearchBot er specifikt designet til at forbedre søgeoplevelser i Amazon-produkter som Alexa og Rufus, men vigtigt nok crawler den IKKE indhold til generativ AI-modeltræning. Amzn-User understøtter brugerinitierede handlinger, såsom at hente live information, når kunder stiller Alexa spørgsmål, der kræver opdaterede webdata, og den crawler heller ikke til AI-træningsformål. Alle tre crawlere respekterer Robots Exclusion Protocol og overholder robots.txt-direktiver, hvilket giver webstedsejere mulighed for at kontrollere deres adgang. Amazon publicerer IP-adresserne for hver crawler på sin udviklerportal, hvilket gør det muligt for webstedsejere at verificere legitim trafik. Derudover respekterer alle Amazon-crawlere rel=nofollow-direktiver på linkniveau og robots meta-tags på sideniveau, herunder noarchive (forhindrer brug til modeltræning), noindex (forhindrer indeksering) og none (forhindrer begge dele).
| Crawlernavn | Primært formål | AI-modeltræning | User Agent | Nøgle-use cases |
|---|---|---|---|---|
| Amazonbot | Generel produkt-/serviceforbedring | Ja | Amazonbot/0.1 | Overordnet Amazon-serviceforbedring, AI-træning |
| Amzn-SearchBot | Søgeoplevelse-forbedring | Nej | Amzn-SearchBot/0.1 | Alexa-søgning, Rufus-shoppingassistent-indeksering |
| Amzn-User | Brugerinitieret live-datahentning | Nej | Amzn-User/0.1 | Realtids-Alexa-forespørgsler, aktuelle informationsanmodninger |
Amazon respekterer den branchestandardiserede Robots Exclusion Protocol (RFC 9309), hvilket betyder, at webstedsejere kan kontrollere Amazonbot-adgang gennem deres robots.txt-fil. Amazon henter robots.txt-filer på værtsniveau fra roden af dit domæne (f.eks. example.com/robots.txt) og vil bruge en cached kopi fra de sidste 30 dage, hvis filen ikke kan hentes. Ændringer af din robots.txt-fil afspejles typisk inden for cirka 24 timer i Amazons systemer. Protokollen understøtter standard user-agent- og allow/disallow-direktiver, hvilket giver granulær kontrol over, hvilke crawlere der kan tilgå specifikke mapper eller filer. Det er dog vigtigt at bemærke, at Amazon-crawlere IKKE understøtter crawl-delay-direktivet, så denne parameter vil blive ignoreret, hvis den inkluderes i din robots.txt-fil.
Her er et eksempel på, hvordan du kontrollerer Amazonbot-adgang:
# Bloker Amazonbot fra at crawle hele dit websted
User-agent: Amazonbot
Disallow: /
# Tillad Amzn-SearchBot for søgesynlighed
User-agent: Amzn-SearchBot
Allow: /
# Bloker en specifik mappe fra Amazonbot
User-agent: Amazonbot
Disallow: /private/
# Tillad alle andre crawlere
User-agent: *
Disallow: /admin/
Webstedsejere bekymret over bot-trafik bør verificere, at crawlere der hævder at være Amazonbot, faktisk er legitime Amazon-crawlere. Amazon leverer en verificeringsproces ved hjælp af DNS-opslag til at bekræfte autentisk Amazonbot-trafik. For at verificere en crawlers legitimitet, find først den tilgående IP-adresse fra dine serverlogfiler, udfør derefter et omvendt DNS-opslag på denne IP-adresse ved hjælp af host-kommandoen. Det hentede domænenavn bør være et subdomæne af crawl.amazonbot.amazon. Udfør derefter et fremadrettet DNS-opslag på det hentede domænenavn for at verificere, at det resolver tilbage til den originale IP-adresse. Denne tovejs verificeringsproces hjælper med at forhindre spoofing-angreb, da ondsindede aktører potentielt kunne sætte omvendte DNS-records til at efterligne Amazonbot. Amazon publicerer verificerede IP-adresser for alle sine crawlere på udviklerportalen på developer.amazon.com/amazonbot/ip-addresses/, hvilket giver et yderligere referencepunkt til verificering.
Eksempel på verificeringsproces:
$ host 12.34.56.789
789.56.34.12.in-addr.arpa domain name pointer 12-34-56-789.crawl.amazonbot.amazon.
$ host 12-34-56-789.crawl.amazonbot.amazon
12-34-56-789.crawl.amazonbot.amazon has address 12.34.56.789
Hvis du har spørgsmål om Amazonbot eller har brug for at rapportere mistænkelig aktivitet, kontakt Amazon direkte på amazonbot@amazon.com og inkluder relevante domænenavne i din besked.
Der eksisterer en kritisk skelnen mellem Amazons crawlere vedrørende AI-modeltræning. Amazonbot kan bruges til at træne Amazons kunstige intelligensmodeller, hvilket gør den relevant for indholdsskabere bekymret over, at deres arbejde bruges til AI-træningsformål. I modsætning hertil crawler Amzn-SearchBot og Amzn-User eksplicit IKKE indhold til generativ AI-modeltræning, og fokuserer udelukkende på at forbedre søgeoplevelser og understøtte brugerforespørgsler. Hvis du vil forhindre dit indhold i at blive brugt til AI-modeltræning, kan du bruge robots meta-tagget noarchive i din sides HTML-header, som instruerer Amazonbot om ikke at bruge siden til modeltræningsformål. Denne skelnen er vigtig for udgivere, skabere og webstedsejere, der ønsker at opretholde kontrol over, hvordan deres indhold bruges i AI-træningspipelinen, mens de stadig tillader deres indhold at optræde i Amazon-søgeresultater og Rufus-anbefalinger.
Rufus er Amazons avancerede AI-shoppingassistent, der udnytter webcrawling og AI-teknologi til at levere personaliserede shoppinganbefalinger og assistance. Mens Amazonbot bidrager til Amazons overordnede AI-infrastruktur, bruger Rufus specifikt Amzn-SearchBot til at indeksere produktinformation og webindhold relevant for shopping-forespørgsler. Rufus er bygget på Amazon Bedrock og udnytter avancerede store sprogmodeller, herunder Anthropic Claude Sonnet og Amazon Nova, kombineret med en custom model trænet på Amazons omfattende produktkatalog, kundeanmeldelser, community Q&As og webinformation. Shoppingassistenten hjælper kunder med at researche produkter, sammenligne muligheder, spore priser, finde tilbud og endda automatisk købe varer, når de når målpriser. Siden lanceringen er Rufus blevet bemærkelsesværdigt populær, med over 250 millioner kunder der bruger den, månedlige aktive brugere op med 149 %, og interaktioner steget 210 % år-over-år. Kunder der bruger Rufus mens de handler, er over 60 % mere tilbøjelige til at foretage et køb under den shopping-session, hvilket demonstrerer den betydelige indvirkning af AI-drevet shoppingassistance på forbrugeradfærd.
Webstedsejere bør udvikle en strategisk tilgang til at håndtere Amazons crawlere baseret på deres specifikke forretningsmål og indholdspolitikker:
noarchive robots meta-tagget eller bloker den helt via robots.txtamazonbot@amazon.com med dine domæneinformationer for personlig vejledning, hvis du har specifikke bekymringer eller spørgsmål om, hvordan Amazon-crawlere interagerer med dit webstedAmazonbot er Amazons generelle crawler, der bruges til at forbedre produkter og tjenester, og den kan bruges til AI-modeltræning. Amzn-SearchBot er specifikt designet til søgeoplevelser i Alexa og Rufus, og den crawler eksplicit IKKE til AI-modeltræning. Hvis du vil forhindre AI-træningsbrug, bloker Amazonbot, men tillad Amzn-SearchBot for søgesynlighed.
Tilføj følgende linjer til din robots.txt-fil i roden af dit domæne: User-agent: Amazonbot efterfulgt af Disallow: /. Dette vil forhindre Amazonbot i at crawle hele dit websted. Du kan også bruge Disallow: /specific-path/ til kun at blokere bestemte mapper.
Ja, Amazonbot kan bruges til at træne Amazons kunstige intelligensmodeller. Hvis du vil forhindre dette, brug robots meta-tagget i din sides HTML-header, som instruerer Amazonbot om ikke at bruge siden til modeltræning.
Udfør et omvendt DNS-opslag på crawlerens IP-adresse og verificer, at domænet er et subdomæne af crawl.amazonbot.amazon. Udfør derefter et fremadrettet DNS-opslag for at bekræfte, at domænet resolver tilbage til den originale IP. Du kan også tjekke Amazons publicerede IP-adresser på developer.amazon.com/amazonbot/ip-addresses/.
Brug standard robots.txt-syntaks: User-agent: Amazonbot til at målrette crawleren, efterfulgt af Disallow: / for at blokere al adgang eller Disallow: /path/ for at blokere specifikke mapper. Du kan også bruge Allow: / for eksplicit at tillade adgang.
Amazon afspejler typisk robots.txt-ændringer inden for cirka 24 timer. Amazon henter din robots.txt-fil regelmæssigt og vedligeholder en cached kopi i op til 30 dage, så ændringer kan tage en hel dag at propagere gennem deres systemer.
Ja, absolut. Du kan oprette separate regler for hver crawler i din robots.txt-fil. For eksempel, tillad Amzn-SearchBot med User-agent: Amzn-SearchBot og Allow: /, mens du blokerer Amazonbot med User-agent: Amazonbot og Disallow: /.
Kontakt Amazon direkte på amazonbot@amazon.com. Inkluder altid dit domænenavn og eventuelle relevante detaljer om din bekymring i din besked. Amazons supportteam kan give personlig vejledning til din specifikke situation.
Spor nævnelser af dit brand på tværs af AI-systemer som Alexa, Rufus og Google AI Overviews med AmICited - den førende platform til overvågning af AI-svar.
Komplet guide til PerplexityBot crawleren – forstå hvordan den fungerer, styr adgang, overvåg citater og optimer for synlighed på Perplexity AI. Lær om stealth ...

Få indsigt i hvordan AI-crawlere som GPTBot og ClaudeBot fungerer, hvordan de adskiller sig fra traditionelle søgemaskinecrawlere, og hvordan du optimerer dit s...

Lær om PerplexityBot, Perplexitys webcrawler, der indekserer indhold til dens AI-svarmotor. Forstå hvordan den fungerer, overholdelse af robots.txt, og hvordan ...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.