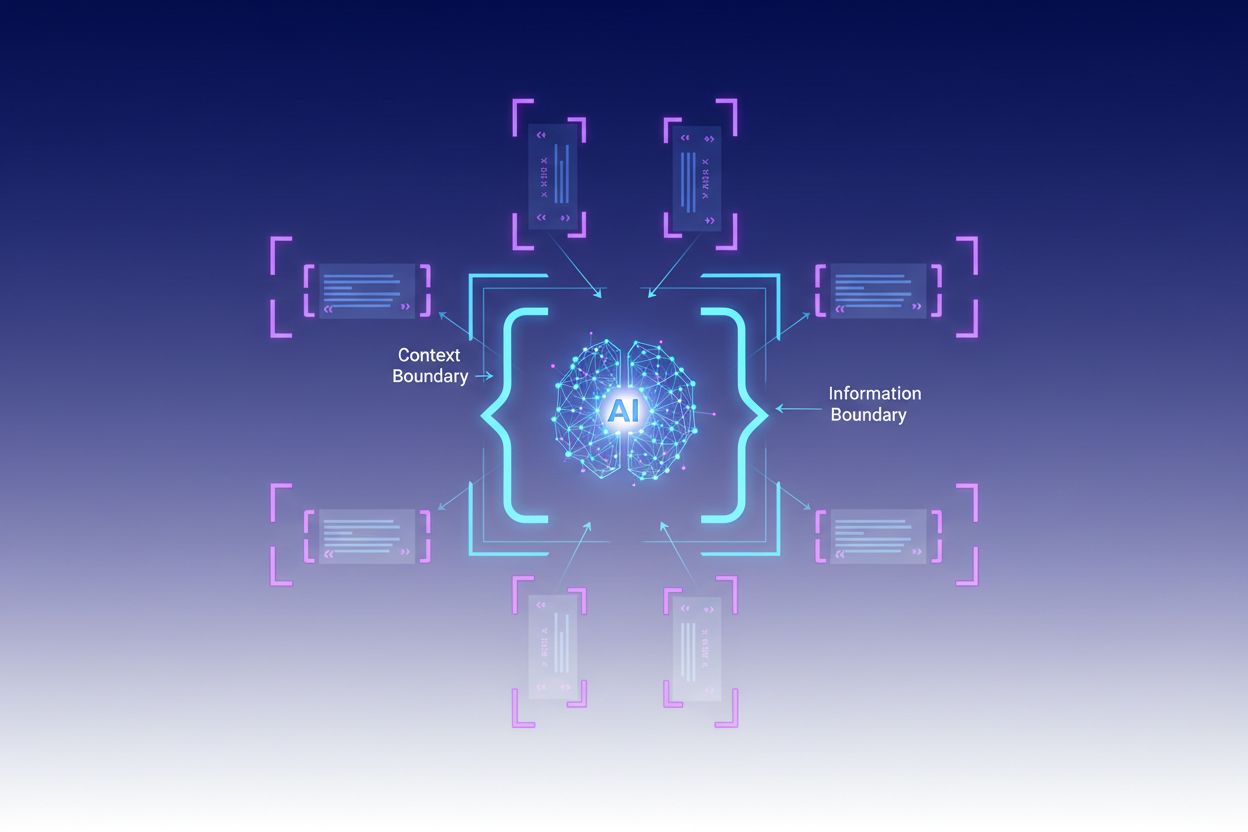
Konstekstuel indramning er en indholdsoptimeringsteknik, der etablerer klare grænser omkring information for at forhindre AI-misforståelser og hallucinationer. Den bruger eksplicitte afgrænsere og kontekstsmarkører for at sikre, at AI-modeller forstår præcist, hvor relevant information begynder og slutter, og forhindrer generering af svar baseret på antagelser eller opdigtede detaljer.
Konstekstuel indramning
Konstekstuel indramning er en indholdsoptimeringsteknik, der etablerer klare grænser omkring information for at forhindre AI-misforståelser og hallucinationer. Den bruger eksplicitte afgrænsere og kontekstsmarkører for at sikre, at AI-modeller forstår præcist, hvor relevant information begynder og slutter, og forhindrer generering af svar baseret på antagelser eller opdigtede detaljer.
Hvad er konstekstuel indramning?
Konstekstuel indramning er en indholdsoptimeringsteknik, der etablerer klare grænser omkring information for at forhindre AI-misforståelser og hallucinationer. Denne metode involverer brug af eksplicitte afgrænsere—såsom XML-tags, markdown-overskrifter eller specialtegn—til at markere begyndelsen og slutningen af specifikke informationsblokke og dermed skabe det, eksperter kalder en “kontekstgrænse”. Ved at strukturere prompts og data med disse tydelige markører sikrer udviklere, at AI-modeller præcist forstår, hvor relevant information begynder og slutter, og forhindrer modellen i at generere svar baseret på antagelser eller opdigtede detaljer. Konstekstuel indramning repræsenterer en udvikling af traditionel prompt engineering og rækker ind i den bredere disciplin kontekst engineering, som fokuserer på at optimere al information leveret til et LLM for at opnå ønskede resultater. Teknikken er særligt værdifuld i produktionsmiljøer, hvor nøjagtighed og konsistens er afgørende, da den giver matematiske og strukturelle værn, der guider AI-adfærd uden at kræve kompleks betinget logik.
Hallucinationsproblemet
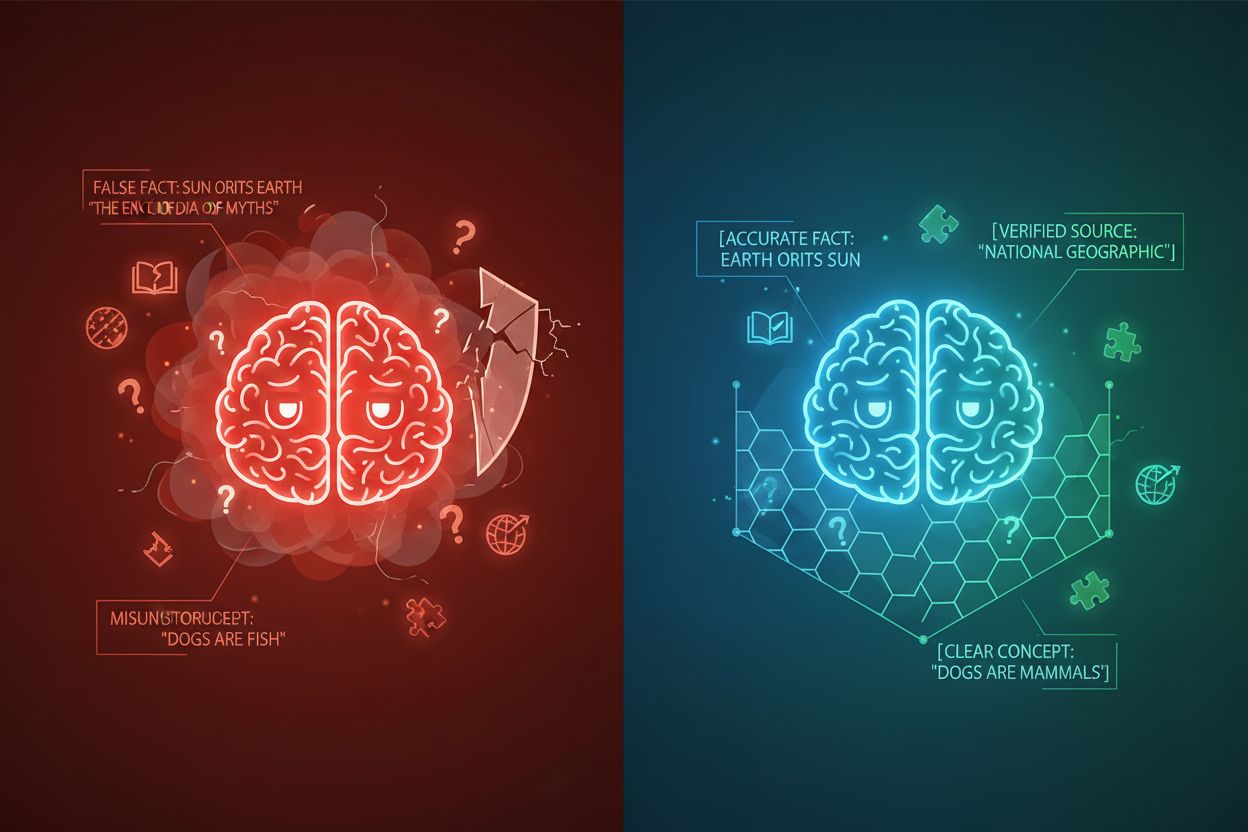
AI-hallucination opstår, når sprogmodeller genererer svar, der ikke er forankret i faktuel information eller den specifikke kontekst, der er givet, hvilket resulterer i falske fakta, vildledende udsagn eller henvisninger til ikke-eksisterende kilder. Forskning viser, at chatbots opfinder fakta cirka 27% af tiden, hvor 46% af deres tekster indeholder faktuelle fejl, mens ChatGPT’s journalistiske citater var forkerte 76% af tiden. Disse hallucinationer stammer fra flere kilder: modeller kan lære mønstre fra biased eller ufuldstændige træningsdata, misforstå forholdet mellem tokens eller mangle tilstrækkelige begrænsninger, der begrænser mulige outputs. Konsekvenserne er alvorlige på tværs af brancher—i sundhedssektoren kan hallucinationer føre til forkerte diagnoser og unødvendige medicinske indgreb; i juridiske sammenhænge kan de resultere i opdigtede sagscitater (som set i Mata v. Avianca-sagen, hvor en advokat blev sanktioneret for at bruge ChatGPT’s falske juridiske citater); i erhvervslivet spildes ressourcer gennem fejlbehæftet analyse og prognoser. Det grundlæggende problem er, at uden klare kontekstgrænser arbejder AI-modeller i et informationsvakuum, hvor de er mere tilbøjelige til at “udfylde hullerne” med plausible, men unøjagtige informationer og behandler hallucination som en funktion frem for en fejl.
Hallucinationstype
Hyppighed
Indvirkning
Eksempel
Faktuelle unøjagtigheder
27-46%
Spredning af misinformation
Falske produktegenskaber
Kildeopdigtning
76% (citater)
Tab af troværdighed
Ikke-eksisterende citater
Misforståede koncepter
Varierende
Forkert analyse
Forkerte juridiske præcedenser
Bias-mønstre
Løbende
Diskriminerende outputs
Stereotypiske svar
Ready to Monitor Your AI Visibility?
Track how AI chatbots mention your brand across ChatGPT, Perplexity, and other platforms.
Effektiviteten af konstekstuel indramning hviler på fem grundlæggende principper:
Afgrænserbrug: Benyt konsistente, entydige markører (XML-tags som <context>, markdown-overskrifter eller specialtegn) til tydeligt at adskille informationsblokke og forhindre, at modellen forveksler grænser mellem forskellige datakilder eller instruktionstyper.
Kontekstvinduesstyring: Fordel strategisk tokens mellem systeminstruktioner, brugerinput og hentet viden, så den mest relevante information optager modellens begrænsede opmærksomhedsbudget, mens mindre vigtige detaljer filtreres eller hentes efter behov.
Informationshierarki: Etabler klare prioritetsniveauer for forskellige informationstyper, så modellen kan se, hvilke data der skal behandles som autoritative kilder versus supplerende kontekst, og forhindre, at primære og sekundære informationer vægtes ens.
Grænsedefinition: Angiv eksplicit, hvilken information modellen skal tage i betragtning, og hvad den skal ignorere, så der skabes hårde stop, der forhindrer modellen i at ekstrapolere ud over de givne data eller antage noget om ikke nævnt information.
Omfangsmarkører: Brug strukturelle elementer til at angive omfanget af instruktioner, eksempler og data, så det er klart, om vejledningen gælder globalt, for specifikke sektioner eller kun for bestemte typer forespørgsler.
Implementeringsteknikker
Implementering af konstekstuel indramning kræver omhyggelig opmærksomhed på, hvordan information struktureres og præsenteres for AI-modeller. Struktureret inputformatering med JSON- eller XML-skemaer giver eksplicitte feltdefinitioner, der guider modeladfærd—for eksempel skaber indpakning af brugerforespørgsler i <user_query>-tags og forventede outputs i <expected_output>-tags entydige grænser. Systemprompter bør organiseres i adskilte sektioner med markdown-overskrifter eller XML-tags: <background_information>, <instructions>, <tool_guidance> og <output_description> tjener hver deres formål og hjælper modellen med at forstå informationshierarkiet. Få-skuds eksempler bør indeholde indrammet kontekst, der præcist viser, hvordan modellen skal strukturere sine svar, med tydelige afgrænsere omkring input og output. Værktøjsdefinitioner drager fordel af eksplicitte parameterbeskrivelser og anvendelsesbegrænsninger, så modellen ikke misbruger værktøjer eller anvender dem uden for deres tilsigtede omfang. Retrieval-Augmented Generation (RAG)-systemer kan implementere konstekstuel indramning ved at indramme hentede dokumenter i kildemarkører (<source>document_name</source>) og bruge grounding scores til at verificere, at genererede svar holder sig inden for grænserne af den hentede information. For eksempel fungerer CustomGPT’s kontekstgrænsefunktion ved at træne modeller udelukkende på uploadede datasæt, så svar aldrig bevæger sig ud over den givne vidensbase—en praktisk implementering af konstekstuel indramning på arkitekturniveau.
Stay Updated on AI Visibility Trends
Get the latest insights on AI mentions, brand monitoring, and optimization strategies.
Konstekstuel indramning vs. andre tilgange
Selvom konstekstuel indramning deler ligheder med beslægtede teknikker, indtager den en særskilt position i AI engineering-landskabet. Basal prompt engineering fokuserer primært på at udforme effektive instruktioner og eksempler, men mangler den systematiske tilgang til at håndtere alle kontekstelementer, som konstekstuel indramning tilbyder. Kontekst engineering, den bredere disciplin, omfatter konstekstuel indramning som ét element blandt mange—det inkluderer prompt-optimering, værktøjsdesign, hukommelsesstyring og dynamisk konteksthentning, hvilket gør det til en overbygning på konstekstuel indramnings mere fokuserede tilgang. Simpel instruktionsopfølgning er afhængig af modellens evne til at forstå naturlige sprog-instruktioner uden eksplicitte strukturelle grænser, hvilket ofte fejler, når instruktionerne er komplekse, eller når modellen støder på tvetydige situationer. Guardrails og valideringssystemer opererer på outputniveau og tjekker svar efter generering, hvorimod konstekstuel indramning arbejder på inputniveau for at forhindre hallucinationer, før de opstår. Den væsentligste forskel er, at konstekstuel indramning er forebyggende og strukturel—den former det informationslandskab, modellen arbejder inden for—i stedet for at være korrektiv eller reaktiv, hvilket gør den mere effektiv og pålidelig til at bevare nøjagtighed i produktionssystemer.
Virkelige anvendelser
Konstekstuel indramning giver målbar værdi på tværs af forskellige anvendelser. Kundeservicechatbots bruger kontekstgrænser til at begrænse svar til virksomhedsgodkendte vidensbaser og forhindre, at agenter opfinder produktegenskaber eller giver uautoriserede løfter. Systemer til analyse af juridiske dokumenter indrammer relevant retspraksis, lovtekster og præcedenser, så AI kun henviser til verificerede kilder og ikke opfinder juridiske citater. Medicinske AI-systemer implementerer stramme kontekstgrænser omkring kliniske retningslinjer, patientdata og godkendte behandlingsprotokoller og forhindrer farlige hallucinationer, der kan skade patienter. Indholdsgenereringsplatforme bruger konstekstuel indramning til at håndhæve brandretningslinjer, tonekrav og faktuelle begrænsninger, så genereret indhold stemmer overens med organisatoriske standarder. Forsknings- og analysetools indrammer primære kilder, datasæt og verificeret information, så AI kan syntetisere indsigter, samtidig med at det sikres, at kilder tilskrives korrekt, og opfindelse af falske statistikker eller undersøgelser undgås. AmICited.com eksemplificerer dette princip ved at overvåge, hvordan AI-systemer citerer og refererer brands på tværs af GPTs, Perplexity og Google AI Overviews—grundlæggende ved at spore, om AI-modeller holder sig inden for passende kontekstgrænser, når de omtaler bestemte virksomheder eller produkter, og hjælper organisationer med at forstå, om AI-systemer hallucinere om deres brand eller repræsenterer deres information præcist.
Best practices og implementeringsstrategi
Succesfuld implementering af konstekstuel indramning kræver overholdelse af gennemprøvede best practices:
Start med minimal kontekst: Begynd med det mindst mulige informationssæt, der er nødvendigt for præcise svar, og udvid kun, når test afslører huller, for at forhindre kontekstforurening og bevare modellens fokus.
Brug konsistente afgrænsermønstre: Etabler og vedligehold ensartede afgrænserkonventioner i hele dit system, så det bliver lettere for modellen at genkende grænser og reducere forvirring fra inkonsekvent formatering.
Test og valider grænser: Test systematisk, om modellen respekterer definerede grænser ved at forsøge at få den til at bevæge sig ud over dem, så du kan identificere og lukke huller før udrulning.
Overvåg for kontekstdrift: Følg løbende, om modellens svar forbliver inden for de tiltænkte grænser over tid, da modeladfærd kan ændre sig ved forskellige inputmønstre eller når vidensbaser udvikler sig.
Implementér feedbackloops: Skab mekanismer, hvor brugere eller menneskelige anmeldere kan rapportere tilfælde, hvor modellen har overskredet sine grænser, og brug denne feedback til at justere kontekstdefinitioner og forbedre fremtidig ydeevne.
Versionér dine kontekstdefinitioner: Behandl kontekstgrænser som kode, vedligehold versionshistorik og dokumentation for ændringer, så du kan rulle tilbage, hvis nye grænsedefinitioner giver dårligere resultater.
Værktøjer og platforme, der understøtter konstekstuel indramning
Flere platforme har indbygget konstekstuel indramning i deres kernefunktioner. CustomGPT.ai implementerer kontekstgrænser gennem deres “kontekstgrænse”-funktion, som fungerer som en beskyttende mur, der sikrer, at AI kun bruger data leveret af brugeren og aldrig bevæger sig ind i generel viden eller opfinder information—denne tilgang har vist sig effektiv for organisationer som MIT, der kræver absolut nøjagtighed i videnslevering. Anthropic’s Claude fremhæver kontekst engineering-principper og leverer detaljeret dokumentation om, hvordan man strukturerer prompts, styrer kontekstvinduer og implementerer værn, der holder svar inden for definerede grænser. AWS Bedrock Guardrails tilbyder automatiserede ræsonnementstjek, der verificerer genereret indhold mod matematiske og logikbaserede regler, hvor grounding scores angiver, om svar holder sig inden for kildematerialet (scores over 0,85 kræves til finansielle anvendelser). Shelf.io tilbyder RAG-løsninger med kontekststyringsmuligheder, så organisationer kan implementere retrieval-augmented generation samtidig med at stramme grænser omkring, hvilke informationer modellen kan tilgå og referere til, opretholdes. AmICited.com spiller en komplementær rolle ved at overvåge, hvordan AI-systemer citerer og refererer til dit brand på tværs af flere AI-platforme, så du kan forstå, om AI-modeller respekterer passende kontekstgrænser, når de omtaler din organisation, eller om de holder sig inden for præcis, verificeret information om dit brand—grundlæggende ved at give indsigt i, om konstekstuel indramning fungerer effektivt i praksis.
Ofte stillede spørgsmål
Hvad er forskellen på konstekstuel indramning og prompt engineering?
Prompt engineering fokuserer primært på at udforme effektive instruktioner og eksempler, mens konstekstuel indramning er en systematisk tilgang til at håndtere alle kontekstelementer gennem eksplicitte afgrænsere og grænser. Konstekstuel indramning er mere struktureret og forebyggende og arbejder på inputniveau for at forhindre hallucinationer, før de opstår, hvorimod prompt engineering er bredere og omfatter forskellige optimeringsteknikker.
Hvordan forhindrer konstekstuel indramning AI-hallucinationer?
Konstekstuel indramning forhindrer hallucinationer ved at etablere klare informationsgrænser med afgrænsere som XML-tags eller markdown-overskrifter. Dette fortæller AI-modellen præcis, hvilken information den skal tage i betragtning, og hvad den skal ignorere, så den ikke opfinder detaljer eller antager noget om ikke nævnt information. Ved at begrænse modellens opmærksomhed til definerede grænser reduceres sandsynligheden for at generere falske fakta eller ikke-eksisterende kilder.
Hvilke afgrænsere er de mest almindelige i konstekstuel indramning?
Almindelige afgrænsere inkluderer XML-tags (som og ), markdown-overskrifter (# Sektionnavn), specialtegn (---, ===) og strukturerede formater som JSON eller YAML. Det vigtigste er konsistens—brug af de samme afgrænsermønstre i hele dit system hjælper modellen med at genkende grænser pålideligt og reducerer forvirring fra inkonsekvent formatering.
Kan konstekstuel indramning bruges med alle AI-modeller?
Principperne for konstekstuel indramning kan anvendes på de fleste moderne sprogmodeller, selvom effektiviteten varierer. Modeller, der er trænet til bedre at følge instruktioner (som Claude, GPT-4 og Gemini), har en tendens til mere pålideligt at respektere grænser. Teknikken fungerer bedst sammen med modeller, der understøtter strukturerede output og er trænet på varieret, velstruktureret data.
Hvordan implementerer jeg konstekstuel indramning i mine AI-applikationer?
Start med at organisere dine systemprompter i adskilte sektioner med tydelige afgrænsere. Strukturér input og output med JSON- eller XML-skemaer. Brug konsistente afgrænsermønstre hele vejen igennem. Implementér få-skuds eksempler, der viser modellen præcis, hvordan den skal respektere grænser. Test grundigt for at sikre, at modellen respekterer de definerede grænser, og overvåg ydeevnen over tid for at opdage kontekstdrift.
Hvad er ydelsesmæssige konsekvenser af at bruge konstekstuel indramning?
Konstekstuel indramning kan øge tokenforbruget en smule på grund af ekstra afgrænsere og strukturelle markører, men dette opvejes typisk af forbedret nøjagtighed og færre hallucinationer. Teknikken forbedrer faktisk effektiviteten ved at forhindre modellen i at spilde tokens på opdigtet information. I produktionssystemer opvejer nøjagtighedsgevinsterne langt den minimale token-overhead.
Hvordan relaterer konstekstuel indramning sig til Retrieval-Augmented Generation (RAG)?
Konstekstuel indramning og RAG er komplementære teknikker. RAG henter relevant information fra eksterne kilder, mens konstekstuel indramning sikrer, at modellen holder sig inden for grænserne af den hentede information. Sammen skaber de et kraftfuldt system, hvor modellen kan få adgang til ekstern viden, men kun refererer til verificerede, hentede kilder.
Flere platforme har indbygget understøttelse: CustomGPT.ai tilbyder kontekst-grænsefunktioner, Anthropic's Claude leverer kontekst engineering-dokumentation og understøttelse af struktureret output, AWS Bedrock Guardrails inkluderer automatiserede tjek af ræsonnement, og Shelf.io tilbyder RAG med kontekststyring. AmICited.com overvåger, hvordan AI-systemer citerer dit brand og hjælper med at verificere, at konstekstuel indramning fungerer effektivt.
Overvåg hvordan AI refererer til dit brand
Konstekstuel indramning sikrer, at AI-systemer giver præcis information om dit brand. Brug AmICited til at spore, hvordan AI-modeller citerer og refererer til dit indhold på tværs af GPTs, Perplexity og Google AI Overviews.
Hvad er et kontekstvindue, og hvorfor bør indholdsmarkedsførere gå op i det?
Fællesskabsdiskussion om AI-kontekstvinduer og deres betydning for indholdsmarkedsføring. Forståelse af, hvordan kontekstgrænser påvirker AI's behandling af dit...
Kontekstvindue forklaret: det maksimale antal tokens, en LLM kan behandle ad gangen. Lær hvordan kontekstvinduer påvirker AI-nøjagtighed, hallucinationer og bra...
Lær hvad kontekstvinduer er i AI-sprogmodeller, hvordan de fungerer, deres indvirkning på modelydelse, og hvorfor de er vigtige for AI-drevne applikationer og o...
9 min læsning
Cookie Samtykke Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.