
Hvordan Forstår AI-systemer Enhedsrelationer?
Lær, hvordan AI-systemer identificerer, udtrækker og forstår relationer mellem enheder i tekst. Oplev teknikker til udtrækning af enhedsrelationer, NLP-metoder ...
8 min læsning

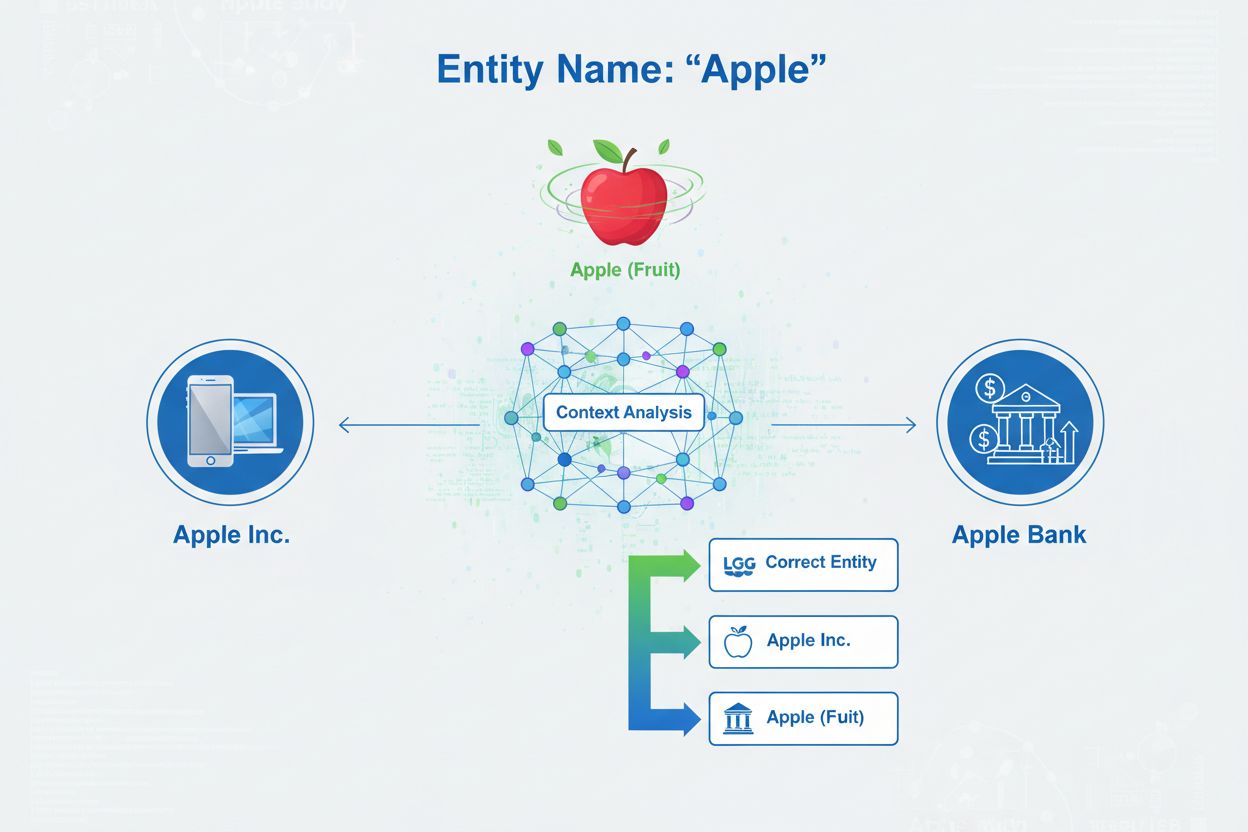
Entitetsafklaring er processen med at bestemme, hvilken specifik enhed en bestemt omtale henviser til, når flere enheder deler det samme navn. Det hjælper AI-systemer med nøjagtigt at forstå og citere indhold ved at løse tvetydighed i navngivne enhedsreferencer, hvilket sikrer, at omtaler af ‘Apple’ korrekt identificerer, om der refereres til Apple Inc., frugten eller en anden enhed med samme navn.
Entitetsafklaring er processen med at bestemme, hvilken specifik enhed en bestemt omtale henviser til, når flere enheder deler det samme navn. Det hjælper AI-systemer med nøjagtigt at forstå og citere indhold ved at løse tvetydighed i navngivne enhedsreferencer, hvilket sikrer, at omtaler af 'Apple' korrekt identificerer, om der refereres til Apple Inc., frugten eller en anden enhed med samme navn.
Entitetsafklaring er processen med at bestemme, hvilken specifik enhed en bestemt omtale henviser til, når flere enheder deler det samme navn eller lignende referencer. I forbindelse med kunstig intelligens og naturlig sprogbehandling (NLP) sikrer entitetsafklaring, at når et AI-system støder på en navngiven enhed i tekst, identificerer det korrekt, hvilket virkelighedsobjekt, person, organisation eller sted der henvises til. Dette adskiller sig grundlæggende fra navngivet enhedsgenkendelse (NER), som blot identificerer, at en enhed findes og klassificerer den i en kategori som “person”, “organisation” eller “sted”. Hvor NER besvarer spørgsmålet “Er der en enhed her?”, besvarer entitetsafklaring “Hvilken specifik enhed er dette?” For eksempel, når sætningen “Apple was the brain-child of Steve Jobs” behandles, identificerer NER “Apple” som en organisation, men entitetsafklaring afgør, om dette henviser til Apple Inc., teknologivirksomheden, eller potentielt en anden enhed med samme navn. Denne sondring er afgørende for AI-systemer, der skal forstå og citere indhold nøjagtigt, hvorfor AmICited.com overvåger, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews håndterer entitetsafklaring, når de genererer svar om brands og organisationer.
Det grundlæggende problem, som entitetsafklaring løser, er tvetydighed—det faktum, at mange enhedsnavne kan referere til flere forskellige virkelighedsobjekter. Denne tvetydighed skaber betydelige udfordringer for AI-systemer, der forsøger at forstå og generere nøjagtigt indhold. Ifølge Stanford AI Index 2024 indeholder over 18% af LLM-uddata, der involverer brandenheder, enten hallucinationer eller fejlagtige tilskrivninger, hvilket betyder, at AI-systemer ofte forveksler en enhed med en anden eller genererer falsk information om enheder. Denne fejlrente har alvorlige konsekvenser for brandrepræsentation og indholdsnøjagtighed. Når et AI-system fejlagtigt identificerer en enhed, kan det give forkerte oplysninger, tilskrive udsagn til den forkerte organisation eller undlade at citere den korrekte kilde til information.
| Entity Name | Possible Meanings | AI Confusion Rate |
|---|---|---|
| Apple | Tech Company / Fruit / Bank | High |
| Delta | Airlines / Faucet Company / Greek Letter | High |
| Jaguar | Car Manufacturer / Animal Species | Medium |
| Amazon | E-commerce Company / Rainforest / River | High |
| Orange | Color / Fruit / Telecom Company | Medium |
Konsekvenserne af dårlig entitetsafklaring rækker ud over simple faktuelle fejl. For indholdsskabere og brands kan fejlagtig identifikation i AI-genererede svar føre til tabt synlighed, forkert tilskrivning og skade på brandets omdømme. Når en bruger spørger et AI-system om “Delta”, søger de måske information om Delta Airlines, men hvis systemet forveksler det med Delta Faucet Company, får brugeren irrelevante oplysninger. Dette er netop grunden til, at AmICited.com overvåger, hvordan AI-systemer afklarer enheder—for at hjælpe brands med at forstå, om de bliver korrekt identificeret og citeret i AI-genereret indhold på tværs af flere platforme.
Entitetsafklaring fungerer gennem en systematisk proces, der kombinerer flere NLP-teknikker for at løse tvetydighed og korrekt identificere enheder. Forståelsen af denne proces afslører, hvorfor nogle AI-systemer klarer sig bedre end andre med at opretholde citeringsnøjagtighed.
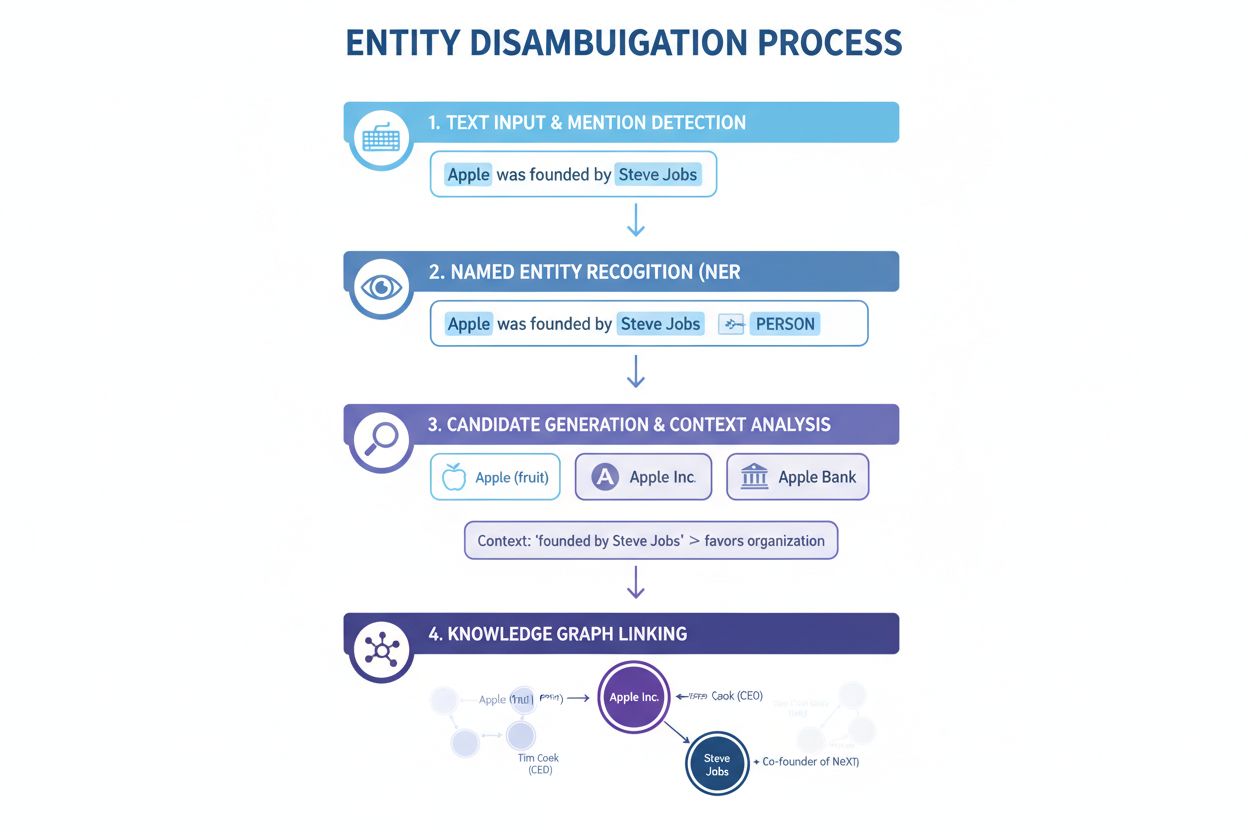
Navngivet enhedsgenkendelse (NER): Det første trin indebærer at identificere og klassificere navngivne enheder i teksten. NER-systemer gennemgår tekstdata og finder omtaler af enheder, som de tildeler til foruddefinerede kategorier såsom person, organisation, sted, produkt eller dato. For eksempel identificerer NER i sætningen “Apple was the brain-child of Steve Jobs” både “Apple” og “Steve Jobs” som enheder og klassificerer dem som henholdsvis organisation og person. Dette grundlæggende trin er essentielt, fordi afklaring ikke kan finde sted, før det er fastslået, hvilke enheder der er til stede i teksten.
Enhedskategorisering: Når enheder er identificeret, skal de kategoriseres mere præcist. Dette indebærer ikke blot bred klassificering, men også forståelse for den specifikke type og kontekst for hver enhed. Systemet analyserer den omgivende tekst for at forstå, om “Apple” optræder i en teknologikontekst (hvilket tyder på Apple Inc.), en madkontekst (frugten) eller en finansiel kontekst (Apple Bank). Denne kontekstuelle analyse indsnævrer mulighederne før selve afklaringstrinnet.
Afklaring: Dette er det centrale trin, hvor systemet bestemmer, hvilken specifik enhed der refereres til. Systemet vurderer flere kandidatenheder, der matcher det identificerede navn, og bruger forskellige signaler—herunder kontekst, enhedsbeskrivelser, semantiske relationer og viden-graf-oplysninger—for at vælge den mest sandsynlige korrekte enhed. For “Apple was the brain-child of Steve Jobs” genkender systemet, at Steve Jobs er stærkt forbundet med Apple Inc., hvilket gør det til det korrekte valg.
Videnbase-linking: Det sidste trin indebærer at linke den afklarede enhed til en unik identifikator i en ekstern videnbase eller viden-graf, såsom Wikidata, Wikipedia eller en proprietær database. Denne linking bekræfter enhedens identitet og beriger teksten med semantisk information, som kan bruges til yderligere behandling og analyse. Enheden tildeles en unik URI (Uniform Resource Identifier), der fungerer som et definitivt referencepunkt.
Forskellige tilgange til entitetsafklaring har udviklet sig over tid, hver med deres egne fordele og begrænsninger. Forståelsen af disse tilgange forklarer, hvorfor moderne AI-systemer varierer i deres afklaringsnøjagtighed.
Regelbaserede tilgange: Disse systemer bruger foruddefinerede sproglige regler og heuristiske mønstre til at afklare enheder. De kan anvende regler som “hvis ‘Apple’ optræder nær ‘iPhone’ eller ‘MacBook’, refererer det til Apple Inc.” eller “hvis ‘Delta’ optræder nær ‘airline’ eller ‘flight’, refererer det til Delta Airlines.” Mens regelbaserede systemer er fortolkelige og ikke kræver store træningsdatasæt, har de svært ved nye kontekster og kan ikke tilpasse sig nye betydninger uden manuelle opdateringer.
Maskinlæringstilgange: Supervised machine learning-modeller lærer af annoterede træningsdata at forudsige den korrekte enhed baseret på kontekstuelle egenskaber. Disse systemer udtrækker egenskaber fra den omgivende tekst og bruger algoritmer som Support Vector Machines eller Random Forests til at klassificere, hvilken enhed der er mest sandsynlig. Maskinlæringsmetoder er mere fleksible end regelbaserede systemer, men kræver omfattende mærkede træningsdata og har muligvis svært ved at generalisere til enheder, de ikke har set før.
Deep learning og transformerbaserede modeller: Moderne entitetsafklaring benytter i stigende grad transformer-arkitekturer som BERT, RoBERTa og specialiserede modeller som GENRE og BLINK. Disse modeller bruger neurale netværk til at forstå kontekst på et dybere niveau og opfange semantiske relationer og sproglige nuancer. Transformer-modeller opnår overlegen ydeevne på standardbenchmarks og håndterer bedre komplekse afklaringssituationer. For eksempel bruger Ontotext’s CEEL (Common English Entity Linking) et transformer-baseret system optimeret til CPU-effektivitet og opnår 96% enhedsgenkendelsesnøjagtighed og 76% enhedslinking-nøjagtighed på standardbenchmarks.
Integration af viden-grafer: Moderne systemer kombinerer i stigende grad maskinlæring med viden-grafer—strukturerede databaser, der repræsenterer enheder og deres relationer. Viden-grafer giver rig kontekstuel information om enheder, deres egenskaber og hvordan de relaterer sig til andre enheder. Ved at forespørge viden-grafer under afklaring kan systemer få adgang til metadata, beskrivelser og relationsinformation, der hjælper med at løse tvetydighed mere præcist.
Entitetsafklaring er blevet uundværlig i adskillige brancher og applikationer, der alle drager fordel af nøjagtig enhedsidentifikation og citering.
Søgemaskiner: Google, Bing og andre søgemaskiner er stærkt afhængige af entitetsafklaring for at levere relevante resultater. Når en bruger søger på “Apple”, skal søgemaskinen afgøre, om brugeren er interesseret i Apple Inc., frugten eller en anden enhed med det navn. Søgemaskiner bruger forespørgselskontekst, brugerhistorik og viden-grafer til at afklare og returnere de mest relevante resultater. Derfor viser søgeresultater for “Apple” typisk teknologivirksomheden først—systemet har lært, at det oftest er den tilsigtede enhed.
Medier og udgivelse: Nyhedsorganisationer og indholdsplatforme bruger entitetsafklaring til at forbedre indholdsopdagelse og linke relaterede artikler. Når en artikel nævner “Apple”, kan systemet automatisk linke til Apple Inc.’s videnbaseindgang, hvilket giver læserne ekstra kontekst og relaterede artikler. Dette øger brugerengagementet og hjælper læserne med at forstå den bredere sammenhæng af nyhedshistorier.
Sundhedssektoren: Medicinske institutioner bruger entitetsafklaring til nøjagtigt at identificere lægemidler, sygdomme og medicinske procedurer i patientjournaler og litteratur. Afklaring af lægemiddelnavne er særlig kritisk—“aspirin” kan referere til det generiske lægemiddel, et specifikt mærke eller en doseringsvariant. Nøjagtig afklaring sikrer, at sundhedspersonale får adgang til korrekte oplysninger, og at patientjournaler organiseres korrekt.
Finansielle tjenester: Investeringsfirmaer og finansanalytikere bruger entitetsafklaring til at spore virksomhedsreferencer i nyheder, regnskaber og markedsdata. Når markedsrisiko analyseres, skal firmaet nøjagtigt identificere alle omtaler af en bestemt virksomhed på tværs af forskellige datakilder. Entitetsafklaring sikrer, at “Apple”-referencer korrekt tilskrives Apple Inc. og ikke andre enheder, hvilket muliggør nøjagtig risikovurdering og porteføljeanalyse.
E-handel: Onlineforhandlere bruger entitetsafklaring til at matche produktomtaler med faktiske produkter i deres kataloger. Når en kunde søger efter “Apple laptop”, skal systemet afklare “Apple” som virksomheden og matche det til relevante produkter. Dette forbedrer søgenøjagtigheden og hjælper kunderne med hurtigere at finde det, de søger.
AmICited.com anvender entitetsafklaringsprincipper til at overvåge, hvordan AI-systemer som ChatGPT, Perplexity og Google AI Overviews håndterer brandomtaler. Ved at spore, om disse systemer korrekt afklarer brandenheder og citerer dem korrekt, hjælper AmICited brands med at forstå deres synlighed og repræsentation i AI-genereret indhold.
Viden-grafer er blevet fundamentale for moderne entitetsafklaringssystemer ved at levere strukturerede repræsentationer af enheder og deres relationer. En viden-graf er i bund og grund en database af enheder (repræsenteret som noder) og relationerne mellem dem (repræsenteret som kanter). Hver enhedsnod indeholder metadata som navn, beskrivelse, type og egenskaber. For eksempel kan “Apple Inc.” i en viden-graf have egenskaber som “grundlagt i 1976”, “hovedkvarter i Cupertino”, “branch: teknologi” og relationer som “grundlagt af Steve Jobs” og “producerer iPhone”.
Når et entitetsafklaringssystem støder på en tvetydig enhedsreference, kan det forespørge viden-grafen for at få adgang til rig kontekstuel information om kandidatenheder. Disse oplysninger hjælper systemet med at træffe mere informerede afklaringsbeslutninger. Hvis systemet for eksempel forsøger at afklare “Apple” og finder, at den omgivende tekst nævner “Steve Jobs”, kan det forespørge viden-grafen og opdage, at Steve Jobs er stærkt forbundet med Apple Inc., hvilket gør det til den mest sandsynlige korrekte enhed. Viden-grafer som Wikidata og Wikipedia giver offentligt tilgængelig enhedsinformation, som mange AI-systemer bruger under inferens. Proprietære viden-grafer bygget af organisationer som Google, Microsoft og andre leverer yderligere domænespecifik information. Integrationen af viden-grafer med maskinlæringsmodeller har markant forbedret entitetsafklaringsnøjagtigheden, da systemer nu kan kombinere lærte mønstre med struktureret faktuel information.
På trods af betydelige fremskridt står entitetsafklaringssystemer over for flere vedvarende udfordringer, der begrænser deres nøjagtighed og anvendelighed.
Polysemi og tvetydighed: Mange enhedsnavne har flere legitime betydninger, og kontekst alene er måske ikke tilstrækkelig for at afklare dem. “Bank” kan referere til en finansiel institution eller bredden af en flod. “Crane” kan betyde en fugl eller en kranmaskine. Nogle enhedsnavne er så tvetydige, at selv mennesker har svært ved at afgøre betydningen uden yderligere kontekst. AI-systemer skal lære at genkende, når konteksten er utilstrækkelig, og håndtere sådanne tilfælde hensigtsmæssigt.
Nye og fremvoksende enheder: Videnbaser og træningsdatasæt bliver forældede, efterhånden som nye enheder opstår. Når en ny virksomhed grundlægges, eller et nyt produkt lanceres, har entitetsafklaringssystemer måske ikke information om det i deres videnbaser. Zero-shot entity linking—evnen til at afklare enheder, der ikke er set under træning—forbliver en udfordring. Systemer skal være i stand til at genkende, at en enhed er ny, og håndtere det hensigtsmæssigt, fremfor at matche den forkert til en eksisterende enhed med lignende navn.
Navnevarianter og stavefejl: Enheder har ofte flere navne, forkortelser og varianter. “United States”, “USA”, “U.S.” og “America” refererer alle til den samme enhed. Stavefejl og tastefejl komplicerer yderligere afklaringen. Systemer skal genkende disse variationer og korrekt kortlægge dem til den kanoniske enhed. Dette er særligt udfordrende i brugergenereret indhold, hvor stavefejl er almindelige.
Ufuldstændige eller forældede data: Videnbaser kan indeholde ufuldstændig information om enheder, eller informationen kan blive forældet, efterhånden som enheder udvikler sig. Et firmas hovedkvarter kan ændres, ledelsen kan skifte, eller en virksomhed kan blive opkøbt. Hvis videnbasen ikke opdateres rettidigt, kan afklaringssystemer benytte forældede oplysninger til at træffe beslutninger.
Skalerbarhed og ydeevne: Behandling af store mængder tekst med høj-nøjagtig entitetsafklaring kræver betydelige computerressourcer. Realtidsafklaring til webskala-applikationer er computerkrævende. Systemer skal balancere nøjagtighed med hastighed og omkostninger, hvilket ofte betyder kompromiser, der reducerer afklaringskvaliteten.
For brands og indholdsskabere er forståelse af entitetsafklaring afgørende for at sikre nøjagtig repræsentation i AI-genereret indhold. Efterhånden som AI-systemer bliver mere indflydelsesrige i, hvordan information opdages og forbruges, skal brands tage proaktive skridt for at sikre, at de afklares og citeres korrekt.
Forudgående afklaringsstrategier: Brands kan implementere strategier, der gør deres enheder lettere for AI-systemer at afklare korrekt. Dette indebærer at skabe klare, distinkte digitale signaler, der hjælper AI-systemer med entydigt at identificere brandet. En vigtig strategi er implementering af strukturerede data med Schema.org-markering og JSON-LD-format på brandets hjemmeside. Disse strukturerede data fortæller AI-systemer eksplicit om brandets identitet, herunder dets officielle navn, beskrivelse, logo, hovedkvarter og andre karakteristika. Når AI-systemer støder på brandnavnet, kan de referere til disse strukturerede data for at bekræfte den korrekte enhed.
Viden-graf-optimering: Brands bør sikre sig en stærk tilstedeværelse i store viden-grafer som Wikidata og Wikipedia. Dette indebærer at oprette eller vedligeholde nøjagtige Wikipedia-artikler, sikre at Wikidata-opføringer er komplette og opdaterede, og bygge relationer mellem brandenheden og relaterede enheder. Jo mere omfattende og nøjagtig brandets viden-graftilstedeværelse er, desto mere information har AI-systemer til rådighed til afklaring.
Kontekstuel indholdsstrategi: Brands kan skabe indhold, der giver klar kontekst om deres identitet og adskiller dem fra andre enheder med lignende navne. Indhold, der eksplicit nævner brandets branche, produkter, stiftere og unikke værditilbud, hjælper AI-systemer med at forstå brandets karakteristika. Dette kontekstuelle indhold bliver en del af de træningsdata og den kontekst, AI-systemer bruger til afklaring.
Citeringsovervågning: Værktøjer som AmICited.com gør det muligt for brands at overvåge, hvordan AI-systemer afklarer og citerer deres brand på tværs af forskellige platforme. Ved at spore, om ChatGPT, Perplexity, Google AI Overviews og andre systemer korrekt identificerer og citerer brandet, kan brands identificere afklaringsfejl og tage korrigerende handling. Denne overvågning er essentiel for at forstå brandets synlighed i den generative AI-tidsalder.
Generative Engine Optimization (GEO): Efterhånden som entitetsafklaring bliver vigtigere for AI-synlighed, bør brands integrere enhedsoptimering i deres bredere GEO-strategi. Dette indebærer at sikre, at brandenheden er klart defineret, veldokumenteret og let at skelne fra konkurrerende enheder. GEO omfatter ikke blot traditionel SEO, men også optimering for, hvordan AI-systemer forstår og repræsenterer brands.
Entitetsafklaring udvikler sig fortsat i takt med, at AI-teknologien skrider frem, og nye udfordringer opstår. Flere tendenser former fremtiden for denne vigtige kapabilitet.
Flersproget entitetsafklaring: Efterhånden som AI-systemer bliver mere globale, er evnen til at afklare enheder på tværs af flere sprog stadigt vigtigere. En persons navn kan staves forskelligt på forskellige sprog, og den samme enhed kan omtales med forskellige navne i forskellige sproglige kontekster. Avancerede flersprogede modeller udvikles til at håndtere entitetsafklaring på tværs af sproggrænser, hvilket muliggør virkelig globale AI-systemer.
Realtidsafklaring i store sprogmodeller: Moderne store sprogmodeller som GPT-4 og Claude inkorporerer i stigende grad realtids-entitetsafklaring under tekstgenerering. I stedet for kun at stole på træningsdata kan disse modeller forespørge viden-grafer og eksterne databaser under inferens for at verificere enhedsinformation og sikre nøjagtig afklaring. Denne kapacitet forbedrer citeringsnøjagtigheden og reducerer hallucinationer.
Forbedret zero-shot learning: Fremtidige entitetsafklaringssystemer vil sandsynligvis opnå bedre resultater på enheder, der ikke er set under træning. Fremskridt indenfor few-shot og zero-shot learning vil gøre det muligt for systemer at afklare nye enheder mere effektivt, hvilket mindsker behovet for hyppig gen-træning og gør systemer mere tilpasningsdygtige til fremvoksende enheder.
Integration med Retrieval-Augmented Generation (RAG): RAG-systemer, der kombinerer sprogmodeller med informationssøgning, bliver stadig mere populære. Disse systemer kan hente relevant enhedsinformation fra videnbaser under tekstgenerering, hvilket forbedrer afklaringsnøjagtighed og citeringskvalitet. Denne integration er et væsentligt skridt fremad for at sikre, at AI-systemer citerer kilder nøjagtigt.
Standardisering og interoperabilitet: Efterhånden som entitetsafklaring bliver kritisk for AI-systemer, vil industristandarder for enhedsrepræsentation og afklaring sandsynligvis opstå. Disse standarder vil muliggøre bedre interoperabilitet mellem forskellige systemer og videnbaser, så AI-systemer nemt kan få adgang til og bruge enhedsinformation på tværs af platforme.
Entitetsafklaring er gået fra at være en nicheopgave inden for NLP til at være en afgørende kapabilitet for at sikre, at AI-systemer forstår og repræsenterer information korrekt. Efterhånden som AI får større indflydelse på, hvordan information opdages og forbruges, vil betydningen af nøjagtig entitetsafklaring kun vokse. For brands, indholdsskabere og organisationer er forståelse og optimering for entitetsafklaring essentielt for at opretholde synlighed og sikre korrekt repræsentation i den generative AI-tidsalder.
Navngivet enhedsgenkendelse identificerer, at en enhed findes i teksten og klassificerer den i kategorier som person, organisation eller sted. Entitetsafklaring går videre ved at bestemme, hvilken specifik enhed der refereres til, når flere enheder deler det samme navn. For eksempel identificerer NER 'Apple' som en organisation, mens entitetsafklaring afgør, om det henviser til Apple Inc., Apple Bank eller en anden enhed.
Entitetsafklaring sikrer, at AI-systemer nøjagtigt forstår, hvilken enhed der diskuteres, og citerer den korrekt. Ifølge Stanford AI Index 2024 indeholder over 18% af LLM-uddata, der involverer brandenheder, hallucinationer eller fejlagtige tilskrivninger. Nøjagtig entitetsafklaring forhindrer AI-systemer i at forveksle en enhed med en anden, hvilket er afgørende for at opretholde brandets omdømme og citeringsnøjagtighed.
Viden-grafer giver struktureret information om enheder og deres relationer. Når et AI-system støder på en tvetydig enhedsreference, kan det forespørge viden-grafen for at få adgang til metadata, beskrivelser og relationsinformation om kandidatenheder. Disse kontekstuelle oplysninger hjælper systemet med at træffe mere informerede afklaringsbeslutninger og vælge den korrekte enhed.
Ja, gennem zero-shot entity linking-metoder. Moderne systemer kan genkende, når en enhed er ny og håndtere det hensigtsmæssigt fremfor fejlagtigt at matche den til en eksisterende enhed. Det er dog stadig en udfordring, og systemer klarer sig bedre, når nye enheder har tydelige kontekstuelle signaler, der adskiller dem fra eksisterende enheder.
Nøjagtig entitetsafklaring sikrer, at dit brand identificeres og citeres korrekt i AI-genererede svar. Når AI-systemer korrekt afklarer dit brand, får brugerne nøjagtig information om din organisation, hvilket forbedrer brandets synlighed og omdømme. Dårlig afklaring kan føre til, at dit brand forveksles med konkurrenter eller andre enheder, hvilket reducerer synligheden og potentielt skader omdømmet.
Nøgleudfordringer inkluderer polysemi (flere betydninger for det samme navn), nye enheder der ikke er i træningsdata, navnevarianter og stavefejl, ufuldstændige eller forældede videnbaser og skalerbarhedsproblemer. Derudover er nogle enhedsnavne iboende tvetydige, og kontekst alene er måske ikke tilstrækkelig til at bestemme den korrekte enhed.
Brands kan implementere strukturerede data med Schema.org-markering, vedligeholde nøjagtige Wikipedia- og Wikidata-opføringer, skabe kontekstrigt indhold, der tydeligt adskiller deres brand, og overvåge, hvordan AI-systemer afklarer deres brand med værktøjer som AmICited. Disse strategier hjælper AI-systemer med at identificere og citere dit brand korrekt.
Kontekst er afgørende for entitetsafklaring. Den omgivende tekst, relaterede enheder og semantiske relationer giver alle signaler, der hjælper AI-systemer med at bestemme, hvilken enhed der refereres til. For eksempel, hvis 'Apple' optræder nær 'Steve Jobs' og 'teknologi', kan systemet bruge denne kontekst til at afklare det som Apple Inc. frem for frugten.
Spor entitetsafklaringens nøjagtighed på tværs af AI-platforme og sikr, at dit brand identificeres og citeres korrekt i AI-genererede svar.
Lær, hvordan AI-systemer identificerer, udtrækker og forstår relationer mellem enheder i tekst. Oplev teknikker til udtrækning af enhedsrelationer, NLP-metoder ...

Udforsk hvordan AI-systemer genkender og bearbejder enheder i tekst. Lær om NER-modeller, transformer-arkitekturer og virkelige anvendelser af enhedsforståelse....

Entity Recognition er en AI NLP-egenskab, der identificerer og kategoriserer navngivne enheder i tekst. Lær hvordan det fungerer, dets anvendelser i AI-overvågn...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.