
AI-indeksdækning
Lær hvad AI-indeksdækning er, og hvorfor det er vigtigt for din virksomheds synlighed i ChatGPT, Google AI Overviews og Perplexity. Opdag tekniske faktorer, bes...
7 min læsning

Indeksdækning henviser til procentdelen og status for hjemmesidens sider, der er blevet opdaget, crawlet og inkluderet i en søgemaskines indeks. Det måler, hvilke sider der er berettigede til at vises i søgeresultaterne, og identificerer tekniske problemer, der forhindrer indeksering.
Indeksdækning henviser til procentdelen og status for hjemmesidens sider, der er blevet opdaget, crawlet og inkluderet i en søgemaskines indeks. Det måler, hvilke sider der er berettigede til at vises i søgeresultaterne, og identificerer tekniske problemer, der forhindrer indeksering.
Indeksdækning er målet for, hvor mange sider fra dit website der er blevet opdaget, crawlet og inkluderet i en søgemaskines indeks. Det repræsenterer procentdelen af dit websites sider, som er berettigede til at dukke op i søgeresultaterne, og identificerer hvilke sider, der oplever tekniske problemer, som forhindrer indeksering. I bund og grund besvarer indekstdækning det afgørende spørgsmål: “Hvor meget af mit website kan søgemaskiner faktisk finde og rangere?” Denne måling er fundamental for at forstå dit websites synlighed i søgemaskiner og overvåges gennem værktøjer som Google Search Console, som giver detaljerede rapporter om indekserede sider, ekskluderede sider og sider med fejl. Uden korrekt indekstdækning forbliver selv det mest optimerede indhold usynligt for både søgemaskiner og brugere, der søger efter din information.
Indeksdækning handler ikke kun om kvantitet – det handler om at sikre, at de rigtige sider bliver indekseret. Et website kan have tusindvis af sider, men hvis mange af dem er dubletter, tyndt indhold eller sider, der er blokeret af robots.txt, kan den faktiske indekstdækning være betydeligt lavere end forventet. Denne sondring mellem det samlede antal sider og indekserede sider er afgørende for at udvikle en effektiv SEO-strategi. Organisationer, der regelmæssigt overvåger indekstdækning, kan identificere og rette tekniske problemer, før de påvirker organisk trafik, hvilket gør det til en af de mest handlingsorienterede metrics i teknisk SEO.
Begrebet indekstdækning opstod, efterhånden som søgemaskiner udviklede sig fra simple crawlers til sofistikerede systemer, der kunne behandle millioner af sider dagligt. I SEO’s tidlige dage havde webmastere begrænset indsigt i, hvordan søgemaskiner interagerede med deres sider. Google Search Console, oprindeligt lanceret som Google Webmaster Tools i 2006, revolutionerede denne gennemsigtighed ved at give direkte feedback om crawling- og indekseringsstatus. Indeksdækningsrapporten (tidligere kaldet “Sideindekseringsrapporten”) blev det primære værktøj til at forstå, hvilke sider Google havde indekseret, og hvorfor andre var ekskluderet.
Efterhånden som websites blev mere komplekse med dynamisk indhold, parametre og dubletter, blev problemer med indekstdækning stadig mere almindelige. Forskning viser, at cirka 40-60% af websites har betydelige problemer med indekstdækningen, hvor mange sider forbliver uopdagede eller bevidst udelukket fra indekset. Fremkomsten af JavaScript-tunge websites og single-page applications har yderligere kompliceret indekseringen, da søgemaskiner skal gengive indholdet, før de kan afgøre, om det kan indekseres. I dag anses overvågning af indekstdækning for at være essentielt for enhver organisation, der er afhængig af organisk trafik, og brancheeksperter anbefaler månedlige audits som minimum.
Forholdet mellem indekstdækning og crawlbudget er blevet stadig vigtigere, efterhånden som websites skaleres op. Crawlbudget refererer til det antal sider, Googlebot vil crawle på dit website inden for en given tidsramme. Store websites med dårlig struktur eller for mange dubletter kan spilde crawlbudgettet på sider med lav værdi, så vigtigt indhold forbliver uopdaget. Studier viser, at over 78% af virksomheder bruger en form for overvågningsværktøj til indhold for at spore deres synlighed på tværs af søgemaskiner og AI-platforme, idet de anerkender, at indekstdækning er grundlaget for enhver synlighedsstrategi.
| Begreb | Definition | Primær kontrol | Anvendte værktøjer | Indvirkning på placeringer |
|---|---|---|---|---|
| Indeksdækning | Procentdel af sider indekseret af søgemaskiner | Metatags, robots.txt, indholdskvalitet | Google Search Console, Bing Webmaster Tools | Direkte – kun indekserede sider kan rangere |
| Crawlbarhed | Bots’ evne til at få adgang til og navigere på sider | robots.txt, sidestruktur, interne links | Screaming Frog, ZentroAudit, serverlogs | Indirekte – sider skal være crawlbare for at blive indekseret |
| Indekserbarhed | Evne for crawlede sider til at blive tilføjet i indekset | Noindex-direktiver, kanoniske tags, indhold | Google Search Console, URL Inspection Tool | Direkte – afgør om sider vises i resultaterne |
| Crawlbudget | Antal sider Googlebot crawler per tidsenhed | Sideautoritet, sidekvalitet, crawlfejl | Google Search Console, serverlogs | Indirekte – påvirker hvilke sider, der bliver crawlet |
| Duplikeret indhold | Flere sider med identisk eller lignende indhold | Kanoniske tags, 301 redirects, noindex | SEO-auditværktøjer, manuel gennemgang | Negativt – udvander rangeringsevne |
Indeksdækning fungerer gennem en tretrinsproces: opdagelse, crawling og indeksering. I opdagelsesfasen finder søgemaskiner URLs via forskellige metoder, herunder XML-sitemaps, interne links, eksterne backlinks og direkte indsendelse via Google Search Console. Når de er opdaget, bliver URLs sat i kø til crawling, hvor Googlebot anmoder om siden og analyserer dens indhold. Til sidst, under indekseringen, behandler Google sidens indhold, vurderer relevans og kvalitet og beslutter, om den skal inkluderes i det søgbare indeks.
Indeksdækningsrapporten i Google Search Console kategoriserer sider i fire primære statusser: Gyldig (indekserede sider), Gyldig med advarsler (indekseret, men med problemer), Ekskluderet (bevidst ikke indekseret) og Fejl (sider, der ikke kunne indekseres). Inden for hver status er der specifikke problemtyper, der giver indblik i, hvorfor sider er eller ikke er indekserede. For eksempel kan sider være ekskluderet, fordi de indeholder et noindex metatag, er blokeret af robots.txt, er dubletter uden korrekt kanonisk tag, eller returnerer 4xx eller 5xx HTTP-statuskoder.
At forstå de tekniske mekanismer bag indekstdækning kræver kendskab til flere nøglekomponenter. robots.txt-filen er en tekstfil i dit websites rodmappe, der instruerer søgemaskinecrawlere om, hvilke mapper og filer de må og ikke må tilgå. Forkert konfiguration af robots.txt er en af de mest almindelige årsager til problemer med indekstdækning – hvis du ved en fejl blokerer vigtige mapper, forhindrer du Google i overhovedet at opdage de sider. Meta robots-tagget, placeret i en sides HTML-head, giver sidenspecifikke instruktioner med direktiver som index, noindex, follow og nofollow. Kanonisk tag (rel=“canonical”) fortæller søgemaskiner, hvilken version af en side der er den foretrukne, hvis der findes dubletter, hvilket forebygger indeksopblæsning og samler rangeringsevne på den foretrukne version.
For virksomheder, der er afhængige af organisk trafik, har indekstdækning direkte betydning for både omsætning og synlighed. Når vigtige sider ikke bliver indekseret, kan de ikke vises i søgeresultater, hvilket betyder, at potentielle kunder ikke kan finde dem via Google. E-handelswebsites med dårlig indekstdækning kan have produktsider, der sidder fast i status “Opdaget – aktuelt ikke indekseret”, hvilket resulterer i tabte salg. Content marketing-platforme med tusindvis af artikler har brug for robust indekstdækning for at sikre, at deres indhold når ud til publikum. SaaS-virksomheder er afhængige af indekseret dokumentation og blogindlæg for at generere organiske leads.
De praktiske konsekvenser rækker ud over traditionel søgning. Med fremkomsten af generative AI-platforme som ChatGPT, Perplexity og Google AI Overviews er indekstdækning også blevet relevant for AI-synlighed. Disse systemer bruger ofte indekseret webindhold som træningsdata og kildehenvisninger. Hvis dine sider ikke er korrekt indekseret af Google, er de mindre tilbøjelige til at indgå i AI-træningsdatabaser eller blive citeret i AI-genererede svar. Det skaber et forstærket synlighedsproblem: dårlig indekstdækning påvirker både traditionelle søgeplaceringer og synlighed i AI-genereret indhold.
Organisationer, der proaktivt overvåger deres indekstdækning, ser målbare forbedringer i organisk trafik. Et typisk scenarie kan være, at 30-40% af de indsendte URLs er ekskluderet på grund af noindex-tags, duplikeret indhold eller crawlfejl. Efter udbedring – fjernelse af unødvendige noindex-tags, korrekt kanonisering og rettelse af crawlfejl – stiger antallet af indekserede sider ofte med 20-50%, hvilket direkte korrelerer med forbedret organisk synlighed. Omkostningerne ved ikke at handle er betydelige: hver måned, en side ikke er indekseret, mister du potentiel trafik og konverteringer.
Google Search Console er fortsat det primære værktøj til overvågning af indekstdækning og giver de mest autoritative data om Googles indekseringsbeslutninger. Indeksdækningsrapporten viser indekserede sider, sider med advarsler, ekskluderede sider og fejlsider, med detaljeret opdeling af forskellige problemtyper. Google tilbyder også URL Inspection Tool, der giver dig mulighed for at tjekke indekseringsstatus for enkelte sider og anmode om indeksering af nyt eller opdateret indhold. Dette værktøj er uvurderligt til fejlfinding af specifikke sider og forståelse af, hvorfor Google ikke har indekseret dem.
Bing Webmaster Tools tilbyder lignende funktionalitet gennem Index Explorer og URL Submission. Selvom Bings markedsandel er mindre end Googles, er det stadig vigtigt for at nå brugere, der foretrækker Bing. Bings data om indekstdækning adskiller sig til tider fra Googles og kan afsløre problemer, der er specifikke for Bings crawling- eller indekseringsalgoritmer. Organisationer med store websites bør overvåge begge platforme for at sikre fuld dækning.
For AI-overvågning og brandsynlighed sporer platforme som AmICited, hvordan dit brand og domæne vises på ChatGPT, Perplexity, Google AI Overviews og Claude. Disse platforme kobler traditionel indekstdækning med AI-synlighed, så organisationer kan forstå, hvordan deres indekserede indhold omsættes til omtale i AI-genererede svar. Denne integration er afgørende for moderne SEO-strategi, da synlighed i AI-systemer i stigende grad påvirker brand awareness og trafik.
Tredjeparts SEO-auditværktøjer som Ahrefs, SEMrush og Screaming Frog giver yderligere indsigt i indekstdækningen ved at crawle dit site uafhængigt og sammenligne deres resultater med Googles rapporterede indekstdækning. Uoverensstemmelser mellem din crawl og Googles kan afsløre problemer som JavaScript-renderingsproblemer, server-side fejl eller crawlbudgetbegrænsninger. Disse værktøjer identificerer også forældreløse sider (sider uden interne links), som ofte har problemer med at blive indekseret.
Forbedring af indekstdækning kræver en systematisk tilgang, der adresserer både tekniske og strategiske problemer. Start med at auditere din nuværende status ved hjælp af Google Search Consoles indekstdækningsrapport. Identificér de primære problemtyper, der påvirker dit site – om det er noindex-tags, robots.txt-blokeringer, duplikeret indhold eller crawlfejl. Prioritér problemerne efter indvirkning: sider, der burde være indekseret, men ikke er det, har højere prioritet end sider, der med rette er ekskluderet.
Dernæst, ret fejlkonfigurationer i robots.txt ved at gennemgå din robots.txt-fil og sikre, at du ikke ved et uheld blokerer vigtige mapper. En typisk fejl er at blokere /admin/, /staging/ eller /temp/ mapper, som bør blokeres, men samtidig ved en fejl også blokere /blog/, /products/ eller andet offentligt indhold. Brug Google Search Consoles robots.txt-tester for at sikre, at vigtige sider ikke bliver blokeret.
Implementér derefter korrekt kanonisering for dubleret indhold. Hvis du har flere URLs, der viser lignende indhold (fx produktsider tilgængelige via forskellige kategoristier), så implementér selvrefererende kanoniske tags på hver side eller brug 301-redirects til at samle til én version. Det forhindrer indeksopblæsning og samler rangeringsevnen på den foretrukne version.
Fjern dernæst unødvendige noindex-tags fra sider, du ønsker indekseret. Auditér dit website for noindex-direktiver, især på staging-miljøer, der måske ved en fejl er blevet sat i produktion. Brug URL Inspection Tool til at tjekke, at vigtige sider ikke har noindex-tags.
Indsend et XML-sitemap til Google Search Console med kun indekserbare URLs. Hold dit sitemap rent ved at udelukke sider med noindex-tags, redirects eller 404-fejl. For store websites kan du overveje at opdele sitemaps efter indholdstype eller sektion for bedre organisering og mere detaljeret fejllogning.
Ret crawlfejl som døde links (404-fejl), serverfejl (5xx) og redirect-kæder. Brug Google Search Console til at identificere berørte sider og udbedre dem systematisk. For 404-fejl på vigtige sider kan du enten gendanne indholdet eller lave 301-redirects til relevante alternativer.
Fremtiden for indekstdækning udvikler sig i takt med ændringer i søgeteknologi og fremkomsten af generative AI-systemer. Efterhånden som Google fortsætter med at skærpe sine Core Web Vitals-krav og E-E-A-T (Experience, Expertise, Authoritativeness, Trustworthiness)-standarder, vil indekstdækning i stigende grad afhænge af indholdskvalitet og brugeroplevelsesmålinger. Sider med dårlige Core Web Vitals eller tyndt indhold kan opleve udfordringer med indekseringen, selvom de teknisk set er crawlbare.
Fremkomsten af AI-genererede søgeresultater og answer engines ændrer, hvordan indekstdækning betyder noget. Traditionelle søgerangeringer afhænger af indekserede sider, men AI-systemer kan citere indekseret indhold anderledes eller prioritere visse kilder over andre. Organisationer skal ikke kun overvåge, om sider er indekseret af Google, men også om de bliver citeret og refereret af AI-platforme. Dette dobbelte synlighedskrav betyder, at overvågning af indekstdækning skal udvides ud over Google Search Console til også at omfatte AI-overvågningsplatforme, der sporer brandomtale på tværs af ChatGPT, Perplexity og andre generative AI-systemer.
JavaScript-rendering og dynamisk indhold vil fortsat komplicere indekstdækningen. Efterhånden som flere websites benytter JavaScript-frameworks og single-page applications, skal søgemaskiner kunne gengive JavaScript for at forstå sidens indhold. Google har forbedret sine muligheder for JavaScript-rendering, men udfordringer består. Fremtidige best practices vil sandsynligvis lægge vægt på server-side rendering eller dynamisk rendering for at sikre, at indholdet straks er tilgængeligt for crawlere uden krav om JavaScript-eksekvering.
Integrationen af strukturerede data og schema markup bliver stadig vigtigere for indekstdækningen. Søgemaskiner bruger strukturerede data til bedre at forstå sidens indhold og kontekst, hvilket potentielt forbedrer indekseringsbeslutninger. Organisationer, der implementerer omfattende schema markup for deres indholdstyper – artikler, produkter, events, FAQs – kan opleve forbedret indekstdækning og øget synlighed i rich results.
Endelig vil begrebet indeksdækning udvides fra sider til at omfatte entiteter og emner. Fremtidens overvågning handler ikke kun om, hvorvidt sider er indekseret, men også om dit brand, dine produkter og emner er korrekt repræsenteret i søgemaskinernes knowledge graphs og AI-træningsdata. Det repræsenterer et fundamentalt skift fra indeksering på sideniveau til synlighed på entitetsniveau og kræver nye overvågningsmetoder og strategier.
+++
Crawlbarhed refererer til, om søgemaskinebots kan få adgang til og navigere på dine hjemmesidesider, styret af faktorer som robots.txt og sidens struktur. Indekserbarhed bestemmer dog, om crawlede sider faktisk tilføjes til søgemaskinens indeks, styret af meta robots-tags, kanoniske tags og indholdskvalitet. En side skal være crawlbar for at være indekserbar, men det at være crawlbar garanterer ikke indeksering.
For de fleste hjemmesider er det tilstrækkeligt at tjekke indekstdækningen månedligt for at fange større problemer. Hvis du dog foretager væsentlige ændringer i din sidestruktur, offentliggør nyt indhold regelmæssigt eller udfører migrationer, bør du overvåge rapporten ugentligt eller hver anden uge. Google sender e-mailnotifikationer om presserende problemer, men disse er ofte forsinkede, så proaktiv overvågning er afgørende for at opretholde optimal synlighed.
Denne status betyder, at Google har fundet en URL (typisk gennem sitemaps eller interne links), men endnu ikke har crawlet den. Dette kan ske på grund af crawlbudget-begrænsninger, hvor Google prioriterer andre sider på dit website. Hvis vigtige sider forbliver i denne status i længere tid, kan det indikere problemer med crawlbudgettet eller lav sideautoritet, som skal adresseres.
Ja, indsendelse af et XML-sitemap til Google Search Console hjælper søgemaskiner med at opdage og prioritere dine sider til crawling og indeksering. Et velholdt sitemap, der kun indeholder indekserbare URLs, kan markant forbedre indekstdækningen ved at lede Googles crawlbudget mod dit vigtigste indhold og reducere den tid, det tager at blive opdaget.
Almindelige problemer inkluderer sider blokeret af robots.txt, noindex meta tags på vigtige sider, duplikeret indhold uden korrekt kanonisering, serverfejl (5xx), redirect-kæder og tyndt indhold. Derudover forekommer 404-fejl, soft 404'er og sider med autorisationskrav (401/403-fejl) ofte i rapporter om indekstdækning og kræver udbedring for at forbedre synligheden.
Indeksdækning påvirker direkte, om dit indhold vises i AI-genererede svar fra platforme som ChatGPT, Perplexity og Google AI Overviews. Hvis dine sider ikke er korrekt indekseret af Google, er de mindre tilbøjelige til at blive inkluderet i træningsdata eller citeret af AI-systemer. Overvågning af indekstdækning sikrer, at dit brandindhold kan opdages og citeres på både traditionelle søgemaskiner og generative AI-platforme.
Crawlbudget er antallet af sider, Googlebot vil crawle på dit website inden for en given tidsramme. Websites med dårlig crawlbudgeteffektivitet kan have mange sider, der sidder fast med status 'Opdaget – aktuelt ikke indekseret'. Optimering af crawlbudgettet ved at rette crawlfejl, fjerne duplikerede URLs og bruge robots.txt strategisk sikrer, at Google fokuserer på at indeksere dit mest værdifulde indhold.
Nej, ikke alle sider skal indekseres. Sider som staging-miljøer, duplikerede produktvarianter, interne søgeresultater og arkiver over privatlivspolitikker bør typisk udelukkes fra indekset ved hjælp af noindex-tags eller robots.txt. Målet er kun at indeksere værdifuldt, unikt indhold, der opfylder brugerens hensigt og bidrager til dit websites samlede SEO-præstation.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Lær hvad AI-indeksdækning er, og hvorfor det er vigtigt for din virksomheds synlighed i ChatGPT, Google AI Overviews og Perplexity. Opdag tekniske faktorer, bes...

Indekserbarhed er søgemaskiners evne til at inkludere sider i deres indeks. Lær hvordan crawlability, tekniske faktorer og indholdskvalitet påvirker, om dine si...
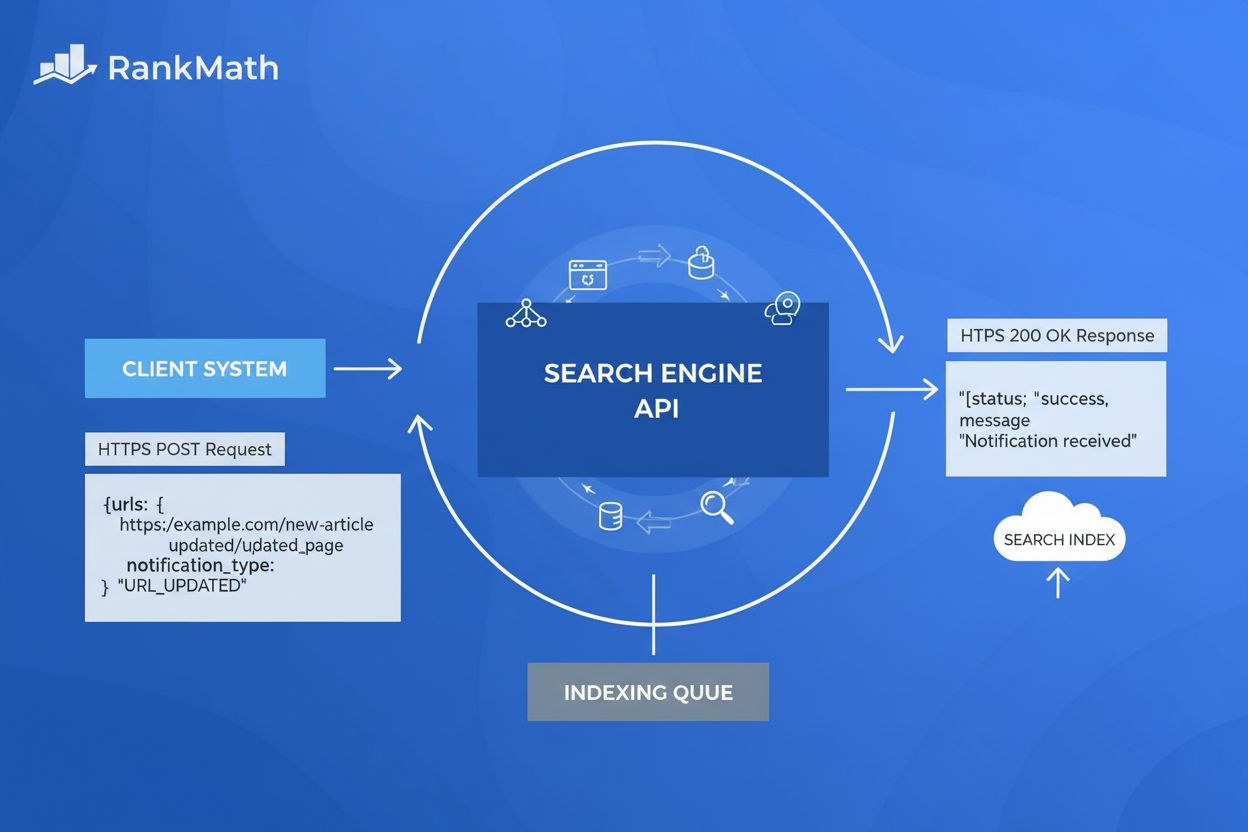
Lær hvad Indekserings-API'et er, hvordan det fungerer til direkte URL-indsendelse til Google, og hvordan det accelererer indeksering sammenlignet med traditione...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.