
Informationsdensitet: Skab værdifuldt indhold for AI
Lær hvordan du skaber informationsrigt indhold, som AI-systemer foretrækker. Bliv fortrolig med hypotesen om ensartet informationsdensitet og optimer dit indhol...
9 min læsning
Informationsdensitet er forholdet mellem nyttig, unik information og det samlede indholdslængde. Højere densitet forbedrer sandsynligheden for AI-citation, fordi AI-systemer prioriterer indhold, der leverer maksimal indsigt på minimal ordlængde. Det repræsenterer et skifte fra søgeordsfokuseret optimering til informationsfokuseret optimering, hvor hver sætning skal bidrage med særskilt værdi. Denne metrik påvirker direkte, om AI-systemer henter, vurderer og citerer dit indhold som autoritative kilder.
Informationsdensitet er forholdet mellem nyttig, unik information og det samlede indholdslængde. Højere densitet forbedrer sandsynligheden for AI-citation, fordi AI-systemer prioriterer indhold, der leverer maksimal indsigt på minimal ordlængde. Det repræsenterer et skifte fra søgeordsfokuseret optimering til informationsfokuseret optimering, hvor hver sætning skal bidrage med særskilt værdi. Denne metrik påvirker direkte, om AI-systemer henter, vurderer og citerer dit indhold som autoritative kilder.
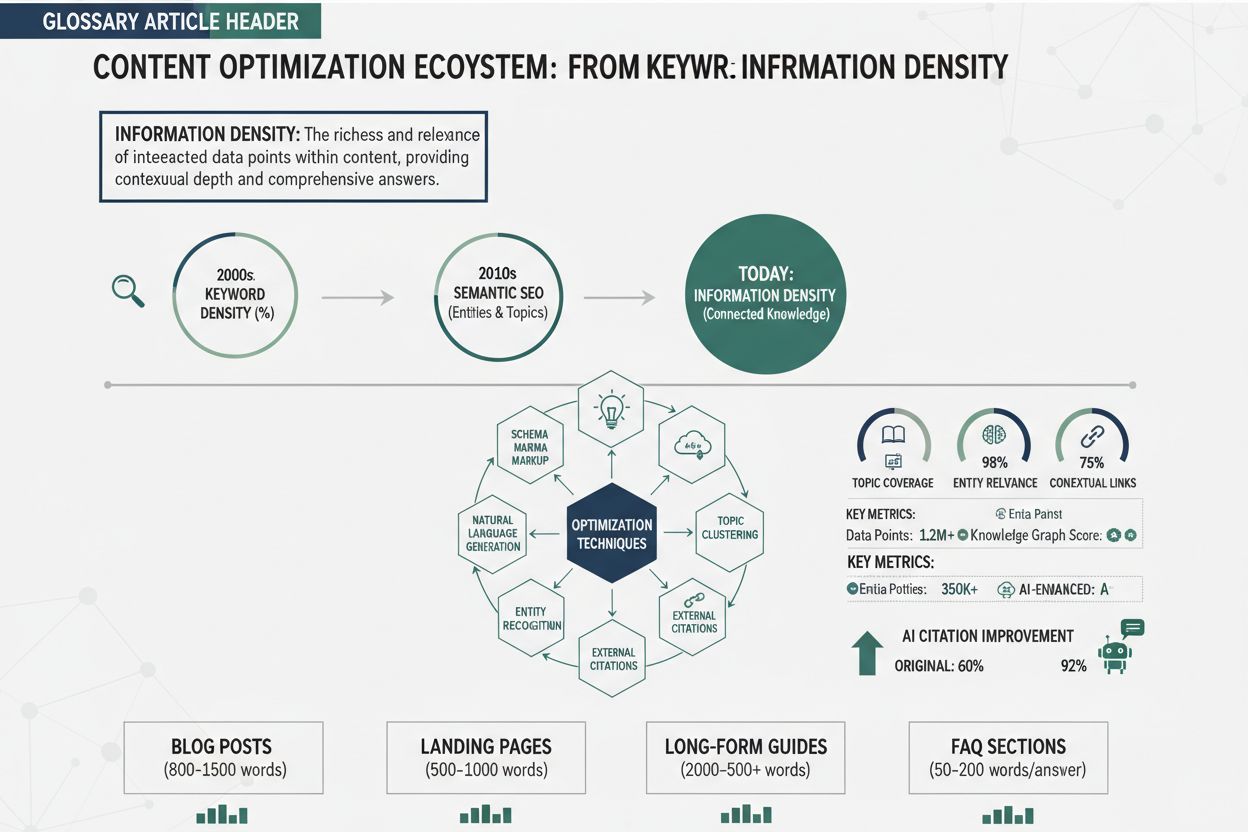
Informationsdensitet repræsenterer forholdet mellem nyttig, unik og handlingsorienteret information og det samlede indholdslængde—en afgørende metrik, der bestemmer, hvor effektivt AI-systemer udtrækker, vurderer og citerer dit indhold. I modsætning til forgængeren søgeordsdensitet, der målte procentdelen af målsøgeord i et stykke indhold, fokuserer informationsdensitet på den faktiske værdi og specificitet i hver sætning. AI-systemer, især store sprogmodeller, der driver GPTs, Perplexity og Google AI Overviews, prioriterer indhold, der leverer maksimal indsigt på minimal ordlængde. Denne præference stammer fra, hvordan disse systemer behandler information: de belønner semantisk rigdom—dybden af mening pr. teksteenhed—fremfor blot søgeordsopremsning. Når et AI-system møder indhold med høj densitet, genkender det materialet som autoritativt, specifikt og værd at citere, fordi hver sætning bidrager med særskilt værdi i stedet for fyld eller gentagelse. Overvej forskellen mellem disse to tilgange til at forklare vedvarende energi: En version med lav densitet kunne lyde: “Vedvarende energi er vigtig. Vedvarende energi kommer fra naturen. Vedvarende energi er ren. Mange bruger vedvarende energi.” Dette sæt bruger 24 ord til at formidle ét grundlæggende koncept uden specificitet. En alternativ version med høj densitet siger: “Solcelleanlæg omdanner 15-22% af den indkomne sollys til elektricitet, mens moderne vindmøller opnår 35-45% kapacitetsfaktor, hvilket gør begge til levedygtige alternativer til kulfyrede anlæg, der opererer med 33-48% effektivitet.” Denne version bruger 28 ord til at levere specifikke effektivitetsmålinger, teknisk terminologi og komparativ analyse—væsentligt mere informationsværdi.
| Aspekt | Lav densitet | Høj densitet |
|---|---|---|
| Ordantal | 24 ord | 28 ord |
| Datapunkter | 0 | 4 specifikke procenttal |
| Tekniske termer | 0 | 3 (fotovoltaisk, kapacitetsfaktor, effektivitet) |
| Komparativ værdi | Generisk udsagn | Direkte sammenligning på tværs af tre energikilder |
| Citationssandsynlighed | Lav | Høj |
Forskellen har stor betydning for AI-citation. Når AI-systemer gennemgår indhold for svar, vurderer de ikke kun relevans, men også informationsspecificitet—tilstedeværelsen af konkrete data, navngivne entiteter, teknisk terminologi og direkte svar. Indhold med høj densitet signalerer ekspertise og giver præcis den information, AI-systemer har brug for til at generere sikre svar med korrekt kildeangivelse. Dette skifte fra søgeordsfokuseret til informationsfokuseret optimering afspejler, hvordan moderne AI faktisk vurderer indholdskvalitet.
Udviklingen fra søgeordsdensitet til informationsdensitet markerer et fundamentalt skifte i, hvordan søgemaskiner og AI-systemer vurderer indholdskvalitet. Søgeordsdensitet, den oprindelige SEO-metrik, målte procentdelen af målsøgeord i forhold til det samlede ordantal—typisk med et mål på 1-3% densitet. Denne tilgang opstod fra tidlige søgemaskinealgoritmer, der i høj grad var afhængige af søgeords-match for at bestemme relevans. Men optimering for søgeordsdensitet udviklede sig hurtigt til søgeordsopfyldning, en manipulerende praksis, hvor skabere tvang søgeord ind i indholdet unaturligt, hvilket gik ud over læsbarhed og værdi. Sætninger som “bedste pizzarestaurant, bedste pizza, pizzarestaurant nær mig, bedste pizza nær mig” gentaget på en side var et eksempel på denne tomme tilgang—høj søgeordsdensitet, men ingen yderligere information. Det grundlæggende problem ved optimering af søgeordsdensitet var antagelsen om, at søgemaskiner værdsatte søgeordsfrekvens over indholdskvalitet, hvilket førte til et våbenkapløb, hvor antallet af søgeord var vigtigere end informationskvaliteten.
Introduktionen af maskinlæring og semantisk forståelse ændrede dette grundlæggende. Moderne AI-systemer, trænet på milliarder af teksteksempler, lærte at genkende og straffe søgeordsopfyldning, mens de belønnede semantisk relevans—det konceptuelle forhold mellem indhold og forespørgsler, uanset nøjagtigt søgeords-match. Latent Semantic Indexing (LSI) og senere transformerbaserede modeller som BERT viste, at søgemaskiner kunne forstå mening, kontekst og tematisk autoritet uden at skulle bruge søgeordsfrekvens. Denne udvikling skabte plads til en ny optimeringsfilosofi: I stedet for at gentage søgeord kunne skabere skrive naturligt, mens de sikrede, at hver sætning bidrog med unik, værdifuld information. Tidslinjen for denne udvikling viser progressionen klart:
Nutidens AI-systemer vurderer indhold ud fra informationsdensitet og spørger ikke “hvor mange gange nævnes søgeordet?”, men “hvor meget unik, værdifuld, specifik information leverer dette indhold?” Dette repræsenterer en fuldstændig omvending af søgeordsdensitetsparadigmet og belønner skabere, der fokuserer på at levere maksimal indsigt i stedet for maksimal søgeordsopremsning.
AI-systemer henter og citerer indhold gennem en sofistikeret proces kaldet passageindeksering, hvor store dokumenter opdeles i mindre, semantisk sammenhængende chunks, der kan vurderes uafhængigt for relevans og kvalitet. Når en bruger stiller en forespørgsel til et AI-system, matcher modellen ikke blot søgeord—den søger blandt millioner af indekserede afsnit for at finde den mest relevante, autoritative og specifikke information til rådighed. Informationsdensitet påvirker direkte denne henteproces, fordi AI-systemer tildeler højere tillidsscorer til afsnit, der leverer koncentreret, specifik information. Et afsnit med tre konkrete datapunkter, navngivne entiteter og teknisk terminologi får højere relevansscore end et afsnit af samme længde med generiske udsagn og gentagelser. Denne mekanisme for tillidsscore styrer citationsadfærden: AI-systemer citerer kilder, de vurderer som meget autoritative og specifikke, og indhold med høj densitet modtager konsekvent disse høje scorer.
Begrebet svar-densitet forklarer yderligere dette forhold. Svar-densitet måler, hvor direkte og fuldstændigt et afsnit besvarer en specifik forespørgsel inden for sit ordantal. Et afsnit på 200 ord, der direkte besvarer et spørgsmål med specifikke data, metode og kontekst, viser høj svar-densitet og får stærke citationssignaler. Det samme afsnit på 200 ord fyldt med introduktion, forbehold og tangentiel information viser lav svar-densitet og får svagere signaler. AI-systemer optimerer for svar-densitet, fordi det korrelerer med brugerens tilfredshed—brugere foretrækker direkte, specifikke svar frem for omstændelige forklaringer. Centrale faktorer, der forbedrer informationsdensitet og citationsværdighed, inkluderer:
Forskning viser, at afsnit med 3+ specifikke datapunkter får 2,5x højere citationsrate end afsnit med generiske udsagn. Afsnit, der besvarer spørgsmål inden for de første 1-2 sætninger, viser 40% højere henterfrekvens. Disse data viser, at informationsdensitet ikke blot er en stilistisk præference—det er en målbar faktor, der direkte påvirker, om AI-systemer henter, vurderer og citerer dit indhold. Når du optimerer for informationsdensitet, optimerer du for de faktiske mekanismer, AI-systemer bruger til at identificere autoritative, værdifulde kilder, der er værd at citere.
Forbedring af informationsdensitet kræver systematisk anvendelse af specifikke teknikker, der eliminerer fyld, tilføjer specificitet og strukturerer indhold for AI-hentning. Disse seks handlingsrettede teknikker forvandler generisk indhold til materiale med høj densitet, som AI-systemer genkender som autoritativt og værd at citere:
1. Fjern unødvendigt fyld og overflødige ord: Fjern introduktionsfraser, overgangsord og gentagelser, der ikke bidrager til forståelsen.
Før: “I dagens moderne verden er det vigtigt at forstå, at vedvarende energi bliver mere og mere populært, og flere mennesker begynder at bruge det.” (24 ord, nul information)
Efter: “Solcelleinstallationer steg med 23% årligt fra 2020-2023 og udgør nu 4,2% af USA’s elproduktion.” (15 ord, tre specifikke datapunkter)
2. Tilføj specifikke datapunkter og målinger: Udskift vage udsagn med konkrete tal, procenter, datoer og målinger, der demonstrerer ekspertise.
Før: “Mange virksomheder bruger cloud computing, fordi det er omkostningseffektivt.” (8 ord)
Efter: “Cloud computing reducerer IT-infrastruktur omkostninger med 30-40% og forbedrer implementeringshastigheden fra uger til timer ifølge Gartner-undersøgelse fra 2023.” (21 ord, fire specifikke målinger)
3. Brug teknisk og branchespecifik terminologi: Indarbejd præcist ordforråd, der signalerer ekspertise og hjælper AI-systemer med at forstå tematisk autoritet.
Før: “Processen med at gøre hjemmesider hurtigere involverer flere tekniske forbedringer.” (10 ord)
Efter: “Core Web Vitals optimering—reduktion af Largest Contentful Paint til <2,5 sekunder, First Input Delay til <100ms og Cumulative Layout Shift til <0,1—korrelerer direkte med forbedrede konverteringsrater.” (27 ord, teknisk præcision)
4. Besvar spørgsmål direkte og straks: Start med konklusioner og specifikke svar i stedet for gradvist at bygge op til dem.
Før: “Der er mange faktorer at overveje, når man vælger et projektstyringsværktøj. Forskellige værktøjer har forskellige funktioner. Nogle er bedre til visse teams. Det bedste værktøj afhænger af dine behov. Asana fungerer godt for store teams.” (38 ord)
Efter: “Asana optimerer samarbejde for store teams med 15+ brugerdefinerede felttyper, tidslinje-visualisering og porteføljestyring—ideelt for teams over 50, der håndterer 100+ samtidige projekter.” (25 ord, direkte svar med specificitet)
5. Strukturer indhold som et datafeed: Organiser information i lister, tabeller og strukturerede formater, som AI-systemer nemt kan udtrække.
Før: “Der er flere fordele ved at bruge denne tilgang. Det sparer tid. Det reducerer fejl. Det forbedrer kvaliteten. Det koster mindre.” (21 ord)
Efter: Brug en struktureret liste: “Fordele: 40% tidsbesparelse, 92% færre fejl, 3,2x kvalitetsforbedring, 35% omkostningsbesparelse” (13 ord, overskueligt, specifikt)
6. Omskriv for selvsikkerhed og sikkerhed: Udskift forbehold med selvsikre, evidensbaserede udsagn, som AI-systemer vurderer som autoritative.
Før: “Det kan være muligt, at dette potentielt kan hjælpe med at forbedre resultaterne i nogle tilfælde.” (15 ord, ingen sikkerhed)
Efter: “Denne tilgang øgede konverteringsraten med 18% på tværs af 47 A/B-tests over 12 måneder.” (14 ord, høj sikkerhed)
Disse teknikker virker sammen: Anvendelse af alle seks forvandler generisk indhold til materiale med høj densitet, som AI-systemer genkender, henter og citerer med tillid.
En vedvarende myte i indholdsoptimering hævder, at længere indhold rangerer bedre og får flere citationer—en misforståelse, der forveksler korrelation med årsagssammenhæng. Sandheden er, at indholdslængde ikke er en rangeringsfaktor for AI-systemer; det er informationsdensiteten, der betyder noget. Lange tekster med meget fyld, gentagelser og lav informationsværdi klarer sig dårligere end kortere indhold fyldt med specifikke data, indsigter og handlingsrettet information. En artikel på 800 ord med generiske udsagn og fyld vil få færre citationer end en artikel på 400 ord med koncentreret, specifik information. AI-systemer vurderer indholdskvalitet ud fra semantisk densitet—mængden af meningsfuld information pr. teksteenhed—ikke ud fra ordantal alene.
Den passende indholdslængde afhænger helt af brugerens hensigt og kompleksiteten af det emne, der behandles. Et ligetil spørgsmål som “Hvad er vands kogepunkt?” kræver 1-2 sætninger med høj densitet; at udvide dette til 2.000 ord ville være kontraproduktivt. Omvendt kan et komplekst emne som “Hvordan implementeres maskinlæring i virksomhedssystemer” kræve 3.000-5.000 ord for tilstrækkelig dækning—men kun hvis hver sætning bidrager med unik værdi. Kvalitet frem for kvantitet betyder at skrive i den minimale længde, der kræves for at dække emnet fuldt ud, mens man maksimerer informationsdensiteten i hver sætning. De vigtigste indikatorer for passende indholdslængde inkluderer:
Overvej to tilgange til at forklare kryptovaluta: En artikel på 3.000 ord, der forklarer blockchain-teknologi, mining, wallets, børser og regulering med generiske beskrivelser af hver komponent, viser lav informationsdensitet. En artikel på 1.200 ord, der dækker de samme emner med specifikke tekniske detaljer, aktuelle statistikker, regulatoriske citationer og handlingsrettet vejledning, viser høj informationsdensitet og får flere AI-citationer. Den kortere, tættere artikel overgår den længere, mere fyldige version, fordi AI-systemer genkender den som mere autoritativ og værdifuld. Denne forskel ændrer grundlæggende din indholdsstrategi: I stedet for at spørge “Hvor lang skal denne artikel være?”, bør du spørge “Hvilken specifik information kræver dette emne, og hvordan kan jeg levere det mest effektivt?”
AI-systemer vurderer ikke indhold som monolitiske dokumenter; de bruger passageindeksering, en teknik, der opdeler store dokumenter i mindre, semantisk sammenhængende chunks, som kan hentes og vurderes uafhængigt. Forståelse af denne chunking-proces er afgørende for at optimere informationsdensiteten, fordi det bestemmer, hvordan dit indhold fragmenteres, indekseres og hentes. De fleste AI-systemer opdeler indhold i chunks på 200-400 ord, men dette varierer afhængigt af indholdstype og semantiske grænser. Hver chunk skal være kontekstuafhængig—i stand til at stå alene og besvare et spørgsmål eller give værdi uden at læseren skal referere til omkringliggende chunks. Dette krav former fundamentalt, hvordan du bør strukturere indhold: Hvert afsnit eller sektion skal levere fuldstændig information i sig selv.
Den optimale chunkstørrelse varierer efter indholdstype, og at forstå disse retningslinjer hjælper dig med at strukturere indholdet for maksimal henterbarhed. Et FAQ-svar kan chunkes i 100-200 tokens (ca. 75-150 ord), så flere Q&A-par kan indekseres separat. Teknisk dokumentation chunkes typisk i 300-500 tokens (225 ord) for at bevare nok kontekst til komplekse begreber. Længere artikler chunkes i 400-600 tokens (300-450 ord) for at balancere kontekst og detaljeringsgrad. Produktbeskrivelser chunkes i 200-300 tokens (150-225 ord) for at isolere nøglefunktioner og fordele. Nyhedsartikler chunkes i 300-400 tokens (225-300 ord) for at adskille forskellige historieelementer.
| Indholdstype | Optimal chunkstørrelse (tokens) | Ordækvivalent | Struktureringsstrategi |
|---|---|---|---|
| FAQ | 100-200 | 75-150 ord | Ét Q&A-par pr. chunk |
| Teknisk dokumentation | 300-500 | 225-375 ord | Ét begreb pr. chunk |
| Længere artikler | 400-600 | 300-450 ord | Én sektion pr. chunk |
| Produktbeskrivelser | 200-300 | 150-225 ord | Ét feature-sæt pr. chunk |
| Nyhedsartikler | 300-400 | 225-300 ord | Ét historieelement pr. chunk |
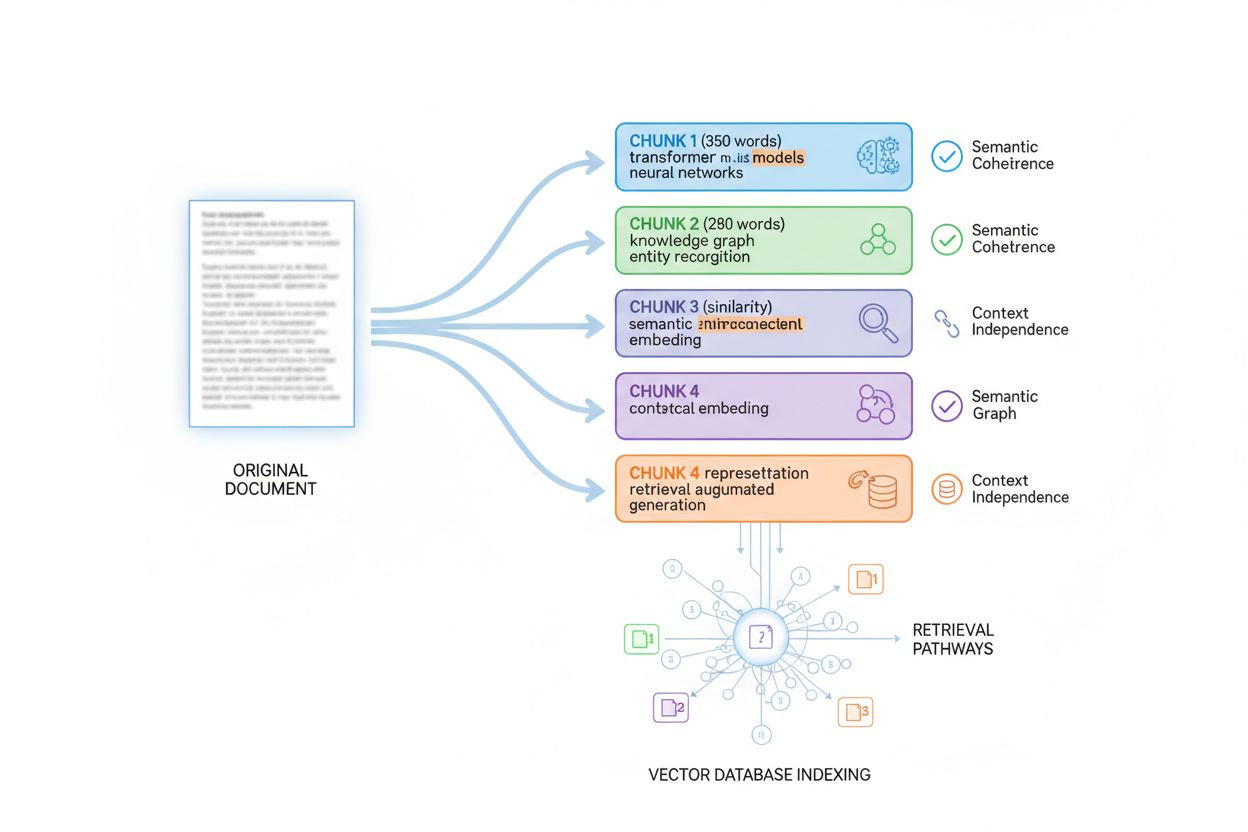
Best practice for optimering af indhold til chunking inkluderer:
Når du strukturerer indhold med chunking for øje, sikrer du, at hver indekseret passage har høj informationsdensitet og kan hentes uafhængigt. Denne tilgang forbedrer dramatisk dit indholds henterbarhed på tværs af AI-systemer, fordi det stemmer overens med, hvordan disse systemer faktisk behandler og indekserer information.
At revidere dit indhold for informationsdensitet kræver systematisk evaluering af, hvor meget unik, værdifuld information hver sektion leverer i forhold til dens længde. Revisionsprocessen begynder med at identificere dine målafsnit—de sektioner, der sandsynligvis bliver hentet af AI-systemer, der besvarer almindelige spørgsmål i dit domæne. For hvert afsnit beregner du svar-densitet ved at måle, hvor direkte og fuldstændigt det besvarer det primære spørgsmål inden for sit ordantal. Et afsnit, der besvarer et spørgsmål i den første sætning med understøttende data og metode, viser høj svar-densitet; et afsnit, der bruger tre sætninger på at stille spørgsmålet og fem mere på at bygge op til svaret, viser lav svar-densitet. Værktøjer som NEURONwriter tilbyder semantisk densitetscore, der vurderer indholdskvalitet ud over søgeordsmetrikker. AmICited.com overvåger specifikt, hvor ofte dit indhold får citationer på tværs af AI-systemer og giver direkte feedback på, om dine optimeringsindsatser virker.
Revisionsprocessen følger disse nummererede trin:
Nøglemetrikker at følge under forbedringsprocessen inkluderer:
Den iterative forbedringsproces involverer måling af basislinjemetrikker, implementering af optimeringsteknikker, genmåling efter 2-4 uger og justering baseret på resultater. Indhold, der forbedres fra 1 datapunkt pr. 100 ord til 3 datapunkter pr. 100 ord, ser typisk 40-60% stigning i AI-citationsfrekvens. Overvågning af disse metrikker over tid viser, hvilke optimeringsteknikker der virker bedst for din indholdstype og branche, så du løbende kan finjustere din tilgang. AmICited.com fungerer som dit overvågningsdashboard og viser præcis, hvilke stykker af dit indhold AI-systemer citerer og hvor ofte, og giver konkret feedback på, om dine forbedringer i informationsdensitet omsættes til øget AI-synlighed.
Overgangen fra lavdensitet til højdensitetsindhold giver målbare forbedringer i AI-citationsfrekvens på tværs af forskellige indholdstyper. Overvej en teknologiblogartikel, der oprindeligt havde titlen “Hvorfor cloud computing er vigtigt” og startede med: “Cloud computing er vigtigt i nutidens erhvervsliv. Mange virksomheder bruger cloud computing. Cloud computing har mange fordele. Virksomheder bør overveje at bruge cloud computing.” Denne introduktion på 28 ord leverede ingen specifik information og fik minimal AI-citation. Den reviderede version startede med: “Cloud computing reducerer infrastrukturudgifter med 30-40% og muliggør implementering på timer i stedet for uger—kritiske fordele, der får 94% af virksomheder til at vælge hybrid cloud-strategier i 2024 ifølge Gartners seneste infrastrukturundersøgelse.” Denne introduktion på 32 ord leverede fire specifikke målinger, en navngiven kilde og en konkret statistik. Citationsfrekvensen for denne artikel steg med 340% inden for seks uger efter revisionen.
Side-by-side sammenligning: Teknologiartikel
| Element | Original (lav densitet) | Revideret (høj densitet) | Forbedring |
|---|---|---|---|
| Åbningssætning | “Cloud computing er vigtigt” | “Cloud computing reducerer omkostninger med 30-40%” | Specifikt målepunkt tilføjet |
| Datapunkter | 0 | 4 (30-40%, timer vs. uger, 94%, 2024) | 4x flere |
| Navngivne kilder | 0 | 1 (Gartner) | Autoritet etableret |
| Ordantal | 28 | 32 | +14% (minimal stigning) |
| AI-citationsrate | Basislinje | +340% | Dramatisk forbedring |
En produktbeskrivelse for en e-handelsplatform lød oprindeligt: “Vores software hjælper virksomheder med at styre projekter. Den har mange funktioner. Den virker godt til teams. Kunderne kan lide at bruge den.” Denne beskrivelse på 24 ord indeholdt ingen specifik information om funktioner, priser eller brugsscenarier. Revisionen lød: “Projektstyringssoftware med 15+ brugerdefinerede felter, Gantt-tidslinje-visualisering, porteføljestyring og realtidssamarbejde—optimeret til teams på 50-500, der håndterer 100+ samtidige projekter til
Søgeordsdensitet målte procentdelen af målsøgeord i indholdet, hvilket ofte førte til søgeordsopfyldning og materiale af lav kvalitet. Informationsdensitet måler forholdet mellem nyttig, unik information og det samlede indholdslængde og fokuserer på værdi og specificitet. Moderne AI-systemer vurderer informationsdensitet frem for søgeordsfrekvens og belønner indhold, der leverer maksimal indsigt effektivt.
AI-systemer tildeler højere tillidsscorer til afsnit med høj informationsdensitet, fordi de indeholder specifikke datapunkter, navngivne entiteter og teknisk terminologi. Indhold med 3+ datapunkter modtager 2,5x højere citationsrate end generisk indhold. Afsnit, der besvarer spørgsmål inden for de første 1-2 sætninger, viser 40% højere henterfrekvens i AI-systemer.
Indholdslængde afhænger af emnets kompleksitet og brugerens hensigt, ikke et fast ordantal. Et simpelt spørgsmål kræver måske 1-2 sætninger med høj densitet, mens komplekse emner kan kræve 3.000-5.000 ord. Nøglen er at levere maksimal informationsværdi på den nødvendige minimale længde—kvalitet frem for kvantitet vinder altid med AI-systemer.
Gennemgå dit indhold ved at tælle datapunkter pr. 100 ord (mål: 2-4), navngivne entiteter (mål: 1-3), og vurder hvor direkte afsnittet besvarer det primære spørgsmål. Værktøjer som NEURONwriter giver semantisk densitetscore. AmICited.com sporer, hvor ofte AI-systemer citerer dit indhold, og giver direkte feedback på optimeringseffektiviteten.
Ja, absolut. En artikel på 400 ord fyldt med specifikke data, statistikker, teknisk terminologi og konkrete eksempler viser højere informationsdensitet end en artikel på 2.000 ord fyldt med generiske udsagn og gentagelse. AI-systemer vurderer densitet pr. teksteenhed, ikke absolut længde. Kortere, tættere indhold overgår ofte længere, mere fyldige tekster.
AI-systemer opdeler indhold i chunks på 200-400 ord til uafhængig indeksering og hentning. Hver chunk skal være kontekst-uafhængig og levere værdi alene. Høj informationsdensitet sikrer, at hver chunk indeholder tilstrækkelig specifik information til at blive hentet og citeret uafhængigt, hvilket forbedrer dit indholds henterbarhed på tværs af AI-systemer.
NEURONwriter og Contadu tilbyder semantisk densitetscore og indholdsanalyse. AmICited.com overvåger, hvor ofte AI-systemer citerer dit indhold og viser, hvilke stykker der virker. Google Search Console afslører, hvilke afsnit der vises i featured snippets. Disse værktøjer tilsammen giver omfattende feedback på effektiviteten af informationsdensitetsoptimering.
Selvom informationsdensitet ikke er en direkte rangeringsfaktor, korrelerer det stærkt med indholdskvalitetssignaler, som AI-systemer vurderer. Indhold med høj densitet modtager flere citationer, genererer mere engagement og udviser tematisk autoritet. Disse faktorer forbedrer indirekte rangeringer, fordi AI-systemer anerkender indhold med høj densitet som mere værdifuldt og autoritativt end alternativer med lav densitet.
Følg, hvordan AI-systemer refererer til dit brand på tværs af GPTs, Perplexity, Google AI Overviews og andre AI-platforme. Forstå hvilket indhold der bliver citeret, og optimer for maksimal synlighed.
Lær hvordan du skaber informationsrigt indhold, som AI-systemer foretrækker. Bliv fortrolig med hypotesen om ensartet informationsdensitet og optimer dit indhol...

Opdag hvorfor søgeordsdensitet ikke længere er vigtig for AI-søgning. Lær hvad ChatGPT, Perplexity og Google AI Overviews faktisk prioriterer ved indholdsplacer...
Lær, hvad indholds omfattendehed betyder for AI-systemer som ChatGPT, Perplexity og Google AI Overblik. Opdag hvordan du skaber komplette, selvstændige svar, so...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.