
Transformer-arkitektur
Transformer-arkitektur er et neuralt netværksdesign, der bruger self-attention-mekanismer til at behandle sekventielle data parallelt. Det driver ChatGPT, Claud...
15 min læsning
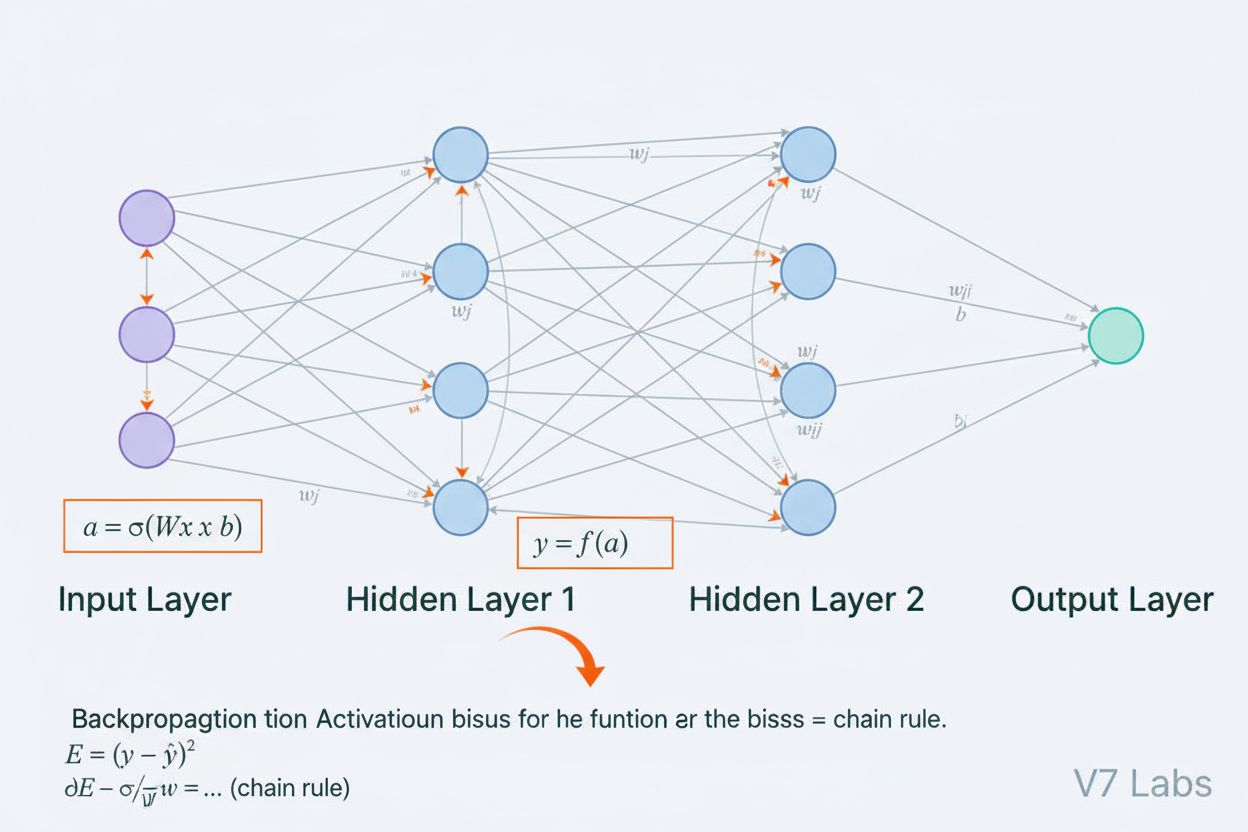
Et neuralt netværk er et computersystem inspireret af biologiske neurale netværk, der består af sammenkoblede kunstige neuroner organiseret i lag, som er i stand til at lære mønstre fra data gennem en proces kaldet backpropagation. Disse systemer udgør fundamentet for moderne kunstig intelligens og dyb læring og driver applikationer fra naturlig sprogbehandling til computer vision.
Et neuralt netværk er et computersystem inspireret af biologiske neurale netværk, der består af sammenkoblede kunstige neuroner organiseret i lag, som er i stand til at lære mønstre fra data gennem en proces kaldet backpropagation. Disse systemer udgør fundamentet for moderne kunstig intelligens og dyb læring og driver applikationer fra naturlig sprogbehandling til computer vision.
Et neuralt netværk er et computersystem, der grundlæggende er inspireret af strukturen og funktionen af biologiske neurale netværk, som findes i dyrs hjerner. Det består af sammenkoblede kunstige neuroner organiseret i lag—typisk et inputlag, et eller flere skjulte lag og et outputlag—som arbejder sammen for at behandle data, genkende mønstre og lave forudsigelser. Hver neuron modtager input, anvender matematiske transformationer gennem vægte og bias og sender resultatet gennem en aktiveringsfunktion for at producere et output. Det definerende kendetegn ved neurale netværk er deres evne til at lære fra data gennem en iterativ proces kaldet backpropagation, hvor netværket justerer sine interne parametre for at minimere forudsigelsesfejl. Denne læringsevne, kombineret med deres kapacitet til at modellere komplekse ikke-lineære sammenhænge, har gjort neurale netværk til den grundlæggende teknologi bag moderne kunstig intelligens, fra store sprogmodeller til computer vision-applikationer.
Konceptet om kunstige neurale netværk opstod ud fra tidlige forsøg på matematisk at modellere, hvordan biologiske neuroner kommunikerer og bearbejder information. I 1943 foreslog Warren McCulloch og Walter Pitts den første matematiske model af en neuron og viste, at simple beregningsenheder kunne udføre logiske operationer. Dette teoretiske fundament blev fulgt op af Frank Rosenblatts introduktion af perceptronen i 1958, en algoritme designet til mønstergenkendelse, som blev den historiske forfader til nutidens avancerede neurale netværksarkitekturer. Perceptronen var i bund og grund en lineær model med begrænset output, der kunne lære simple beslutningsgrænser. Feltet oplevede dog betydelige tilbageslag i 1970’erne, da forskere opdagede, at enkeltlagede perceptroner ikke kunne løse ikke-lineære problemer som XOR-funktionen, hvilket førte til den såkaldte “AI-vinter.” Gennembruddet kom i 1980’erne med genopdagelsen og forbedringen af backpropagation, en algoritme der muliggjorde træning af multilagsnetværk. Denne genopblomstring accelererede dramatisk i 2010’erne med tilgængeligheden af enorme datasæt, kraftfulde GPU’er og forbedrede træningsteknikker, hvilket førte til deep learning-revolutionen, der transformerede kunstig intelligens.
Et neuralt netværks arkitektur består af flere væsentlige komponenter, der arbejder sammen. Inputlaget modtager rå datafunktioner fra eksterne kilder, hvor hver neuron i dette lag svarer til én funktion. Skjulte lag udfører det beregningsmæssige arbejde ved at transformere input til stadigt mere abstrakte repræsentationer gennem vægtede kombinationer og ikke-lineære aktiveringsfunktioner. Antallet og størrelsen af skjulte lag bestemmer netværkets kapacitet til at lære komplekse mønstre—dybere netværk kan fange mere avancerede sammenhænge, men kræver mere data og computerkraft. Outputlaget producerer de endelige forudsigelser, og dets struktur afhænger af opgaven: en enkelt neuron til regression, flere neuroner til multi-klasse klassifikation eller specialiserede arkitekturer til andre applikationer. Hver forbindelse mellem neuroner har en vægt, der bestemmer indflydelsen, mens hver neuron har en bias, der flytter aktiveringstærsklen. Disse vægte og bias er de lærbare parametre, som netværket justerer under træning. Aktiveringsfunktionen anvendt i hver neuron indfører nødvendig ikke-linearitet, der gør det muligt for netværket at lære komplekse beslutningsgrænser og mønstre, som lineære modeller ikke kan opfange.
Neurale netværk lærer gennem en tofaset iterativ proces. Under fremadpropagering flyder inputdata gennem netværket fra inputlaget til outputlaget. Ved hver neuron beregnes den vægtede sum af input plus bias (z = w₁x₁ + w₂x₂ + … + wₙxₙ + b), som derefter sendes gennem en aktiveringsfunktion for at give neuronens output. Denne proces gentages gennem hvert skjult lag, indtil outputlaget nås, som producerer netværkets forudsigelse. Netværket beregner så fejlen mellem sin forudsigelse og den sande label ved hjælp af en tab-funktion, der kvantificerer, hvor langt forudsigelsen er fra det korrekte svar. Ved backpropagation bliver denne fejl sendt bagud gennem netværket ved hjælp af kædereglen fra calculus. Ved hver neuron beregner algoritmen gradienten af tabet i forhold til hver vægt og bias og bestemmer, hvor meget hver parameter bidrog til den samlede fejl. Disse gradienter styrer parameteropdateringerne: vægte og bias justeres i retning modsat gradienten, skaleret med en læringsrate, der styrer skridtstørrelsen. Denne proces gentages over mange iterationer gennem træningsdatasættet og reducerer gradvist tabet, så netværkets forudsigelser forbedres. Kombinationen af fremadpropagering, tabsberegning, backpropagation og parameteropdateringer udgør den komplette træningscyklus, der gør det muligt for neurale netværk at lære fra data.
| Arkitekturtype | Primær anvendelse | Nøglekarakteristik | Styrker | Begrænsninger |
|---|---|---|---|---|
| Feedforward-netværk | Klassifikation, regression på strukturerede data | Information flyder kun i én retning | Enkel, hurtig træning, fortolkelig | Kan ikke håndtere sekventielle eller rumlige data godt |
| Convolutional Neural Networks (CNNs) | Billedgenkendelse, computer vision | Konvolutionslag opdager rumlige træk | Fremragende til at fange lokale mønstre, parameter-effektive | Kræver store mærkede billeddatasæt |
| Recurrent Neural Networks (RNNs) | Sekventielle data, tidsserier, NLP | Skjult tilstand bevarer hukommelse over tidstrin | Kan behandle sekvenser af variabel længde | Lider under forsvindende/eksploderende gradienter |
| Long Short-Term Memory (LSTM) | Langtrækkende afhængigheder i sekvenser | Hukommelsesceller med input/glemme/output-gates | Håndterer langtidshukommelse effektivt | Mere kompleks, langsommere træning end RNNs |
| Transformer-netværk | Naturlig sprogbehandling, store sprogmodeller | Multi-head attention-mekanisme, parallel behandling | Meget paralleliserbar, fanger langtrækkende afhængigheder | Kræver massive computerressourcer |
| Generative Adversarial Networks (GANs) | Billedgenerering, syntetisk dataoprettelse | Generator- og diskriminatornetværk konkurrerer | Kan generere realistisk syntetisk data | Svære at træne, mode collapse-problemer |
Indførelsen af aktiveringsfunktioner er en af de mest afgørende innovationer i designet af neurale netværk. Uden aktiveringsfunktioner ville et neuralt netværk matematisk set være ækvivalent med en enkelt lineær transformation, uanset hvor mange lag det indeholder. Det skyldes, at sammensætningen af lineære funktioner stadig er lineær, hvilket kraftigt begrænser netværkets evne til at lære komplekse mønstre. Aktiveringsfunktioner løser dette problem ved at indføre ikke-linearitet i hver neuron. ReLU (Rectified Linear Unit)-funktionen, defineret som f(x) = max(0, x), er blevet det mest populære valg i moderne deep learning på grund af dens beregningsmæssige effektivitet og effektivitet i træning af dybe netværk. Sigmoid-funktionen, f(x) = 1/(1 + e^(-x)), presser outputs til et interval mellem 0 og 1 og er nyttig til binære klassifikationsopgaver. Tanh-funktionen, f(x) = (e^x - e^(-x))/(e^x + e^(-x)), producerer outputs mellem -1 og 1 og klarer sig ofte bedre end sigmoid i skjulte lag. Valget af aktiveringsfunktion har stor indflydelse på netværkets læringsdynamik, konvergenshastighed og endelige ydeevne. Moderne arkitekturer bruger ofte ReLU i skjulte lag for dens effektivitet og sigmoid eller softmax i outputlag for sandsynlighedsestimering. Den ikke-linearitet, aktiveringsfunktioner indfører, gør det muligt for neurale netværk at approksimere enhver kontinuert funktion, en egenskab kendt som universal approximation theorem, hvilket forklarer deres bemærkelsesværdige alsidighed på tværs af forskellige anvendelser.
Markedet for neurale netværk har oplevet eksplosiv vækst, hvilket afspejler teknologiens centrale rolle i moderne kunstig intelligens. Ifølge nyere markedsundersøgelser havde det globale marked for software til neurale netværk en værdi på cirka 34,76 milliarder dollars i 2025 og forventes at nå 139,86 milliarder dollars i 2030, hvilket svarer til en årlig vækstrate (CAGR) på 32,10%. Det bredere marked for neurale netværk viser endnu mere dramatisk ekspansion, med estimater der peger på vækst fra 34,05 milliarder dollars i 2024 til 385,29 milliarder dollars i 2033, med en CAGR på 31,4%. Denne eksplosive vækst drives af flere faktorer: øget tilgængelighed af store datasæt, udvikling af mere effektive træningsalgoritmer, udbredelsen af GPU- og specialiseret AI-hardware og den udbredte anvendelse af neurale netværk på tværs af industrier. Ifølge Stanfords AI Index Report 2025 rapporterede 78% af organisationerne brug af AI i 2024, op fra 55% året før, og neurale netværk udgør rygraden i de fleste enterprise AI-implementeringer. Anvendelsen spænder over sundhed, finans, produktion, detailhandel og stort set alle andre sektorer, da organisationer indser den konkurrencefordel, neurale netværksbaserede systemer giver til mønstergenkendelse, forudsigelse og beslutningstagning.
Neurale netværk driver de mest avancerede AI-systemer, der er i drift i dag, herunder ChatGPT, Perplexity, Google AI Overviews og Claude. Disse store sprogmodeller er bygget på transformer-baserede neurale netværksarkitekturer, der bruger attention-mekanismer til at behandle og generere menneskesprog med bemærkelsesværdig sofistikering. Transformer-arkitekturen, introduceret i 2017, revolutionerede naturlig sprogbehandling ved at muliggøre parallel behandling af hele sekvenser frem for sekventiel behandling, hvilket dramatisk forbedrede træningseffektivitet og modelpræstation. I forbindelse med brandovervågning og AI-citationssporing er forståelse af neurale netværk afgørende, fordi disse systemer bruger neurale netværk til at forstå kontekst, hente relevant information og generere svar, der kan referere til eller citere dit brand, domæne eller indhold. AmICited udnytter viden om, hvordan neurale netværk bearbejder og henter information, til at overvåge hvor dit brand optræder i AI-genererede svar på tværs af flere platforme. I takt med at neurale netværk bliver bedre til at forstå semantisk betydning og hente relevante oplysninger, bliver det stadig vigtigere at overvåge dit brands tilstedeværelse i AI-svar for at opretholde brandsynlighed og styre dit online omdømme i en tid med AI-drevet søgning og indholdsgenerering.
Effektiv træning af neurale netværk indebærer flere betydelige udfordringer, som forskere og praktikere må tackle. Overfitting opstår, når et netværk lærer træningsdataene for godt, inklusive deres støj og særheder, hvilket resulterer i dårlig ydeevne på nye, usete data. Dette er særligt problematisk med dybe netværk, der har mange parametre i forhold til træningsdatasættets størrelse. Underfitting er det modsatte problem, hvor netværket ikke har tilstrækkelig kapacitet eller træning til at opfange de underliggende mønstre i dataene. Forsvindende gradient-problemet forekommer i meget dybe netværk, hvor gradienterne bliver eksponentielt mindre, når de sendes bagud, hvilket får vægte i de tidlige lag til at opdatere ekstremt langsomt eller slet ikke. Eksploderende gradient-problemet er det modsatte, hvor gradienterne bliver eksponentielt større, hvilket medfører ustabil træning. Moderne løsninger inkluderer batch normalisering, som normaliserer lag-inputs for at opretholde stabil gradientflow; residualforbindelser (skip connections), der tillader gradienter at flyde direkte gennem lag; og gradient clipping, der begrænser gradienternes størrelse. Regulariseringsteknikker som L1 og L2 regularisering tilføjer straf for store vægte og fremmer enklere modeller, der generaliserer bedre. Dropout deaktiverer tilfældigt neuroner under træning og forhindrer co-adaptation, hvilket forbedrer generalisering. Valget af optimeringsalgoritme (såsom Adam, SGD eller RMSprop) og læringsrate påvirker træningseffektivitet og endelig modelpræstation betydeligt. Praktikere skal nøje balancere modelkompleksitet, træningsdatasætsstørrelse, regulariseringsstyrke og optimeringsparametre for at opnå netværk, der lærer effektivt uden overfitting.
Udviklingen af neurale netværksarkitekturer har fulgt en klar linje mod stadigt mere avancerede mekanismer til informationsbehandling. Tidlige feedforward-netværk var begrænset til input af fast længde og kunne ikke opfange tidsmæssige eller sekventielle afhængigheder. Recurrent neural networks (RNNs) introducerede feedback-sløjfer, der tillod information at bestå over tidstrin og muliggjorde behandling af sekvenser med variabel længde. RNNs led dog under gradientflow-problemer og var grundlæggende sekventielle, hvilket forhindrede parallelisering på moderne hardware. Long Short-Term Memory (LSTM)-netværk løste nogle af disse problemer gennem hukommelsesceller og gatingmekanismer, men forblev grundlæggende sekventielle. Gennembruddet kom med transformer-netværk, som helt erstattede rekurrens med attention-mekanismer. Attention-mekanismen gør det muligt for netværket dynamisk at fokusere på forskellige dele af inputtet ved at beregne vægtede kombinationer af alle inputelementer parallelt. Det gør det muligt for transformere at fange langtrækkende afhængigheder effektivt og samtidig udnytte fuld parallelisering på GPU-klynger. Transformer-arkitekturen, kombineret med massiv skala (moderne store sprogmodeller indeholder milliarder til billioner af parametre), har vist sig bemærkelsesværdig effektiv til naturlig sprogbehandling, computer vision og multimodale opgaver. Succesen med transformere har ført til deres udbredelse som standardarkitektur for førende AI-systemer, herunder alle store sprogmodeller. Denne udvikling viser, hvordan arkitektoniske innovationer, kombineret med øget computerkraft og større datasæt, fortsætter med at udvide grænserne for, hvad neurale netværk kan opnå.
Feltet for neurale netværk udvikler sig fortsat hurtigt med flere lovende retninger. Neuromorfisk computing sigter mod at skabe hardware, der i højere grad efterligner biologiske neurale netværk og potentielt opnår større energieffektivitet og beregningskraft. Few-shot og zero-shot learning-forskning fokuserer på at gøre neurale netværk i stand til at lære ud fra få eksempler og dermed efterligne menneskelig læring bedre. Forklarbarhed og fortolkelighed er blevet stadig mere vigtige, og forskere udvikler teknikker til at forstå og visualisere, hvad neurale netværk lærer, hvilket er afgørende for anvendelser med stor betydning som sundhed, finans og retssystemer. Federated learning muliggør træning af neurale netværk på distribuerede data uden at centralisere følsomme oplysninger og adresserer dermed privatlivsbekymringer. Kvanteneurale netværk repræsenterer et område, hvor kvantecomputing kombineres med neurale netværksarkitekturer og muligvis giver eksponentielle hastighedsforøgelser for visse problemer. Multimodale neurale netværk, der integrerer tekst, billeder, lyd og video, bliver stadig mere sofistikerede og muliggør mere omfattende AI-systemer. Energieffektive neurale netværk udvikles for at reducere de beregningsmæssige og miljømæssige omkostninger ved træning og udrulning af store modeller. I takt med at neurale netværk udvikler sig, bliver deres integration i AI-overvågningssystemer som AmICited stadig vigtigere for organisationer, der ønsker at forstå og styre deres brands tilstedeværelse i AI-genereret indhold og svar på tværs af platforme som ChatGPT, Perplexity, Google AI Overviews og Claude.
Neurale netværk er inspireret af strukturen og funktionen af biologiske neuroner i den menneskelige hjerne. I hjernen kommunikerer neuroner gennem elektriske signaler via synapser, som kan styrkes eller svækkes baseret på erfaring. Kunstige neurale netværk efterligner denne adfærd ved at bruge matematiske modeller af neuroner forbundet gennem vægtede forbindelser, hvilket gør det muligt for systemet at lære og tilpasse sig ud fra data på en måde, der ligner, hvordan biologiske hjerner bearbejder information og danner minder.
Backpropagation er den primære algoritme, der gør det muligt for neurale netværk at lære. Under fremadpropagering flyder data gennem netværkets lag og producerer forudsigelser. Netværket beregner derefter fejlen mellem de forudsagte og faktiske outputs ved hjælp af en tab-funktion. I den bagudgående fase bliver denne fejl sendt tilbage gennem netværket ved hjælp af kædereglen fra calculus, hvor det beregnes, hvor meget hver vægt og bias har bidraget til fejlen. Vægtene justeres derefter i retningen, der minimerer fejlen, typisk ved brug af gradient descent-optimering.
De primære neurale netværksarkitekturer inkluderer feedforward-netværk (data flyder kun i én retning), convolutional neural networks eller CNNs (optimeret til billedbehandling), recurrent neural networks eller RNNs (designet til sekventielle data), long short-term memory-netværk eller LSTMs (forbedrede RNNs med hukommelsesceller) og transformer-netværk (bruger attention-mekanismer til parallel behandling). Hver arkitektur er specialiseret til forskellige typer data og opgaver, fra billedgenkendelse til naturlig sprogbehandling.
Moderne AI-systemer som ChatGPT, Perplexity og Claude er bygget på transformer-baserede neurale netværk, som bruger attention-mekanismer til effektiv sprogbehandling. Disse neurale netværk gør det muligt for systemerne at forstå kontekst, generere sammenhængende tekst og udføre komplekse ræsonnementer. Neurale netværks evne til at lære fra enorme datasæt og fange indviklede mønstre i sprog gør dem uundværlige for at bygge samtale-AI, der kan forstå og svare på menneskelige forespørgsler med bemærkelsesværdig nøjagtighed.
Vægte i neurale netværk styrer styrken af forbindelserne mellem neuroner og bestemmer, hvor stor indflydelse hvert input har på outputtet. Bias er yderligere parametre, som flytter aktiveringstærsklen for neuroner, så de kan aktiveres, selv når inputtene er svage. Sammen udgør vægte og bias de lærbare parametre i netværket, som justeres under træning for at minimere forudsigelsesfejl og gøre det muligt for netværket at lære komplekse mønstre fra data.
Aktiveringsfunktioner indfører ikke-linearitet i neurale netværk og gør det muligt for dem at lære komplekse, ikke-lineære relationer i data. Uden aktiveringsfunktioner ville det at stable flere lag stadig resultere i lineære transformationer, hvilket kraftigt ville begrænse netværkets læringskapacitet. Almindelige aktiveringsfunktioner inkluderer ReLU (Rectified Linear Unit), sigmoid og tanh, som hver især indfører forskellige typer ikke-linearitet, der hjælper netværket med at fange indviklede mønstre og lave mere sofistikerede forudsigelser.
Skjulte lag er mellemliggende lag mellem input- og outputlag, hvor netværket udfører det meste af sin beregningsmæssige arbejde. Disse lag udtrækker og transformerer egenskaber fra rå inputdata til stadigt mere abstrakte repræsentationer. Dybden og bredden af de skjulte lag bestemmer netværkets kapacitet til at lære komplekse mønstre. Dybdegående netværk med flere skjulte lag kan fange mere sofistikerede relationer i data, men kræver flere computerressourcer og omhyggelig træning for at undgå overfitting.
Begynd at spore, hvordan AI-chatbots nævner dit brand på tværs af ChatGPT, Perplexity og andre platforme. Få handlingsrettede indsigter til at forbedre din AI-tilstedeværelse.
Transformer-arkitektur er et neuralt netværksdesign, der bruger self-attention-mekanismer til at behandle sekventielle data parallelt. Det driver ChatGPT, Claud...

Lær hvad Natural Language Processing (NLP) er, hvordan det fungerer, og dets afgørende rolle i AI-systemer. Udforsk NLP-teknikker, applikationer og udfordringer...

Lær hvad AI-indholds-syndikeringsnetværk er, hvordan de fungerer, og hvorfor de er essentielle for moderne indholdsdistribution. Opdag hvordan AI-optimering for...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.