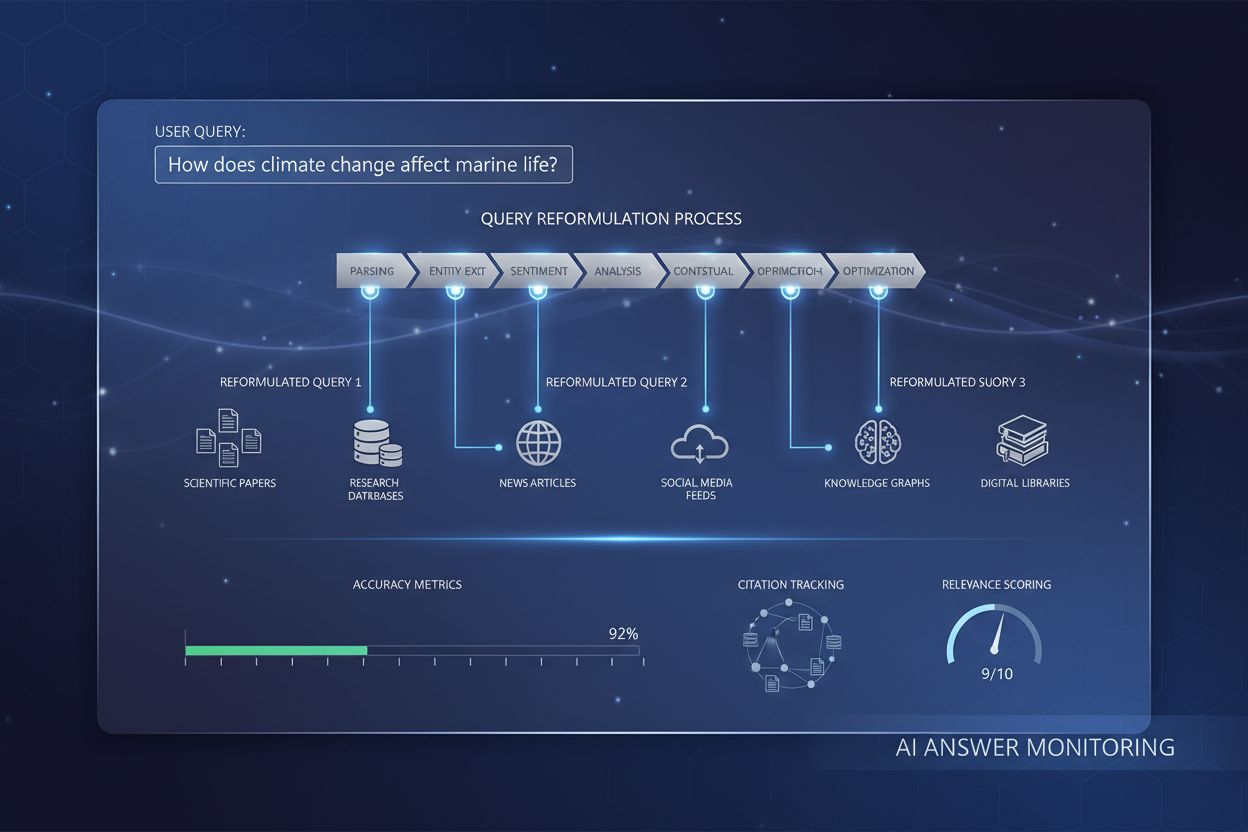
Forespørgselsreformulering
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...
10 min læsning
Optimering af forespørgselsudvidelse er processen med at forbedre brugersøgninger med relaterede termer, synonymer og kontekstuelle variationer for at øge AI-systemers præcision i informationshentning og indholdsrelevans. Det bygger bro over ordforrådsgab mellem brugerforespørgsler og relevante dokumenter og sikrer, at AI-systemer som GPT’er og Perplexity kan finde og referere mere passende indhold. Denne teknik er essentiel for at forbedre både omfanget og nøjagtigheden af AI-genererede svar. Ved intelligent at udvide forespørgsler kan AI-platforme markant forbedre, hvordan de finder og citerer relevante kilder.
Optimering af forespørgselsudvidelse er processen med at forbedre brugersøgninger med relaterede termer, synonymer og kontekstuelle variationer for at øge AI-systemers præcision i informationshentning og indholdsrelevans. Det bygger bro over ordforrådsgab mellem brugerforespørgsler og relevante dokumenter og sikrer, at AI-systemer som GPT'er og Perplexity kan finde og referere mere passende indhold. Denne teknik er essentiel for at forbedre både omfanget og nøjagtigheden af AI-genererede svar. Ved intelligent at udvide forespørgsler kan AI-platforme markant forbedre, hvordan de finder og citerer relevante kilder.
Optimering af forespørgselsudvidelse er processen med at omformulere og forbedre søgeforespørgsler ved at tilføje relaterede termer, synonymer og semantiske variationer for at forbedre informationshentning og svarenes kvalitet. I sin kerne adresserer forespørgselsudvidelse ordforrådsgabsproblemet—den grundlæggende udfordring, at brugere og AI-systemer ofte bruger forskellig terminologi til at beskrive de samme begreber, hvilket fører til manglende relevante resultater. Denne teknik er kritisk for AI-systemer, fordi den bygger bro mellem, hvordan folk naturligt udtrykker deres informationsbehov, og hvordan indhold faktisk er indekseret og gemt. Ved intelligent at udvide forespørgsler kan AI-platforme markant forbedre både relevansen og omfanget af deres svar.
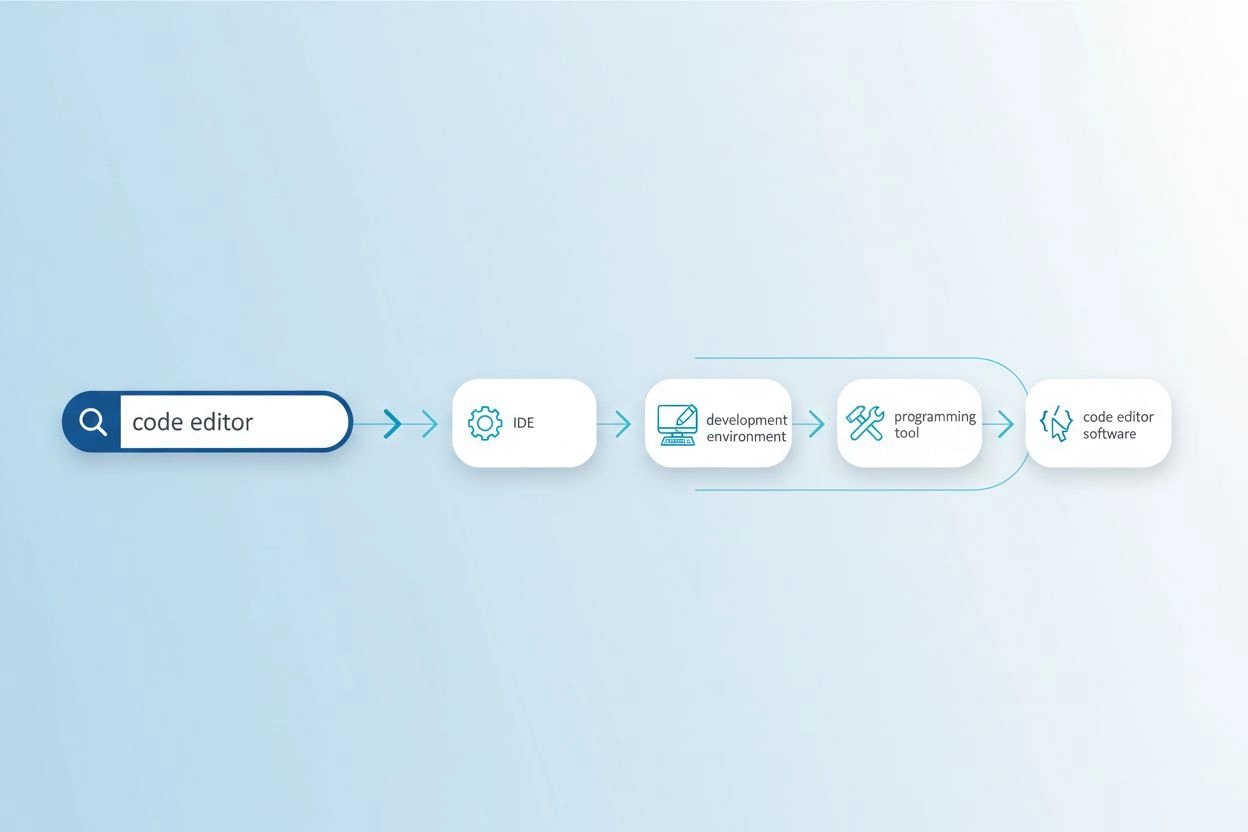
Ordforrådsgabsproblemet opstår, når de præcise ord, der bruges i en forespørgsel, ikke matcher terminologien i relevante dokumenter, hvilket får søgesystemer til at overse værdifuld information. For eksempel kan en bruger, der søger efter “kodeeditor”, gå glip af resultater om “IDE’er” (Integrated Development Environments) eller “teksteditorer”, selvom disse er meget relevante alternativer. Ligeledes kan en person, der søger på “køretøj”, ikke finde resultater, der er tagget med “bil”, “automobil” eller “motorkøretøj”, på trods af tydelig semantisk overlapning. Dette problem bliver mere udtalt i specialiserede domæner, hvor flere tekniske termer beskriver det samme begreb, og det påvirker direkte kvaliteten af AI-genererede svar ved at begrænse det kildemateriale, der er tilgængeligt for syntese. Forespørgselsudvidelse løser dette ved automatisk at generere relaterede forespørgselsvariationer, der fanger forskellige måder, den samme information kan udtrykkes på.
| Oprindelig forespørgsel | Udvidet forespørgsel | Effekt |
|---|---|---|
| kodeeditor | IDE, teksteditor, udviklingsmiljø, kildekodeeditor | Finder 3-5x flere relevante resultater |
| maskinlæring | AI, kunstig intelligens, dyb læring, neurale netværk | Fanger domænespecifikke terminologivariationer |
| køretøj | bil, automobil, motorkøretøj, transport | Inkluderer almindelige synonymer og relaterede termer |
| hovedpine | migræne, spændingshovedpine, smertelindring, hovedpinebehandling | Adresserer medicinske terminologivariationer |
Moderne forespørgselsudvidelse anvender flere supplerende teknikker, som hver har deres egne fordele afhængigt af anvendelse og domæne:
Hver teknik tilbyder forskellige afvejninger mellem beregningsomkostning, udvidelseskvalitet og domænespecificitet, hvor LLM-baserede tilgange giver den højeste kvalitet, men kræver flere ressourcer.
Forespørgselsudvidelse forbedrer AI-svar ved at give sprogmodeller og hentningssystemer et rigere og mere omfattende sæt kildemateriale at trække på, når de genererer svar. Når en forespørgsel udvides med synonymer, relaterede begreber og alternative formuleringer, kan hentningssystemet få adgang til dokumenter, der bruger anden terminologi, men indeholder lige så relevant information, hvilket markant øger recall i søgeprocessen. Denne udvidede kontekst gør det muligt for AI-systemer at syntetisere mere komplette og nuancerede svar, da de ikke længere er begrænset af de specifikke ordvalg i den oprindelige forespørgsel. Dog introducerer forespørgselsudvidelse et præcision vs. recall-afvejning: Mens udvidede forespørgsler henter flere relevante dokumenter, kan de også indføre støj og mindre relevante resultater, hvis udvidelsen er for aggressiv. Nøglen til optimering er at kalibrere udvidelsesintensiteten for at maksimere relevansforbedringer og minimere irrelevant støj, så AI-svar bliver mere omfattende uden at gå på kompromis med nøjagtigheden.
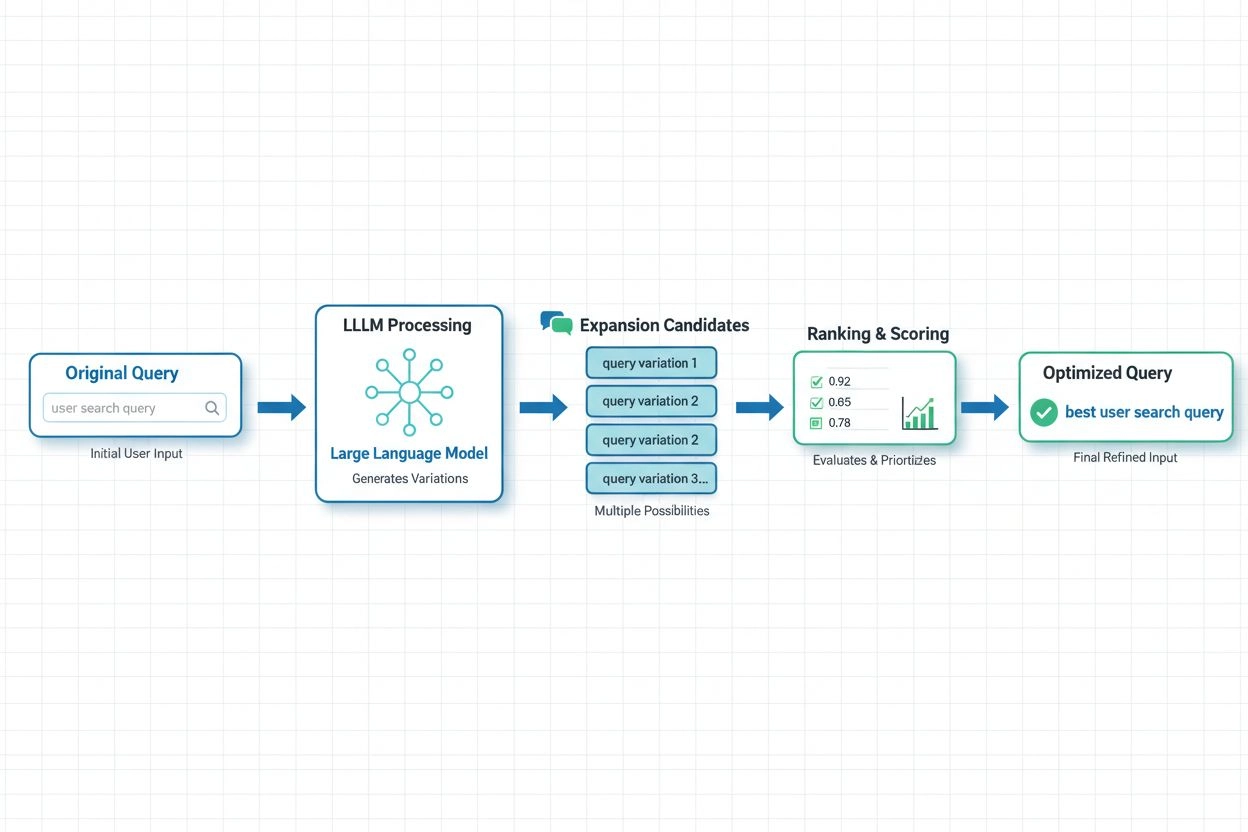
I moderne AI-systemer er LLM-baseret forespørgselsudvidelse blevet den mest sofistikerede tilgang og udnytter store sprogmodellers semantiske forståelse til at generere kontekstuelt passende forespørgselsvariationer. Nyere forskning fra Spotify demonstrerer styrken i denne tilgang: Deres implementering, der bruger præferencejusteringsteknikker (kombinerer RSFT og DPO-metoder), opnåede cirka 70 % reduktion i behandlingstid og forbedrede samtidig top-1-hentningspræcision. Disse systemer fungerer ved at træne sprogmodeller til at forstå brugerpræferencer og intentioner og derefter generere udvidelser, der stemmer overens med, hvad brugerne faktisk finder værdifuldt, frem for blot at tilføje tilfældige synonymer. Realtidsoptimeringstilgange tilpasser løbende udvidelsesstrategier baseret på brugerfeedback og informationshentningsresultater, så systemerne lærer, hvilke udvidelser der fungerer bedst for bestemte forespørgselstyper og domæner. Denne dynamiske tilgang er særligt værdifuld for AI-overvågningsplatforme, da det gør det muligt for systemer at spore, hvordan forespørgselsudvidelse påvirker citationsnøjagtighed og indholdsopdagelse på tværs af forskellige emner og brancher.
På trods af fordelene giver forespørgselsudvidelse væsentlige udfordringer, der kræver nøje optimeringsstrategier. Over-udvidelsesproblemet opstår, når for mange forespørgselsvariationer tilføjes, hvilket introducerer støj og henter irrelevante dokumenter, der udvander svarenes kvalitet og øger beregningsomkostninger. Domænespecifik justering er essentiel, fordi udvidelsesteknikker, der fungerer godt til generel websøgning, kan fejle i specialiserede områder som medicinsk forskning eller juridiske dokumenter, hvor terminologisk præcision er kritisk. Organisationer skal balancere dækning versus nøjagtighed—udvide nok til at fange relevante variationer uden at udvide så meget, at irrelevante resultater overdøver signalet. Effektive valideringsmetoder inkluderer A/B-test af forskellige udvidelsesstrategier mod menneskelige vurderinger af relevans, overvågning af målepunkter som precision@k og recall@k og løbende analyse af, hvilke udvidelser der faktisk forbedrer downstream-task-performance. De mest succesfulde implementeringer bruger adaptiv udvidelse, der justerer intensiteten baseret på forespørgselskarakteristika, domænekontekst og observeret informationshentningskvalitet, frem for at anvende ensartede udvidelsesregler på alle forespørgsler.
For AmICited.com og AI-overvågningsplatforme er optimering af forespørgselsudvidelse grundlæggende for præcist at kunne spore, hvordan AI-systemer citerer og refererer kilder på tværs af forskellige emner og søgekontekster. Når AI-systemer bruger udvidede forespørgsler internt, får de adgang til et bredere udvalg af potentielle kildematerialer, hvilket direkte påvirker, hvilke citater der vises i deres svar, og hvor omfattende de dækker tilgængelig information. Det betyder, at overvågning af AI-svar-kvalitet kræver forståelse for ikke blot, hvad brugerne spørger om, men også hvilke udvidede forespørgselsvariationer AI-systemet muligvis bruger i kulissen for at hente støttende information. Brands og indholdsskabere bør optimere deres indholdsstrategi ved at overveje, hvordan deres materiale kan opdages gennem forespørgselsudvidelse—ved at bruge flere terminologiske variationer, synonymer og relaterede begreber gennem hele deres indhold for at sikre synlighed på tværs af forskellige forespørgselsformuleringer. AmICited hjælper organisationer med at spore dette ved at overvåge, hvordan deres indhold optræder i AI-genererede svar på tværs af forskellige forespørgselstyper og udvidelser, afsløre huller, hvor indhold kan blive overset på grund af ordforrådsgab, og give indsigt i, hvordan strategier for forespørgselsudvidelse påvirker citationsmønstre og indholdsopdagelse i AI-systemer.
Forespørgselsudvidelse tilføjer relaterede termer og synonymer til den oprindelige forespørgsel, mens kerneintentionen bevares, hvorimod forespørgselsomskrivning reformulerer hele forespørgslen for bedre at matche søgesystemets kapaciteter. Forespørgselsudvidelse er additiv—den udvider søgeomfanget—mens omskrivning er transformativ og ændrer, hvordan forespørgslen udtrykkes. Begge teknikker forbedrer informationshentning, men udvidelse er typisk mindre risikabel, da den bevarer den oprindelige intention.
Forespørgselsudvidelse påvirker direkte, hvilke kilder AI-systemer opdager og citerer, fordi det ændrer de dokumenter, der er tilgængelige for hentning. Når AI-systemer bruger udvidede forespørgsler internt, får de adgang til et bredere udvalg af potentielle kilder, hvilket påvirker, hvilke citater der vises i deres svar. Det betyder, at overvågning af AI-svar-kvalitet kræver forståelse for ikke kun, hvad brugerne spørger om, men også hvilke udvidede forespørgselsvariationer AI-systemet muligvis bruger i kulissen.
Ja, over-udvidelse kan introducere støj og hente irrelevante dokumenter, der udvander svarenes kvalitet. Dette sker, når for mange forespørgselsvariationer tilføjes uden korrekt filtrering. Nøglen er at balancere udvidelsesintensiteten for at maksimere forbedringer i relevans samtidig med at irrelevante resultater minimeres. Effektive implementeringer bruger adaptiv udvidelse, der justerer intensiteten baseret på forespørgselskarakteristika og observeret informationshentningskvalitet.
Store sprogmodeller har revolutioneret forespørgselsudvidelse ved at muliggøre semantisk forståelse af brugerintention og generere kontekstuelt passende forespørgselsvariationer. LLM-baseret udvidelse bruger præferencejusteringsteknikker til at træne modeller, så de genererer udvidelser, der faktisk forbedrer informationshentning i stedet for blot at tilføje tilfældige synonymer. Nyere forskning viser, at LLM-baserede tilgange kan reducere behandlingstiden med ~70 % og samtidig øge præcisionen.
Brands bør bruge flere terminologiske variationer, synonymer og relaterede koncepter gennem hele deres indhold for at sikre synlighed på tværs af forskellige forespørgselsformuleringer. Det betyder at overveje, hvordan dit materiale kan opdages gennem forespørgselsudvidelse—ved at bruge både tekniske og dagligdags termer, inkludere alternative formuleringer og adressere relaterede begreber. Denne strategi sikrer, at dit indhold kan opdages uanset hvilke forespørgselsvariationer AI-systemer bruger.
Nøglemålepunkter inkluderer precision@k (relevans af de øverste k-resultater), recall@k (dækning af relevant indhold i de øverste k-resultater), Mean Reciprocal Rank (placering af første relevante resultat) og downstream-task-performance. Organisationer overvåger også behandlingstid, beregningsomkostninger og brugertilfredshedsmålinger. A/B-testning af forskellige udvidelsesstrategier mod menneskelige vurderinger af relevans giver den mest pålidelige validering.
Nej, de er komplementære men forskellige teknikker. Forespørgselsudvidelse ændrer inputforespørgslen for at forbedre informationshentning, mens semantisk søgning bruger indlejringer og vektorrepræsentationer til at finde konceptuelt lignende indhold. Forespørgselsudvidelse kan indgå i en semantisk søgningspipeline, men semantisk søgning kan også fungere uden eksplicit forespørgselsudvidelse. Begge teknikker tackler ordforrådsgabet, men gennem forskellige mekanismer.
AmICited sporer, hvordan AI-systemer citerer og refererer kilder på tværs af forskellige emner og søgekontekster, hvilket afslører hvilke udvidede forespørgsler der fører til, at dit brand nævnes. Ved at overvåge citationsmønstre på tværs af forskellige forespørgselstyper og udvidelser giver AmICited indsigt i, hvordan strategier for forespørgselsudvidelse påvirker indholdsopdagelse og citationsnøjagtighed i AI-systemer som GPT'er og Perplexity.
Optimering af forespørgselsudvidelse påvirker, hvordan AI-systemer som GPT'er og Perplexity opdager og citerer dit indhold. Brug AmICited til at spore, hvilke udvidede forespørgsler der fører til, at dit brand bliver nævnt i AI-svar.
Lær hvordan forespørgselsreformulering hjælper AI-systemer med at fortolke og forbedre brugerforespørgsler for bedre informationssøgning. Forstå teknikkerne, fo...

Forespørgselsforfining er den iterative proces med at optimere søgeforespørgsler for bedre resultater i AI-søgemaskiner. Lær hvordan det fungerer på tværs af Ch...

Lær hvordan du optimerer søgeord til AI-søgemaskiner. Opdag strategier til at få dit brand citeret i ChatGPT, Perplexity og Google AI-svar med handlingsrettede ...
Cookie Samtykke
Vi bruger cookies til at forbedre din browsingoplevelse og analysere vores trafik. See our privacy policy.